 |
JPEG 法では DCT 変換結果の符号化に「ハフマン圧縮」を利用していたのに対し、JPEG2000 はウェーブレット変換の結果を「算術符号化 ( Arithmetic Coder )」で符号化しています。この章では、算術符号化の原理について説明した後、算術符号化の一種である「Range Coder」と「Q-Coder」を紹介します。
算術符号化の説明に入る前に、ハフマン符号化について復習しておきます。ハフマン符号化では、出現率の高いデータに短い符号、逆に出現率の低いデータに長い符号を割り当てることによってデータを圧縮していました。例えば 100 個のデータのうち 99 個が a、残り 1 個が b だった場合、a に 1 ビットの符号 '0'、b に 1 ビットの符号 '1' を割り当てることで、全体のデータ長を 100 ビットで表すことができることになります。
ここで、ハフマン符号化の章で紹介した「エントロピー」と言う概念を使って、圧縮可能なビット数の理論限界値を求めてみます。データ x が配列中で出現する確率を P(x) としたとき、エントロピーの計算式は、
なので、上記の例では
となり、理論的には全体のデータ長を約 8 ビット程度にまで圧縮できることになります。しかし、ハフマン符号化では符号列のビット数が必ず整数値となるため、理論値とは程遠い結果となってしまいます。
なお、ハフマン圧縮を使って理論値に近づけるための方法として、データのグルーピングというものがあります。上記の例で、例えばデータ列を二つずつペアにした場合、出現するデータは aa と ab ( または ba ) のいずれかになります。これを符号化すると、全体のデータ長は 50 ビットとなり、データ一つずつを符号化する場合に比べて圧縮率を高めることができます。まとめるデータの数を増やせばそれだけ圧縮率は高く可能性がありますが、逆に各データの出現頻度が小さくなりすぎて圧縮率が下がる要因にもなります。データをどの程度まとめれば最適なのかはデータにも依存するため、汎用的に利用するのは困難です。
整数値の符号長しか使うことができないというハフマン符号化の問題をクリアする符号化として「算術符号化 ( Arithmetic Coder )」が登場しました。算術符号化は、先ほど説明したデータのグルーピングという考え方を発展させて、データ列全体を一つの符号列として置き換える方法です。データ列を 0 と 1 の間の有理数で表し、符号化と復号化に算術演算を利用するため、この名称が付きました。
算術符号化のアルゴリズムを、データ列の例として、abacab を使って説明したいと思います。このデータ列の出現率は
| a | 1/2 |
| b | 1/3 |
| c | 1/6 |
となるため、ハフマン符号化を使った場合は a を 1 ビット、b を 2 ビット、c を 3 ビットで表すことで、計 10 ビットに圧縮することができます。
算術符号化では、まず 0 から 1 までの数直線上に、各データを出現率の幅だけ空けて並べておきます。
|
ここで、数直線上で割り当てた範囲の最小値で各データを表すことにすると、a は 0、b は 0.5 ( = 1 / 2 )、c は 0.833... ( = 5 / 6 ) になります。最初のデータは a になるので、これを数直線上の 0 として表すことにします。
二番目のデータを加えると ab になりますが、これを数直線上で表すために、上記数直線上の a の範囲 ( 0 〜 1 / 2 ) に、前回同様各データを出現率の幅だけ空けて並べます。
 |
b は数直線上で 0.25 ( = 1 / 4 ) で表されているため、データ列 ab は数直線上の 0.25 と表すことにします。さらに ab の範囲 ( 1 / 4 〜 5 / 12 ) に、各データを出現率の幅だけ空けて並べます。この操作を繰り替えしていきます。
 |
上記の方法で六つのデータを順に符号化した結果、データ列 abacab は、数直線上の 93 / 288 ( = 0.3229... ) で表すことができることになります。また数直線を見ると、他のデータ列に関してもそれぞれ決められた数値を持つことが分かると思います ( 例えば abacaa は 23 / 72 になります )。このように、算術符号化によってデータ列は 0 から 1 の間の有理数に置換されることになるわけです。
符号化された値は有理数なので、場合によっては割り切れない場合も発生します。また割り切れたとしても桁数が大量になると圧縮率は低下してしまいます ( 元のデータ量より多くなる可能性の方が大きくなります )。そこで問題になるのが、いったい何桁分まで保持すべきかということになりますが、符号化された数値が一意のデータ列を表している以上、他の符号と区別ができる分の桁数を保持すればいいことになります。例えば上記の例では、対象のデータ列である abacab が 93 / 288、次のデータ列 abacac が 281 / 864 なので、その差は 281 / 864 - 93 / 288 = 1 / 432 となり、1 / 1000 の精度まであれば区別ができます。このとき、小数点以下第 4 位以降を切り捨てて、abacab は 0.322、abacac は 0.325 になります。
復号処理は、符号化のときと同様に 0 から 1 までの数直線を用意して、符号の値がどの範囲にあるかを調べます。上記の例では、0.322 は 0 と 1/2 の間にあるので、最初のデータは a ということになります。次にデータ a が持つ範囲 0 〜 0.5 に出現率の幅分データを並べる操作も符号化と全く同じです。すると 0.322 は 1 / 4 と 5 / 12 の間になるので、二番目のデータは b となります。これを繰りかえすと、データを復号することができます。
もう一つの問題は、どこまで復号化を行えばいいかということです。上記方法で処理を行った場合、符号化された値は無限に復号化することができてしまいます。どこで処理を止めればいいか、なんらかの方法で持っておく必要がありますが、一番簡単な方法としては、データ数をあらかじめ持っておくやり方が考えられます。
さらにもうひとつ、大きな問題があります。コンピュータは通常、浮動小数点数の演算をサポートしていますが、浮動小数点数は有効桁数に制限があるため、今回のようにデータ量によって大量の桁数が必要となるような場合には利用できません。通常の数値演算処理が使用できないので新たに演算用のプログラムを用意する必要があります。しかし、まともに全桁に対して演算処理を行えば、桁数が増える毎に処理時間は増大してしまい実用的なプログラムにはなりません。下位の桁に対してのみ演算を行い、オーバーフローしたら上位の桁の数を変更するような処理が必要となります。
ハフマン符号化に比べて圧縮率が高いという利点があるものの、上記問題に特許問題も加わって、算術符号化はあまり普及しませんでした。後で紹介する「Range Coder」の登場により、ようやく利用され始めたというのが現実のようです。
ところで、この方法で本当に圧縮ができるのか不思議に思うかもしれません。圧縮率は、他の符号と識別可能な精度に依存します。上記の例では各符号との値の幅は 1 / 432 でしたが、これを二進数で表すと 1 / 110110000 になるため、9 ビットの符号で表せることになります。元の符号は三種類のデータを持っているので、最低でも一つのデータに対して 2 ビットは必要になります。つまり元のデータは ( なんらかの符号化をしていない限り ) 最低でも 2 x 6 = 12 ビットは必要になり、確かに圧縮されていることになります。
0 と 1 が等しい頻度で発生するデータ列があるとします。どちらのデータが出現しても、数直線の幅は常に 1 / 2 ( 二進数で 1 / 10 ) ずつ小さくなるため、必要な精度は毎回 1 ビットずつ増えていくことになります。つまりこのときは、全く圧縮がされないことになります。
しかし、例えば 0 の出現頻度が 1 / 100、1 のそれが 99 / 100 である場合、1 が出現しても数直線の幅に大きな変化は表れません。つまり符号を識別するための精度も少なくすることができ、結果的に圧縮できることになります。
出現する確率がpであるデータを符号化したとき、他の符号と識別するために必要な精度を確保するために
の量のビットを出力する必要があります。出現頻度が 1 / 2 ならば 1 ビット出力しなければなりませんが、出現頻度が 99 / 100 ならば約 0.0145 ビットを出力するだけで済みます。ハフマン符号化と同様に、出現率の高いデータは少ない情報量で表していることになるわけです。
前の章でも述べたように、符号を表す数直線上の値を算出するためには通常の演算以外の方法を使う必要があります。算術圧縮時に利用する方法として、ある精度まで到達した時点で数値を定数倍 ( 例えば 10 倍 ) して、オーバーフローした分だけ出力する処理がよく用いられます。このとき、数値を定数倍すると同時に数直線上の範囲の幅も同じ定数を掛ける必要があります。
「Range Coder」ではさらに、符号化と復号化を高速に行うためデータの入出力をビット単位ではなくバイト単位にし、かつ整数演算処理のみを使います。基本的な処理方法は算術圧縮法と変わりませんが、算術圧縮法の特許が認可される前にこの方法が論文によって発表されていたため、特許フリーの算術圧縮法として注目されました。
「Range Coder」では、数直線の幅 ( 以下 Range と略します ) を 1 ではなく大きな整数で初期化します。データを一つ読み込んだ後、符号と Range を計算する仕組み自体は算術符号化と変わりませんが、整数演算を用いて計算されるところが異なります。具体的には、データの大きさを Size、読み込んだデータの出現回数を Count、累積出現回数 ( 前のデータの出現回数の総和 ) を Accum としたとき、
新たな符号 = 現在の符号 + ( Range / Size ) * Accum
Range = ( Range / Size ) * Count
として計算することができます。
処理を進めるうちに、Range の値は小さくなっていきます。よって、ある定数値より小さくなったら、符号と Range を定数倍します。つまり、数直線を定数倍して大きくすることで精度を保つわけです。符号を定数倍するとオーバーフローしてしまうため、上位ビットは符号列として出力して切り捨てます。
「Range Coder」による符号化の例を、算術符号化のときに使ったデータを利用して示します。
| データ | 出現回数 | 累積出現回数 |
|---|---|---|
| a | 3 | 0 |
| b | 2 | 3 |
| c | 1 | 5 |
| データ | 符号 | Range |
|---|---|---|
| 初期値 | 0 | 100 |
| a | 0 + (100/6) x 0 = 0 | (100/6) x 3 = 48 |
| b | 0 + (48/6) x 3 = 24 | (48/6) x 2 = 16 |
| a | 24 + (16/6) x 0 = 24 | (16/6) x 3 = 6 |
| Rangeを10倍 | 240 | 60 |
| 符号の3桁目(2)を出力 | 40 | 60 |
| c | 40 + (60/6) x 5 = 90 | (60/6) x 1 = 10 |
| a | 90 + (10/6) x 0 = 90 | (10/6) x 3 = 3 |
| Rangeを10倍 | 900 | 30 |
| 符号の3桁目(9)を出力 | 0 | 30 |
| b | 0 + (30/6) x 3 = 15 | (30/6) x 2 = 10 |
Range Coder符号化処理による数直線の変化は、以下のようになります。
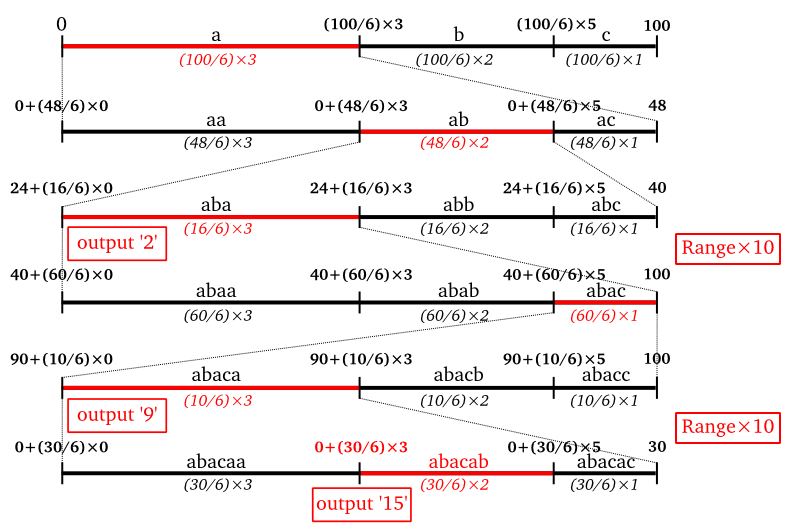 |
上記の例では Range の初期値を 100 としています。Range が 10 より小さくなったら符号と Range を 10 倍し、符号の 3 桁目を符号列に出力します。最後のデータまで符号化を行ったら、その時点での符号を符号列に出力して処理を完了します。この処理で、符号は '2915' になりました。
復号化処理でも、Range の初期値は符号化と同じ値を使います。また、符号化したデータの先頭の値を取得して、それを符号の初期値とします。符号を Range / Size で割り、その値を累積出現回数と比較して、範囲内にあったデータを復号化されたデータとして出力した後、符号と Range を以下の式で再計算します。
新たな符号 = 現在の符号 - ( Range / Size ) * 復号したデータの累積出現回数
Range = ( Range / Size ) * 復号したデータの出現回数
「( Range / Size ) * 復号したデータの累積出現回数」は、それまでに復号化したデータを表す数直線上の値になるため、新たな符号はそれと現状の符号との誤差を示しています。この誤差を、次の復号のために使用するわけです。言葉では説明が難しいのですが、下記の例で示した図を見れば容易に理解できると思います。
符号化の場合と同様に、Range がある値より小さくなったら符号と Range を定数倍します。また、符号は定数倍した後、符号データから下位ビットを補うことで必要な精度を保ちます。
| 符号/(Range/Size) | 出力データ | 符号 | Range |
|---|---|---|---|
| 初期値 | 29 | 100 | |
| 29 / (100/6) = 1 | a | 29 - (100/6) x 0 = 29 | (100/6) x 3 = 48 |
| 29 / (48/6) = 3 | b | 29 - (48/6) x 3 = 5 | (48/6) x 2 = 16 |
| 5 / (16/6) = 2 | a | 5 - (16/6) x 0 = 5 | (16/6) x 3 = 6 |
| Rangeを10倍 | 50 | 60 | |
| 符号データから下位ビットを取得 | 51 | 60 | |
| 51 / (60/6) = 5 | c | 51 - (60/6) x 5 = 1 | (60/6) x 1 = 10 |
| 1 / (10/6) = 1 | a | 1 - (10/6) x 0 = 1 | (10/6) x 3 = 3 |
| Rangeを10倍 | 10 | 30 | |
| 符号データから下位ビットを取得 | 15 | 30 | |
| 15 / (30/6) = 3 | b | 15 - (30/6) x 3 = 0 | (30/6) x 2 = 10 |
Range Coder 復号化処理による数直線の変化は、以下のようになります。
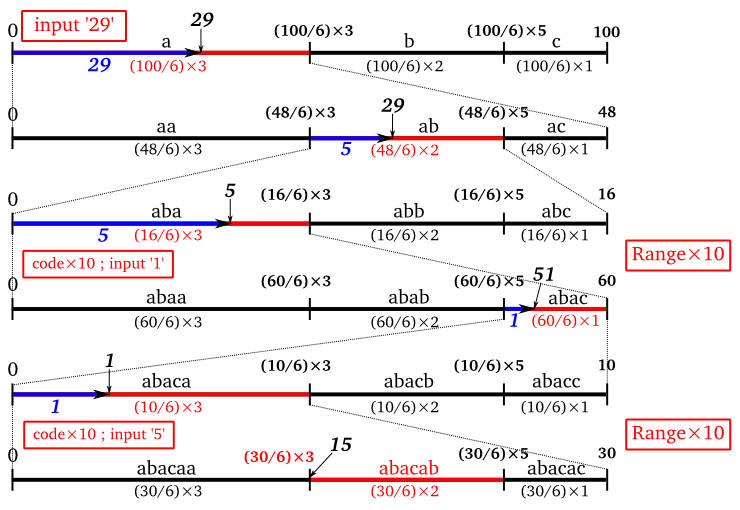 |
復号化の場合、数直線は常に 0 から Range までの範囲になります。符号が数直線上のどこに位置しているのかをチェックして、Range を復号化されたデータが持つ範囲に変換するところは、やはり算術符号化での処理と本質的に変わりありません。
処理方法は以上になりますが、ここでいくつかの問題を解決する必要があります。まず一つは、符号化と復号化での計算で使用している変数 Range / Size がゼロになる可能性があるということで、このときは Range を計算した結果が 0 になってしまうため処理を続けることができなくなります。よって、Range の取り得る最小値はデータのサイズより大きくなければなりません。Range / Size がゼロになった場合、サンプル・プログラムでは単純にエラー終了しています。Range の最小値は、以下に示すサンプル・プログラム内の定数値 RANGE_CODER_MIN_RANGE で定義されており、この大きさのデータまでは処理が可能であるということになります。
もう一つの問題は、符号化処理時に新たな符号を計算する際、オーバーフローが発生する可能性があると言うことです。処理の流れから見て、符号は Range の最大値を越えることはできません。もし越えた場合、オーバーフローした場合のビットは捨てられてしまうことになります。サンプル・プログラムでは、符号の上位 1 ビットをキャリー・ビットとして、Range と符号を定数倍する前にキャリー・ビットをチェックし、1 が立ったらそのビットを前の符号に加算する処理を行っています。前の符号の全ビットが立っている状態である場合、さらにその前の符号に加算する処理を続ける必要があります。
この現象は、符号の最上位ビットが立っていた場合に発生します。次に加算される値は最大で Range に等しくなるので、1 ビットだけはみ出す可能性があり、この時に更新が必要となります。しかし、それ以上はみ出すことはないので、1 ビットのみを考慮すれば十分です。
以下に、サンプル・プログラムを示します。
/* Range Coder用パラメータ */ typedef unsigned long long int CodeType; // code・range の型 const CodeType ONE = 1; const unsigned int RANGE_CODER_RANGE_BIT_SIZE = sizeof( CodeType ) * CHAR_BIT - 1U; // rangeのビット数 const unsigned int RANGE_CODER_MAX_DATA_BIT_SIZE = ( sizeof( CodeType ) - 1U ) * CHAR_BIT; // 最大データサイズのビット数 const CodeType RANGE_CODER_INIT_RANGE = ONE << RANGE_CODER_RANGE_BIT_SIZE; // rangeの初期値 const CodeType RANGE_CODER_MIN_RANGE = ONE << RANGE_CODER_MAX_DATA_BIT_SIZE; // rangeが取り得る最小値 const CodeType RANGE_CODER_MAX_CODE = RANGE_CODER_INIT_RANGE; // codeの最大値 const CodeType RANGE_CODER_RANGE_MASK = RANGE_CODER_INIT_RANGE - ONE; // range用のマスクパターン /* CountData : バイト列 data に対し、データの出現頻度をカウントして counter に登録する */ void CountData( const vector< unsigned char >& data, vector< size_t >* counter ) { // 出現頻度の初期化 counter->assign( UCHAR_MAX + 1, 0 ); for ( vector< unsigned char >::const_iterator cit = data.begin() ; cit != data.end() ; ++cit ) ++( ( *counter )[*cit] ); } /* 出現頻度データ counter の累積出現頻度を計算して accum に登録する 戻り値 : 出現頻度の総数 */ size_t AccumCount( const vector< size_t >& counter, vector< size_t >* accum ) { // 累積出現頻度の初期化 accum->assign( UCHAR_MAX + 1, 0 ); for ( vector< size_t >::size_type i = 1 ; i < accum->size() ; ++i ) (*accum)[i] = (*accum)[i-1] + counter[i-1]; return( accum->back() + counter.back() ); } /* 符号のオーバーフロー分が符号の先頭まで達した場合のリフレッシュ encode : 符号列 bufferCnt : バッファ部分に登録されているビット数 戻り値 : バッファ部分の新たな登録ビット数 */ size_t RefleshOverflowData( vector< unsigned char >* encode, size_t bufferCnt ) { bool lsb = true; const unsigned char msb = 1 << ( CHAR_BIT - 1 ); for ( vector< unsigned char >::size_type i = 0 ; i < encode->size() - 1 ; ++i ) { unsigned char buff = (*encode)[i]; (*encode)[i] >>= 1; if ( lsb ) (*encode)[i] |= msb; lsb = ( ( buff & 1 ) != 0 ); } if ( bufferCnt >= CHAR_BIT ) { encode->push_back( 0 ); bufferCnt = 0 ; } if ( lsb ) encode->back() |= 1 << bufferCnt; else encode->back() &= ( 1 << bufferCnt ) - 1; return( bufferCnt + 1 ); // リフレッシュした場合はバッファのサイズが一つ増える } /* 符号のオーバーフロー分を、前の符号に加える encode : 符号列 bufferCnt : バッファ部分に登録されているビット数 戻り値 : バッファ部分の新たな登録ビット数 */ size_t AddOverflowData( vector< unsigned char >* encode, size_t bufferCnt ) { // 最初にバッファ部分に加算する CodeType i = encode->back() + 1; encode->back() = i & ( ( ONE << bufferCnt ) - 1 ); // バッファもオーバーフローしている場合、その前の符号にも加算する if ( i >= ( 1U << bufferCnt ) ) { vector< unsigned char >::size_type index = encode->size() - 1; // 次に処理するインデックスの一つ後 do { if ( index-- == 0 ) // すでに先頭までたどったらリフレッシュ return( RefleshOverflowData( encode, bufferCnt ) ); i = (*encode)[index] + 1; (*encode)[index] = i & UCHAR_MAX; } while ( i > UCHAR_MAX ); } return( bufferCnt ); } /* Range Coder符号化 data : 符号化対象のデータ列 encode : 符号化データを保持する配列 counter : データの出現頻度 accum : データの累積出現頻度 */ void RangeEncode( const vector< unsigned char >& data, vector< unsigned char >* encode, const vector< size_t >& counter, const vector< size_t >& accum ) { /* code = 0 +----------------------------------------+ <---- range = RANGE_CODER_INIT_RANGE ----> */ CodeType range = RANGE_CODER_INIT_RANGE; CodeType code = 0; size_t bufferCnt = 0; // バッファ(データ末尾)に登録されているデータの幅 size_t size = data.size(); encode->assign( 1, 0 ); for ( vector< unsigned char >::const_iterator c = data.begin() ; c != data.end() ; ++c ) { CodeType unit = range / size; // データ間の幅の単位 if ( unit == 0 ) throw std::runtime_error( "Calculation results of the variable \"unit\" is zero." ); /* code(c) code(c+1) +----------------+------------------------------+ <- accum * unit -> <--- range = counter * unit ---> ( unit = range / size ) */ code += unit * accum[*c]; range = unit * counter[*c]; // オーバーフロー時の処理 if ( code >= RANGE_CODER_MAX_CODE ) { bufferCnt = AddOverflowData( encode, bufferCnt ); code -= RANGE_CODER_MAX_CODE; } // 符号の書き込み while ( range < RANGE_CODER_MIN_RANGE ) { if ( bufferCnt >= CHAR_BIT ) { encode->push_back( 0 ); bufferCnt = 0; } encode->back() = ( encode->back() << 1 ) + ( ( code >> ( RANGE_CODER_RANGE_BIT_SIZE - 1 ) & 1 ) ); code = ( code << 1 ) & RANGE_CODER_RANGE_MASK; range <<= 1; ++bufferCnt; } } // 残りの符号を書き込み for ( size_t i = 0 ; i < RANGE_CODER_RANGE_BIT_SIZE ; ++i ) { if ( bufferCnt >= CHAR_BIT ) { encode->push_back( 0 ); bufferCnt = 0; } encode->back() = ( encode->back() << 1 ) + ( ( code >> ( RANGE_CODER_RANGE_BIT_SIZE - 1 ) & 1 ) ); code <<= 1; ++bufferCnt; } if ( bufferCnt > 0 ) encode->back() <<= ( CHAR_BIT - bufferCnt ); } /* 復号データの検索 code : 符号 accum : データの累積出現頻度 戻り値 : 復号したデータ */ inline unsigned char FindDecodeData( CodeType code, const vector< size_t >& accum ) { // *cit <= code となる位置を探索する vector< size_t >::const_iterator cit = std::upper_bound( accum.begin(), accum.end(), code ); // cit が先頭になることはありえない if ( cit == accum.begin() ) throw std::runtime_error( "Can't find data from code ( code is too little )." ); return( std::distance( accum.begin(), cit ) - 1 ); } /* バッファに符号列の要素をひとつ読み込む encode : 符号列 cit: 次のバッファ位置へのポインタ buffer : 読み込んだ符号列を登録するバッファへのポインタ bufferCnt : バッファ内に登録されたビット数 戻り値 : すでに全バッファを読み終えていたら false を返す */ bool GetBuffer( const vector< unsigned char >& encode, vector< unsigned char >::const_iterator* cit, unsigned char* buffer, size_t* bufferCnt ) { if ( *cit == encode.end() ) return( false ); *buffer = **cit; ++( *cit ); *bufferCnt = 0; return( true ); } /* Range Coder復号化 encode : 符号列 data : 複合したデータを保持する配列へのポインタ counter : データの出現頻度 accum : データの累積出現頻度 size : データ列のサイズ 戻り値 : 復号に必要な符号が encode から取得できなくなったら false を返す */ bool RangeDecode( const vector< unsigned char >& encode, vector< unsigned char >* data, const vector< size_t >& counter, const vector< size_t >& accum, size_t size ) { CodeType range = RANGE_CODER_INIT_RANGE; CodeType code = 0; CodeType unit; unsigned char buffer = 0; size_t bufferCnt = 8; data->clear(); // 符号の取り込み vector< unsigned char >::const_iterator cit = encode.begin(); for ( size_t i = 0 ; i < RANGE_CODER_RANGE_BIT_SIZE ; ++i ) { if ( bufferCnt >= CHAR_BIT ) if ( ! GetBuffer( encode, &cit, &buffer, &bufferCnt ) ) return( false ); code = ( code << 1 ) + ( buffer >> ( CHAR_BIT - 1 ) ); buffer <<= 1; ++bufferCnt; } // データの抽出 for ( size_t i = 0 ; i < size ; ++i ) { unit = range / size; if ( unit == 0 ) throw std::runtime_error( "Calculation results of the variable \"unit\" is zero." ); unsigned char c = FindDecodeData( code / unit, accum ); data->push_back( c ); code -= unit * accum[c]; range = unit * counter[c]; // Range が小さくなったら二倍してバッファを更新 while ( range < RANGE_CODER_MIN_RANGE ) { if ( bufferCnt >= CHAR_BIT ) if ( ! GetBuffer( encode, &cit, &buffer, &bufferCnt ) ) return( false ); code = ( code << 1 ) + ( buffer >> ( CHAR_BIT - 1 ) ); buffer <<= 1; ++bufferCnt; range <<= 1; } } return( true ); }
符号や Range の型として CodeType を定義しています。この型はサンプル・プログラムでは unsigned long long int としているので、x86 系 Linux 上でなら 32bit/64bit のどちらも 8 バイト ( 64 ビット ) となります。この型を利用して、二つの定数 RANGE_CODER_RANGE_BIT_SIZE と RANGE_CODER_MAX_DATA_BIT_SIZE が定義され、前者は Range の取りうる値、後者は最大データサイズをそれぞれ二進数で表した時の桁数 ( ビット数 ) を意味します。CodeType 型が 8 バイトなら、
RANGE_CODER_RANGE_BIT_SIZE = 8 x 8 - 1 = 63
RANGE_CODER_MAX_DATA_BIT_SIZE = ( 8 - 1 ) x 8 = 56
という値になり、この値から Range の初期値 RANGE_CODER_INIT_RANGE = 263 と最小値 RANGE_CODER_MIN_RANGE = 256 としています。また、符号の取りうる最大値 RANGE_CODER_MAX_CODE は RANGE_CODER_INIT_RANGE と等しく 263 となります。
符号化を行う前に、各データの出現回数と累積出現回数を求める必要があります。これはそれぞれ関数 CountData と AccumCount で行います。なお、このデータは符号化処理だけではなく復号化処理でも必要となるので、その分だけデータ量は増えてしまうことになります。各データの出現回数と累積出現回数が得られたら、対象のデータ列と併せて関数 RangeEncode にて符号化を行います。処理に先立って、Range を初期値 RANGE_CODER_INIT_RANGE で初期化し、符号 code をゼロとします。また、バッファ用の要素だけを符号列に用意し、その値はゼロクリアしておきます。ループ処理に入ったら、前述で示した計算式にて code と Range を更新します。
code = code + ( データの累積出現回数 ) x Range / ( データの総数 )
Range = Range ( データの出現回数 ) / ( データの総数 )
更新後、符号のビットがはみ出していたら AddOverflowData を使ってバッファにそのビットを加算します。このとき、バッファ自体もオーバーフローする可能性があるので、そのときはさらに符号列の前にさかのぼって加算を繰り返さなければなりません。さらに、先頭までオーバーフローを繰り返してしまう最悪の場合を想定して、そのときのための関数 RefleshOverflowData を用意しています。この関数は、先頭まであふれてしまったビットを取り込むため今度は先頭から下位側へ 1 ビットずつシフトさせる処理を行います。結果として、先頭だけビットが立った状態であとはバッファを除き全てゼロになるので、かなりの部分の処理を省略することが可能ですが、めったに発生しない現象なのでそのままビットシフト処理をさせるようにしています ( ちなみに、意図的にテストデータを作成して試した以外で発生したことは全くありませんでした )。
なお、この方法は効率が悪いため、次節以降で紹介する「Q-Coder ( MQ-Coder )」では「ビット・スタフィング ( Bit-Stuffing )」という手法を用いてオーバーフローによるビットの伝播を防いでいます。
復号化は RangeDecode で行います。前述の通り、ここでも各データの出現回数と累積出現回数を渡す必要があるので、符号化データの他に保持しておく必要があることに注意が必要です。処理の内容は先に示した通りで、符号から得られるデータの累積出現回数を
で求めて該当するデータを累積出現回数のデータ列から探索します。次に、対象データの累積出現回数を使って
で新しい符号を求め、Range を
で更新します。
ハフマン符号化や LZ 法などで使用したサンプルを使って、Range Coder による符号化処理を評価した結果を以下に示します。まずは「風景」画像からです。
| 画像 | エントロピー (Bits) | Range:63, Data:56 | Range:31, Data:24 | |||||
|---|---|---|---|---|---|---|---|---|
| 符号サイズ (Bytes) | 圧縮率(%) | 実圧縮サイズ (Bits) | 符号サイズ (Bytes) | 圧縮率(%) | 実圧縮サイズ (Bits) | |||
| 画像1 | 7.438 | 2193558 | 92.98 | 7.438 | 2215385 | 93.90 | 7.512 | |
| 画像2 | 7.807 | 2302486 | 97.59 | 7.807 | 2324904 | 98.54 | 7.883 | |
| 画像3 | 7.670 | 2261976 | 95.88 | 7.670 | 2284112 | 96.81 | 7.745 | |
| 画像4 | 7.745 | 2284187 | 96.82 | 7.745 | 2306420 | 97.76 | 7.821 | |
| 画像5 | 7.911 | 2332910 | 98.88 | 7.911 | 2354468 | 99.80 | 7.984 | |
| 画像6 | 7.811 | 2303532 | 97.64 | 7.811 | 2325703 | 98.58 | 7.886 | |
| 画像7 | 7.828 | 2308688 | 97.85 | 7.828 | 2330834 | 98.79 | 7.903 | |
| 画像8 | 7.809 | 2303122 | 97.62 | 7.810 | 2325605 | 98.57 | 7.886 | |
| 画像9 | 7.692 | 2268567 | 96.15 | 7.692 | 2291404 | 97.12 | 7.770 | |
| 画像10 | 7.898 | 2329276 | 98.73 | 7.898 | 2351392 | 99.66 | 7.973 | |
表において、Range の値は Range のビット数を、Data の値は 最大データサイズのビット数をそれぞれ表します。例えば Range:63, Data:56 ならば、Range の初期値は 263 ≅ 9.22 x 1018 で、データの最大数は 263 = 268,435,456 x 268,435,456 になるので十分な大きさがあります。ちなみに 224 = 4096 x 4096 なので、Range:31, Data:24 の場合、巨大な画像を扱うには十分な大きさと言えなくなります。
エントロピーは、各画像のデータ出現回数から求めた理論上の圧縮限界値で、その後に二つのパラメータ Range:63, Data:56, Range:31, Data:24 に対して圧縮後の符号サイズと圧縮率、実際に 1 画素分 ( 8 ビット ) が圧縮されたサイズをそれぞれ示しています。Range:63, Data:56 の場合は、実圧縮サイズが理論値とほぼ一致するため、これ以上の圧縮は望めないことを意味しています。Range:31, Data:24 とした場合に少しだけ圧縮率が落ちているのは精度によるものと考えられます。Range Coder は内部では整数演算を行うため、純粋な算術圧縮法に比較すると誤差が生じ、その誤差分だけサイズが増えるのでしょう。( 誤差といっても変換自体には影響はありません。その誤差も含めて可逆的に変換されるためです )。
以下、「アニメ調」と「アニメ調」GIF 画像についても処理を実施した結果を示しておきます。
| 画像 | エントロピー (Bits) | Range:63, Data:56 | Range:31, Data:24 | |||||
|---|---|---|---|---|---|---|---|---|
| 符号サイズ (Bytes) | 圧縮率(%) | 実圧縮サイズ (Bits) | 符号サイズ (Bytes) | 圧縮率(%) | 実圧縮サイズ (Bits) | |||
| 画像1 | 5.978 | 1762866 | 74.72 | 5.978 | 1779570 | 75.43 | 6.034 | |
| 画像2 | 6.840 | 2017201 | 85.50 | 6.840 | 2039666 | 86.45 | 6.916 | |
| 画像3 | 5.418 | 1597771 | 67.72 | 5.418 | 1619493 | 68.64 | 5.491 | |
| 画像4 | 6.473 | 1908944 | 80.91 | 6.473 | 1931080 | 81.85 | 6.548 | |
| 画像5 | 3.191 | 941125 | 39.89 | 3.191 | 962563 | 40.80 | 3.264 | |
| 画像6 | 7.817 | 2305386 | 97.71 | 7.817 | 2328075 | 98.68 | 7.894 | |
| 画像7 | 6.767 | 1995681 | 84.59 | 6.767 | 2019072 | 85.58 | 6.846 | |
| 画像8 | 6.825 | 2012884 | 85.32 | 6.825 | 2035054 | 86.26 | 6.901 | |
| 画像9 | 4.209 | 1241414 | 52.62 | 4.209 | 1268961 | 53.79 | 4.303 | |
| 画像10 | 7.511 | 2215128 | 93.89 | 7.511 | 2236760 | 94.81 | 7.584 | |
| 画像 | エントロピー (Bits) | Range:63, Data:56 | Range:31, Data:24 | |||||
|---|---|---|---|---|---|---|---|---|
| 符号サイズ (Bytes) | 圧縮率(%) | 実圧縮サイズ (Bits) | 符号サイズ (Bytes) | 圧縮率(%) | 実圧縮サイズ (Bits) | |||
| 画像1 | 3.490 | 1029382 | 43.63 | 3.490 | 1057370 | 44.82 | 3.585 | |
| 画像2 | 4.054 | 1195467 | 50.67 | 4.054 | 1210535 | 51.31 | 4.105 | |
| 画像3 | 1.873 | 552391 | 23.41 | 1.873 | 578957 | 24.54 | 1.963 | |
| 画像4 | 3.314 | 977234 | 41.42 | 3.314 | 997408 | 42.28 | 3.382 | |
| 画像5 | 4.115 | 1213665 | 51.44 | 4.115 | 1239975 | 52.56 | 4.205 | |
| 画像6 | 3.212 | 947265 | 40.15 | 3.212 | 968237 | 41.04 | 3.283 | |
| 画像7 | 1.986 | 585656 | 24.82 | 1.986 | 614733 | 26.06 | 2.084 | |
| 画像8 | 2.860 | 843485 | 35.75 | 2.860 | 881562 | 37.37 | 2.989 | |
| 画像9 | 3.303 | 974104 | 41.29 | 3.303 | 987236 | 41.84 | 3.348 | |
| 画像10 | 3.206 | 945461 | 40.07 | 3.206 | 985558 | 41.77 | 3.342 | |
ハフマン符号化では、「適応型 ( 動的 ) ハフマン符号化」というものがありました。これはハフマン木の作成と符号化処理を並列で行うやり方で、データを全て読み込んで出現頻度を調べてから符号化処理をする必要がないため、逐次データを読み込みながら符号化を行いたい場合に利用することができました。これは算術符号化でも利用できる手段であり、例えば出現頻度の初期値を全データに対して 1 としておいて、一つのデータを符号・復号化する度に更新することで簡単に対応できます。以下に、Range Coderで示した例と同じサンプル・データを利用して、実際に適応型の符号化・復号化を行った例を示します。
| データ | 符号 | Range | 出現回数 | 累積出現回数 | ||||
|---|---|---|---|---|---|---|---|---|
| a | b | c | a | b | c | |||
| 初期値 | 0 | 100 | 1 | 1 | 1 | 0 | 1 | 2 |
| a | 0 + (100/3) x 0 = 0 | (100/3) x 1 = 33 | 2 | 1 | 1 | 0 | 2 | 3 |
| b | 0 + (33/4) x 2 = 16 | (33/4) x 1 = 8 | 2 | 2 | 1 | 0 | 2 | 4 |
| Rangeを10倍 | 160 | 80 | ||||||
| 符号の3桁目(1)を出力 | 60 | 80 | ||||||
| a | 60 + (80/5) x 0 = 60 | (80/5) x 2 = 32 | 3 | 2 | 1 | 0 | 3 | 5 |
| c | 60 + (32/6) x 5 = 85 | (32/6) x 1 = 5 | 3 | 2 | 2 | 0 | 3 | 5 |
| Rangeを10倍 | 850 | 50 | ||||||
| 符号の3桁目(8)を出力 | 50 | 50 | ||||||
| a | 50 + (50/7) x 0 = 50 | (50/7) x 3 = 21 | 4 | 2 | 2 | 0 | 4 | 6 |
| b | 50 + (21/8) x 4 = 58 | (21/8) x 2 = 4 | 4 | 3 | 2 | 0 | 4 | 7 |
| 符号 58 を出力 | ||||||||
| 符号 / ( Range / Size ) | 出力データ | 符号 | Range | 出現回数 | 累積出現回数 | ||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | c | a | b | c | ||||
| 初期値 = 18 | 18 | 100 | 1 | 1 | 1 | 0 | 1 | 2 | |
| 18 / (100/3) = 0 | a | 18 - (100/3) x 0 = 18 | (100/3) x 1 = 33 | 2 | 1 | 1 | 0 | 2 | 3 |
| 18 / (33/4) = 2 | b | 18 - (33/4) x 2 = 2 | (33/4) x 1 = 8 | 2 | 2 | 1 | 0 | 2 | 4 |
| Rangeを10倍 | 20 | 80 | |||||||
| 符号データからデータ 5 を取得 | 25 | 80 | |||||||
| 25 / (80/5) = 1 | a | 25 - (80/5) x 0 = 25 | (80/5) x 2 = 32 | 3 | 2 | 1 | 0 | 3 | 5 |
| 25 / (32/6) = 5 | c | 25 - (32/6) x 5 = 0 | (32/6) x 1 = 5 | 3 | 2 | 2 | 0 | 3 | 5 |
| Rangeを10倍 | 0 | 50 | |||||||
| 符号データからデータ 8 を取得 | 8 | 50 | |||||||
| 8 / (50/7) = 1 | a | 8 - (50/7) x 0 = 8 | (50/7) x 3 = 21 | 4 | 2 | 2 | 0 | 4 | 6 |
| 8 / (21/8) = 4 | b | 8 - (21/8) x 4 = 0 | (21/8) x 2 = 4 | 4 | 3 | 2 | 0 | 4 | 7 |
適応型の処理の場合、累積出現回数を毎回算出し直す必要があるため、初めから出現頻度を計算する場合に比べると処理時間は長くなります。また、最初は出現頻度の偏りがないことから圧縮率も低下する傾向にあります。しかし、最初から全てのデータを読み込んでから処理することができない場合、例えばデータを他の変換処理で加工しながら、並行して算術符号化を行いたい場合は、この方法は有効な手段になります。
ところで、Range Coder のサンプル・プログラムでは 0 〜 255 までのデータを符号化処理しましたが、算術符号化の場合は、二進数に変換して 0 か 1 の二つのデータとして処理することが可能です。このような算術符号化は「二進算術符号化 ( Binary Arithmetic Coding )」と呼ばれています。数直線は 0 と 1 の二つのエリアに分割されるだけで済むため、その分処理も単純にすることが可能になります。
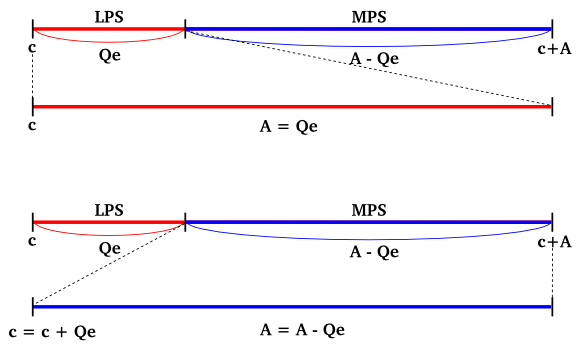
Q-Coderは、IBM が開発した「適応型二進算術符号化 ( Adaptive Binary Arithmetic Coding)」であり、JPEG2000 ではこの発展形である MQ-Coder が利用されています。Q-Coder の特徴として、符号化する値が実際の値 ( 0 か 1 ) ではなく、「MPS ( More Probable Symbol )」と「LPS ( Less Probable Symbol )」という二つのシンボルであることが挙げられます。実際の値に関係なく、出現確率の高い側を前者、低い側を後者と表して符号化を行います。数直線は二つのエリアに分かれ、0 に近い側が LPS、遠い側がMPSとなります。
 |
Range Coder と同じように、Range はある一定の幅を保つように「正規化 ( Renormalization )」を行います。Q-Coder では Range のことを確率区間幅 A として表し、常に 0.75 ( 2 進法の 0.11 ) 〜 1.5 ( 2 進法の 1.1 ) の範囲に保持します。このとき、A の値は 1 に近似されることになります。
LPS の発生する確率を Qe としたとき、数直線上の MPS と LPS の幅は以下のように計算することができます。
LPSの幅 = Qe x A
MPSの幅 = A - ( Qe x A )
しかし、A は 1 に近似できるため、上式は以下のようにすることができます。
LPSの幅 = Qe
MPSの幅 = A - Qe
Q-Coder も算術符号化の一種なので、符号と確率区間幅 A を毎回更新することになります。入力データは LPS と MPS の二つであり、それぞれ次のように処理します。この処理においては加算以外の演算が不要になるため実装を単純化することができ、特に処理回数の多い場所であることから高速な処理が期待できます。実装が単純な分、ハードウェアへの実装がしやすいという特徴もあります。
| LPS | MPS | |
|---|---|---|
| 符号 C | C | C + Qe |
| 確率区間幅 A | Qe | A - Qe |
 |
前に述べたように、Q-Coder では Range Coder 同様、確率区間幅 A がある一定の値より小さくなったときに符号と A を定数倍します。Q-Coder では、A が 0.75 より小さくなったらそれぞれを 2 倍して、A が常に 0.75 〜 1.5 の範囲にあるように調整を行います。符号は常に大きくなるので、一定回数正規化処理を行ったら上位のビットを符号列として出力します。また、Range Coder と同様に桁上りが発生する場合がありますが、Q-Coder では「ビット・スタフィング ( Bit Stuffing )」という方法を使って解決しています。この方法は、前の符号の全ビットが立っていた ( = 0xFF ) 場合、キャリー・ビットを冗長な 1 ビットとして出力するというもので、これにより桁上りによる再計算を回避することができます。
符号と確率区間幅 A の更新は近似式を用いているため、LPS の幅が MPS のそれよりも大きくなる場合が発生します。例えば、Qe = 0.48、A = 0.88 のとき、正確に計算すれば
LPSの幅 = 0.48 x 0.88 = 0.42
MPSの幅 = 0.88 - ( 0.48 x 0.88 ) = 0.46
になりますが、近似式を使うと
LPSの幅 = 0.48
MPSの幅 = 0.88 - 0.48 = 0.40
となり、大きさが逆転してしまいます。このため、大小関係の逆転が発生した場合は LPS と MPS それぞれを示す区間も逆転させる必要があります。これを MPS と LPS の「状態交換 ( Conditional Exchange )」と言います。
算術符号化処理でのもうひとつ重要な処理として出現頻度の算出がありますが、Q-Coder ではここでも処理を単純化するために「確率推定 ( Probability Estimate )」という方法を使っています。文字通り、きちんと出現頻度を計算する代わりに推定した値を使って処理を行うというものですが、推定値を入力した値に応じて適正なものに保つために、正規表現でも紹介した「有限オートマトン ( Finite State Automaton : 有限状態機械 )」を利用しています。この有限オートマトンにはそれぞれ番号が振られ、一つのオートマトンに対して Qe 値、LPS・MPS それぞれの符号化時に次の状態へ移るための番号、LPS・MPSの符号入れ換えを行うかどうかを示すフラグが定義されています。
MPS 符号化時は Qe は減少する傾向にあるため、状態もそのようになるよう遷移する番号が振られています。逆に LPS 符号化時は Qeが増加するように遷移します。また、常に MPS 符号が発生した場合、Qe は最小値のまま常に同じ状態を遷移し続けることになります。
算術符号化処理の紹介は以上になります。JPEG2000では、エンベデッド符号化の一つであるEBCOTとQ-Coderの発展形であるMQ-Coderを組み合わせて使用しており、最初はこの内容まで一度に紹介しようと思っていましたが、そうなると量がかなり多くなってしまうため、次章にて紹介することにします。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |