以前は、アセンブリ言語で書かれた x68k専用のプログラムを利用して性能評価を行なった結果を掲載していましたが、x68kを利用している方はもうほとんどいないのではないかと思いますので、全く異なる題材に切替えることにしました。作成したサンプルのプログラムは一応残しておきますので、御利用されたい方は以下のリンク先からダウンロードしてください。念のためですが、x68k専用なので他機種では使用できません。
x68k専用サンプル・プログラム (gline.zip)サンプルのプログラムではダブルステップ Bresenhamアルゴリズムと両端からの同時描画を使って高速化を図り、また水平・垂直線分は別処理で行っています。クリッピングについては中点分割アルゴリズムは使わず、直接端辺と線分の交点を算出することで行います。
サンプルには、線分描画用プログラム[g_line.s]の他、アセンブルに必要なファイルがいくつか入っています。
実行形式ファイルは入っていません。もし使用する場合は各自でアセンブルしてください。
線分を描画するために必要なプログラムは前回までの内容で大体そろいました。しかし、今のところは普通の線分を描画できるだけであり、例えば、表示された画像の色を反転させて描画したり、点線などのラインパターンをサポートするなどの応用的な利用はできません。前者は、グラフィックツールなどで線分による範囲指定(矩形・ポリゴンでの範囲指定や曲線描画の指定など)に、後者は、ドローイングツールなどで線分を描画する場合によく利用されます。工夫次第では、他にもいろいろな応用が可能になります。
今のプログラムの書き方では、特殊な用途に応じて線分描画ルーチンに機能を追加する必要があります。しかし、あらゆる用途を想定して機能を追加していくことは不可能なので、できれば外部からプラグインのような形で機能を追加できた方が便利です。そのような場合に有効なのが、関数ポインタを使ったテクニックです。
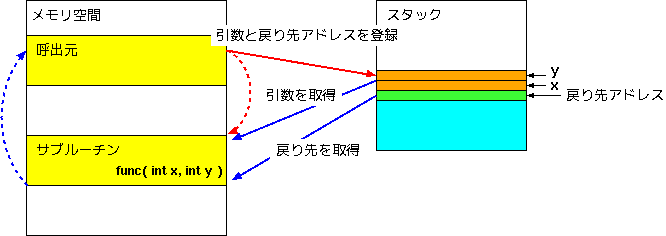
コンピュータのメモリ上では、プログラムもデータも同等に数値で表現されています。機能ごとに分かれたプログラムは、メモリ上のある場所に書き込まれている形になります。サブルーチンを呼び出す時は、渡すべき引数と戻り先アドレス(つまり現在位置)をスタックに入れて、サブルーチンのあるアドレスへジャンプします。サブルーチン側は、スタックに登録された引数を取り出して処理を行ない、処理が終わったら戻り先アドレスを取り出して元の場所にジャンプします。大雑把に言うと、サブルーチンはこのような流れで呼び出されます。
呼出元は、サブルーチンのあるアドレスへジャンプするだけで、そのサブルーチンがいったい何者であるかは意識していません。従って、引数の渡し方が統一されていれば、ジャンプするアドレスを用途に応じて変更することによってサブルーチンの切り替えを行なうことが可能になります。C言語において、サブルーチンの切り替えを行なうために利用されるのが「関数ポインタ(Function Pointer)」です。
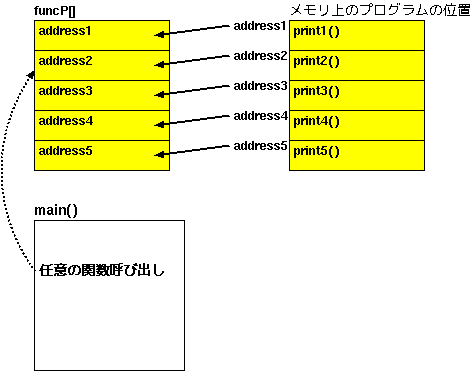
/* 1から 5までの表示用関数 */ void print1() { printf( "1\n" ); } void print2() { printf( "2\n" ); } void print3() { printf( "3\n" ); } void print4() { printf( "4\n" ); } void print5() { printf( "5\n" ); } int main( int argc, char* argv[] ) { /* 数値表示用関数のポインタ */ void (*funcP[])() = { print1, print2, print3, print4, print5, }; /* 引数は必ず1つ必要 */ if ( argc < 2 ) return( -1 ); /* 引数に応じて表示用関数を切り替え */ int i = atoi( argv[1] ); if ( i > 0 && i <= sizeof(funcP) / sizeof(funcP[0]) ) ( *(funcP[i - 1]) )(); }
上記ソースコードは、関数ポインタを利用したサブルーチン切り替えのサンプルです。数値表示用関数のポインタの配列 funcP[]に関数へのポインタを登録して、引数の番号に応じた要素(=関数)を呼び出して実行しています。
関数ポインタは、" [戻り値] (*[関数ポインタを示す変数名])( [引数], ... ) "のように宣言します。例えば、char*型一つと int型二つを引数として持ち、int型を戻り値とする関数のための関数ポインタは、
と宣言することになり、この時の関数ポインタは funcPになります。関数ポインタを他の関数への引数として渡す場合も、同様の記述を行なう必要があります。
上に記述した宣言は、
とは異なることに注意が必要です(括弧の有無に注意)。下側のように表記すると、"*"は intと結合してしまい、funcPは「intへのポインタを返す関数」を意味することになります。
関数ポインタ内の引数が多くなると、宣言するたびに長い引数の列を表記するのは面倒だし、ソースが見づらくなるので、通常は typedefを使い、関数ポインタの型に対して別名を定義してしまいます。上に示した関数ポインタの型は、以下のように記述することで FuncPとして別名定義できます。
typedefで定義する型名(上の例では FuncP)は、変数名を宣言する時の位置と同じ場所に記述します。このように別名を定義しておくと、関数ポインタの宣言は次のように簡単に記述することができます。
int型の戻り値を返す関数 f( char*, int, int )へのポインタを funcPへ代入して、関数ポインタを通して fを実行する場合、次のように記述します。
FuncP funcP = f; int res = (*funcP)( cp, i, j );
サンプル・プログラムの中の funcPの宣言も、typedefを利用すれば、通常の配列宣言と同じような形式で記述することができます。
typedef void (*FuncP[])();
FuncP funcP[] = {
print1, print2, print3, print4, print5,
};
関数ポインタ(及びそれを要素に持つ配列など)は、さまざまな場面で活用することのできる非常に便利な機能です。宣言の方法が少しだけ複雑に見えますが、慣れてしまえば、ソースの冗長性などを抑えることが可能になる他に、機能の変更や追加がしやすいプログラムを作成することもできるようになります。
現在利用されているほとんどの言語は「オブジェクト指向プログラミング言語 (Object-Oriented Programming Language; OOPL)」と呼ばれ、C言語などのような従来の「手続き型言語 (Procedural Language)」とはプログラムの記述方法が異なります。細かい内容は他の参考書に譲るとして、ここではオブジェクト指向言語の持つ特徴を簡単に説明します。
従来の手続き型言語では、処理に必要なデータを変数として宣言して、そのデータを処理するための手続きを関数として作成することで一つのプログラムを完成させます。そのため、プログラムの規模が大きくなるに従って、以下のような弊害が発生することになります。
そこで、データと手続きを一つにまとめ、両者をより密接なもの(オブジェクト)として用意して、手続きのひとまとまりを小さくする手法としてオブジェクト指向言語が開発されることになります。その特徴は、次のようになります。
カプセル化とは、データと手続きをオブジェクトとしてまとめたとき、「何を公開して何を隠蔽するか」を明確にすることです。隠蔽されたデータや実装(手続きの具体的な内容のこと)は外部からアクセスすることはできなくなるため、それらの仕様が変更されたとしても外部はなんの影響も受けず、変更による問題が発生しづらくなります。例えば、複数の要素を確保して、要素番号を渡すことによってその要素を返す手続きを持ったオブジェクトがあったとき、要素を確保するためのエリアが配列ではなく(データが巨大化したなどの理由により)ファイルになったり、さらにはその複合になったとしても、その部分が外部からアクセスできないようになっていれば、呼び出し側に対する変更は必要ありません。これが、中のデータ部分にまでアクセスできるようになっていたら、内部の仕様変更に応じて呼び出し側も変更をする必要が発生するため、利用頻度の高いオブジェクトであるほど容易には変更することができなくなります。外部には無関係な部分を隠蔽して、必要な部分だけを公開することが、カプセル化の目的となります。
継承は、オブジェクトの構造化を目的とした概念です。あるカテゴリに分類できるオブジェクトの集合を一つにまとめ、それらを同じものとして扱うことができるようになります。例えば、住所録用に作成したオブジェクトに対して、今までなかった血液型などの情報を追加したい場合、既存のオブジェクトそのものを変更するのではなく、その機能を継承した新たなオブジェクトを用意して、それに対して変更を行うようなことができます。既存のオブジェクトが複数のプログラムですでに利用されていて、それらを変更するのが容易ではない場合に有効な方法です。継承される側は基底クラス(スーパークラス)などと呼ばれ、継承する側は派生クラス(サブクラス)と呼ばれます。
Javaや C#などは、全オブジェクトに対する基底クラスとして Object型が存在し、他のオブジェクトは全て Objectの派生クラスになります。それに対して C++は全オブジェクトに対する基底クラスは存在しません。このあたりは、設計方針の違いによるものです。何らかの機能を持ったオブジェクトに対して基底クラスを作成するとします(例えば配列のように、複数のデータの集合を表現するクラスなど)。すると、この基底クラスから考えられる全ての派生クラスに対して、その共通点はたいてい"空集合"になります。逆に和集合を用意して、無関係なデータや手続きへのアクセスは無視するか、エラーを返すような基底クラスを用意した場合、肥大化したインターフェースを持ったクラスとなってしまいます。そのようなインターフェースは「ファット・インターフェース(Fat Interface)」と呼ばれ、C++の設計者である Bjarne Stroustrupはそういった作り方は避けるべきと書いています。実際、C++の標準ライブラリにある同様のオブジェクト(コンテナクラス)は、別のかしこい手法によって構造化を行なっています。
ちなみに、Javaや C#が持っている Objectクラスでは、オブジェクトのコピー(clone)や等値判定(equal)・文字列変換(toString)などのメソッドが用意されています。
最後の多相性は、自分としては最も重要な概念だと考えています。継承関係にあるオブジェクトは全て共通のインターフェースを持っています。要素番号から要素を取得する機能を持った基底クラスに対して複数のオブジェクトが継承関係にあるとき、それら全ては、要素番号から要素を取得するインターフェースを持つことが保証されます。また、その中に実装する機能を各派生クラスの特徴に合わせて変更することによって、アクセス方法は共通でもその内容が異なるようにすることができます。
派生クラスは、基底クラスへのポインタやリファレンス(参照)を使って操作することが可能です。またそのとき、派生クラス毎に再定義した機能が呼び出されるようにすることができます。派生クラス毎に再定義できる関数の事を「仮想関数(Virtual Function)」といいます。仮想関数の詳細については後の方で詳しく説明します。
オブジェクト指向プログラムを作成するために、オブジェクト指向言語と呼ばれる C++や Javaなどを使わなければならないかというと、そういうわけではありません。事実、ツールキットのGTK+は、C言語で開発されていながら基本設計はオブジェクト指向となっています。C++や Javaはオブジェクト指向プログラムが作成しやすいというだけで、手続き型プログラムを作成することもやろうと思えばできてしまいます。
前節の説明の中で、オブジェクトとクラスという二つの言葉が使われていました。両者は同じ意味を持つように見えますが、実際には異なるものです。まず、クラスはオブジェクトが持つデータや機能、アクセス範囲などを定めた「設計図」のようなもので、このクラスを元に生成されたものがオブジェクトになります。クラスを元に生成されたオブジェクトは「インスタンス(Instance)とも呼ばれ、インスタンスを生成することを「インスタンス化(Instantiation)」といいます。
クラスの中で定義するデータの事を「メンバ変数(Member Variable)」、処理内容を「メンバ関数(Member Function)」といいます(メンバ変数は「フィールド(Field)」、メンバ関数は「メソッド(Method)」とも呼ばれます。以下、両方合わせて「メンバ」と略記します)。メンバ変数は通常、メンバ関数を通して加工されたり外部へ出力されたりします。ここで重要なのは、オブジェクトが個々にメンバ変数を持っており、メンバ関数も個々のオブジェクトのメンバ変数に対して処理を行なうということです。具体的なデータを持ち、そのデータに対する処理がメンバ関数として定義されているような場合は、ちょうど C言語における構造体に処理部分が付加されたような形になります。このような型を「具象型(Concrete Type)」といいます。
ここで具象型の簡単なサンプルとして、座標を表現するためのオブジェクトを作成してみたいと思います。
class Coord { // メンバ変数 int x; int y; public: // コンストラクタ Coord( int _x = 0, int _y = 0 ) : x( _x ), y( _y ) {} // メンバ関数 void add( const Coord& c ) { x += c.x; y += c.y; } void sub( const Coord& c ) { x -= c.x; y -= c.y; } bool eq( const Coord& c ) const { return( x == c.x && y == c.y ); } bool ne( const Coord& c ) const { return( ! eq( c ) ); } };
上記サンプル・プログラムは、C++を利用しています。JavaやC#を利用した場合は書式が少し変わりますが、大まかな構成は変わりません。class名として最初に Coordを宣言し、以下のブロック内にその定義内容を記述します。最初の定義内容はメンバ変数で、座標を表す値として( x, y )の二つの成分が宣言されています。次にある publicラベルは、それ以降の定義内容が外部に公開されていることを示しており、カプセル化を実現するための機能として利用されます。このサンプルでは、メンバ変数は非公開に、メンバ関数は公開にすることにしてあります。ちなみに、非公開にする場合は privateラベルを利用しますが、デフォルトの状態が非公開であるため先頭の privateラベルは省略できます。
メンバ関数としては、座標どうしの加減算(add,sub)と比較用関数(eq,ne)が定義されています。ここでは宣言とその内容がまとめて記述されていますが、内容を外部に記述することもできます。eqと neでは、引数の後に const句が記述されています。これは、eqと neが定数メンバ関数であり、オブジェクトの内容を変更しないということを示しています。
メンバ関数の中で、クラス名と同じ名称を持った、戻り値のないメンバ関数がひとつ用意されています。これは「コンストラクタ(Constructor; 構築子)」と呼ばれ、インスタンス化を行なうときに実行されて、主にメンバ変数の初期化などで利用されます。コンストラクタの引数にはデフォルトの値が定義されています(int _x = 0の部分)。このような引数はデフォルト引数と呼ばれ、C++独自の機能であり、インスタンス化を行なう場合に引数を省略すると、デフォルト値が使われるようになっています(デフォルト引数は、コンストラクタのみでなく他のメンバ関数でも利用できます)。
メンバ関数の引数の型(Coord)には、前側に const句、後側に"&"が付加されています。"&"は参照渡し(call by reference)であることを示しています。それに対する値渡し(call by value)では、データの内容を別のエリアにコピーして渡すので、渡されたデータの中身を変更しても元のデータは影響を受けません。しかし、参照渡しではデータの参照先を渡すため、サブルーチン側でデータの中身を変更すると、元のデータそのものが影響を受けます。
オブジェクトが巨大である場合、データをコピーして渡すことはかなりのリソースを消費することになるため、値渡しよりも参照渡しをした方が効率的です。また、派生クラスのオブジェクトを基底クラスの型を持った引数として値渡しした場合、基底クラスの内容だけがコピーされるため(これを「スライシング(Slicing)」といいます)、思いもよらない動作やエラーの原因となります。抽象型を使った多相性の実現にはポインタかリファレンスを渡す必要もあるので、オブジェクトを引数として渡す場合は参照渡しにするのが一般的です。しかし前述のとおり、参照渡しにするとサブルーチン側で内容を書き換えることができてしまうため、内容が定数であることを示すために const句を用います。
なお、オブジェクトを「値渡し」にしては絶対にいけないというわけではありません。データ量が小さく、処理中に中身を変更するけど元のデータは変えたくないような場合は、値渡しにした方が余計な処理を書かずに済みます。
このクラスをインスタンス化して実際に利用する場合は、次のように記述します。
Coord c0( 3, 1 ); // (x,y) = (3,1) で初期化して c0を構築 Coord c1 = Coord( 5, 3 ); // (x,y) = (5,3) で初期化したオブジェクトを c1に代入 Coord origin; // デフォルト値(0,0)による構築 Coord* cp = new Coord( 3, 6 ); // ヒープ領域への構築
コンストラクタとは逆に、オブジェクトを解体する場合に呼び出される「デストラクタ(Destructor; 解体子)」という特別なメンバ関数もあります。JavaやC#の場合、似たような機能にファイナライザ(Finalizer)があります。
C++と Java・C#の間には設計思想の違いからオブジェクトの構築と解体に大きな違いがあります。C++の場合、new演算子を使ってインスタンス化しない場合は一時変数としてオブジェクトが構築され、スコープから外れたときに自動的に削除されます。new演算子を使った時はヒープ領域にオブジェクトが構築され、delete演算子が実行されるまでは解体されることはありません。それに対して Java・C#ではオブジェクトは必ずヒープ領域に作成され、ガベージコレクション機能を使って利用されなくなった領域を自動的に開放するため、プログラマは記憶領域の管理がほとんど不要になります。ガベージコレクション機能はオブジェクトの解体は自動で行ないますが、その中で利用されている外部リソース(ファイルやソケット、データベースなど)に関しては管理していないため、オブジェクトが開放されるときに後始末が必要な場合に(というより何らかの理由で処理後の後始末ができなかった場合の保険として)ファイナライザが利用されることになります。
オブジェクトのメンバ関数は、次のように利用することができます。
c0.add( c1 ); // c0にc1を加算 cp->sub( c0 ); // *cpからc0を減算 if ( c1.eq( origin ) ) {...} // c1とoriginが等しいか
構造体を使う場合の書き方とほとんど変わらないことが上記内容からわかると思います。
具象型の場合、オブジェクトが持っている機能とそのインターフェースは密接に結合しています。継承を利用して、新たな機能を持った派生クラスを作成しようとしたとき、基底クラスの中にあるデータなどが派生クラスにも必要であるとは限らないし、逆にそのデータが邪魔になるような場合も起こり得ます。そこで、インターフェース部分には実際の機能は記述せず、そこから継承された派生クラス側だけに実際の処理内容を記述すると、後付けで別の派生クラスを追加するとき他の派生クラスが影響を受けることはありません。
前述のように、派生クラスで内容が再定義される可能性のあるメンバ関数は仮想関数といいます。仮想関数が派生クラスで再び実装されていた場合、基底クラスの機能が上書き(override)され、新しい機能が呼び出されることになります。逆に再定義されていなければ、基底クラスの機能がそのまま利用されることになります。
さらに、基底クラスの中で関数の内容が実装されていない(宣言のみがされた)関数は純粋仮想関数(Pure Virtual Function)といいます。純粋仮想関数を持ったクラスは、実際の処理内容を持っていないためインスタンス化はできません。
仮想関数と純粋仮想関数は、派生クラスのオブジェクトが基底クラスのポインタまたはリファレンスに代入されたとしても、その派生クラス特有の機能が呼び出されます。
例えば、色成分の表現には RGB成分の他、YUVやCMY・HSVなど様々な型があります。しかし、どれを利用しても、点を描画するときには色コードに変換することになるので、色コードを返すメンバ関数を共通で持てば、どの色成分にも対応できる描画ルーチンを構築することができます。
class Color { public: // 仮想関数の定義 virtual unsigned int getCode() const = 0; // 色コードを返す virtual ~Color() {} // 仮想デストラクタ }; class RGB : public Color { typedef unsigned char UChar; // メンバ変数 UChar r; UChar g; UChar b; public: // コンストラクタ RGB( UChar _r, UChar _g, UChar _b ); // メンバ関数 unsigned int getCode() const; // 色コードを返す }; class YUV : public Color { // メンバ変数 double y; double u; double v; public: // コンストラクタ YUV( double _y, double _u, double _v ); // メンバ関数 unsigned int getCode() const; // 色コードを返す }; class CMY : public Color { : }; class HSV : public Color { : };
上記サンプル・プログラムにおいて、Colorが基底クラス、その他のクラスが Colorから派生したクラスになります。派生クラスには、クラス名の後ろに" : public Color"と記述してあります。これは、各クラスが Colorから派生したことを示しています。publicと宣言されている場合、基底クラスで公開されているメンバは派生クラスにおいても外部に公開され、さらに派生クラスのオブジェクトのポインタやリファレンスが基底クラスのそれらに変換することができるようになります。ここで privateと宣言した場合、基底クラスの公開メンバが派生クラスにおいては外部に公開されず、型の変換も外部ではできなくなるため、多相性を実現することができなくなります。
publicやprivateはアクセス制御を分類するためのキーワードであり、この他に「限定公開(protected)」というものもあります。それぞれのアクセス制御内容を表にまとめておきます。
| アクセス指定子 | アクセス制御 | メンバのアクセス範囲 | 基底クラスのアクセス範囲 | 基底クラスの参照への型変換 |
|---|---|---|---|---|
| private | 非公開 | そのメンバを持ったクラス内部のみ | 継承したクラス内部のみ | 継承したクラス内部のみ |
| protected | 限定公開 | そのメンバを持ったクラスとその派生クラスの内部のみ | 継承したクラスとその派生クラスの内部のみ | 継承したクラスとその派生クラスの内部のみ |
| public | 公開 | 全て | 全て | 全て |
限定公開されたメンバは、そこから継承された派生クラスの内部で利用することができるため、派生クラスを設計する場合に利用可能なサービスを提供したい場合に使われます。基底クラスに対してprivateやprotected宣言をした場合は前述のように多相性を実現することができなくなります。しかし、継承を使って「包含関係」を実現するすることができるようになります。
包含関係とは、クラス内部のメンバ変数として、他のクラスによるオブジェクトを持っている関係にあることを意味しています。このような関係は「has-a関係」とも言われています。それに対し、継承関係は「派生クラスは基底クラスの一種である」関係になるので「is-a関係」とも呼ばれます。あるクラスの機能を利用して他のクラスを構築したい場合、その関係を「has-a関係」にするか「is-a関係」にするか、決めにくい場合がよくあります。has-a関係にした場合、中に含まれるオブジェクトのメンバは、外部とアクセスできるようにメンバ関数を用意しない限り非公開になるため、それらを利用したい場合は is-a関係にした方が余分な定義が不要になります(ここでオブジェクトを公開することは考慮しません。オブジェクト自体を書き換えられることから非常に危険なため、そのようなことは通常は行いません)。しかし、is-a関係の場合は基底クラスを複数持たせることができなくなる上、公開したくないメンバまで外部に見えるようになってしまいます。
あるクラスの機能の一部だけを利用したいような場合、クラスを複数持たせることを考慮する必要がなければ、privateやprotected宣言を使って継承を行うことで包含と同じ関係を得ることができます。必要な機能だけを用意すれば、他の機能は外部から隠蔽することができるようになり、しかも基底クラスの参照へ型変換されなくなるので、隠蔽していた機能が基底クラスへの型変換によって外部へ公開されてしまう心配もありません。C++では多重継承が可能なので、インターフェース部分は公開派生してデータを表すクラスは非公開・限定公開派生するテクニックがよく利用されます。
定義した色成分を必要に応じて切り替えて描画したいような場合、次のようにプログラムを作成することで実現できます。
void drawSomeShape( const Color& col ) { unsigned int code = col.getCode(); : } void f() { RGB rgb( 0, 0, 0 ); drawSomeShape( rgb ); } void g() { YUV yuv( 0, 0, 0 ); drawSomeShape( yuv ); }
関数 fは RGBを、関数 gは YUVをそれぞれ利用してオブジェクトを作成し、drawSomeShapeを呼び出しています。drawSomeShapeへは、基底クラスである Colorへのリファレンスを渡します。Colorオブジェクトそのものを渡すわけではないことに注意してください。オブジェクトをコピーして渡した場合は基底クラスのオブジェクトに型変換され、仮想関数が未定義なのでコンパイル時にエラーとなります。ここは非常に重要なので繰り返し書きますが、多相性を利用するには、必ず基底クラスのオブジェクトへのポインタかリファレンスを使わなければならないことに注意しましょう。
Colorのようなクラスは「抽象型(Abstract Type)」と呼ばれ、主にインターフェースを定義して、多相性を実現するために利用されます。Javaや C#では、インターフェース用に特化したクラスを「インターフェース(Interface)」として宣言することもできます。インターフェースは純粋仮想関数(Javaや C#では抽象メソッドといいます)しか持たないクラスで、多重継承ができない Javaや C#において、インターフェースだけは多重継承(実際には「継承する」ではなく「実装する」と呼ばれています)ができます。これはちょうど、C++において、インターフェースを公開派生、データを非公開派生した多重継承を想定しています。
クラス Colorの中に、今までなかった特別なメソッド ~Colorがあります。コンストラクタの書式によく似ていますが、先頭にチルダ("~")が付加されています。これがデストラクタで、オブジェクトを解体するときに呼び出されるメンバ関数です。仮想関数を持った抽象クラスでは、後始末する必要がない場合でも必ず仮想デストラクタが必要になります。デストラクタが仮想関数であるということがポイントで、例えば、基底クラスへのポインタまたはリファレンスを使って派生クラスのオブジェクトがある関数に渡されていたとき、その関数内でオブジェクトが解体されたとしたら、派生クラス用のデストラクタを呼び出す必要があります。しかし、基底クラスのデストラクタが仮想関数でない場合は基底クラス用のデストラクタが呼び出され、派生クラス用のものは呼び出されないため、正しい解体処理が行なわれない可能性が生じます。
多相性をうまく利用すれば、オブジェクトを利用しているプログラムに手を加えることなく新たな機能を追加することが可能になります。この仕組みは何となく関数ポインタの機構とよく似ていることに気付きませんか?
仮想関数はどのように実現されているのでしょうか? C言語において、関数ポインタを利用すれば、任意の機能に切り替えることができます。この仕組みを応用すれば、仮想関数も実現できそうな気がします。
よく利用される実装方法として、「仮想関数テーブル(Virtual Method Table)」と呼ばれる関数ポインタ用のテーブルをクラス毎に用意して、オブジェクトの中に仮想関数テーブルへのポインタを保持するやり方があります。オブジェクトの仮想関数を呼び出す側は、その中でどんな処理をしているかは意識することなく、決められた場所にある参照先の関数を呼び出すだけになります。
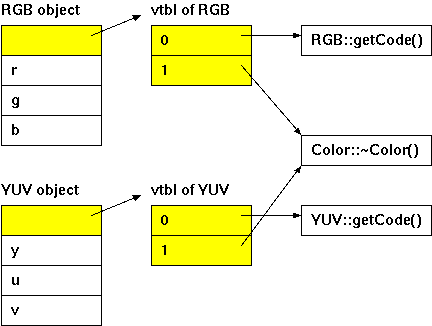
C++でなく C言語で多相性を実現するため、上記のような実装方法を利用する手段があります。構造体の中に仮想関数テーブルへのポインタを用意しておいて、派生クラス用の仮想関数テーブルを作成しておけば、参照先を変更することで異なる機能を持ちながら同じ型の構造体が作成できます。
以下に、構造体を利用した多相化の例を示します。
typedef unsigned char UChar; typedef struct _Color Color; /* 基底クラス Color */ typedef struct _Color_VTable Color_VTable; /* 仮想関数テーブル */ /* 仮想関数テーブルの定義 */ struct _Color_VTable { unsigned int (*getCode)( Color* ); /* getCode仮想関数 */ }; /* 基底クラス Colorの定義 */ struct _Color { Color_VTable* vtbl; /* 仮想関数テーブルへのポインタ */ void* memArg; /* メンバ変数へのポインタ */ }; /* 派生クラス RGBの定義 */ typedef struct RGB { UChar r; UChar g; UChar b; } RGB; /* 派生クラス RGB用のgetCode仮想関数 */ unsigned int RGBgetCode( Color* col ) { RGB* rgb = (RGB*)( col->memArg ); return( ( rgb->r << 16 ) | ( rgb->g << 8 ) | rgb->b ); } /* 派生クラス YUVの定義 */ typedef struct YUV { double y; double u; double v; } YUV; /* 派生クラス YUV用のgetCode仮想関数 */ unsigned int YUVgetCode( Color* col ) { YUV* yuv = (YUV*)( col->memArg ); double r = yuv->y + 1.4020 * yuv->v; double g = yuv->y - 0.3441 * yuv->u - 0.7139 * yuv->v; double b = yuv->y + 1.7718 * yuv->u - 0.0012 * yuv->v; return( ( (UChar)r << 16 ) | ( (UChar)g << 8 ) | (UChar)b ); } int main( int argc, char* argv[] ) { /* 仮想関数テーブル */ Color_VTable rgbVtbl = { RGBgetCode, }; Color_VTable yuvVtbl = { YUVgetCode, }; /* メンバ変数の初期化 */ RGB rgbArg = { 0, 1, 2 }; YUV yuvArg = { 0.0, 1.0, 2.0 }; /* インスタンス化 */ Color rgb = { &rgbVtbl, &rgbArg }; Color yuv = { &yuvVtbl, &yuvArg }; /* 色コードの出力 */ printf( "rgb=%d\n", ( *( ( rgb.vtbl )->getCode ) )( &rgb ) ); printf( "yuv=%d\n", ( *( ( yuv.vtbl )->getCode ) )( &yuv ) ); return( 0 ); }
構造体 Colorは基底クラスを表し、仮想関数テーブルとメンバ変数へのポインタをその中に持っています。構造体 RGBと YUVは派生クラスを表し、それぞれ専用のメンバ変数を有します。RGBgetCodeと YUVgetCodeはそれぞれ RGB、YUV専用の仮想関数になります。
メインルーチンでは Color型の二つの変数 rgbと yuvを用意しています。それぞれには専用の仮想関数テーブルとメンバ変数で初期化して、仮想関数 getCodeを呼び出しています。この構成が、先に説明した仮想関数テーブルによる実装方法とよく似ていることに注意してください。
多相性を実現する方法は他にもいくつか考えられると思います。特に、Gtk+の実装方法などは参考になるのではないでしょうか(昔、Web上で読んだ記憶がありますが、内容は忘れてしまいました)。しかし、オブジェクト指向言語がいくらでも利用できる今となっては、勉強用途以外ではあまり必要ではないようにも思います。
具象型の場合、オブジェクトどうしの加算や減算などを行なうことがよくあります。例えば、複素数を表現するクラスを作成したとき、複素数どうしでの演算処理は当然必要になるわけです。この時、通常の組み込み型で使われる表記方法で演算ができれば、非常に便利な上に、プログラムが見やすくなります。
C++では、演算子の多重定義が可能です。つまり、加算処理に対して専用のメンバ関数 addを呼び出す表現を用いる代わりに、c0 += c1のように表現することができます。前に紹介した Coordクラス内のメンバ関数には加算・減算処理や座標値の比較関数があったので、これらを次のように書き換えます。
class Coord { // メンバ変数 int x; int y; public: // コンストラクタ Coord( int _x = 0, int _y = 0 ) : x( _x ), y( _y ) {} // メンバ関数 Coord& operator+=( const Coord& c ) { x += c.x; y += c.y; return( *this ); } Coord& operator-=( const Coord& c ) { x -= c.x; y -= c.y; return( *this ); } bool operator==( const Coord& c ) const { return( x == c.x && y == c.y ); } bool operator!=( const Coord& c ) const { return( ! ( *this == c ) ); } };
オブジェクトを使って加算・減算する場合は、次のように表記します。
c0 += c1; // c0にc1を加算 *cp -= c0; // *cpからc0を減算 if ( c1 == origin ) {...} // c1とoriginが等しいか
operator+=と operator-=の関数定義の中で、"return( *this )"と記述してあるところがあります。thisは自分自身へのポインタを示しており、"return( *this )"は「自分自身へのリファレンスを返す」という意味になります。これだけではわかりづらいと思いますが、例えば c0 += c1の処理時は c0へのリファレンスが戻り値として返されるので、
のような書き方ができるようになります。この場合、c0 -= c1の処理でc0へのリファレンスが戻り値として得られ、それを c0へ加算していることになります。演算子の多重定義を行なう場合、自分自身へのリファレンスを返すのが一般的な書き方です。
ちなみに、operator...の表記も利用可能で、上式は次のように書き表すこともできます。
同様に、operator!=の定義は、次のいずれかで書き表すことができます。
return( ! (*this).operator==( c ) );
return( ! this->operator==( c ) );
さらに、自分自身へのポインタは省略できるので、次の様にも記述できます。
自分自身のメンバ関数を利用するときは、最後に示した書き方をするのが一般的です。しかし、演算子の多重定義を利用する場合、サンプル・プログラムに示した書き方の方が見やすい場合もあります。このあたりは、好みの問題だと思います。
演算子の多重定義の中で、オブジェクトに対して関数呼び出し構文を付加するためのメンバ関数 operator()があります。例えば、Coordクラスに対して
void operator()() { print( "(%d,%d)\n", x, y ); }
というメンバ関数を追加すると、c0()と記述することで座標値を表示することができます。オブジェクトを関数のように扱うことができるわけです。
関数ポインタを利用すれば、必要に応じて機能の異なる処理を行なうことができることを最初に説明しました。しかし、渡すことのできる引数が決まっているため、少し特殊な用途に利用しようとしたときに実現が困難な場面もよく発生します。例えば、線分描画のために点を描く関数を複数用意して、それらの関数ポインタを利用した切り替えができるようにしたとします。通常、点を描画するためには座標値と色コードが必要なので、引数もそれらを用意することにします。
通常の点描画であればこれで過不足はありません。しかし、例えば色反転させた点を描画する場合、座標値で指定した点の色コードで描画色が決定するので、色コードを引数として渡すことは不要であり、二番めの引数は余分になります。余分になるのならまだいいのですが、算出した座標値を配列に取り込むような処理をしたい場合、今度は引数が足りないことになるので、実現はできないことになります。
このような場合に対処するためには、どんなパラメータにも対応できるような引数を用意する必要があります。
第二引数の型は void*なので、任意の型のポインタを渡すことができます(複数のパラメータを渡すことも可能です)。しかし、パラメータの内容は各関数により異なるため、どんなデータを渡せばいいのか呼び出し側で把握しておく必要があります。もし誤ったデータを渡してしまったら、処理が正しく行なわれず、最悪ハングしてしまう可能性もあるわけです。
どんなパラメータにも対処できるようにしながら、安全に処理することができるようにするための方法として、抽象型を利用する方法があります。
/* 点描画用基底クラス */ class PSetBase { public: virtual void pset( const Coord& ) = 0; // 点描画 virtual ~PSetBase() {} // 仮想デストラクタ }; /* 任意の色の点を描画する */ class PSet : public PSetBase { unsigned int col; // 色コード public: // コンストラクタ PSet( unsigned int _col ) : col( _col ) {} void pset( const Coord& ); // 点描画 }; /* 色反転した点を描画する */ class NotSet : public PSetBase { public: void pset( const Coord& ); // 点描画 }; /* 座標を配列に取り込む */ class PGet : public PSetBase { Coord* colArray; // 座標を取り込む配列の先頭ポインタ unsigned int index; // 現在の取り込み位置 unsigned int size; // 配列の大きさ public: // コンストラクタ PGet( Coord* _colArray, unsigned int _size ) : colArray( _colArray ), index( 0 ), size( _size ) {} void pset( const Coord& ); // 点描画 };
線分描画ルーチンへ PSetBaseへのポインタかリファレンスを渡して、点描画で psetを呼び出してやれば、必要に応じた適切な処理を行なうことができるようになります。このようなオブジェクトは関数呼び出しに特化したオブジェクトになるので、「関数オブジェクト(Function Object)」と呼ばれています。
PSetBaseの派生クラスのオブジェクト psetからメンバ関数の psetを呼び出すときは、次のように記述します。
こう書くと、同じ語句が二つ並んで何だか冗長な感じがします。そこで、演算子の多重定義を利用して psetを operator()に置き換えます。
すると、オブジェクトが関数であるかのように記述することができるようになります。
線分描画のテスト用プログラムをアップロードしておきます。ご自由におつかいください。Vine Linux 4.2上で動作確認をしています(Gtk+2が必要です)。
操作マニュアルは特に用意していませんが、適当にクリックしてみればどんな動きをするかはすぐにわかると思います。
この章では、関数ポインタからオブジェクト指向言語、さらに関数オブジェクトまでの概要を説明してきました。しかし、細かい点については省略したり、まだ紹介していない便利な機能もあったりします。例えば、Template(または Generics)や例外処理などは非常に便利で重要な機能です。関数呼び出しの内容を中心に、最も重要と思われる箇所に重点を置いて書いたつもりが、やはりどうしても書いておかないとダメな部分が他にもあって、思っていたよりもボリュームが大きくなってしまいました。参考にした文献.1はさらに詳細な内容を含んでおり、言語を越えた一般的なプログラミング技法に関しても記述されているので、興味のある方は是非一読を勧めます(少々高価ですが)。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |