前章に引き続き「文字列照合 ( String Matching )」のアルゴリズムから、この章では「Boyer-Moore(BM)法」を中心に紹介したいと思います。このアルゴリズムは、実用上最速な文字列照合アルゴリズムとして文字列検索ツールやエディタで数多く使用されているようです。また、日本語などの多バイト文字を処理する方法も後半で紹介したいと思います。
コンピュータ・サイエンティストの「Robert Stephen Boyer」と「J Strother Moore」、また両者とは独立に「Ralph William Gosper」が考案した「Boyer-Moore (BM) 法」の最大の特徴は、パターンを末尾側から逆方向に比較するということです。
テキストとパターンの先頭をそろえた後、今までのアルゴリズムではパターン先頭とテキスト先頭を比較するのですが、BM 法ではパターン末尾 ( これをパターン先頭から m 文字めとします ) の文字と、テキストの m 文字めの文字を比較します。もし一致していたら注目文字を一つ前にずらし、末尾側から逆方向に比較していきます。もし不一致が検出されたら、不一致を引き起こしたテキスト側の文字に注目して、もしその文字がパターン中に含まれていたら、両者が重なる位置までパターンを右にずらします。そうしないと、同じ場所で再び不一致を検出してしまうからです。また同じ理由により、不一致を引き起こしたテキスト上の文字がパターン中に含まれていない場合、不一致を起こしたテキスト上の文字より次の位置までパターン先頭をずらすことができます。この様子を下図に示します。
| 1) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | ← テキスト | 不一致箇所の文字は 'Y' |
| K | Y | O | K | U | ← パターン | 2 文字めは 'Y' | ||||||||||||
| 2) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | 不一致箇所の文字は 'Y' | |
| K | Y | O | K | U | 2 文字めは 'Y' | |||||||||||||
| 3) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | 不一致箇所の文字は 'A' | |
| K | Y | O | K | U | 'A' は含まれない | |||||||||||||
| 4) | T | O | K | K | Y | O | K | Y | O | K | A | K | Y | O | K | U | 照合成功 | |
| K | Y | O | K | U |
KMP 法同様、BM 法でもパターンの移動量をあらかじめテーブルに登録します。KMP 法のテーブルは不一致を起こしたパターン上の位置をキーにしていましたが、BM 法では不一致を起こした個所のテキスト側の文字自体がインデックスとなります。このテーブルには、右端の文字位置を 0 として、各文字がパターンの右端から何文字めに現れるかを登録します。パターン中に同じ文字が複数ある場合には、その最も末尾側の位置を採用します。パターンが "KYOKU" という文字であった場合は、パターンの文字列長は 5 で、
| 4 | 3 | 2 | 1 | 0 |
| K | Y | O | K | U |
だから、
| K | 1 |
| Y | 3 |
| O | 2 |
| U | 0 |
| それ以外 | 5 |
となります。
上で登録した移動量はあくまでも右端を起点としたものなので、不一致を起こした位置に応じて補正をする必要があります。例えば、パターン末尾から 2 文字めで不一致が検出されたら、テーブルの値から 1 を引かなければなりません。上の例で示したパターン "KYOKU" の末尾 "U" は他の位置にないため移動量が 0 となり、パターン末尾以外で不一致が検出され、テキスト側の文字が "U" であれば移動量は必ず負数となります (これをバックスライドと言いますが、詳細は後ほど説明します)。また、パターン末尾で不一致を起こした場合はテキスト側の文字が必ず "U" 以外になるので、移動量がゼロというのは意味のない値です。この場合は、パターン末尾の文字は最初から存在しないものとみなし、上の例では "U" に対する移動量は 5 としても問題はありません。パターン末尾と同じ文字が先頭側にあった場合、末尾以外の位置で最も末尾側に近いものを採用すればよく、従って末尾の文字に関してはチェックをする必要がないことを意味します。
まずはパターンの移動量をテーブルに登録する関数のサンプルを以下に示します。
/* makeBMTable : 移動量(bmTable)の作成 const basic_string<T>& pattern : 検索対象の文字列 map<T,typename basic_string<T>::size_type>& bmTable : 移動量を保持する配列 */ template<class T> void makeBMTable( const basic_string<T>& pattern, map<T,typename basic_string<T>::size_type>& bmTable ) { typename basic_string<T>::const_iterator patIt = pattern.begin(); // pattern に対する反復子 typename basic_string<T>::size_type counter = pattern.length(); // カウンタ bmTable.clear(); while ( counter > 1 ) bmTable[*patIt++] = --counter; }
処理は非常に単純で、文字コードをキー、移動する文字数を値とした map 型のコンテナ bmTable を用意し、次に ( パターンの長さ - 1 ) を初期値とするカウンタ ( counter ) を設け、パターン中の文字を先頭から順に抽出して、その文字に対応するテーブル上の要素にその時点でのカウンタ値を登録してはカウンタから 1 減じます。パターン中に同じ文字があった場合、同じ文字が出てくる度にテーブルを上書きすることになるため、テーブルには最も末尾側の位置が残ることになります。また、前に述べた理由により、counter は 1 になるまで登録をを行い、移動量がゼロになる文字の登録は行いません。
BM 法を実装する上で注意する必要のある問題として、テキスト上で不一致を起こした文字がパターンの比較位置より末尾側に含まれていた場合に生じるバックスライドがあります。以下にバックスライドの例を示します。
| ... | T | O | K | K | U | ... | ← 不一致箇所の文字は 'K' |
| K | Y | O | K | U | ← 4 文字めは 'K' | ||
| ... | T | O | K | K | U | ... | |
| K | Y | O | K | U | ←バックスライド | ||
上の例では、パターン末尾から 3 文字めで不一致が検出され、不一致を起こしたテキスト上の文字が "K" なので、テーブルに登録された値は 1 であり移動量は 1 - 2 = -1 になります。このまま処理を続けると、次にパターンの末尾 "U" で不一致を起こし、照合対象のテキストの文字は "K" なので移動量は 1 - 0 = 1 となって最初の状態に戻ってしまいます。このように無限ループに陥ってしまうのを避けるため、バックスライドが発生した場合は必ず最低一文字分パターンを右に移動しなければならないのですが、実はパターンを右一文字ではなく "二文字分" 移動しても問題ありません。というのも、あと一文字パターンが右へ移動すれば文字列が全て一致する場合は、不一致を生じた位置より末尾側にあるパターンの文字は全て一致し、それは必ず不一致を起こしたテキストの文字とは一致しないため、バックスライドが生じないからです。逆に、バックスライドが発生した場合は一文字スライドしても一致は決してしないことを意味します。以下に詳細を示します。
| ... | X | A | B | C | D | E | F | G | ... |
| A | B | C | D | E | F | G |
末尾側の 3 文字は一致したのだから
よって
4 文字めで不一致が発生したから
よって末尾側の 3 文字 ( E, F, G ) と不一致を起こしたテキスト上の文字 ( C ) が一致することはなく、バックスライドは発生しない
* パターン末尾で不一致を起こした場合は、注目位置より末尾側の文字はパターン上にないから当然バックスライドは発生しません。念のため。
以下に、BM 法による文字列照合アルゴリズムのサンプルを示します。
/* bmStrstr : BM法による文字列照合 const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type txtIdx : 検索開始位置 戻り値 : 一致した位置( npos ならば見つからなかった) */ template<class T> typename basic_string<T>::size_type bmStrstr( const basic_string<T>& text, const basic_string<T>& pattern, typename basic_string<T>::size_type txtIdx ) { typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 typename basic_string<T>::size_type txtLen = text.length(); // text の文字列長 if ( txtLen < patLen ) return( basic_string<T>::npos ); txtLen -= patLen; // 不一致時のパターンの移動量を求める map<T,typename basic_string<T>::size_type> bmTable; makeBMTable( pattern, bmTable ); while ( txtIdx <= txtLen ) { typename basic_string<T>::size_type patIdx = patLen; // 比較位置 for ( ; patIdx > 0 ; --patIdx ) if ( text[txtIdx + patIdx - 1] != pattern[patIdx - 1] ) break; if ( patIdx == 0 ) return( txtIdx ); // 全て一致した!! // テーブルから移動量を求める typename map<T,typename basic_string<T>::size_type>::const_iterator mapIt = // bmTableの登録位置 bmTable.find( text[txtIdx + patIdx - 1] ); typename basic_string<T>::size_type shtIdx = patIdx; // 移動量(不一致発生位置で初期化) if ( mapIt != bmTable.end() ) { typename basic_string<T>::size_type i1 = mapIt->second; // 末尾を基準とした移動量 typename basic_string<T>::size_type i2 = patLen - patIdx; // 補正量(末尾と不一致文字の差分) shtIdx = ( i1 < i2 ) ? 2 : i1 - i2; } txtIdx += shtIdx; } return( basic_string<T>::npos ); }
bmTable にはパターン上の文字コードに対する移動量しか登録されていないので、パターンには存在しない文字に対しては、無条件でパターン上での不一致発生位置を移動量としています。末尾の文字が不一致であればこの値は文字列長と等しくなり、不一致を起こしたテキスト上の文字はパターンのどこにも存在しない文字なので、完全に重ならないように移動できることになります。例えばパターンの (先頭から) 三文字めで不一致を起こしたのであれば、テキスト上の次の文字がパターンの先頭になるように移動すればよいので、移動量は 3 になります。patIdx がこれらの値と等しくなることは、ループ処理の最初に行われる比較処理から容易に理解できると思います。
不一致を起こしたテキスト上の文字がパターンに存在する文字だった場合、bmTable に登録されている移動量を i1 に代入します。この値はパターン末尾で不一致を起こした時を基準としているので、そうではない場合は補正量の計算が必要です。例えば、パターンの末尾から二文字めで不一致が発生したのであれば、移動量を 1 だけ小さくすればいいので、補正量は 1 になります。補正量は i2 としてパターンの文字列長 patLen と不一致発生個所 patIdx の差から求めています。i1 - i2 が負数だった場合、バックスライドが発生したことを意味します。このときは前に説明した通り、移動量は強制的に 2 とすることができます。
上で紹介した方法は、BM 法のアルゴリズムの半分だけを利用した簡略版であり、オリジナルの方法では、KMP 法に似た考え方を用いた移動量を第二のテーブルとして用意して、二つのテーブルのうち移動量のより大きい方を採用する仕組みになっています。パターンの末尾側から照合して途中で不一致を検出した時、一致した末尾側の文字列 ( 以下、この部分文字列を s1 とします ) がパターンのより前側にあって ( この部分文字列は s0 とします )、しかもパターン上で s0 と s1 の一つ前にある文字が一致していなければ、テキスト上の s1 に照合した位置まで s0 がちょうど重なるようにパターンを移動して照合を再開します。パターン上で s0 と s1 の一つ前にある文字が一致していると、照合は同じ位置で再び失敗することになるので、これらは異なる文字でなければなりません。従って、s0 がパターンの先頭にあるのならば、無条件で移動させることができます。
| ... | Z | O | O | Z | O | O | ... | ||
| B | O | O | D | O | O | ||||
| s1 | |||||||||
| ... | Z | O | O | Z | O | O | ... | ||
| O | O | O | O | ||||||
| s0 | s1 | ||||||||
| ... | Z | O | O | Z | O | O | ... | ||
| B | O | O | D | O | O | ||||
| 0 | 1 | 2 | 3 | ||||||
上記の例の場合、s1 の "OO" はパターンの 2 文字めにもあり、両者の一つ前の文字はそれぞれ "D" と "B" なので異なります。従って、パターン 2 文字めと 3 文字めの "OO" を s0 として、s0 が s1 の位置に重なるようにします。インデックスをゼロから始める ( つまり、1 文字めのインデックスをゼロとする ) 場合、s0 の末尾のインデックスは 2 になり、その文字がパターン末尾の添字 5 になればよいので、移動量は 5 - 2 = 3 になります。パターンの先頭から i 番め ( ここでも i はゼロから開始するとします。すなわち、先頭の文字に対しては i = 0 です ) で不一致を検出したときの移動量を保持した配列の要素を shift[i] としたとき、上の例では i = 3 のときに不一致を検出したので shift[3] = 3 になります。
少し注意しなければならないのは配列 shift の末尾の要素で、これはパターンの末尾ですぐに不一致を検出した場合の移動量を意味します。このときは部分文字列 s1 そのものが存在しないので、無条件で「一致した」と見なして、パターン末尾の文字と異なる文字の位置を探すことになります。
s1 と一致する部分が存在しない場合、今度は s1 の中の末尾がパターンの先頭と一致しないかをチェックします。一致する個所があれば、その位置がパターンの先頭になるように移動します。
| ... | Z | A | A | X | Y | Z | ... | |||
| Y | Z | Y | X | Y | Z | |||||
| s1 | ||||||||||
| ... | Z | A | A | X | Y | Z | ... | |||
| Y | Z | Y | X | Y | Z | |||||
| ... | Z | A | A | X | Y | Z | ... | |||
| Y | Z | Y | X | Y | Z | |||||
| 0 | 1 | 2 | 3 | 4 | ||||||
上記の例では、パターンの先頭から 3 文字めで不一致を検出しています。s1 の "XYZ" と一致する部分文字列 s0 は存在しないので、最初に示したルールに従えば、照合した文字列に重ならないように 6 文字分パターンを右へ移動させることになります。しかし、実際には s1 の末尾とパターン先頭にある 2 文字 "YZ" が一致しているので、それらが重なるように移動させるとパターン全体が完全に一致する可能性があります。従って、移動量は 6 ではなく、その値から一致した文字数 2 を引いた 4 になります ( つまり、shift[2] = 4 になります )。s0 と s1 が末尾側の一部だけ一致した状態であることを意味しているので、最初に示した場合において s0 の先頭側が欠けた状態になっているだけで、内容としてはほぼ同じであると考えることができます。
どちらに対しても該当する部分文字列が見つからない場合は、照合した部分に完全に重ならないように、パターンの文字列長だけ右に移動させることになります。
正式な BM 法のサンプル・プログラムを以下に示します。
/* makeBMTable2 : 第二の移動量の作成 const basic_string<T>& pattern : 検索対象の文字列 vector<basic_string<T>::size_type>& bmTable : 移動量を保持する配列 */ template<class T> void makeBMTable2( const basic_string<T>& pattern, vector<typename basic_string<T>::size_type>& bmTable ) { typename basic_string<T>::size_type sIdx1 = pattern.length(); // 部分文字列 s1 の先頭 bmTable.assign( sIdx1, basic_string<T>::npos ); if ( sIdx1 == 0 ) return; // 部分文字列 s0 の候補を登録(末尾の文字と一致する文字位置) vector<typename basic_string<T>::size_type> nextIdx; // 部分文字列 s0 の候補 for ( typename basic_string<T>::size_type sIdx0 = sIdx1 - 1 ; sIdx0 > 0 ; --sIdx0 ) { if ( pattern[sIdx0 - 1] == pattern[sIdx1 - 1] ) { nextIdx.push_back( sIdx0 - 1 ); // 最初に不一致を起こした個所は、最初の文字が不一致の場合の比較開始個所 } else if ( bmTable[sIdx1 - 1] == basic_string<T>::npos ) { bmTable[sIdx1 - 1] = pattern.length() - sIdx0; } } if ( bmTable[sIdx1 - 1] == basic_string<T>::npos ) bmTable[sIdx1 - 1] = pattern.length(); // s1 と一致してその前の文字は異なる文字列を検索 typename basic_string<T>::size_type sLen = 2; // 照合する部分文字列の長さ for ( --sIdx1 ; sIdx1 > 0 ; --sIdx1 ) { for ( unsigned int i = 0 ; i < nextIdx.size() ; ) { typename basic_string<T>::size_type sIdx0 = nextIdx[i]; // 部分文字列 s0 の先頭候補 // s0 != s1 または s0 が先頭にある場合 if ( sIdx0 == 0 || pattern[sIdx0 - 1] != pattern[sIdx1 - 1] ) { nextIdx.erase( nextIdx.begin() + i ); if ( bmTable[sIdx1 - 1] == basic_string<T>::npos ) bmTable[sIdx1 - 1] = pattern.length() - ( sIdx0 + sLen - 1 ); } else { --nextIdx[i]; ++i; } } if ( nextIdx.size() == 0 ) break; ++sLen; } // s1 の末尾がパターン先頭と一致するかをチェック sIdx1 = pattern.length(); typename basic_string<T>::size_type curIdx1 = basic_string<T>::npos; // 先頭と一致する末尾の文字列の開始位置(退避用) while ( sIdx1 > 1 ) { --sIdx1; if ( bmTable[sIdx1 - 1] != basic_string<T>::npos ) continue; sLen = pattern.length() - sIdx1; typename basic_string<T>::size_type i = 0; // s1 のパターン先頭との照合開始位置 while ( sLen > 0 ) { if ( strncmp_( pattern.begin(), pattern.begin() + sIdx1 + i, sLen ) == 0 ) break; ++i; --sLen; } if ( curIdx1 == pattern.length() - sLen ) break; // これ以上 sIdx0 は変化しない bmTable[sIdx1 - 1] = curIdx1 = pattern.length() - sLen; } // 残りは全て最後に得られた curIdx1 とする while ( sIdx1 > 0 ) { if ( bmTable[sIdx1 - 1] == basic_string<T>::npos ) bmTable[sIdx1 - 1] = curIdx1; --sIdx1; } } /* formalBMStrstr : BM法による文字列照合(正式版) const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type txtIdx : 検索開始位置 戻り値 : 一致した位置( npos ならば見つからなかった) */ template<class T> typename basic_string<T>::size_type formalBMStrstr( const basic_string<T>& text, const basic_string<T>& pattern, typename basic_string<T>::size_type txtIdx ) { typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 typename basic_string<T>::size_type txtLen = text.length(); // text の文字列長 if ( txtLen < patLen ) return( basic_string<T>::npos ); txtLen -= patLen; // 不一致時のパターンの移動量を求める map<T,typename basic_string<T>::size_type> bmTable1; // The Bad Character Rule makeBMTable( pattern, bmTable1 ); vector<typename basic_string<T>::size_type> bmTable2; // The Good Suffix Rule makeBMTable2( pattern, bmTable2 ); while ( txtIdx <= txtLen ) { typename basic_string<T>::size_type patIdx = patLen; // 比較位置 for ( ; patIdx > 0 ; --patIdx ) if ( text[txtIdx + patIdx - 1] != pattern[patIdx - 1] ) break; if ( patIdx == 0 ) return( txtIdx ); // 全て一致した!! // テーブルから移動量を求める typename map<T,typename basic_string<T>::size_type>::const_iterator mapIt = // bmTable1 の登録位置 bmTable1.find( text[txtIdx + patIdx - 1] ); typename basic_string<T>::size_type shtIdx1 = patIdx; // 移動量(不一致発生位置で初期化) if ( mapIt != bmTable1.end() ) { typename basic_string<T>::size_type i1 = mapIt->second; // 末尾を基準とした移動量 typename basic_string<T>::size_type i2 = patLen - patIdx; // 補正量(末尾と不一致文字の差分) shtIdx1 = ( i1 < i2 ) ? 2 : i1 - i2; } txtIdx += std::max( shtIdx1, bmTable2[patIdx - 1] ); // bmTable1 と bmTable2 の移動量が大きい方を選択 } return( basic_string<T>::npos ); }
makeBMTable2 は、第二のテーブルを作成するために使われます。前述したように、このプログラムは大きく 4 つの処理に分割することができます。
各処理を行う前に、移動量を保持する配列 bmTable を初期化します。bmTable の要素数はパターンの文字列長と等しく、その要素は npos ( 文字列 basic_string<T> の最大値 ) とします。最初のループが一番めの処理に該当し、ここでは部分文字列 s0 の候補を配列 nextIdx に登録する処理を行います。末尾の文字と一致した個所は、s0 の末尾である可能性があるためその位置を登録すると同時に、最初に不一致を検出した個所は、末尾の文字で不一致を検出した場合にその位置に重なるようにパターンを移動させることができることを意味するので、bmTable の末尾の要素をその位置を使って決めることができます。
| 0 | 1 | 2 | 3 | 4 | 5 | ||||
| パターン | A | A | B | A | B | A | ... | nextIdx = { 3, 1, 0 } | |
| テキスト | ? | ? | ? | ? | ? | ||||
| A | A | B | A | B | A | ... | bmTable[5] = 1 | ||
上の例において、パターン上で末尾の文字 "A" と一致する位置は 0, 1, 3 の 3 ヶ所で、これらの値が降順になるように nextIdx に登録しておきます。このとき、末尾の位置に対する bmTable の値 bmTable[5] は、パターン長 6 から不一致を起こした個所 + 1 ( この場合は 4 + 1 = 5 ) を引いた 1 になります。
二番めのループ処理で、部分文字列 s0 の候補となる文字列を前側に伸ばしながら末尾の部分文字列 s0 と比較します。一致しなかった、あるいは s0 が先頭にあった場合は、次からは候補ではないので nextIdx から除外し、逆にその位置での移動量が得られたことになるので、最初に見つかった(末尾側により近い方の)位置を bmTable へ登録します。一致した場合、候補としては残す必要があるので、nextIdx の対象要素の値から 1 を引いて部分文字列 s0 の先頭を前側にずらします。
| 0 | 1 | 2 | 3 | 4 | 5 | |||||||
| パターン | A A | B A | B A | ... | nextIdx = { 2 } | |||||||
| テキスト | ? | ? | ? | ? | A | |||||||
| A | A | B | A | B | A | ... | bmTable[4] = 4 | |||||
先の例において、比較文字数を 2 にすると、nextIdx = 3 の場合だけ文字列 "BA" として一致するので、候補はこのひとつだけになり、その位置は 1 を引いた 2 になります。nextIdx = 0 は先頭になり、nextIdx = 1 は前側の文字が不一致を起こすので両方とも候補から外れます。移動する位置は nextIdx = 1 のときで、bmTable[4] の値はパターン長 6 から、s0 の先頭に s0 の文字列長を加えたもの ( すなわち s0 の末尾文字の次の位置 ) を引いた値で、6 - ( 0 + 2 ) = 4 となります。
| 0 | 1 | 2 | 3 | 4 | 5 | |||||
| パターン | A | A B | A B A | ... | nextIdx = { 1 } | |||||
| A | A | B A B A | ... | nextIdx = {} | ||||||
| テキスト | ? | ? | A | B | A | |||||
| A | A | B | A | B | A | ... | bmTable[2] = 2 | |||
比較文字数が 3 のとき、nextIdx = 2 の場合は文字列 "ABA" として末尾の文字列と一致するのでまだ候補として残り、その位置は 1 になります。不一致は検出されず、bmTable[3] には何も登録されません。比較文字数を 4 まで増やすと、nextIdx = 1 の場合は文字列 "AABA" であり、末尾の "BABA" とは一致しません。よって、この要素は削除され、bmTable[2] = 2 になります。これで nextIdx は空となり、ループから抜けます。
3 番めのループ処理は、末尾の部分文字列 s1 の中で、さらにその末尾の部分が先頭の部分文字列 s0 と一致するかを検出する処理を行っています。
| 0 | 1 | 2 | 3 | 4 | 5 | |||||||||
| パターン | Y | Z | Z | X | Z | |||||||||
| Y | Z | Z | X | Y | Z | ... | bmTable[4] = 6 | |||||||
| パターン | Y | Z | Z | Y | Z | |||||||||
| Y | Z | Z | X | Y | Z | ... | bmTable[3] = 4 | |||||||
| パターン | Y | Z | X | Y | Z | |||||||||
| Y | Z | Z | X | Y | Z | ... | bmTable[2] = 4 | |||||||
| パターン | Y | Z | X | Y | Z | |||||||||
| Y | Z | Z | X | Y | Z | ... | bmTable[1] = 4 | |||||||
| パターン | Z | Z | X | Y | Z | |||||||||
| Y | Z | Z | X | Y | Z | ... | bmTable[0] = 4 | |||||||
上記の例をみると明らかなように、末尾から順に文字列 s1 の長さを増やしていくと、ある時点で一致する箇所がそれ以上増えなくなります。これを検出すれば、残りのまだ移動量が登録されていない要素は全て同じ値で登録してしまうことができます。
2 番めと 3 番めのループ処理において、同一の要素に対してそれぞれで異なる位置が検出される場合があります。しかし、2 番めのループ処理がパターンの途中にある一致文字列を検出するのに対し、3 番めの場合は先頭と末尾の一致を検出しているので、明らかに前者の方が移動量は少なくなります。つまり後者を採用すると一致を見逃す可能性があり、前者の処理ですでに移動量が確定している場合は後者の処理は不要です。3 番めのループ処理では、すでに移動量が確定している場合は処理をスキップしています。
最後の 4 番めのループ処理では、3 番めの処理で確定した固定の移動量をまだ未確定の要素に登録します。これで全ての要素に対して移動量が確定したことになります。
最初に示した、不一致を検出した時のテキストの文字をパターンの中の一致する文字と合わせる方法は「The Bad Character Rule」と呼ばれるのに対し、後者の、KMP 法によく似たやり方は「The Good Suffix Rule」といいます (*1-1)。The Good Suffix Rule は平均の性能にあまり貢献せず、作成も面倒であるため、通常は最初に示した簡略版が主に利用されるようです。オリジナル BM 法のメリットとしては、バックスライドが発生しないことと、「最悪の場合」でも比較回数を KMP 法と同じ程度に抑えられることが挙げられます。なお、Boyer と Moore が最初に考案した方法は、部分文字列 s1 と s0 が同じであれば、その前側の文字はチェックせずに採用するというものでした。これは「Weak Good Suffix Rule」というのに対し、前側の文字の不一致もチェックする方式は「Strong Good Suffix Rule」といいます。KMP 法でも高速化の手法として、一致した文字列の次の文字を照合し、一致したら (テキストとの文字列照合時は必ず不一致となるので) 採用しないという処理を追加していますが、これと同じ原理になります。
上に述べた「最悪の場合」ですが、同じ文字コードからなるテキストから、それとは異なる文字コードを一つだけ先頭に持ち、あとに続く文字は全てテキストの文字コードと同じパターンを検索する場合を想定すればいいでしょう。例えばテキスト "AAA......A" からパターン "BAAA......A" を検索する場合などです。この時は、パターンの後ろから順に比較をして先頭文字で不一致を検出し、(バックスライドのため)二文字だけ右へ移動する動作を繰り返すことになります。The Good Suffix Rule を適用した場合、照合した部分文字列末尾の次の位置までパターンの先頭を移動することができるので、比較回数は劇的に少なくなります。
BM 法が発表されたのは 1977 年で、KMP 法と同時期でした。前述の通り、発表時は「The Bad Character Rule」と「The Good Suffix Rule」の二つの方式を採用していましたが、一般的には前者の「The Bad Character Rule」のみが採用されています。その後、「The Bad Character Rule」に対してさらに最適化が行われ、現在はそれら最適化されたバージョンが広く用いられています。最適化手法の中からまずは Horspool のアルゴリズムを紹介します。
オリジナルの BM 法は、不一致を検出した位置でのテキストの文字が一致するようにパターンを移動するというやり方でした。これを改良して、常にパターン末尾と照合した位置の文字と一致する形にしたのが「Horspool のアルゴリズム (Horspool Algorithm)」で、「Boyer-Moore-Horspool(BMH) 法」などとも呼ばれています。このアルゴリズムはビクトリア大学のコンピュータ科学教授「R. Nigel Horspool」によって 1980 年に発表されました。以下に、BMH 法を適用した場合の処理の様子を示します。
| 1) | A | B | S | J | A | C | K | A | B | C | ← テキスト | 不一致箇所の文字は 'S' | | | 末尾の文字は 'S' |
| A | B | C | ← パターン | 'S' は含まれない | ||||||||||
| 2) | A | B | S | J | A | C | K | A | B | C | 不一致箇所の文字は 'A' | | | 末尾の文字は 'C' | |
| A | B | C | 'C' は(末尾以外には)含まれない | |||||||||||
| 3) | A | B | S | J | A | C | K | A | B | C | 不一致箇所の文字は 'B' | | | 末尾の文字は 'B' | |
| A | B | C | 2 文字めは 'B' | |||||||||||
| 4) | A | B | S | J | A | C | K | A | B | C | 照合成功 | |||
| A | B | C | ||||||||||||
最初の処理は BM 法の場合と変わりませんが、二番目の処理では、BM 法の場合、不一致を起こした個所のテキストの文字 "A" を使うことになるので一文字分しか移動しないのに対し、BMH 法では末尾の "C" を使い、パターンの末尾以外には "C" がないことから一気に 3 文字分移動しています。このように、常にパターン末尾と照合した位置に着目した方が移動する量が多くなる可能性が高くなり、より効率よく処理することができるようになります。また、その他にもバックスライドが発生しないという利点があります。というのも、常にパターン末尾を起点に移動することになるので、末尾側に文字がある場合を考慮する必要がないからです。なお、BM 法の時と同様に、移動量を求める際にパターン末尾の文字は無視することができます (というより無視しなければなりません)。
BMH 法のサンプル・プログラムを以下に示します。
/* bmhStrstr : BMH法による文字列照合 const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type txtIdx : 検索開始位置 戻り値 : 一致した位置( npos ならば見つからなかった) */ template<class T> typename basic_string<T>::size_type bmhStrstr( const basic_string<T>& text, const basic_string<T>& pattern, typename basic_string<T>::size_type txtIdx ) { typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 typename basic_string<T>::size_type txtLen = text.length(); // text の文字列長 if ( txtLen < patLen ) return( basic_string<T>::npos ); txtLen -= patLen; // 不一致時のパターンの移動量を求める map<T,typename basic_string<T>::size_type> bmTable; makeBMTable( pattern, bmTable ); while ( txtIdx <= txtLen ) { typename basic_string<T>::size_type patIdx = patLen; // 比較位置 for ( ; patIdx > 0 ; --patIdx ) if ( text[txtIdx + patIdx - 1] != pattern[patIdx - 1] ) break; if ( patIdx == 0 ) return( txtIdx ); // 全て一致した!! // テーブルから移動量を求める typename map<T,typename basic_string<T>::size_type>::const_iterator mapIt = // bmTableの登録位置 bmTable.find( text[txtIdx + patLen - 1] ); txtIdx += ( mapIt != bmTable.end() ) ? mapIt->second : patLen; // 移動量を加算 } return( basic_string<T>::npos ); }
常にパターン末尾が起点になるため、BM 法のように不一致個所によって補正を行う必要がなく、バックスライドについても考慮する必要がないことから、BM 法よりもシンプルな実装内容になっています。
BMH 法をさらに改良したアルゴリズムが「Sunday のアルゴリズム (Sunday Algorithm)」で、別名「Quick Search Algorithm」とも呼ばれています。Sunday のアルゴリズムは、「Daniel M. Sunday」によって 1990 年に発表されました。BMH 法と Sunday のアルゴリズムとの違いは、前者が末尾の文字を着目しているのに対し、後者は末尾の次の文字に着目するという点だけです。以下に、例を示します。
| 1) | A | B | S | J | A | C | K | A | B | C | ← テキスト | 末尾の文字は 'S' | | | 末尾の次の文字は 'J' |
| A | B | C | ← パターン | 'J' は含まれない | ||||||||||
| 2) | A | B | S | J | A | C | K | A | B | C | 末尾の文字は 'K' | | | 末尾の次の文字は 'A' | |
| A | B | C | 1 文字目は 'A' | |||||||||||
| 3) | A | B | S | J | A | C | K | A | B | C | 照合成功 | |||
| A | B | C | ||||||||||||
最初の処理において、テキスト上の末尾の次の文字は "J" でパターンには含まれないので、パターンの先頭をテキスト "J" の次の位置まで一気に移動させることができます。二番目の処理では末尾の次の文字が "A" なので、パターンの先頭にある "A" と重なるように移動することになります。すると、BMH 法より一回少ない移動回数で照合個所が見つかることになります。
Sunday 法のアルゴリズムのサンプル・プログラムを以下に示します。
/* makeSundayTable : シフト量の作成(Sundayのアルゴリズム専用) const basic_string<T>& pattern : 検索対象の文字列 map<T,typename basic_string<T>::size_type>& bmTable : 移動量を保持する配列 */ template<class T> void makeSundayTable( const basic_string<T>& pattern, map<T,typename basic_string<T>::size_type>& bmTable ) { typename basic_string<T>::const_iterator patIt = pattern.begin(); // pattern に対する反復子 typename basic_string<T>::size_type counter = pattern.length(); // カウンタ bmTable.clear(); while ( counter > 0 ) bmTable[*patIt++] = counter--; } /* sundayStrstr : Sundayアルゴリズムによる文字列照合 const basic_string<T>& text : 検索先文字列 const basic_string<T>& pattern : 検索対象の文字列 typename basic_string<T>::size_type txtIdx : 検索開始位置 戻り値 : 一致した位置( npos ならば見つからなかった) */ template<class T> typename basic_string<T>::size_type sundayStrstr( const basic_string<T>& text, const basic_string<T>& pattern, typename basic_string<T>::size_type txtIdx ) { typename basic_string<T>::size_type patLen = pattern.length(); // pattern の文字列長 typename basic_string<T>::size_type txtLen = text.length(); // text の文字列長 if ( txtLen < patLen ) return( basic_string<T>::npos ); txtLen -= patLen; // 不一致時のパターンの移動量を求める map<T,typename basic_string<T>::size_type> bmTable; makeSundayTable( pattern, bmTable ); while ( txtIdx <= txtLen ) { typename basic_string<T>::size_type patIdx = patLen; // 比較位置 for ( ; patIdx > 0 ; --patIdx ) if ( text[txtIdx + patIdx - 1] != pattern[patIdx - 1] ) break; if ( patIdx == 0 ) return( txtIdx ); // 全て一致した!! if ( txtIdx == txtLen ) break; // 末尾の次の文字がない場合は処理を終了(一致する文字列はなかった) // テーブルから移動量を求める typename map<T,typename basic_string<T>::size_type>::const_iterator mapIt = // bmTableの登録位置 bmTable.find( text[txtIdx + patLen] ); txtIdx += ( mapIt != bmTable.end() ) ? mapIt->second : patLen + 1; // 移動量を加算 } return( basic_string<T>::npos ); }
末尾の次の文字に着目しているため、BMH 法に比べて移動量は一つだけ大きくなります。それを考慮して、移動量の算出プログラムも専用のものを用意しています。Sunday 法の場合はパターン末尾の文字がテキスト側の末尾の次の文字に一致した場合も 1 だけ移動することができるので、移動量算出の対象としていることに注意して下さい。また、文字列照合ルーチン内では、ちょうど末尾で不一致となった場合、末尾の次の文字は存在しないのでループから抜ける処理を加えています。その他は基本的に BMH 法と変わりはありません。
不一致が検出されたとき、末尾の文字、さらにはその次の文字がパターンのいずれかの個所と一致しない限り、移動させても一致することはありません。結局、不一致を起こした個所で位置合わせを行うことはまだ無駄のある可能性があったということになります。BM 法が発表されたのが 1977 年で、それから 13 年後の 1990 年に Sunday のアルゴリズムが発表されるまで誰もそのことに気づかなったというのは、それだけ文字列照合に対する関心があまりないということになるのでしょうか。
*1-1) The Good Suffix Rule を適用した場合、前回の照合時に末尾からたどって不一致を起こした個所までの文字列は一致していることが保証されています。特に、パターンの末尾と先頭が一致している場合 (二番目に示した例、サンプル・プログラムでは三番目の処理で得られる移動量) は、パターンの先頭が前回の不一致個所と末尾の間に位置し、しかも前回比較を開始した末尾部分までは一致していることが保証されるので、その範囲の比較は不要になります。この最適化を「ガリル規則 (Galil Rule)」といいます。以下の例を見ると理解しやすいと思います。
| ... | X | Y | X | Y | Z | ... | ← テキスト | ||||
| Y | Z | Y | X | Y | Z | ← パターン | |||||
| ... | X | Y | Z | X | Y | Z | ... | ||||
| Y | Z | Y | X | Y | Z | ← パターン先頭の "YZ" は一致していることが保証される | |||||
以下に、各アルゴリズムを使って文字列照合処理を行ったときの処理時間を示します。テストの条件は、次の A から D までの四通りになります。
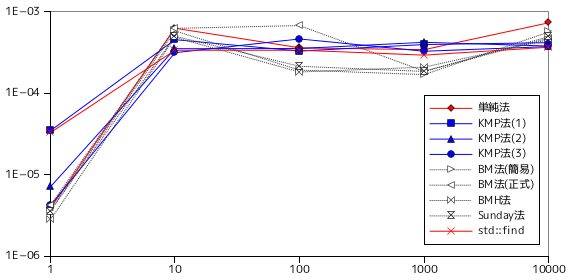
上記の条件に対し、テキストとパターンの文字列長を変化させながら、各条件に対して 10 回処理を行い、その合計時間を表に示しています。まずはテスト A の計測結果を以下に示します。下表において、「単純法」は一番初めに紹介した「単純な文字列照合」のサンプル・プログラムを、KMP 法は前章で紹介したアルゴリズムで、(1) が最初に示したサンプル・プログラム、(2) が不一致を起こした個所の文字も考慮した最適化バージョン、(3) はさらに先頭の文字に対しても不一致の可能性をチェックしたバージョンをそれぞれ表します。BM 法は今回紹介したアルゴリズムで、(簡易)は「The Bad Character Rule」のみを適用したバージョン、(正式)は「Strong Good Suffix Rule」まで適用したバージョンです。また、その後に続いて「Horspool のアルゴリズム (BMH 法)」と「Sunday のアルゴリズム」の結果を示しています。最後の std::find は、比較用に std::string の文字列照合メンバ関数 find を使った処理結果です。表の下側にはグラフを示していますが、パターン長に対する処理時間の推移は、横軸・縦軸ともに対数で表されていることに注意して下さい。
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 350,000 | 1 | 0.000004 | 0.000035 | 0.000007 | 0.000004 | 0.000004 | 0.000004 | 0.000003 | 0.000004 | 0.000033 |
| 10 | 0.000630 | 0.000456 | 0.000353 | 0.000316 | 0.000585 | 0.000628 | 0.000487 | 0.000503 | 0.000338 | |
| 100 | 0.000362 | 0.000330 | 0.000355 | 0.000465 | 0.000193 | 0.000679 | 0.000183 | 0.000215 | 0.000338 | |
| 1,000 | 0.000344 | 0.000398 | 0.000423 | 0.000329 | 0.000170 | 0.000187 | 0.000210 | 0.000186 | 0.000295 | |
| 10,000 | 0.000735 | 0.000419 | 0.000381 | 0.000375 | 0.000567 | 0.000478 | 0.000457 | 0.000498 | 0.000368 | |
| ||||||||||
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 1,000 | 10 | 0.000022 | 0.000003 | 0.000002 | 0.000002 | 0.000008 | 0.000009 | 0.000002 | 0.000007 | 0.000002 |
| 10,000 | 0.000025 | 0.000020 | 0.000023 | 0.000030 | 0.000052 | 0.000049 | 0.000037 | 0.000031 | 0.000014 | |
| 100,000 | 0.000506 | 0.000099 | 0.000100 | 0.000124 | 0.000165 | 0.000216 | 0.000140 | 0.000155 | 0.000110 | |
| 1,000,000 | 0.001027 | 0.001025 | 0.000862 | 0.000919 | 0.001774 | 0.001898 | 0.001460 | 0.001849 | 0.000902 | |
| 2,500,000 | 0.002739 | 0.002449 | 0.002274 | 0.002580 | 0.003978 | 0.004528 | 0.003640 | 0.003831 | 0.002228 | |
| 5,000,000 | 0.004719 | 0.005041 | 0.005038 | 0.005139 | 0.008859 | 0.009401 | 0.007230 | 0.007714 | 0.004522 | |
| 7,500,000 | 0.006888 | 0.007763 | 0.007801 | 0.007809 | 0.012254 | 0.014248 | 0.011678 | 0.012140 | 0.007019 | |
| 10,000,000 | 0.009356 | 0.011256 | 0.010207 | 0.010272 | 0.015858 | 0.020235 | 0.015125 | 0.016157 | 0.009361 | |
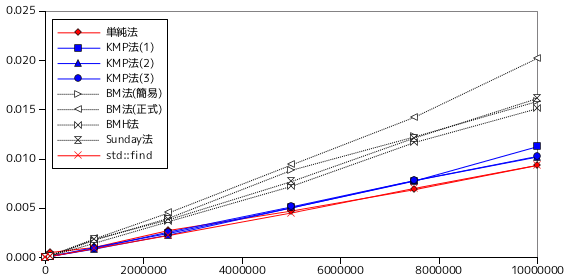 | ||||||||||
テスト A は、完全にランダムな文字列を使った照合テストであり、パターン長が 1 でない限りは一致する文字列は見つからず、テキストの最後まで照合を行うことになります。どの処理も、パターン長による処理時間の推移はほとんど変化していません。唯一、パターン長が 1 の場合は処理時間が非常に短くなっていますが、これはテキストの途中で(しかも先頭に近いほうで)一致する文字列が見つかる可能性が非常に高いためです。
パターン長がどれだけ長くなっても、比較的早く不一致が検出できれば処理時間には影響はしないため、このような結果になったと推定できます。しかし、パターンを使って前処理を行う必要のある KMP 法や BM 法は、前処理の実装によって処理時間に大きく影響を与えてしまう可能性もあります。
テキスト長に対する処理時間は、どの場合も線形に増加する傾向にあります。BM 法は、他のアルゴリズムに比べて処理時間が長くなる結果になりました。このテストは完全にランダムな文字列を使って行なっているので、文字の出現頻度や並び方に一定の偏りがある通常の文字列とは異なり、余計な処理の加わったアルゴリズムの方が不利となる結果になっています。KMP 法に対しても、単純な方法に比べると若干処理時間が長くなる傾向にあります。
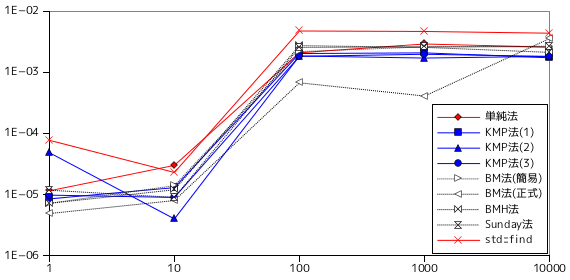
次はテスト B の、極端に文字種が少ない文字列による照合結果を示します。
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 350,000 | 1 | 0.000012 | 0.000008 | 0.000048 | 0.000010 | 0.000007 | 0.000005 | 0.000007 | 0.000012 | 0.000077 |
| 10 | 0.000030 | 0.000013 | 0.000004 | 0.000009 | 0.000014 | 0.000008 | 0.000012 | 0.000009 | 0.000023 | |
| 100 | 0.002079 | 0.002022 | 0.001841 | 0.001822 | 0.002170 | 0.000672 | 0.002716 | 0.002541 | 0.004725 | |
| 1,000 | 0.002898 | 0.002075 | 0.001705 | 0.001967 | 0.002596 | 0.000408 | 0.002548 | 0.002597 | 0.004643 | |
| 10,000 | 0.002560 | 0.001721 | 0.001818 | 0.001816 | 0.002660 | 0.003552 | 0.002110 | 0.002609 | 0.004343 | |
 | ||||||||||
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 1,000 | 10 | 0.000009 | 0.000023 | 0.000006 | 0.000049 | 0.000024 | 0.000011 | 0.000008 | 0.000013 | 0.000014 |
| 10,000 | 0.000015 | 0.000019 | 0.000023 | 0.000017 | 0.000015 | 0.000015 | 0.000006 | 0.000011 | 0.000009 | |
| 100,000 | 0.000017 | 0.000006 | 0.000008 | 0.000013 | 0.000004 | 0.000007 | 0.000011 | 0.000011 | 0.000018 | |
| 1,000,000 | 0.000012 | 0.000036 | 0.000027 | 0.000008 | 0.000011 | 0.000020 | 0.000008 | 0.000009 | 0.000018 | |
| 2,500,000 | 0.000006 | 0.000014 | 0.000010 | 0.000012 | 0.000031 | 0.000013 | 0.000015 | 0.000019 | 0.000025 | |
| 5,000,000 | 0.000026 | 0.000007 | 0.000019 | 0.000074 | 0.000053 | 0.000016 | 0.000012 | 0.000010 | 0.000045 | |
| 7,500,000 | 0.000017 | 0.000008 | 0.000004 | 0.000004 | 0.000013 | 0.000014 | 0.000013 | 0.000013 | 0.000034 | |
| 10,000,000 | 0.000017 | 0.000012 | 0.000017 | 0.000012 | 0.000021 | 0.000041 | 0.000015 | 0.000033 | 0.000085 | |
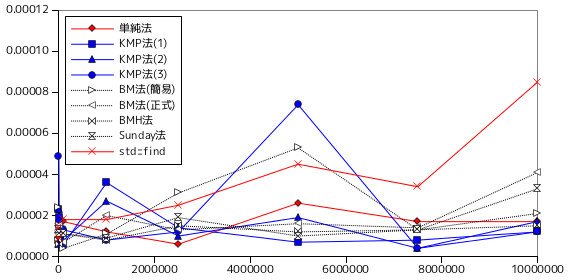 | ||||||||||
テスト B は、文字列はランダムですが、文字種が 'A', 'B' と極端に少ないので、パターン長が多少長くても一致する確率が増える分、処理時間が早くなることが期待できます。しかし、パターン長による処理時間は文字種が多い場合よりも長くなっています。これは、一致する確率が多くなる分、完全に一致しなくても途中まで一致している場合も多くなり、比較回数がかえって増えていることが原因であると考えられます。テキスト長に対しては処理時間の変化はかなり少なくなっています。一致する場合が増えるので、テキストの長さに依存しなくなったことが理由として挙げられます。
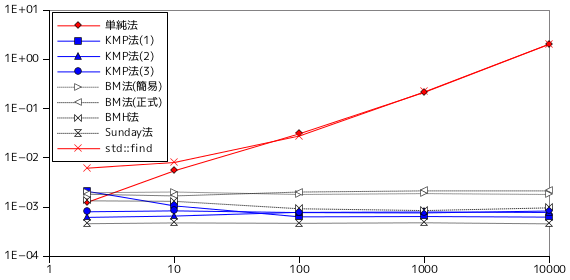
テスト C の、'A' のみからなるテキストをパターン 'AAA.....AB' で照合した結果は次のようになりました。
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 350,000 | 2 | 0.001237 | 0.002090 | 0.000618 | 0.000803 | 0.001950 | 0.001819 | 0.001338 | 0.000459 | 0.006155 |
| 10 | 0.005436 | 0.001056 | 0.000657 | 0.000837 | 0.002020 | 0.001683 | 0.001307 | 0.000476 | 0.008030 | |
| 100 | 0.030679 | 0.000633 | 0.000781 | 0.000772 | 0.001799 | 0.002017 | 0.000923 | 0.000467 | 0.027712 | |
| 1,000 | 0.213346 | 0.000643 | 0.000795 | 0.000760 | 0.001875 | 0.002130 | 0.000848 | 0.000479 | 0.217559 | |
| 10,000 | 2.029856 | 0.000625 | 0.000778 | 0.000834 | 0.001800 | 0.002128 | 0.000963 | 0.000456 | 2.037866 | |
 | ||||||||||
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 1,000 | 10 | 0.000022 | 0.000004 | 0.000004 | 0.000005 | 0.000010 | 0.000011 | 0.000007 | 0.000003 | 0.000049 |
| 10,000 | 0.000207 | 0.000039 | 0.000040 | 0.000037 | 0.000136 | 0.000094 | 0.000092 | 0.000030 | 0.000822 | |
| 100,000 | 0.002503 | 0.000164 | 0.000230 | 0.000211 | 0.000449 | 0.000463 | 0.000240 | 0.000172 | 0.002538 | |
| 1,000,000 | 0.011983 | 0.001988 | 0.002186 | 0.002536 | 0.004709 | 0.005065 | 0.002982 | 0.001671 | 0.022496 | |
| 2,500,000 | 0.027496 | 0.005265 | 0.005089 | 0.006063 | 0.011490 | 0.012422 | 0.007287 | 0.003612 | 0.055246 | |
| 5,000,000 | 0.051393 | 0.009860 | 0.009484 | 0.011789 | 0.022471 | 0.024333 | 0.013753 | 0.006958 | 0.110094 | |
| 7,500,000 | 0.076234 | 0.014489 | 0.014579 | 0.017712 | 0.033973 | 0.037144 | 0.020767 | 0.010462 | 0.169034 | |
| 10,000,000 | 0.101198 | 0.019057 | 0.019115 | 0.023641 | 0.048415 | 0.047533 | 0.027444 | 0.014366 | 0.221946 | |
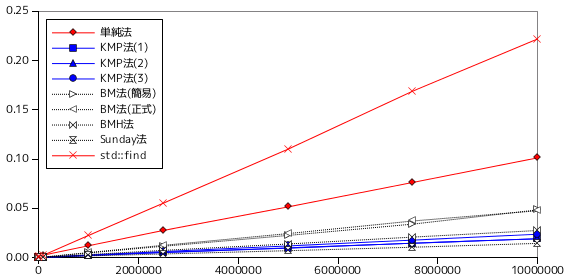 | ||||||||||
テスト C は、単純法の場合、パターン末尾まで照合を繰り返して最後に不一致を検出する処理がテキスト長分だけ繰り返されることになるため、単純法では非常に不利な条件となります。パターン長に対しては、単純法と std::find が線形に増加する傾向にあることがこの結果からわかりますが、これは先ほど示した理由によるものです (この結果から、std::find が単純法と同じアルゴリズムであることもわかります)。
テキスト長に対する処理時間の推移も、単純法と std::find の増加量が他のアルゴリズムに比べて大きいという結果になりました。std::find が単純法と比べても増加量が大きいのが気になりますが、理由は不明です。
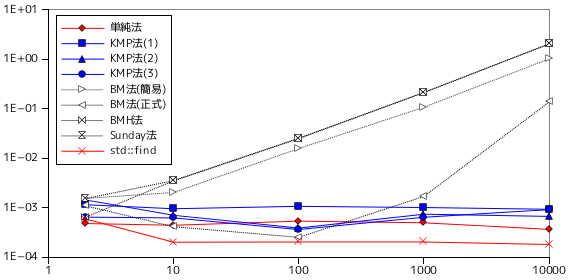
最後はテスト D で、'A' のみからなるテキストをパターン 'BA.....AAA' で照合した結果です。
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 350,000 | 2 | 0.000481 | 0.001151 | 0.001433 | 0.000647 | 0.001547 | 0.001088 | 0.000651 | 0.001533 | 0.000593 |
| 10 | 0.000444 | 0.000956 | 0.000705 | 0.000623 | 0.002029 | 0.000416 | 0.003482 | 0.003528 | 0.000202 | |
| 100 | 0.000537 | 0.001068 | 0.000388 | 0.000363 | 0.015637 | 0.000253 | 0.024825 | 0.025278 | 0.000204 | |
| 1,000 | 0.000498 | 0.001010 | 0.000743 | 0.000643 | 0.106964 | 0.001692 | 0.210573 | 0.212839 | 0.000204 | |
| 10,000 | 0.000366 | 0.000933 | 0.000670 | 0.000917 | 1.013948 | 0.136530 | 2.020456 | 2.027215 | 0.000182 | |
 | ||||||||||
| テキスト長 | パターン長 | 単純法 | KMP法(1) | KMP法(2) | KMP法(3) | BM法(簡易) | BM法(正式) | BMH法 | Sunday法 | std::find |
|---|---|---|---|---|---|---|---|---|---|---|
| 1,000 | 10 | 0.000002 | 0.000002 | 0.000002 | 0.000002 | 0.000014 | 0.000009 | 0.000020 | 0.000021 | 0.000002 |
| 10,000 | 0.000014 | 0.000017 | 0.000019 | 0.000019 | 0.000118 | 0.000038 | 0.000163 | 0.000180 | 0.000013 | |
| 100,000 | 0.000131 | 0.000187 | 0.000232 | 0.000225 | 0.001456 | 0.000219 | 0.001177 | 0.000886 | 0.000058 | |
| 1,000,000 | 0.001764 | 0.002171 | 0.001077 | 0.001594 | 0.006287 | 0.001292 | 0.009251 | 0.009631 | 0.000573 | |
| 2,500,000 | 0.003097 | 0.002641 | 0.002486 | 0.002519 | 0.015001 | 0.003341 | 0.022936 | 0.023118 | 0.001576 | |
| 5,000,000 | 0.004143 | 0.004941 | 0.004697 | 0.004778 | 0.029770 | 0.006280 | 0.044575 | 0.049804 | 0.003164 | |
| 7,500,000 | 0.005527 | 0.007255 | 0.007060 | 0.007023 | 0.044930 | 0.009171 | 0.066829 | 0.072147 | 0.004862 | |
| 10,000,000 | 0.006693 | 0.009265 | 0.009681 | 0.009089 | 0.059640 | 0.012440 | 0.089875 | 0.091643 | 0.006456 | |
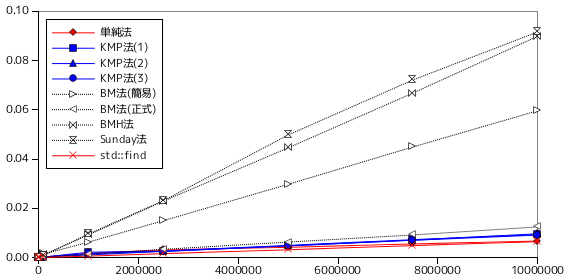 | ||||||||||
テスト D は、パターンの先頭側から照合した場合はすぐに不一致を検出することができるのに対し、末尾側から照合した場合は最後まで不一致が検出できないので、BM 法に対しては不利になる条件です。パターンに対する処理時間は BM 法の簡易版、BMH 法、Sunday のアルゴリズムで線形に増加する傾向であることがこの結果からわかります。BM 法の正式版では、パターン長 1,000 まではほぼ一定であるものの、10,000 になると極端に処理時間が増大しています。これは偶然ではなく、パターン長をさらに 10 倍の 100,000 にすると、BM 法の簡易版では 7.62 sec. なのに対し、正式版では 13.99 sec. と順序が逆転してしまいます。BM 法の正式版では、パターンの長さに対して二乗のオーダーで処理時間が増えています。これは、パターンから移動量テーブルを作成する処理の時間がパターン長の二乗に比例していることが原因です。「Strong Good Suffix Rule」に対する移動量の計算において、候補となる位置はパターン長とほぼ同数だけ作成され、一回のループでも一つずつしか減らないため、パターン長を m とすると、平均 m / 2 個の候補を m / 2 回文字比較することになり、パターン長の二乗のオーダーになってしまうわけです。BM 法の正式版では、パターン長が非常に長いとき、文字列の条件によっては極端に処理時間が増大する場合があることを意味します。
テキスト長に対する処理時間は、BMH 法と Sunday のアルゴリズムが最も増分が高いという結果になっています。正式版 BM 法を使うと、増分がかなり抑えられることもこの結果からわかります。
以下に、各テストの中でパターン・テキスト長が最大のときの結果を、アルゴリズム別に並べた表を示します。また、表の右端にある "Principia Mathematica" は、「INTERNET ARCHIVE」にあった「Full text of "Newton's Principia : the mathematical principles of natural philosophy"」を使い、次の二つのパターンを照合する処理を行ったときの時間を示しています。パターンの右側にある () 内の数値は、その文字がテキストの何番めにあるかを示しています。テキストの総数は 1,494,423 文字であり、ほとんど末尾に近いパターンを選択しています。このテストは、通常の文字列照合処理を想定したものということになります。
長いパターン ... "the operation is to be repeated till the trajectory is exactly enough determined" (1,460,788)
短いパターン ... "BERKELEY" (1,494,384)
| アルゴリズム | テスト A | テスト B | テスト C | テスト D | Principia Mathematica | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10K/350K | 10/10M | 10K/350K | 10/10M | 10K/350K | 10/10M | 10K/350K | 10/10M | 長いパターン | 短いパターン | |
| 単純法 | 0.000735 | 0.009356 | 0.002560 | 0.000017 | 2.029856 | 0.101198 | 0.000366 | 0.006693 | 0.003730 | 0.000852 |
| KMP法(1) | 0.000419 | 0.011256 | 0.001721 | 0.000012 | 0.000625 | 0.019057 | 0.000933 | 0.009265 | 0.003096 | 0.001310 |
| KMP法(2) | 0.000381 | 0.010207 | 0.001818 | 0.000017 | 0.000778 | 0.019115 | 0.000670 | 0.009681 | 0.003026 | 0.001445 |
| KMP法(3) | 0.000375 | 0.010272 | 0.001816 | 0.000012 | 0.000834 | 0.023641 | 0.000917 | 0.009089 | 0.003701 | 0.001283 |
| BM法(簡易) | 0.000567 | 0.015858 | 0.002660 | 0.000021 | 0.001800 | 0.048415 | 1.013948 | 0.059640 | 0.001512 | 0.001267 |
| BM法(正式) | 0.000478 | 0.020235 | 0.003552 | 0.000041 | 0.002128 | 0.047533 | 0.136530 | 0.012440 | 0.001720 | 0.001581 |
| BMH法 | 0.000457 | 0.015125 | 0.002110 | 0.000015 | 0.000963 | 0.027444 | 2.020456 | 0.089875 | 0.001462 | 0.001200 |
| Sunday法 | 0.000498 | 0.016157 | 0.002609 | 0.000033 | 0.000456 | 0.014366 | 2.027215 | 0.091643 | 0.001497 | 0.001787 |
| std::find | 0.000368 | 0.009361 | 0.004343 | 0.000085 | 2.037866 | 0.221946 | 0.000182 | 0.006456 | 0.004058 | 0.000886 |
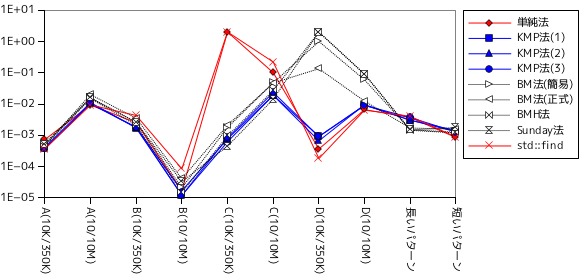 | ||||||||||
表の中の "10K/350K", "10/10M" は "パターン長/テキスト長" を意味しており、前者がパターン長 10,000、テキスト長 350,000 であり、後者がパターン長 10、テキスト長 10,000,000 になります。グラフの縦軸は対数で表されていることに注意して下さい。一目盛りあたり処理時間は 10 倍になります。
単純法の処理時間を 1.00 としたとき、各テスト単位で時間を比率で表した結果が下表のようになります。
| アルゴリズム | テスト A | テスト B | テスト C | テスト D | Principia Mathematica | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10K/350K | 10/10M | 10K/350K | 10/10M | 10K/350K | 10/10M | 10K/350K | 10/10M | 長いパターン | 短いパターン | |
| KMP法(1) | 0.570 | 1.20 | 0.672 | 0.706 | 3.08E-04 | 0.188 | 2.55 | 1.38 | 0.830 | 1.54 |
| KMP法(2) | 0.518 | 1.09 | 0.710 | 1.00 | 3.83E-04 | 0.189 | 1.83 | 1.45 | 0.811 | 1.70 |
| KMP法(3) | 0.510 | 1.10 | 0.709 | 0.706 | 4.11E-04 | 0.234 | 2.51 | 1.36 | 0.992 | 1.51 |
| BM法(簡易) | 0.771 | 1.69 | 1.04 | 1.24 | 8.87E-04 | 0.478 | 2.77E+03 | 8.91 | 0.405 | 1.49 |
| BM法(正式) | 0.650 | 2.16 | 1.39 | 2.41 | 1.05E-03 | 0.470 | 3.73E+02 | 1.86 | 0.461 | 1.86 |
| BMH法 | 0.622 | 1.62 | 0.824 | 0.882 | 4.74E-04 | 0.271 | 5.52E+03 | 13.4 | 0.392 | 1.41 |
| Sunday法 | 0.678 | 1.73 | 1.02 | 1.94 | 2.25E-04 | 0.142 | 5.54E+03 | 13.7 | 0.401 | 2.10 |
| std::find | 0.501 | 1.00 | 1.70 | 5.00 | 1.00 | 2.19 | 0.497 | 0.965 | 1.09 | 1.04 |
完全にランダムな文字列ならば、パターン長が 10 文字程度の場合、単純法が最も速く処理できます。BM 法は逆に最も遅く、単純法の 1.5 倍以上の処理時間が必要になります。パターン長が極端に長ければ、単純法よりも KMP 法や BM 法の方が速く処理できます。テスト C が単純法に対して不利な条件であることは先に述べたとおりで、他のアルゴリズムの方が圧倒的に速く処理できます。テスト D は BM 法に対して不利な条件ですが、正式版では処理速度が改善されていることがこの結果からわかります。しかし前述の通り、パターン長が更に長くなると、正式版のほうがかえって遅くなってしまうため、そのような場面が発生する可能性があるのなら、移動量生成のプログラム部分に対して何らかの改善が必要になります。最後の、テキスト・ファイルから文字列を探索するテストでは、ランダムな文字列によるテストとほぼ同様の結果となっていますが、パターン長が長いと BM 法の処理性能が非常に高くなることは注目すべき結果です。
今度は、"10K/350K" と "10/10M" のそれぞれに対し、テスト A の処理時間を 1.00 として各アルゴリズムごとに比率で表した結果を示します。但し、Principia Mathematica の場合は「長いパターン」を "10K/350K" に対して、「短いパターン」を "10/10M" に対して比率計算しています。
| アルゴリズム | テスト B | テスト C | テスト D | Principia Mathematica | ||||
|---|---|---|---|---|---|---|---|---|
| 10K/350K | 10/10M | 10K/350K | 10/10M | 10K/350K | 10/10M | 長いパターン | 短いパターン | |
| 単純法 | 3.48 | 1.82E-03 | 2.76E+03 | 10.8 | 0.498 | 0.715 | 5.07 | 0.0911 |
| KMP法(1) | 4.11 | 1.07E-03 | 1.49 | 1.69 | 2.23 | 0.823 | 7.39 | 0.116 |
| KMP法(2) | 4.77 | 1.67E-03 | 2.04 | 1.87 | 1.76 | 0.948 | 7.94 | 0.142 |
| KMP法(3) | 4.84 | 1.17E-03 | 2.22 | 2.30 | 2.45 | 0.885 | 9.87 | 0.125 |
| BM法(簡易) | 4.69 | 1.32E-03 | 3.17 | 3.05 | 1.79E+03 | 3.76 | 2.67 | 0.0799 |
| BM法(正式) | 7.43 | 2.03E-03 | 4.45 | 2.35 | 2.86E+02 | 0.615 | 3.60 | 0.0781 |
| BMH法 | 4.62 | 9.92E-04 | 2.11 | 1.81 | 4.42E+03 | 5.94 | 3.20 | 0.0793 |
| Sunday法 | 5.24 | 2.04E-03 | 0.916 | 0.889 | 4.07E+03 | 5.67 | 3.01 | 0.111 |
| std::find | 11.8 | 9.08E-03 | 5.54E+03 | 23.7 | 0.495 | 0.690 | 11.0 | 0.0946 |
今までの説明内容から明らかな結果がほとんどですが、長いパターンならランダムな文字列より通常の文章に対する照合の方が処理時間は長くなる傾向が、"Principia Mathematica" の文字列照合の結果からみられます。ランダムな文字列ではパターン長が 10,000 なのに対し、"Principia Mathematica" では 81 文字と非常に少なくなっていますが、テキスト長はランダムな文字列の 35 万文字に対して、"Principia Mathematica" では 150 万文字と約 4 倍あります。テキスト長の方が処理時間に影響を与える分、"Principia Mathematica" の方が遅くなる傾向にあると考えられますが、BM 法以外は 7 〜 8 倍の処理時間が必要になっているためテキストの長さを考慮しても二倍程度は長くなるものと考えられます。これは、部分的に一致する場合が多くなることが原因ですが、BM 法はそのような場合でも高速に検索できるのが、通常の文字列検索でよく利用されている理由の一つなのでしょう。
今まで紹介した文字列照合は 1 バイト文字を扱うことが前提となっていて、日本語などの多バイト文字に対して文字列照合を行った場合に予期せぬ結果が得られてしまう場合があります。例えば、SJIS コードのテキスト "0123" (全角数字) からパターン "Q" を検索した場合、本来なら照合結果は得られないはずなのですが、テキストを文字コードに分解すると
であり、パターンの文字コードは '0x51' なので全角数字 "2" の 2 バイトめと一致してしまいます。このような現象は ISO-2022-JP (JISコード) でも発生します。
EUC コードでは、文字を表現する 2 バイト文字コードの最上位ビットが必ず 1 となり、7 ビットのみを使用する ASCII 文字コードと一致することはないので、上のような現象は発生しません。だから安心かというとそうではなくて、例えば EUC コードのテキスト "相原さんは蠍座です" からパターン '蠍'(文字コードは0xEA,0xB8) を検索すると、
から "相" の 2 バイトめ及び "原" の 1 バイトめと一致してしまいます。このようにパターン自体に 2 バイト文字が含まれていれば、EUC コードと言えども照合がおかしくなる可能性があります。
以下に、各文字コードの特徴について簡単に紹介します。
ISO-2022-JP (JISコード) は、ASCII 文字コードと他の文字集合の間に符合列 (エスケープ・シーケンス) を挿入することにより、各文字集合を区別するようになっています。例えば、"PERLとRUBY" という文字列の文字コードは以下のようになります。
| コード | 0x50 | 0x45 | 0x52 | 0x4C | 0x1B | 0x24 | 0x42 | 0x24 | 0x48 | 0x1B | 0x28 | 0x42 | 0x52 | 0x55 | 0x42 | 0x59 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 対応文字 | P | E | R | L | ESC | $ | B | と | ESC | ( | B | R | U | B | Y | |
0x1B, 0x24, 0x42 ( "ESC $ B" ) は「ここから JIS X 0208-1983 ( 新 JIS ) の文字集合が始まることを示すエスケープ・シーケンス」で、0x1B, 0x28, 0x42 ( "ESC ( B" ) は「ここから ASCII 文字コードが始まることを示すエスケープ・シーケンス」になります。文字列の頭では ASCII 文字から始まることを暗黙の条件としているようで、上のような ASCII 文字列から始まる文字列では符合列は付加されません。
このような文字コードの場合、英語と日本語だけでなく、必要ならば他の言語も混在させることが可能であり、さらに情報交換の際に最上位ビットを無条件で落としてしまうようなネットワーク環境下にあっても正常に情報を交換することができるという利点があります。その反面、任意に 1 バイトを取り出したときに、それがどの文字集合なのか区別できないため、今回のような文字列処理ルーチンが作成しにくくなります。
以下に、文字集合とそのエスケープ・シーケンスを示します。これらは、ISO-2022-JP より多くの文字集合を扱えるようにしたコードである ISO-2022-JP-2004 が使用可能な文字集合で、ISO-2022-JP で使用できるものは下表の上側 4 つ ( ASCII, 旧JIS, 新JIS, ローマ字 ) になります。ISO-2022-JP コードでは、半角カタカナは本来使用しないことになっているのですが、なぜか専用のエスケープ・シーケンスが存在します。また、同じく半角カタカナの始まりを示す「Shift Out (SO)」と、ASCII コードの始まりを示す「Shift In (SI)」があるなど、かなりややこしいことになっています。
| 規格 | 文字集合 | エスケープ・シーケンス |
|---|---|---|
| ISO-2022-JP | ASCII | 0x0F [ SI ] または 0x1B 0x28 0x42 [ ESC(B ] |
| JIS X 0208-1978 (旧JIS) | 0x1B 0x24 0x40 [ ESC$@ ] | |
| JIS X 0208-1983 (新JIS) | 0x1B 0x24 0x42 [ ESC$B ] | |
| JIS X 0201ローマ字 | 0x1B 0x28 0x4A [ ESC(J ] | |
| ISO-2022-JP-1 | JIS X 0212-1990 | 0x1B 0x24 0x28 0x44 [ ESC$(D ] |
| ISO-2022-JP-2 | GB2312-80 (中国漢字) | 0x1B 0x24 0x41 [ ESC$A ] |
| KS C 5601 (KS X 1001) (韓国語) | 0x1B 0x24 0x28 0x43 [ ESC$(C ] | |
| ISO 8859-1 (Latin-1) | 0x1B 0x2E 0x41 [ ESC.A ] | |
| ISO 8859-7 (Greek) | 0x1B 0x2E 0x46 [ ESC.F ] | |
| ISO-2022-JP-2004 | JIS X 0213-2004 第1面 | 0x1B 0x24 0x28 0x51 [ ESC$(Q ] |
| JIS X 0213-2004 第2面 | 0x1B 0x24 0x28 0x50 [ ESC$(P ] | |
| 独自拡張 | 半角カタカナ | 0x0E [ SO ] または 0x1B 0x28 0x49 [ ESC(I ] |
日本語EUC ( Extended UNIX Code ) では、JIS X 0208 文字コードの最上位ビットを 1 にすることにより ASCII コードなどと区別するようになっています。ちなみに 1 バイトカタカナ (半角カナ) の場合は「シングルシフト 2 ( SS2 )」というコード (0x8E) を、JIS X 0212-1990 文字集合の場合は「シングルシフト 3 ( SS3 )」というコード (0x8F) を文字コードの前につけてから最上位ビットを 1 にします (これらは JIS コードにおける SO, SI の最上位ビットを 1 にしたものに相当します)。"PERLとRUBY"という文字列の EUC 文字コードを以下に示します。
| コード | 0x50 | 0x45 | 0x52 | 0x4C | 0xA4 | 0xC8 | 0x52 | 0x55 | 0x42 | 0x59 |
|---|---|---|---|---|---|---|---|---|---|---|
| 対応文字 | P | E | R | L | と | R | U | B | Y | |
日本語 EUC では、文字コードを見ればそれが 1 バイト文字か 2 バイト文字の一部かを判別することが可能です。
MS漢字コード (シフトJIS ( SJIS ) コード) は、JIS X 0208 文字コードを決められた計算式によって変換したものです。このコードが文字列処理ルーチンで問題になるのは、2 バイト文字の 2 バイトめに最上位ビットが 0 となるコードを含む場合があるため ASCII コードとの区別ができなくなることです ( 1 バイトめは重ならないようになっています )。"PERLとRUBY" という文字列の SJIS 文字コードを以下に示します。
| コード | 0x50 | 0x45 | 0x52 | 0x4C | 0x82 | 0xC6 | 0x52 | 0x55 | 0x42 | 0x59 |
|---|---|---|---|---|---|---|---|---|---|---|
| 対応文字 | P | E | R | L | と | R | U | B | Y | |
上の例では 2 バイト文字のコードは二つとも最上位ビットが 1 ですが、例えば "連" の文字コードは 0x98, 0x41 で 2 バイトめが ASCII 文字コード 'A' と重なってしまいます。
今まで紹介した文字コードは、元の文字集合 (Character Set) が同じで符号化だけが異なるというものでした。文字集合の種類は JIS コードの説明の中で示した表の中にも記載されていますが、要は ASCII コードや漢字などに一連の番号を付けたものを文字集合といいます。JIS X 0208 の場合、各文字は「区」と「点」で管理され、例えばひらがなの "あ" は「04 区の 02点」に位置します。区と点に 16 進数 0x20 ( = 32 ) を加えて並べたものが JIS コードに等しく、同じやり方で 0x20 ではなく 0xA0 を加えたもの ( つまり、JIS コードの最上位ビットを 1 にしたもの ) が EUC コードになります。よって、"あ" に対しては JIS コードが 0x2422、EUC コードが 0xA4A2 です。SJIS コードの場合は少々複雑で、区によって計算方法が変わりますが、ひらがなの "あ" の場合は 0x82A0 となります。
JIS X 0208 は日本語で利用される文字だけが対象で、その他の言語用の文字は別の文字集合が存在します。それらを全て一つの文字集合として扱うために決められた業界規格が「ユニコード (Unicode)」です。ひらがなの "あ" は、Unicode では U3042 と表現されます。先頭にある "U" は、この数値が Unicode であることを表しているだけなので、実際のコードは 2 桁めからになります。また、この数値は 16 進数で表現されたものです。
Unicode を符号化する方法はいくつかあります。UTF-8 は ASCII コードに対して互換性があり、最近では Linux などで標準の文字コードとして利用されています。UTF-16 は文字コードが 16 ビット (一部の文字では 32 ビット) で表現されており、Windows の内部ではこのコードが利用されているそうです。さらに UTF-32 という 32 ビット固定長の文字コードも存在するようですが、テキストのコードに利用されることはほとんどないようです。
Unicode の文字コードは非常に巧妙な仕組みを使い、異なる文字のコードが別の文字コードに含まれてしまったり、連続する二つの文字コードの間で別の文字コードが表現されてしまうようなことがないようにしています。例えば UTF-8 において、1 バイトの ASCII コードは 0x00 から 0x7F までの値を取りますが、この範囲の値は他の文字コードには決して含まれません。Unicode に対する UTF-8 バイト列の値の範囲を以下に示します。
| Unicode | バイト列 | 有効ビット数 | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | ||
| U0000-U007F | 00-7F | 7 bit | |||||
| U0080-U07FF | C2-DF | 80-BF | 11 bit | ||||
| U0800-UFFFF | E0-EF | 80-BF | 80-BF | 16 bit | |||
| U10000-U1FFFFF | F0-F7 | 80-BF | 80-BF | 80-BF | 21 bit | ||
| U200000-U3FFFFFF | F8-FB | 80-BF | 80-BF | 80-BF | 80-BF | 26 bit | |
| U4000000-U7FFFFFFF | FC-FD | 80-BF | 80-BF | 80-BF | 80-BF | 80-BF | 31 bit |
このため、UTF-8 や UTF-16 に対しては、バイト単位で一致すれば文字コード自体も一致していることになり、特別な処理を行う必要はありません。但し、UTF-16 や UTF-32 の場合、バイトの並び順が「リトル・エンディアン (Little-Endian)」と「ビッグ・エンディアン (Big-Endian)」の二種類あり、前者の場合はバイト列の並びが逆転します。並び順がどちらかを識別するため「バイト順マーク (Byte Order Mark ; BOM)」が文字列の先頭に付加される場合もあり、さらに UTF-8 にも (不要であるにもかかわらず) BOM を付けることが許されているようです。
上に示したような問題を防ぐための手段として、テキストとパターンの比較を必ず「文字単位」で行うようにして、2 バイト文字の場合は次の文字コードもいっしょに取り出して比較するようにする方法があります。単純法ならば簡単に対応できそうですが、KMP 法や BM 法などを使うことを考えるとテーブルの作成などに工夫が必要です。
別の案としては、文字を全て 16 ビットコードで表現するようにして ( 例えば ASCII コードの上位バイトには 0x00 を補うようにすることで )、比較を常に 2 バイト単位で行う手もあります。但し、この場合はテキストとパターンを前もって加工しておくことが必要になります。
さらに、処理自体は 1 バイト単位で行い、あとで照合した位置が問題ないかチェックする方法もあります。以下に、照合後のチェック方法を示します。
日本語 EUC の場合は、照合したパターンの先頭が ASCII コードならば問題ないのは前に述べた通りですが、そうでなかった場合はテキストを照合位置から先頭方向へ走査して ASCII 文字を探します。見つかったら、その次の文字から照合位置の手前まで (見つからずにテキストの先頭まで到達してしまったら、先頭の文字から照合位置の手前まで) にある文字の数を数えれば、奇数ならば照合位置は漢字コードの 2 バイトめになるため誤り、0 または偶数ならば漢字コードの 1 バイトめになるため正しいと判断することができます。前に示したテキスト "相原さんは蠍座です" からパターン "蠍" を検索する場合、
| 相 | 原 | さ | ん | は | 蠍 | 座 | で | す | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xC1 | 0xEA | 0xB8 | 0xB6 | 0xA4 | 0xB5 | 0xA4 | 0xF3 | 0xA4 | 0xCF | 0xEA | 0xB8 | 0xBA | 0xC2 | 0xA4 | 0xC7 | 0xA4 | 0xB9 |
| 1 | * | * | |||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | * | * | ||||||
表の中でテキストの 2 文字めで照合が得られた場合は奇数になるから誤り、11 文字めでの照合では偶数になるから正しいと判断できます。
日本語 EUC テキストの照合位置をチェックするアルゴリズムのサンプルを以下に示します。
/* checkEUC : 照合位置チェックルーチン(EUC) string::const_iterator i0 : 文字列の先頭 string::const_iterator i1 : 照合位置 戻り値 true ... 正しい ; false ... 正しくない */ bool checkEUC( string::const_iterator i0, string::const_iterator i1 ) { string::const_iterator i = i1; for ( ; i > i0 ; --i ) if ( *( i - 1 ) > 0 ) break; return( ( i1 - i ) % 2 == 0 ); }
SJIS コードの場合は、同様に走査して「SJIS コードの 1 バイトめにはならない文字コード」を探します。見つかった文字は漢字コードの 2 バイトめか ASCII 文字のどちらかになり、その位置で文字は "完結" しています。その直後からは全て 2 バイト文字コードになるので、照合位置の手前までの文字数が偶数なら照合結果は正しく、奇数なら誤りであると判断することができます。ここで「それならば照合位置の手前が SJIS コードの 1 バイトめになり得る文字コードだったら誤りとしてもいいのでは」と思うかもしれませんが、「SJIS コードの 1 バイトめになり得る文字コード」は、「SJIS コードの 2 バイトめになり得る文字コード」でもあるため、これだけでは不充分です。
SJIS コードの 1 バイトめは、つぎのような計算式で求められます(小数点以下切り捨て)。
よって取りうる範囲は 0x81 〜 0x9F と 0xE0 〜 0xEF になります。
SJIS コードのテキスト "連続するA" からパターン "A" を検索する場合、下表の '*' の位置で照合します。
| 連 | 続 | す | る | A | ||||
|---|---|---|---|---|---|---|---|---|
| 0x98 | 0x41 | 0x91 | 0xB1 | 0x82 | 0xB7 | 0x82 | 0xE9 | 0x41 |
| 1 | * | |||||||
| × | 1 | 2 | * | |||||
表の中で、テキストの 2 文字めで照合が得られた場合は奇数になるから誤り、9 文字めでの照合では、「SJISコードの 1 バイトめにはならない文字コード」である0xB7との間が2バイトで偶数になるから正しいと判断できます。
SJIS コードテキストの照合位置をチェックするアルゴリズムのサンプルを以下に示します。
/* checkSJIS : 照合位置チェックルーチン(SJIS) string::const_iterator i0 : 文字列の先頭 string::const_iterator i1 : 照合位置 戻り値 true ... 正しい ; false ... 正しくない */ bool checkSJIS( string::const_iterator i0, string::const_iterator i1 ) { string::const_iterator i = i1; for ( ; i > i0 ; --i ) { unsigned char c = *( i - 1 ); if ( ( c < 0x81 ) || ( c > 0x9F && c < 0xE0 ) || ( c > 0xEF ) ) break; } return( ( i1 - i ) % 2 == 0 ); }
JIS コードの場合は、パターンの先頭文字に応じて処理を切り替える必要があります。
パターンの先頭文字が 0x1B ( = ESC ) でない場合は、パターンが ASCII 文字コードで始まっていることを示しています (と考えてもまず問題ないでしょう)。また、パターンの先頭が ESC で始まっていたとしても、その後に続く文字が 0x28, 0x42 ( = "(B" ) か 0x28, 0x4A ( = "(J" ) ならその後は 1 バイト文字が続きます。よって、テキストを照合位置から先頭方向へ走査しながら ESC を探し、それが見つからないか、もしくは見つかってもその直後の文字列が "(B", "(J" のいずれかであるならば、それまで走査した部分が全て 1 バイト文字であるため問題ないと判断できます。但し、エスケープシーケンス内に照合位置がある場合は除外しなければなりません。ESC 直後の文字列が 0x24, 0x42 ( = "$B" ) または 0x24, 0x40 ( = "$@" ) であった場合は、それまでの文字が 2 バイト文字であるため照合は誤りであると判断できます。
パターンの先頭文字が ESC で、しかもその後に続く文字が 0x24, 0x42 ( = "$B" ) か 0x24, 0x40 ( = "$@" ) ならば、パターン先頭から 2 バイト文字が始まることを意味します。この場合も、一致した部分列が見つかったら先頭方向へ走査を行って ESC を探し、もし ESC が見つからないか、見つかっても直後の 2 バイトが "$B", "$@" でない場合は、一致した文字列の先頭が 2 バイト文字ではないと判断できます。
もし 2 バイト文字であると判断できた場合、エスケープ・シーケンスの次から照合位置手前までの文字数を数えます。偶数ならば、先頭は 2 バイト文字の 1 バイトめと判断できるので正しく、奇数ならばそれは 2 バイト文字の 2 バイトめであると判断できるので誤りと考えることができます。
パターンの先頭にエスケープ・シーケンスがある場合、文字列照合を行う前に特別な処理を行う必要があります。検索したい文字は必ずしもエスケープ・シーケンスの直後に現れるとは限らないため、パターンをそのまま使用して処理を行った場合、目的の文字コードがエスケープ・シーケンスから離れた場所にあった場合などは一致すると判断されません。よって、パターンの先頭にあるエスケープ・シーケンスをあらかじめ除外しておきます。しかし、除外してしまうと今度は先頭から始まる文字がどの文字集合にあたるのかわからなくなるため、別の変数に情報を保持しておく必要があります。
JIS コードのテキスト "連続する$B" からパターン '$B' を検索する場合、
| ESC | $ | B | 連 | 続 | す | る | ESC | ( | B | $ | B | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x1B | 0x24 | 0x42 | 0x4F | 0x22 | 0x42 | 0x33 | 0x24 | 0x39 | 0x24 | 0x6B | 0x1B | 0x28 | 0x42 | 0x24 | 0x42 |
| - | * | * | |||||||||||||
| - | - | - | * | * | |||||||||||
表の中でテキストの 2 文字めで照合が得られた場合は、その文字がエスケープ・シーケンス内にあるから誤り、15 文字めでの照合では、その前にあるエスケープ・シーケンスが ASCII 文字コードの始まりを意味しており、パターンも ASCII 文字なので正しいと判断できます。
JIS コードテキストの照合位置をチェックするアルゴリズムのサンプルを以下に示します。
// JISコード判別コード enum JIS_CODE { JIS_ASCII = 0, // ASCII, ローマ字 JIS_2BYTE = 1, // 新・旧JIS JIS_HANKANA = 2, // 半角カナ }; const char ESC = 0x1B; // Escape const char SI = 0x0F; // Shift In const char SO = 0x0E; // Shift Out // エスケープ・シーケンス const char ASCII[] = "\x1B(B"; // ASCII const char ROMAN[] = "\x1B(J"; // JIS X 0201ローマ字 const char NEWJIS[] = "\x1B$B"; // JIS X 0208-1983 (新JIS) const char OLDJIS[] = "\x1B$@"; // JIS X 0208-1978 (旧JIS) const char HANKANA[] = "\x1B(I"; // 半角カナ const string::size_type ESCSEQ_LEN = 3; // エスケープ・シーケンスの長さ /* 照合位置チェックルーチン(JIS) string::const_iterator i0 : 文字列の先頭 string::const_iterator i1 : 照合位置 JIS_CODE jisCode : パターン先頭文字に対する文字集合 戻り値 true ... 正しい ; false ... 正しくない */ bool checkJIS( string::const_iterator i0, string::const_iterator i1, JIS_CODE jisCode ) { string::const_iterator i = i1; // 注目文字(照合位置で初期化) for ( ; i > i0 ; --i ) { switch ( *( i - 1 ) ) { case ESC : // ESCが見つかった!! if ( i1 - i + 1 <= 2 ) return( false ); // 先頭は ESC_SEQ 内 if ( jisCode == JIS_ASCII ) { // ASCII,ローマ字で始まる場合、ASCIIかJISローマ字のESC_SEQならOK return( ( strncmp_( i - 1, ASCII, sizeof(ASCII) - 1 ) == 0 ) || // ASCII の ESC_SEQ ( strncmp_( i - 1, ROMAN, sizeof(ROMAN) - 1 ) == 0 ) // JISローマ字の ESC_SEQ ); } else if ( jisCode == JIS_HANKANA ) { // 半角カナで始まる場合、半角カナのESC_SEQならOK return( strncmp_( i - 1, HANKANA, sizeof(HANKANA) - 1 ) == 0 ); } else { // 新/旧JISで始まる場合 if ( ( strncmp_( i - 1, NEWJIS, sizeof(NEWJIS) - 1 ) != 0 ) && // 新JISの ESC_SEQ でない ( strncmp_( i - 1, OLDJIS, sizeof(OLDJIS) - 1 ) != 0 ) ) // 旧JISの ESC_SEQ でない return( false ); else return( ( i1 - i ) % 2 == 0 ); // 新旧JISなら文字数を確認 } break; case SO : // SOが見つかった!! // パターンが半角カナで始まるなら一致とみなす return( jisCode == JIS_HANKANA ); } } /* エスケープシーケンスが見つからない場合 パターンの文字集合がASCIIかローマ字で始まるなら true */ return( jisCode == JIS_ASCII ); }
EUC や SJIS と比べるとかなり長いプログラムになっていますが、処理の内容はそれほど大したことはありません。まず、照合位置から先頭方向へ ESC または SO を探索します。ESC が見つかったら、その箇所はエスケープ・シーケンスであるとみなして、定義された文字集合をチェックします。照合箇所がエスケープ・シーケンス内であるかを確認した上で、パターンが 1 バイト文字で始まるのなら、エスケープ・シーケンスが ESC + "(B" (ASCII) か ESC + "(J" (ローマ字) のときだけ一致したと判断し、パターンが半角カナで始まる場合、エスケープ・シーケンスが ESC + "(I" (半角カナ) のときのみ一致したと判断します。パターンが 2 バイト文字で始まる場合、エスケープ・シーケンスが ESC + "$B" (新JIS) と ESC + "$@" (旧JIS) のいずれでもなければ一致しないと判断します。もし一致の可能性があると判断できたとしてもこれだけでは不十分で、最後に照合位置が 2 バイト文字の 1 バイトめにあたるかをチェックして、もしそうであれば一致したとみなします。なお、ESC ではなく SO が見つかったら、照合位置は半角カナの領域だと判断し、もしパターンが半角カナで始まるのなら一致したとみなします。最後に、エスケープ・シーケンスも SO も見つからなかったときは、テキストの先頭が ASCII コードで開始したとして処理をします。
先にも述べたように、パターン先頭にあるエスケープ・シーケンスは取り除く必要があるので、パターン文字列そのものでは先頭がどの文字集合で始まったのか判別することができません。そのため、エスケープ・シーケンスを取り除く処理の中で先頭の文字集合が何かをあらかじめ取得しておきます。この情報は、列挙型 JIS_CODE の変数 jisCode に保持されているとして処理を行っています。
さて、各コードごとに簡単なサンプルを示しつつ対応法について説明してきましたが、その前に説明した各文字コードの仕様を見ればわかるように、上に示したやり方だけでは完全とは言えません。そもそも、現在の多バイト文字コードは仕様が複雑になり過ぎて様々な混乱の元となっています。上に示したように、多バイトコードの表現方法がいくつもあったり、いわゆる全角カナと半角カナなど、同じ種類の文字が別々のコードに割り振られていることなどがその例です。コード体系に関する記事は他にも Web 上で大量に見つかるので、ここまでの説明では物足りない方は、一度検索して他の記事にも目を通されることをお勧めします。
多バイト文字に対応した文字列照合プログラムのソースファイルを載せておきます。サンプル・プログラムに少し毛が生えた程度ですが、それなりに使えるようにしました。文字列照合アルゴリズムは BM 法を適用しています。
| サンプルプログラムをダウンロードする。 |
|---|
| ・ZIP 形式 (strstr.zip) |
| ・tar-gzip 形式 (strstr.tar.gz) |
使い方
strstr [-option] pattern [file] ... 指定したパターンを含む行を表示する
オプション
使用例
strstr -pe -te EUCコード EUC.txt : ファイル EUC.txt からパターン "EUCコード" を検索(パターンとテキストは EUC コードとみなしてチェックする)
ls -l | strstr -x 414243 : ファイルリストから、文字コードが 16 進数の 41, 42, 43 となる文字列 (すなわち ABC) を検索する
備考
◆◇◆更新履歴◆◇◆
「3) 多バイトコードの扱い」のサンプル・プログラム checkSJIS にバグがあったため修正しました。変数を符号付き char としていたため、正しく大小比較することができなくなっていました (ご指摘いただき、ありがとうございました)。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |