
今までは、あるデータ列から目的のデータを検索するアルゴリズムを紹介してきましたが、この章では、ある文字列から、与えられた部分文字列と一致する場所を探す処理である「文字列照合 ( String Matching ) 」を取り上げたいと思います。エディタの検索機能なんかを思い浮かべてもらえればいいと思います。
文字列照合を行うための最も単純な方法は、照合される文字列 ( 以下、わかりやすいように「テキスト」とします ) の頭から順に照合文字列 ( 以下「パターン」と略記します ) と比較して、違っていたら一文字ずつ後ろへずらしながら処理を繰り返すことでしょう。このような処理を行った場合の例を以下に示します。
| 1) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | ← テキスト |
| K | Y | O | K | U | ← パターン | ||||||||||||
| 2) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 3) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 4) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 5) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 6) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 7) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 8) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 9) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 10) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 11) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | |
| K | Y | O | K | U | |||||||||||||
| 12) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | 照合成功 |
| K | Y | O | K | U |
テキストとパターンの中で、両側に下線が引かれた文字は一致したもの、パターンのみに下線が引かれた文字は不一致を検出した個所を示します。
それでは早速サンプルを示したいと思います。
/* strlen_ : 終端文字(\0)を除く文字列の長さを返す char* s : 文字列の先頭ポインタ 戻り値 : 文字列の長さ */ unsigned int strlen_( char* s ) { unsigned int i; for ( i = 0 ; s[i] != '\0' ; i++ ); return( i ); } /* strncmp_ : 二つの文字列を指定した長さ分だけ比較する In s1, s2 : 二つの文字列の先頭ポインタ unsigned int len : 比較する文字列の長さ 終端文字のチェックは行わない 文字列の中に等しくない文字が見つかったら、その差分を返す 戻り値 : <0 ... s1の方が小さい ; >0 ... s1の方が大きい =0 ... s1とs2は等しい */ template<class In> int strncmp_( In s1, In s2, unsigned int len ) { int cmpret = 0; // 文字の比較結果 for ( unsigned int i = 0 ; i < len ; i++ ) { if ( ( cmpret = *s1 - *s2 ) != 0 ) break; ++s1; ++s2; } return( cmpret ); } /* simpleStrstr : 文字列の検索(char*版) char* text : 検索先文字列 char* pattern : 検索対象の文字列 戻り値 : 一致した位置(0ならば見つからなかった) */ char* simpleStrstr( char* text, char* pattern ) { unsigned int patLen = strlen_( pattern ); // patternの文字列長 unsigned int txtLen = strlen_( text ); // textの文字列長 if ( txtLen < patLen ) return( 0 ); // textがpatternより短ければ必ず一致しない char* textEnd = &text[txtLen - patLen]; // 文字列比較可能な最末尾のポインタ do { if ( strncmp_( text, pattern, patLen ) == 0 ) return( text ); } while ( ++text <= textEnd ); return( 0 ); } /* simpleStrstr : 文字列の検索(string版) const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type sIdx : 検索開始位置 戻り値 : 一致した位置(nposならば見つからなかった) */ template<class T> typename basic_string<T>::size_type simpleStrstr( const basic_string<T>& text, const basic_string<T>& pattern, typename basic_string<T>::size_type sIdx ) { typename basic_string<T>::size_type patLen = pattern.length(); // patternの文字列長 typename basic_string<T>::size_type txtLen = text.length(); // textの文字列長 // 検索開始位置からの文字数が pattern の文字数より小さければ必ず一致しない if ( txtLen < sIdx + patLen ) return( basic_string<T>::npos ); typename basic_string<T>::const_iterator textIt = text.begin() + sIdx; // textの開始位置 typename basic_string<T>::const_iterator patIt = pattern.begin(); // patternの開始位置 typename basic_string<T>::const_iterator textEnd = text.end() - patLen + 1; // 文字列比較可能な最末尾 do { if ( strncmp_( textIt, patIt, patLen ) == 0 ) return( textIt - text.begin() ); } while ( ++textIt != textEnd ); return( basic_string<T>::npos ); }
文字列探索を行うメインの関数は simpleStrstr です。この関数は、文字列 text の中でパターン文字列 pattern と一致した個所を見つけたら、その場所のポインタまたは添字の値を返します ( 見つからなかったら NULL ポインタまたは npos ( size_type の最大値 ) を返します )。処理の内容は、pattern と同じ長さ分だけの文字列を text の検索開始位置から順に比較し、一致すればそのときのポインタ・添字を返し、一致しなかったらポインタ・添字をひとつずつ増やしているだけの単純なものです。この実装内容から明らかなように、simpleStrstr は最初に見つかった一致文字列のポインタ・反復子を返す仕様になっています。全ての箇所に対して検索したい場合は、戻り値のポインタ・添字を一つ進めて再度 simpleStrstr で処理する操作を、NULL ポインタまたは npos が返されるまで繰り返します。
simpleStrstr は二種類あり、一つは char* 型で表された文字列を引数としたもの、もう一方は STL(Standard Template Library) にある basic_string 型の文字列を引数としたものです。どちらも処理の内容は全く同一で、差異としては、要素へのアクセスに、前者は通常のポインタを利用して末尾を終端文字 '\0' で検知するのに対し、後者は反復子を利用して末尾をメンバ関数 end ( 実際は末尾から pattern の文字数分だけ先頭側に戻った位置 ) で検知するところだけです。
strlen_ は終端文字 '\0' を除いた文字列の長さを返す関数で、char* 型を利用した文字列専用の関数です。同じ処理を行う関数が、標準ライブラリ関数 strlen としてありますが、サンプルという事で一応実装しておきました。basic_string 型に対してはメンバ関数 length があり、basic_string 版 simpleStrstr ではこれをそのまま利用しています。
strncmp_ は、二つの文字列を引数 len で示した長さ分だけ比較して、不一致を検出したらその文字コードの差を返す関数です。よって、文字列が完全に一致した場合はゼロを返します。これも、同様の関数が標準ライブラリ関数 strncmp として存在しますが、標準ライブラリが char* 型の文字列しか扱えないのに対し、strncmp_ は「テンプレート ( template )」を利用して basic_string 型にもそのまま利用できるようにしてあります。
「テンプレート」は型をパラメータとして扱う手法で、C++ ではよく利用される機能です (*3-1)。上記の例では In がデータ型を表しており、In を型とする変数は s1 と s2 の二つで、これらの変数を使った演算子は * (間接参照) と ++ (前置インクリメント) の二種類です。従って、In 型がこれらの演算子をサポートしていれば、コンパイラが対象とする型に合わせて適切にビルドしてくれます。今回は、char* 型と basic_string<T>::const_iterator 型 (反復子) が対象であり、これらは先ほど示した演算子をサポートしているため、問題なくビルドすることができます。ちなみに、basic_string<T>::const_iterator 型の中にある T もテンプレートを使って指定された任意の型パラメータを表しています。
サンプル・プログラムを利用して、文字列照合処理の時間を計測した結果を以下に示します。
| text size | pattern size | 処理時間 | ||
|---|---|---|---|---|
| char*版 | string版 | char*版(標準ライブラリ) | ||
| 350000 | 1 | 0.000288 | 0.000003 | 0.000021 |
| 10 | 0.000655 | 0.000334 | 0.004900 | |
| 100 | 0.000685 | 0.000395 | 0.002745 | |
| 1000 | 0.000564 | 0.000360 | 0.003859 | |
| 10000 | 0.000759 | 0.000334 | 0.002834 | |
| char*版(標準ライブラリ)含む | char*版(標準ライブラリ)除外 |
|---|---|
|
|
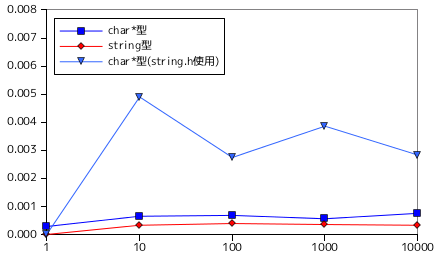
上に示した図表は、text のサイズを 35 万文字固定とし、その中から異なる長さの pattern を探索した時の処理時間を表しています。但し、グラフの横軸は対数で表現しています。
文庫本 1 ページの文字数は通常 600 から 750 文字と言われています。500 ページの文庫本の場合、1 ページが 750 文字として 375000 文字程度となるので、文庫本の内容からある文字列を探す処理を想定して text のサイズを決めています。テストは各条件に対して 10 回行い、その平均を表に示しています。また、文字列としては空白文字(0x20) から '~' (0x7E) までの文字コード 96 文字を対象としています。pattern が一文字である場合を除くと、一致した文字列が存在することは皆無だったので、どの場合も照合に失敗した(最後まで比較処理を行った)ことになります。
char* 版と basic_string 版を比較すると、basic_string 版の方がわずかに短い時間で処理できていることがこの結果からわかります。処理の内容はほとんど変わらないため basic_string 版の方が短時間で処理できるのは不思議ですが、考えられる理由としては、text と pattern の文字列長を求める操作のところで length 関数はすでに計算済みの文字列長を返しているだけである可能性があります。ちなみに char* 版において、strlen と strncmp を標準ライブラリの関数に置き換えたところ、極端に処理が重くなりました。上に示したグラフの左側は、char* 版、basic_string 版の他に、char* 版の標準ライブラリ利用版もプロットした結果であり、処理時間が他と比べて長くなっている様子がわかります。右側は、標準ライブラリ利用版を除外してプロットした結果になります。
今度は pattern のサイズを固定して、text のサイズを変化させた時の処理時間の推移を以下に示します。
| text size | pattern size | 処理時間 | ||
|---|---|---|---|---|
| char*版 | string版 | char*版(標準ライブラリ) | ||
| 1000 | 10 | 0.000001 | 0.000007 | 0.000026 |
| 10000 | 0.000013 | 0.000056 | 0.000157 | |
| 100000 | 0.000227 | 0.000182 | 0.001575 | |
| 1000000 | 0.001476 | 0.000815 | 0.006226 | |
| 2500000 | 0.003495 | 0.002269 | 0.015608 | |
| 5000000 | 0.007042 | 0.004197 | 0.030481 | |
| 7500000 | 0.010315 | 0.006670 | 0.044490 | |
| 10000000 | 0.015119 | 0.008453 | 0.064211 | |
| char*版(標準ライブラリ)含む | char*版(標準ライブラリ)除外 |
|---|---|
 |
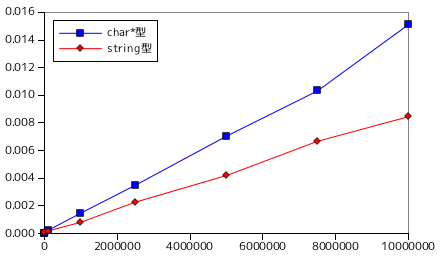 |
pattern のサイズは 10 文字固定とし、text のサイズを 1,000 から 10,000,000 まで変化させた時の推移を示しています。ここでもテストは各条件に対して 10 回繰り返し、その平均時間を示しています。グラフを見れば明らかなように、処理時間は text のサイズにほぼ線形に増加しています。また、前のテストと同様に、basic_string 版が最も処理時間が短く、標準ライブラリを用いた char* 版は極端に処理時間が長くなっています。
文字列比較の場合、処理が終わるまでに文字コードを比較する回数がアルゴリズムの性能を左右します。テキストとパターンのそれぞれの文字数が N, m で、N が m に対して十分大きいとすると、上記のアルゴリズムの場合、最悪 N x m 回近く文字を比較する必要があります。例えば、単一の文字が N 個並んだ文字列から、同じ文字の並びの末尾に一文字だけ違う文字コードを付加した長さ m の文字列を検索した場合、m - 1 文字まで検索して最後の m 文字目で不一致を検出する処理を N - m + 1 回繰り返すことになります。
しかし、テキスト・エディタなどで文字列検索を行うような、普通に利用する場面においては、このような想定外の状態というのはまず起こりません。仮に、各文字コードがテキスト中に現れる確率が全て等しいとした場合、テキストとパターンの一文字目が一致する確率は「文字コードの種類の逆数」となり、さらに二文字目、三文字目と連続して一致する確率はその二乗、三乗と極端に小さくなっていきます。実際には各文字コードの使用頻度がバラバラであるため正確さに欠けるとはいえ、現実の文字コードの種類は十分多いので、二つの文字が連続して一致する確率より一致しない確率の方がずっと高いということはまず間違いないでしょう。
もし、常にパターンの先頭で不一致が見つかったとすれば、文字コードの比較回数は最大でも約 N 回となるので、パターンの先頭で不一致を検出する確率が非常に高ければ実行速度はだいたい N に比例すると考えることができます。実際、パターンの文字数を変化させても実行速度はほとんど変化していないことがわかります。一般に、実行時間がデータの量に比例するアルゴリズムは「高速」、少なくとも「実用的」な部類に属するので、上に示した「単純な」文字列比較は実用上十分「高速」であり、よって文字列照合に関しては複雑なアルゴリズムが入り込む余地があまりないことを意味します。そのため歴史的には、より高速な文字列照合のアルゴリズムが登場するのがかなり遅かったようです (クイックソートの論文が発表されたのは 1962 年、それに対して改良された文字列照合アルゴリズムは 1977 年に発表されています)。
文字列照合アルゴリズムを考案・改良する場合は、シンプルさを保たないと単純な方法には勝てないということを理解しておく必要があります。
*1-1) 「円を描く (3)サンプル・プログラム」の中に、テンプレートに関する説明を記述した箇所があるので、そちらも参考にして下さい
単純な文字列照合アルゴリズムでは不一致が検出されたらパターンを一文字ずらして再び照合を繰り返すものでしたが、より洗練されたアルゴリズムでは、パターンの移動量をなるべく大きくすることで効率を稼ぐようにしています。そのようなアルゴリズムの一つに、TeXの開発者として有名な計算機科学者の「ドナルド・クヌース ( Donald Ervin Knuth )」と、同じく計算機科学者の「ヴァーン・プラット ( Vaughan Ronald Pratt )」、およびこの二人の他に「ジェームス・モリス( James Hiram Morris )」が同時期に単独で考案した「Knuth-Morris-Pratt (KMP) 法」があります。
KMP 法では、パターンとテキストの間で部分的に一致した場合に、その情報を元に大きくパターンを移動することによって効率化を図っています。そのために、不一致を起こした個所それぞれについて何文字までずらせばいいのかを事前に調べてテーブルにしておきます。例えば、前節の例で使用したパターン KYOKU の場合、
| 1 文字目で不一致の場合 | ? | ? | |||||
| 無条件に 1 文字ずらす | K | ||||||
| 2 文字目で不一致の場合 | K | ? | |||||
| 1 文字ずらせば一致の可能性あり | K | ||||||
| 3 文字目で不一致の場合 | K | Y | ? | ? | |||
| 1 文字ずらしても一致しない | K | Y | |||||
| 2 文字ずらせば一致の可能性あり | K | Y | |||||
| 4 文字目で不一致の場合 | K | Y | O | ? | ? | ? | |
| 1 文字ずらしても一致しない | K | Y | O | ||||
| 2 文字ずらしても一致しない | K | Y | O | ||||
| 3 文字ずらせば一致の可能性あり | K | Y | O | ||||
| 5 文字目で不一致の場合 | K | Y | O | K | ? | ? | ? |
| 1 文字ずらしても一致しない | K | Y | O | K | |||
| 2 文字ずらしても一致しない | K | Y | O | K | |||
| 3 文字ずらせば一致の可能性あり | K | Y | O | K | |||
となるので、例えば 4 文字目で不一致を検出したら、無条件に 3 文字分パターンを移動すればいいことになります。
さらに、パターンを移動した後に文字の比較を開始する個所は、一文字目で不一致を起こした場合を除き、前に不一致を起こしたところから行えばいいこともわかると思います。というのも、パターンの移動量を調べた時点で、不一致を起こした個所より前の部分については一致していることがわかっているからです。
| 9 文字目で不一致 | K | Y | O | K | A | K | Y | O | K | ? | ? | ? | ? | ? | ? |
| 5 文字ずらせば一致の可能性あり | K | Y | O | K | A | K | Y | O | K | U |
上の例では、前の 4 文字分はすでに一致していることがわかっているので、前に不一致を起こした個所、すなわちパターンの 5 文字目から比較処理を始めればいいことになります。このことからわかるように、事前に調べるパラメータとしては、パターンの移動量よりも再比較を始める個所 (上の例では 5 文字目) の方が都合がいいことになります。
KMP法による文字列照合アルゴリズムのサンプルを示します。
/* kmpStrstr : KMP法による文字列照合 const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 void (*makeKmpTable)( const basic_string<T>&, vector<unsigned int>& ) : kmpTable 作成用関数 typename basic_string<T>::size_type txtIdx : 検索開始位置 戻り値 : 一致した位置( npos ならば見つからなかった) */ template<class T> typename basic_string<T>::size_type kmpStrstr( const basic_string<T>& text, const basic_string<T>& pattern, void (*makeKmpTable)( const basic_string<T>&, vector<unsigned int>& ), typename basic_string<T>::size_type txtIdx ) { // 不一致時に再び比較を始めるパターン上の位置を求める vector<unsigned int> kmpTable; (*makeKmpTable)( pattern, kmpTable ); typename basic_string<T>::size_type patIdx = 0; // pattern の照合位置 typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 typename basic_string<T>::size_type txtLen = text.length(); // text の文字列長 while ( txtIdx < txtLen ) { // 文字コードが一致した場合、テキストとパターンの照合位置を進める if ( text[txtIdx] == pattern[patIdx] ) { ++txtIdx; ++patIdx; // 全て一致した!! if ( patIdx >= patLen ) return( txtIdx - patLen ); // パターン 1 文字目で不一致の場合はテキストの照合位置を進める } else if ( patIdx == 0 ) { ++txtIdx; // パターン 1 文字目以外で不一致の場合は kmpTable からパターンの照合位置を取得する } else { patIdx = kmpTable[patIdx]; } } return( basic_string<T>::npos ); }
パターン一文字目で不一致を起こした場合は、無条件にテキストの注目位置を進めていることに注意してください。そうしないと無限ループに陥ってしまいます。
サンプル・プログラムの中では、再比較を行うときのパターン上の位置を配列 kmpTable に登録する処理を、関数ポインタ makeKmpTable で渡された関数で実行するように実装しています。この kmpTable を作成する方法ですが、ここでも KMP 法そのものを利用することが可能です。kmpTable の作成ルーチンを以下に示します。
/* makeKmpTable : 比較開始箇所(kmpTable)の作成 const basic_string<T>& pattern : 検索対象の文字列 vector<unsigned int>& kmpTable : 比較開始箇所を保持する配列 */ template<class T> void makeKmpTable( const basic_string<T>& pattern, vector<unsigned int>& kmpTable ) { typename basic_string<T>::size_type txtIdx = 1; // pattern を text とみなした時の照合位置 typename basic_string<T>::size_type patIdx = 0; // pattern の照合位置 typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 kmpTable.assign( patLen, 0 ); while ( txtIdx + 1 < patLen ) { // 一致したら、両者の位置を進めてテーブルに次の文字位置を登録する if ( pattern[txtIdx] == pattern[patIdx] ) { ++txtIdx; ++patIdx; kmpTable[txtIdx] = patIdx; //showKmpRes( pattern, txtIdx, kmpTable[txtIdx] ); // パターン 1 文字目で不一致の場合は、テキストの注目位置を進める } else if ( patIdx == 0 ) { ++txtIdx; //showKmpRes( pattern, txtIdx, kmpTable[txtIdx] ); // パターン 1 文字目以外で不一致の場合は、kmpTable から照合位置を抽出する } else { patIdx = kmpTable[patIdx]; } } }
パッと見ただけでは分かりにくいかもしれないですが、上のサンプルでは、パターン自身をテキストとみなしてその第 2 文字目以降とパターンを照合し、どこで不一致を起こすかを調べ、その結果を kmpTable に登録する処理を行っています。kmpTable 配列のインデックスが不一致を起こした文字の個所を示していますが、2 文字目で不一致を起こした場合 ( txtIdx = 1 ) は無条件にパターンの 1 文字目から再比較を行うため、kmpTable[1] = 0 になります。従って、ループは txtIdx = 2 から開始すればよく、パターン 1 文字目で不一致である場合は kmpTable の値はゼロでよいので、あらかじめ kmpTable の全ての要素はゼロで初期化しておきます。ループに入ってからは、まずパターンの 2 文字目 ( txtIdx = 1 ; これが text の注目位置になります ) と 1 文字目 ( patIdx = 0 ; これは pattern の注目位置です ) を比較し、
| txtIdx patIdx | |||||||
| A. pattern の 1 文字目と text の 2 文字目が一致した | 1 | : | A | A | ? | ||
| 0 | A | A | |||||
| 2 | : | A | A | ? | |||
| 1 | A | A | ... kmpTable[2] = 1 | ||||
| B. pattern の 1 文字目と text の 2 文字目が一致しない | 1 | : | A | B | ? | ||
| 0 | A | B | |||||
| 2 | : | A | B | ? | |||
| 0 | A | B | ... kmpTable[2] = 0 | ||||
上の処理で、3 文字目で不一致を起こした場合の再比較位置が決まったことになります。次はパターンの 3 文字目 ( txtIdx = 2 ) と 2 文字目 ( patIdx = 1 ) または 1 文字目 ( patIdx = 0 ) を比較し、
| txtIdx patIdx | ||||||||
| A | 1. pattern の 2 文字目と text の 3 文字目が一致した | 2 | A | A | A | ? | ||
| 1 | A | A | A | |||||
| 3 | A | A | A | ? | ||||
| 2 | A | A | A | ... kmpTable[3] = 2 | ||||
| 2. pattern の 2 文字目と text の 3 文字目が一致しない | 2 | A | A | B | ? | |||
| 1 | A | A | B | ... patIdx = kmpTable[1] = 0 | ||||
| 2 | A | A | B | ? | ||||
| 0 | A | A | B | |||||
| 3 | A | A | B | ? | ||||
| 0 | A | A | B | ... kmpTable[3] = 0 | ||||
| B | 1. pattern の 1 文字目と text の 3 文字目が一致した | 2 | A | B | A | ? | ||
| 0 | A | B | A | |||||
| 3 | A | B | A | ? | ||||
| 1 | A | B | A | ... kmpTable[3] = 1 | ||||
| 2. pattern の 1 文字目と text の 3 文字目が一致しない | 2 | A | B | C | ? | |||
| 0 | A | B | C | |||||
| 3 | A | B | C | ? | ||||
| 0 | A | B | C | ... kmpTable[3] = 0 | ||||
以下、この処理を patternの末尾まで繰り返すと、最終的には kmpTable が完成します。つまりは text の txtIdx + 1 番目で不一致が起きたと仮定して、pattern 側を右にずらした状態で ( このとき、直前の処理によって txtIdx - 1 までの文字が一致する状態になります ) text の txtIdx 番目と pattern の patIdx 番目を比較し、一致したら、それまでの処理によって txtIdx - 1 以前の文字は一致していることが保証されているので次のパターン文字のインデックスを登録し、一致しなかったら、kmpTable には txtIdx までのインデックスに対して値がすでに登録されており、その値まで注目位置を小さくしても、それまでの位置では一致しないことが保証されているので、KMP 法を適用して patIdxを更新します。
言葉だけの説明ではなかなか納得できないと思いますので、上に示した例を参考にしてください。さらに 5 文字目で不一致が起こった場合の注目位置の更新例を以下に示しておきます。
| txtIdx patIdx | ||||||||||
| A.1 | α. pattern の 3 文字目と text の 4 文字目が一致した | 3 | A | A | A | A | ? | |||
| 2 | A | A | A | A | ||||||
| 4 | A | A | A | A | ? | |||||
| 3 | A | A | A | A | ... kmpTable[4] = 3 | |||||
| β. pattern の 3 文字目と text の 4 文字目が一致しない | 3 | A | A | A | B | ? | ||||
| 2 | A | A | A | B | ... patIdx = kmpTable[2] = 1 | |||||
| 3 | A | A | A | B | ? | |||||
| 1 | A | A | A | B | ... patIdx = kmpTable[1] = 0 | |||||
| 3 | A | A | A | B | ? | |||||
| 0 | A | A | A | B | ||||||
| 4 | A | A | A | B | ? | |||||
| 0 | A | A | A | B | ... kmpTable[4] = 0 | |||||
| A.2 | α. pattern の 1 文字目と text の 4 文字目が一致した | 3 | A | A | B | A | ? | |||
| 0 | A | A | B | A | ||||||
| 4 | A | A | B | A | ? | |||||
| 1 | A | A | B | A | ... kmpTable[4] = 1 | |||||
| α. pattern の 1 文字目と text の 4 文字目が一致しない | 3 | A | A | B | B | ? | ||||
| 0 | A | A | B | B | ||||||
| 4 | A | A | A | B | ? | |||||
| 0 | A | A | A | B | ... kmpTable[4] = 0 | |||||
| B.1 | α. pattern の 2 文字目と text の 4 文字目が一致した | 3 | A | B | A | B | ? | |||
| 1 | A | B | A | B | ||||||
| 4 | A | B | A | B | ? | |||||
| 2 | A | B | A | B | ... kmpTable[4] = 2 | |||||
| β. pattern の 2 文字目と text の 4 文字目が一致しない (1) | 3 | A | B | A | A | ? | ||||
| 1 | A | B | A | A | ... patIdx = kmpTable[1] = 0 | |||||
| 3 | A | B | A | A | ? | |||||
| 0 | A | B | A | A | ||||||
| 4 | A | B | A | A | ? | |||||
| 1 | A | B | A | A | ... kmpTable[4] = 1 | |||||
| γ. pattern の 2 文字目と text の 4 文字目が一致しない (2) | 3 | A | B | A | C | ? | ||||
| 1 | A | B | A | C | ... patIdx = kmpTable[1] = 0 | |||||
| 3 | A | B | A | C | ? | |||||
| 0 | A | B | A | C | ||||||
| 4 | A | B | A | C | ? | |||||
| 0 | A | B | A | C | ... kmpTable[4] = 0 | |||||
| B.2 | α. pattern の 1 文字目と text の 4 文字目が一致した | 3 | A | B | C | A | ? | |||
| 0 | A | B | C | A | ||||||
| 4 | A | B | C | A | ? | |||||
| 1 | A | B | C | A | ... kmpTable[4] = 1 | |||||
| β. pattern の 1 文字目と text の 4 文字目が一致しない | 3 | A | B | C | D | ? | ||||
| 0 | A | B | C | D | ||||||
| 4 | A | B | C | D | ? | |||||
| 0 | A | B | C | D | ... kmpTable[3] = 0 | |||||
再比較をはじめる箇所を出力する関数 showKmpRes を以下に示します。
/* showKmpRes : 比較開始箇所(kmpTable)の表示 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type txtIdx : テキストの注目位置(不一致を起こした位置) typename basic_string<T>::size_type patIdx : パターンの注目位置(照合を再開する位置) */ template<class T> void showKmpRes( const basic_string<T>& pattern, typename basic_string<T>::size_type txtIdx, int patIdx ) { typename basic_string<T>::size_type shtIdx = txtIdx - patIdx; // シフト量 cout << txtIdx << "\t" << pattern.substr( 0, txtIdx ) << "?" << endl; cout << patIdx << "\t"; cout.width( shtIdx ); cout << " "; cout.width( 0 ); cout << pattern.substr( 0, ( patIdx >= 0 ) ? patIdx : 0 ) << pattern.substr( ( patIdx >= 0 ) ? patIdx : 0, 1 ); cout << pattern.substr( ( ( patIdx >= 0 ) ? patIdx : 0 ) + 1, shtIdx - 1 ) << endl; }
makeKmpTable の中でコメントアウトされているこの関数の呼び出しを有効にすると、以下のような出力結果が得られるようになります。
パターン = ZOOZOO の場合 2 ZO? 0 ZO 3 ZOO? 0 ZOO 4 ZOOZ? 1 ZOOZ 5 ZOOZO? 2 ZOOZO
kmpTable を構築する関数を引数で渡すようにしたのは、この関数が後述のように最適化できるからです。他に、kmpTable を構築する関数と KMP 法の関数本体を完全に分離する方法も考えられ、この場合はパターンが固定であるときに同じ処理を繰り返す必要がなくなるという利点もあります。今回はテスト時に毎回パターンを変えることから、まとめて処理する形に実装しています。
上に示したアルゴリズムをもう少し最適化してみます。次のような例において、5 文字目で不一致を起こした場合 (下表の 3 段目)、不一致を起こしたテキストの個所は O 以外の文字なのでこの比較は必ず失敗し、再度テーブルを検索してパターンを移動しなければなりません。このような無駄は 6 文字目で不一致を起こした場合でも発生します。
| txtIdx padIdx | |||||||||
| 1 | Z | O | ? | ||||||
| 0 | Z | O | |||||||
| 2 | Z | O | ? | ||||||
| 0 | Z | O | ... kmpTable[2] = 0 | ||||||
| 2 | Z | O | O | ? | |||||
| 0 | Z | O | O | ||||||
| 3 | Z | O | O | ? | |||||
| 0 | Z | O | O | ... kmpTable[3] = 0 | |||||
| 3 | Z | O | O | Z | ? | ||||
| 0 | Z | O | O | Z | |||||
| 4 | Z | O | O | Z | ? | ||||
| 1 | Z | O | O | Z | ... kmpTable[4] = 1 → 5 文字目は O でないので必ず失敗 | ||||
| 4 | Z | O | O | Z | O | ? | |||
| 1 | Z | O | O | Z | O | ||||
| 5 | Z | O | O | Z | O | ? | |||
| 2 | Z | O | O | Z | O | ... kmpTable[5] = 2 → 6 文字目は O でないので必ず失敗 | |||
よって、テーブルを作成する際に、注目位置の文字が一致したら同時に次の文字も一致するかどうかをチェックし、一致するのであれば ( テキストとの照合時には逆に必ず不一致となるので ) 「再度テーブルを検索する」処理を行って、その比較位置を登録するようにすればいいわけです。上の例では、5 文字目で不一致を起こした場合、再度比較しても 2 文字目でまた不一致を起こすので、比較位置は最終的に 0 になります。6 文字目の場合も 3 文字目でまた不一致を起こすため、登録位置はやはり 0 です。
| txtIdx padIdx | |||||||||||
| 1 | Z | O | |||||||||
| 0 | Z | O | |||||||||
| 2 | Z | O | |||||||||
| 0 | Z | O | ... kmpTable[2] = 0 | ||||||||
| 2 | Z | O | O | ||||||||
| 0 | Z | O | O | ||||||||
| 3 | Z | O | O | ||||||||
| 0 | Z | O | O | ... kmpTable[3] = 0 | |||||||
| 3 | Z | O | O | Z | |||||||
| 0 | Z | O | O | Z | |||||||
| 4 | Z | O | O | Z | |||||||
| 1 | Z | O | O | Z | ... kmpTable[4] = 1 → 5 文字目は O でないので必ず失敗 | ||||||
| Z | O | O | Z | ||||||||
| Z | O | O | Z | ... kmpTable[4] = kmpTable[1] = 0 ( 2 文字目で失敗するので padIdx = 1 での注目位置で再更新 ) | |||||||
| 4 | Z | O | O | Z | O | ||||||
| 1 | Z | O | O | Z | O | ||||||
| 5 | Z | O | O | Z | O | ||||||
| 2 | Z | O | O | Z | O | ... kmpTable[5] = 2 → 6 文字目は O でないので必ず失敗 | |||||
| Z | O | O | Z | O | |||||||
| Z | O | O | Z | O | ... kmpTable[5] = kmpTable[2] = 0 ( 3 文字目で失敗するので padIdx = 2 での注目位置で再更新 ) | ||||||
以上の改善を行ったものを以下に示します。
/* makeKmpTable2 : 比較開始箇所(kmpTable)の作成(高速版 1) const basic_string<T>& pattern : 検索対象の文字列 vector<unsigned int>& kmpTable : 比較開始箇所を保持する配列 */ template<class T> void makeKmpTable2( const basic_string<T>& pattern, vector<unsigned int>& kmpTable ) { typename basic_string<T>::size_type txtIdx = 1; // pattern を text とみなした時の照合位置 typename basic_string<T>::size_type patIdx = 0; // pattern の照合位置 typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 kmpTable.assign( patLen, 0 ); while ( txtIdx + 1 < patLen ) { // 一致したら、両者の位置を進める if ( pattern[txtIdx] == pattern[patIdx] ) { ++txtIdx; ++patIdx; if ( pattern[txtIdx] == pattern[patIdx] ) // 次の文字も一致したら、再度テーブルから文字位置を抽出して登録 kmpTable[txtIdx] = kmpTable[patIdx]; else // そうでなければ、テーブルに次の文字位置を登録 kmpTable[txtIdx] = patIdx; //showKmpRes( pattern, txtIdx, kmpTable[txtIdx] ); // パターン 1 文字目で不一致の場合は、テキストの注目位置を進める } else if ( patIdx == 0 ) { ++txtIdx; //showKmpRes( pattern, txtIdx, kmpTable[txtIdx] ); // パターン 1 文字目以外で不一致の場合は、kmpTable から照合位置を抽出する } else { patIdx = kmpTable[patIdx]; } } }
この関数を使った場合、kmpTable の内容は次のようになります。
パターン = ZOOZOO の場合 2 ZO? 0 ZO 3 ZOO? 0 ZOO 4 ZOOZ? 0 ZOOZ 5 ZOOZO? 0 ZOOZO
さらに上の例において、4 文字目で不一致を起こした場合 ( 2 段目の処理 )、パターン先頭の Z との比較処理も無駄になるのですが、これについても最適化を行うのであれば「テキストの注目位置を移動する量」を新たなパラメータとして持たせる必要があります。このような現象が発生するのは、比較を行う文字位置が一文字目で、かつパターンの先頭とテキストの注目している文字が異なることが明らかな場合のみであり、処理の手間が増える分かえって遅くなる可能性もあるので文献では無視していましたが、ここではサンプルを載せておきます。
/* makeKmpTable3 : 比較開始箇所(kmpTable)の作成(高速版 2) const basic_string<T>& pattern : 検索対象の文字列 vector<int>& kmpTable : 比較開始箇所を保持する配列 */ template<class T> void makeKmpTable3( const basic_string<T>& pattern, vector<int>& kmpTable ) { typename basic_string<T>::size_type txtIdx = 1; // pattern を text とみなした時の照合位置 typename basic_string<T>::size_type patIdx = 0; // pattern の照合位置 typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 kmpTable.assign( patLen, 0 ); while ( txtIdx + 1 < patLen ) { // 一致したら、両者の位置を進める if ( pattern[txtIdx] == pattern[patIdx] ) { ++txtIdx; ++patIdx; if ( pattern[txtIdx] == pattern[patIdx] ) // 次の文字も一致したら、再度テーブルから文字位置を抽出して登録 kmpTable[txtIdx] = kmpTable[patIdx]; else // そうでなければ、テーブルに次の文字位置を登録 kmpTable[txtIdx] = patIdx; //showKmpRes( pattern, txtIdx, kmpTable[txtIdx] ); // パターン 1 文字目で不一致の場合は、テキストの注目位置を進める } else if ( patIdx == 0 ) { ++txtIdx; // 今の注目文字とパターン先頭文字が一致したら負数を登録 if ( pattern[txtIdx] == pattern[0] ) kmpTable[txtIdx] = -1; //showKmpRes( pattern, txtIdx, kmpTable[txtIdx] ); // パターン 1 文字目以外で不一致の場合は、kmpTable から照合位置を抽出する } else { patIdx = kmpTable[patIdx]; } } } /* kmpStrstr3 : KMP法による文字列照合 (2) const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type txtIdx : 検索開始位置 戻り値 : 一致した位置( npos ならば見つからなかった) */ template<class T> typename basic_string<T>::size_type kmpStrstr3( const basic_string<T>& text, const basic_string<T>& pattern, typename basic_string<T>::size_type txtIdx ) { // 不一致時に再び比較を始めるパターン上の位置を求める vector<int> kmpTable; makeKmpTable3( pattern, kmpTable ); typename basic_string<T>::size_type patIdx = 0; // pattern の照合位置 typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 typename basic_string<T>::size_type txtLen = text.length(); // text の文字列長 while ( txtIdx < txtLen ) { // 文字コードが一致した場合、テキストとパターンの照合位置を進める if ( text[txtIdx] == pattern[patIdx] ) { ++txtIdx; ++patIdx; // 全て一致した!! if ( patIdx >= patLen ) return( txtIdx - patLen ); } else { // patIdx がゼロ : 無条件にテキストの照合位置を一つ進める if ( patIdx == 0 ) { ++txtIdx; // kmpTable がゼロより小 : テキストの照合位置を進めて patIdx をゼロで初期化 } else if ( kmpTable[patIdx] < 0 ) { ++txtIdx; patIdx = 0; // kmpTable がゼロ以上 : kmpTable からパターンの照合位置を取得する } else { patIdx = kmpTable[patIdx]; } } } return( basic_string<T>::npos ); }
サンプル・プログラムの中では、text 側の移動量も kmpTable の中にまとめて登録しています。kmpTable の値が正数ならば、その値は pattern の検索開始位置を表し、ゼロまたは負数ならば、その絶対値に 1 を加えた値が text の移動量を表すものとします。text 側の検索位置を移動する場合は、pattern の検索開始位置は必ずゼロになるので、kmpTable が負数なら pattern の検索位置は 0 で初期化することになります。
KMP 法のサンプル・プログラムを利用して文字列照合処理の時間を計測した結果を以下に示します。
| text size | pattern size | 処理時間 (sec.) | |||
|---|---|---|---|---|---|
| simpleStrstr | kmpStrstr1 | kmpStrstr2 | kmpStrstr3 | ||
| 350000 | 1 | 0.000003 | 0.000003 | 0.000013 | 0.000009 |
| 10 | 0.000334 | 0.000355 | 0.000312 | 0.000346 | |
| 100 | 0.000395 | 0.000335 | 0.000335 | 0.000335 | |
| 1000 | 0.000360 | 0.000385 | 0.000380 | 0.000371 | |
| 10000 | 0.000334 | 0.000312 | 0.000350 | 0.000374 | |
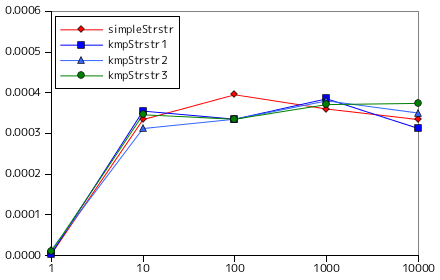 |
単純な文字列照合でのテスト条件と同様に、text のサイズを 35 万文字固定とし、その中から異なる長さの pattern を探索した時の処理時間を計測した結果が上に示した図表になります。ここでもグラフの横軸は対数で表現しています。kmpStrstr1 は、kmpTable の作成に最初に示した関数 makeKmpTable を利用した結果で、kmpStrstr2 はその高速版 makeKmpTable1 を利用した場合、最後の kmpStrstr3 は「テキストの注目位置を移動する量」を加味したバージョンでの計測結果を表します。simpleStrstr は、前節で示した basic_string 版の simpleStrstr の結果で、比較のために加えてあります。
結果としては、KMP 法も単純な照合処理も大差はありませんでした。KMP 法ではいくつかの高速化を試みましたが、どれも効果は全く見られません。
| text size | pattern size | 処理時間 (sec.) | |||
|---|---|---|---|---|---|
| simpleStrstr | kmpStrstr1 | kmpStrstr2 | kmpStrstr3 | ||
| 1000 | 10 | 0.000007 | 0.000001 | 0.000001 | 0.000001 |
| 10000 | 0.000056 | 0.000009 | 0.000008 | 0.000009 | |
| 100000 | 0.000182 | 0.000149 | 0.000142 | 0.000098 | |
| 1000000 | 0.000815 | 0.000871 | 0.000956 | 0.001000 | |
| 2500000 | 0.002269 | 0.002365 | 0.002773 | 0.002389 | |
| 5000000 | 0.004197 | 0.004782 | 0.004723 | 0.004856 | |
| 7500000 | 0.006670 | 0.007522 | 0.007273 | 0.007258 | |
| 10000000 | 0.008453 | 0.010088 | 0.009746 | 0.009796 | |
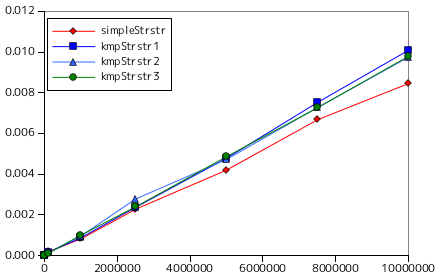 |
上の図表は、pattern のサイズは 10 文字固定とし、text のサイズを 1,000 から 10,000,000 まで変化させた時の推移を示しています。ここでは simpleStrstr が最も処理時間が短く、KMP 法での処理時間はどの場合もほとんど変化しないので、高速化の効果は全く見られません。
KMP 法を利用すると、文字の比較回数はだいたい N に等しくなり、最悪でも 2N となります。比較回数が最悪となる例としては、A が連続したテキストをパターン AB で照合するような場合で、このときは必ずパターン二文字目で不一致を起こし、不一致を起こしたした個所から再度パターンの先頭と照合する操作を繰り返すので、各文字を二回比較することになります。単純法の比較回数が最悪 m x N 回であることと比べると大きく性能が向上したように見えます。しかし、KMP 法はパターンの末尾側で不一致が発生したときにはじめて移動量が大きくなるため、通常の場合では前に述べたようにパターンの先頭付近で不一致が発生することを考えると、処理が複雑な上に前処理が必要になる分、かえって単純な文字列照合よりも遅くなることが考えられます。実際、サンプル・プログラムを使った計測結果では、単純な文字列照合処理よりも処理が長くなるという結果になっています。但し、ここでは完全にランダムな文字列を使ってテストしていて、実際の文字列照合処理は想定していません。通常の(我々が普段扱うような)文字列はランダムではなくあるパターンがあるので、そのような文字列でテストすれば異なる傾向が見られる可能性もあります。これについては、次章でまとめて調べてみたいと思います。
KMP 法のもう一つの特徴としては、テキストを走査する位置が逆戻りしないというものがあります。この特徴により、KMP 法はメモリに納まらないような長いテキストを扱うのに適していて、むしろこの特徴の方が KMP 法の大きな利点といえます。事実、発案者の Morris は、テキストエディタを作成中に逆戻りが発生しないような文字列照合アルゴリズムを考えた結果 KMP 法にたどり着いたという事です。
次回は、文字列照合アルゴリズムの続きとして BM 法を紹介したいと思います。
◆◇◆更新履歴◆◇◆
◎ KMP 法の高速版 kmpStrstr3 にコーディングミスが見つかりました。修正に加えて性能テストもやり直したので、その評価も少し変更しています (2013-10-14)
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |