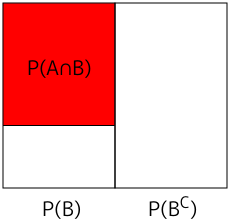
図 1-1. 条件付確率の概念
今まで紹介してきた確率論や統計学では、ある事象が発生する確率は変化することはないという立場をとってきました。例えば、サイコロを投げて出た目を確率変数とした時、100 回投げて全てが 1 の目であったとしても、サイコロに何も細工がされていなければ、それは偶然におこった事象で、1 の目が出る確率は相変わらず 1 / 6 のままです。100 回も 1 の目が続いたのだから、次も必ず 1 であろうと予想できなくもないですが、あくまでも客観的な立場をとるというのが今までの統計学での考え方です。それに対し、今までの結果を踏まえて確率そのものが変化するという立場を取る考え方を採用したのが「ベイズ統計学(Bayesian Statistics)」です。ベイズ統計学の立場では、1 の目が 100 回出たのだから、1 の目が出る確率もそれだけ大きくなっているだろうと判断することになります。今回は、ベイズ統計学の考え方の中心となる「ベイズの定理(Bayes' Theorem)」から出発して、ベイズ統計学での考え方について説明したいと思います。
ある事象 B を前提条件として、その条件下で別の事象 A が起こる確率のことを「条件付確率(Conditional Probability)」といい、以下のような式で表されるのでした。
P(A|B) は事象 B を前提条件としたときに事象 A が起こる確率を表し、P(A∩B) は A と B が同時に起こる確率を表します。下の図において、矩形全体は全事象を表し、縦に割ったうちの左半分が事象 B の起こる範囲、右半分が事象 B の起こらない範囲を表しています。事象 B の起こる範囲の中で、赤く塗られた箇所が A ∩ B、すなわち A と B がどちらも起こる範囲とした時、条件付確率 P(A|B) は、A ∩ B の起こる領域と事象 B の起こる領域の比率で表されると考えることができます。
図 1-1. 条件付確率の概念
ここで、全事象 Ω が複数の事象 Ai ( i = 1, 2, ... ) に分割されると仮定すると、各々の Ai に対して
が成り立ちます。また、事象 Ai を前提条件とした事象 B の条件付確率 P( B | Ai ) は、
と表せるので、この式を変形した
を最初の式に代入すると
となります。Σi( Ai ) = Ω より、各 Ai と B の積集合 Ai ∩ B の和は B に等しく、かつ ( Ai ∩ B ) ∩ ( Aj ∩ B ) = ∅ ( i ≠ j ) なので、P(B) は
| P( B ) | = | Σj( P( Aj ∩ B ) ) |
| = | Σj( P( B | Aj )P( Aj ) ) |
と変形できて、最終的に
という式が得られます。これを「ベイズの定理(Bayes' Theorem)」といいます。P( Ai ) と P( B | Ai ) が既知ならば、それらを使って P( Ai | B ) が求められることをこの定理は表しています。
例えば、10 問の三択問題のテストに答えてもらったところ 4 問に正解したとした時、実際には何問の答えを知っていたのか(何問がまぐれで当たったのか)を評価したいとき、可能性としては
の 5 通りが考えられます( 5 問以上答えを知っていれば当然 5 問以上正解するので無視できます )。答えを知っていた数が i 個のときの事象を Ai、4 問正解したという事象を B とすると、Ai を前提とした時に B になる確率 P( B | Ai ) は「二項分布(Binomial Distribution)」を利用して
| P( B | Ai ) | = | 10-i C 4-i ( 1 / 3 )4-i ( 2 / 3 )6 | ( 0 ≤ i ≤ 4 ) |
| = | 0 | ( 5 ≤ i ≤ 10 ) |
で求められますが、今知りたいのは B を前提とした時の Ai の確率です。そこで、ベイズの定理を利用して P( Ai | B ) を求めると、
| P( Ai | B ) | = | P( B | Ai )P( Ai ) / Σj( P( B | Aj )P( Aj ) ) |
| = | 10-i C 4-i ( 1 / 3 )4-i ( 2 / 3 )6 P( Ai ) / Σj{0→4}( 10-j C 4-j ( 1 / 3 )4-j ( 2 / 3 )6 P( Aj ) ) | |
| = | 10-i C 4-i ( 1 / 3 )4-i P( Ai ) / Σj{0→4}( 10-j C 4-j ( 1 / 3 )4-j P( Aj ) ) |
( 2 / 3 )6 は分子と分母に共通な項なので消すことができます。また、答えを知っている数が等しい回答者は全体の中で (少なくとも 0 ≤ i ≤ 4 の中では) 同程度、つまり P( A0 ) = P( A1 ) = ... = P( A4 ) であると仮定すると、P( Ai ) も消去することができるので
となります。
10-0 C 4-0 ( 1 / 3 )4-0 = ( 10・9・8・7 / 4・3・2 )( 1 / 34 ) = 70 / 33
10-1 C 4-1 ( 1 / 3 )4-1 = ( 9・8・7 / 3・2 )( 1 / 33 ) = 84 / 33
10-2 C 4-2 ( 1 / 3 )4-2 = ( 8・7 / 2 )( 1 / 32 ) = 84 / 33
10-3 C 4-3 ( 1 / 3 )4-3 = 7 / 3 = 63 / 33
10-4 C 4-4 ( 1 / 3 )4-4 = 1 = 27 / 33
より分母は ( 70 + 84 + 84 + 63 + 27 ) / 33 = 328 / 33 なので
であり、各 i に対しては
P( A0 | B ) = 70 / 328 ≅ 0.213
P( A1 | B ) = 84 / 328 ≅ 0.256
P( A2 | B ) = 84 / 328 ≅ 0.256
P( A3 | B ) = 63 / 328 ≅ 0.192
P( A4 | B ) = 27 / 328 ≅ 0.0823
という結果が得られます。4 問正解していたとしても、その全ての回答を知っていた確率は 0.1 より小さく、いくつかの問題に対しては適当に選んで偶然に当たった可能性が高いと考えられますが、いくつの問題がまぐれ当りだったのかについてはほとんど同程度の確率になっているので判断はできないことになります。極端な話、全てまぐれだったという可能性もそれほど低くはありません。しかし、10 個の選択肢から選択しなければならないとすれば、まぐれ当たりの確率は低くなることが予想され、実際に計算すると
10-0 C 4-0 ( 1 / 10 )4-0 = ( 10・9・8・7 / 4・3・2 )( 1 / 104 ) = 21 / 103
10-1 C 4-1 ( 1 / 10 )4-1 = ( 9・8・7 / 3・2 )( 1 / 103 ) = 84 / 103
10-2 C 4-2 ( 1 / 10 )4-2 = ( 8・7 / 2 )( 1 / 102 ) = 280 / 103
10-3 C 4-3 ( 1 / 10 )4-3 = 7 / 10 = 700 / 103
10-4 C 4-4 ( 1 / 10 )4-4 = 1 = 1000 / 103
より分母は ( 21 + 84 + 280 + 700 + 1000 ) / 103 = 2085 / 103 となるので
となって、各 i に対しては
P( A0 | B ) = 21 / 2085 ≅ 0.0101
P( A1 | B ) = 84 / 2085 ≅ 0.0403
P( A2 | B ) = 280 / 2085 ≅ 0.134
P( A3 | B ) = 700 / 2085 ≅ 0.336
P( A4 | B ) = 1000 / 2085 ≅ 0.480
になります。答えを全て知っていたので 4 問正解したという確率が半分程度で、せいぜい一問だけまぐれで当たる場合もあるとすれば全体の 8 割程度の確率になります。まぐれ当りを少なくするためには選択肢を増やせばよいというのは直感的にも納得できる結果です。
4 問正解したという事象は「結果」であり、その「原因」となったのは回答者が答えを何問知っていたかという事象です。ベイズの定理の左辺は 4 問正解したという「結果」を前提とした時の「原因」に対する確率であり、それを「原因」に対する「結果」の確率と、その「原因」の発生確率を使って求めていることになります。このことから、条件付確率は「原因の確率」と呼ばれることもあります。各原因に対する確率 (ここでは、答えを知っている数が等しい回答者が全体の中で占める割合) は、最初は全て等しいものと仮定していました。回答者がどれだけ答えを知っているのか、それを知るためにはテストとは別にその答えを知っていたかアンケートを取り、その結果を元に算出する必要がありますが、そんなことをするくらいならテストせずにアンケートだけにすればよいわけで、そうしたとしても正直にそれに答える回答者はいないことが明白なので (選択肢の横に「この答えを知っていましたか」と書かれていて「知りませんでした。だから適当に選んでます」と素直に答える人はいないですよね)、最初から確率を決めておくことはほとんど不可能です。このようなとき、特に反対する理由が見つからなければ全ての事象の確率は等しいとする考え方を「理由不十分の原則(Principle of Insufficient Reason)」といいます。もちろん頻度の考え方は様々で、例えば、テストの内容がすでに講義で説明されていて、大半の回答者はその答えをある程度は知っているという前提であれば、この原則は成り立たないので適当に頻度の調整を行う必要がありますが、ここで重要になるのは、頻度を求めるための材料が今回はないため、客観的に計算をすることができず主観に基づいて決める必要があるという事実です。今まで説明してきた統計学では、データを元に客観的に推定や検定を行うというのが根底にありました。母集団の分布状況を推定するため、その中から抽出したデータを元に計算を行うという一連の流れの中では、少なくとも計算結果を得るまでの間は主観的な考えは完全に排除されています。しかし、何らかの事象を予想するような場合、推定をするための肝心なデータが存在しないため従来の手法を用いることができません。よって、そのようなときは主観に基づいて確率を定義するプロセスを導入する必要が生じるわけです。このような確率のことを「主観確率(Subjective Probability)」または「ベイズ確率(Bayesian Probability)」といいます。
三択の場合と 10 択の場合それぞれにおいて、各原因に対する確率は 4 問正解したという事象によって変化し、等しい確率にはならなくなっています。このように、ベイズの定理を利用することで原因の確率が更新され、最初の予想が変化していく様子を表すことができます。更新された確率 P( Ai | B ) は新たな P( Ai ) として再利用することができて、最初は全て等しいと考えていた頻度はやがて偏った頻度に変化していくことも予想できます。このような手法を「ベイズ更新(Bayesian Updating)」といい、その手法を使った推定法を「ベイズ推定(Bayesian Inference)」といいます。この考え方から見れば P( Ai ) は最初に想定した確率なので、これを「事前確率(Prior Probability)」と呼び、ベイズの定理によって得られた新たな確率 P( Ai | B ) を事前確率に対して「事後確率(Posterior Probability)」と呼ぶ場合もあります。
ベイズ推定の例題としてよく登場する問題に、箱から赤白の玉を抽出する実験があります。箱が一つあり、赤と白の玉が未知の割合で入っているとします。箱からランダムに N 回復元抜き取り (取り出した玉は箱に戻す操作) をした結果、取り出した玉が赤であった回数が r 回のとき、赤と白の玉がどの程度の比率で入っているのかを推定したいとします。今、赤い玉が全体に対して θ ( 0 ≤ θ ≤ 1 ) の割合で入っていたとした時、N 回の抽出で赤が r 回である確率は二項分布 BN,θ(r) から
になります。実際の試行によって r 回という結果になった時、その結果から θ を推定するためには、θ を変数、r を定数として
と考え、この値が最大になるような θ を求めれば、事象が発生する確率が最も高くなります。この値を「尤度(Likelihood)」といい、尤度が最も高くなるような推定量 θ を「最尤推定量(Maximum Likelihood Estimator ; MLE)」、最尤推定量を求める手法を「最尤法(Maximum Likelihood Estimation ; MLE)」というのでした。最大値を求めるときは係数の NCr は無視できるので、尤度は L(θ) で表して
とすることができます。dL / dθ = 0 となる θ は 0, 1, r / N で、L が最大になるのは r / N のときになり、直感的にも納得できる結果となります。
ベイスの定理を使ってこの問題を解く場合、N 回の復元抜き取りで赤玉が r 回出たという結果に対して、その原因が、赤い玉が全体に対して θ の割合で入っているからだとすれば、
と表すことができます。分母にある和の中で、Ω は全事象を表し、θ が Ω の中で取りうる全ての比率に対して和を計算することを意味します。箱の中の玉の合計はわからないためこのような書き方になっていますが、例えば合計が 3 ならば、θ = { 0, 1/3, 2/3, 1 } となります。
この式の中で、P( r | θ ) は赤玉の割合が θ であるという条件下で赤玉が r 回出る確率であり、これも二項分布から
になります。分母は全ての θ についての P( r | θ )P( θ ) の和ですが、ベイズの定理の導出過程から明らかなように、これは結果が r になる確率 P( r ) と等しくなります。最後に P( θ ) は赤玉の比率が θ である事前確率を表しています。ここで r を固定すれば、P( r | θ ) は θ のみの関数で尤度と同じものになり、分母は θ を持たないため定数となります。事前確率 P( θ ) と尤度 P( r | θ ) の積を何らかの定数で割れば事後確率 P( r | θ ) に等しくなることから、事後確率は事前確率と尤度の積に比例することになり、これを
と表します。ここで、P( θ | r ) も P( θ ) も θ を確率変数とする確率密度関数と考えて、P( θ ) は「事前分布(Prior Distribution)」、P( θ | r ) は「事後分布(Posterior Distribution)」と呼ばれます。
尤度 P( r | θ ) は θr ( 1 - θ )N-r で表されるので、
ということになります。ここで、事前分布 P( θ ) が
という式で表せるとします。K は定数であり、
である必要があるので( β( α, β ) は「ベータ関数(Beta Function)」です )、K = 1 / β( α, β ) となりますが、この定数を無視してしまえば事後分布は
となって、事後分布も事前分布も同じ確率密度関数を使って表すことができるようになります。確率密度関数は事前分布と事後分布で同じである方が扱いやすく、予想が極端に変化してしまうこともないので、このような状態になる方が都合がよいことは理解できると思います。∫Ω P( θ | r ) dθ = 1 になるためには
K∫{0→1} θr+α-1 ( 1 - θ )N-r+β-1 dθ = Kβ( r + α, N - r + β ) = 1 より
K = 1 / β( r + α, N - r + β )
であればよいので、事後確率の確率密度関数は
になります。
試行前は、箱の中にある赤と白の比率は全くわからないので、「理由不十分の原則」に従って θ はどの値も等しい確率で取りうると考えれば、事前確率は一様分布に従います。この時は α = β = 1 であり、事後分布は
となります。これは「ベータ分布(Beta Distribution)」と呼ばれる確率密度関数の一つですが(補足 1)、全事象に対する積分値が 1 となるように係数を持つことを除けば、最尤法における尤度と一致します。また、P( θ | r ) の平均は r / [ r + ( N - r ) ] = r / N であり、最尤推定量として求めた値と等しくなります。
ベイズ推定では、事後分布は尤度と事前分布の積で表されます。パラメータ θ が取りうる全ての値において事前確率が等しければ事後分布は尤度そのものになるので、事前に何の情報もなく事前分布を決められない場合、P( θ ) = (一定) と仮定すれば、ベイズ推定と最尤推定法は同じ結果が得られることになります。しかし、両者の違いは試行を繰り返した時に現われ、最尤推定法の場合は試行を何度実施しても事前分布は一定のままであるのに対し、ベイズ推定では「ベイズ更新」によって事前分布が事後分布に置き換えられます。また、充分な根拠があれば、最初の試行時に仮定する事前分布も一様分布以外の分布にすることができます。ここが最尤推定法とベイズ推定の大きな違いになります。前者は、独立試行である限り、P( θ ) が変化することはないという立場であるのに対し、後者は尤度によって P( θ ) を更新することができるという立場を取ります。特に、点推定としての最尤推定法では θ はある決まった値を取り、決して確率変数にはなり得ません。このあたりが、一般的に使われる統計学とは相反する考え方であり、批判の要因となっているようです。
しかし、それまでの過程を元にして確率が (主観的に) 変化することはよくある話です。例えば、野球やサッカーなどのトーナメント戦で、最初はどのチームも互角だと思っていたのに、あるチームの勝率が高くなってゆくと、各試合におけるそのチームの勝率は高い (たいてい勝つだろう) と推測するようになります。そういった意味において、ベイズ推定はより人間の考え方に合った手法であるとも言えます。
尤度が二項分布に従うとき、事前分布をベータ分布にすることで、事後分布もベータ分布の形にすることができました。このような分布は「共役事前分布(Conjugate Prior Distribution)」と呼ばれ、例えば二項分布の共役事前分布はベータ分布である、ということになります。他の例として、正規分布の平均をパラメータ θ としたときの尤度を考えると、その標本が x = ( x1, x2, ... xN ) ならば尤度 P( x | θ ) は
| P( x | θ ) | = | Πi{1→N}( exp( -( xi - θ )2 / 2σ2 ) / ( 2πσ2 )1/2 ) |
| = | exp( Σi{1→N}( -( xi - θ )2 / 2σ2 ) ) / ( 2πσ2 )N/2 |
で表されます。指数部の和は
| Σi{1→N}( -( xi - θ )2 / 2σ2 ) | |
| = | Σi{1→N}( -( xi2 - 2xiθ + θ2 ) / 2σ2 ) |
| = | Σi{1→N}( -[ θ2 - 2mθ + m2 + xi2 - m2 ] / 2σ2 ) |
| = | Σi{1→N}( -[ ( θ - m )2 + xi2 - 2xim + m2 ] / 2σ2 ) |
| = | Σi{1→N}( -[ ( θ - m )2 + ( xi - m )2 ] / 2σ2 ) |
| = | -( θ - m )2 / [ 2( σ / √N )2 ] + Σi{1→N}( -( xi - m )2 / 2σ2 ) |
と変形することができます。但し、m = Σi{1→N}( xi ) / N として、Σi{1→N}( xi ) = Nm = Σi{1→N}( m ) であることを利用しています。従って、尤度は
| P( x | θ ) | = | exp( -( θ - m )2 / [ 2( σ / √N )2 ] + Σi{1→N}( -( xi - m )2 / 2σ2 ) ) / ( 2πσ2 )N/2 |
| = | exp( -( θ - m )2 / [ 2( σ / √N )2 ] )・exp( Σi{1→N}( -( xi - m )2 / 2σ2 ) ) / ( 2πσ2 )N/2 |
と求められますが、この中で変数 θ を持つのは exp( -( θ - m )2 / [ 2( σ / √N )2 ] ) の部分だけなので、他は定数として無視すれば、ベイズの定理は
とすることができます。尤度が指数関数なので、事前確率も正規分布 N( μ, τ2 ) の形にすれば、式を簡単にするために ( σ / √N )2 = υ2 と表して
| P( θ | x ) | ∝ | N( μ, τ2 )・N( m, υ2 ) |
| = | exp( -( θ - μ )2 / 2τ2 )・exp( -( θ - m )2 / 2υ2 ) | |
| = | exp( -( θ - μ )2 / 2τ2 - ( θ - m )2 / 2υ2 ) | |
| = | exp( -[ υ2( θ - μ )2 + τ2( θ - m )2 ] / 2τ2υ2 ) | |
| = | exp( -[ ( υ2 + τ2 )θ2 - 2( υ2μ + τ2m )θ + ( υ2μ2 + τ2m2 ) ] / 2τ2υ2 ) |
指数部分の分子を、θ2 項の係数を消すために υ2 + τ2 で割ると、
| (分子) | = | θ2 - 2[ ( υ2μ + τ2m ) / ( υ2 + τ2 ) ]θ + ( υ2μ2 + τ2m2 ) / ( υ2 + τ2 ) |
| = | { θ - [ ( υ2μ + τ2m ) / ( υ2 + τ2 ) ] }2 - [ ( υ2μ + τ2m ) / ( υ2 + τ2 ) ]2 + ( υ2μ2 + τ2m2 ) / ( υ2 + τ2 ) |
と変形できて、第二行目以降は θ を持たない定数項なので無視すれば
| P( θ | x ) | ∝ | exp( -{ θ - [ ( υ2μ + τ2m ) / ( υ2 + τ2 ) ] }2 / 2[ τ2υ2 / ( υ2 + τ2 ) ] ) |
| = | N( ( υ2μ + τ2m ) / ( υ2 + τ2 ), ( τυ / ( υ2 + τ2 )1/2 )2 ) |
となるので事後確率も正規分布になります。事前分布の平均 μ は m によって
へ更新され、これは 1 / τ2 : 1 / υ2 の比率で重み付けした両者の平均を表しています。υ2 = τ2 ならば平均そのものになります。分散が大きい側の分布の平均からは離れてゆき、極限として分散が無限大なら、そうでない分布の平均と一致します。
分散は、τ2 から
へ、すなわちその逆数 1 / τ2 が ( 1 / τ )2 + ( 1 / υ )2 へ更新されることになります。分散の逆数は大きく、つまり分散は小さくなることから、分布のばらつきは小さくなるように更新されます。
分散がパラメータとなる場合はどうなるでしょうか。θ = σ2 とすれば、尤度 P( x | θ ) は
| P( x | θ ) | = | exp( Σi{1→N}( -( xi - μ )2 / 2θ ) ) / ( 2πθ )N/2 |
| ∝ | θ-N/2・exp( -T2 / 2θ ) |
となります。但し、
としています。このとき、ベイズの定理は
となるので、事前分布として
を定義すれば、
| P( θ | x ) | ∝ | θ-ν/2-1exp( -ντ / 2θ )・θ-N/2exp( -T2 / 2θ ) |
| = | θ-(ν+N)/2-1exp( -( ντ + T2 ) / 2θ ) |
と表すことができます。事前分布 P( θ ) は「尺度付き逆カイ二乗分布」と呼ばれる確率密度関数で(補足 2)、カイ二乗分布の確率変数を逆数にしたときとよく似た形になっています。ν は自由度、τ は尺度母数と呼ばれるパラメータで、事後分布ではこれらがそれぞれ ν + N, ντ + T2 に更新されています。N は標本数であり、サンプルが増えるたびに大きくなります。それに対して T2 は平均差の二乗和なので、平均差が小さければほとんど変化しないことが期待できます。自由度が尺度母数に対して十分大きければ、分布形状は正規分布に近くなり、その平均は尺度母数とほぼ等しくなります。また、自由度が大きくなるほど分散も小さくなるので、更新を続けることで分布の精度も上がります。
次に、「ポアソン分布(Poisson Distribution)」の共役事前分布を求めてみます。ポアソン分布は次のような確率密度関数で表されるのでした。
λ はこの分布の平均となるパラメータで、二項分布において平均 Np = λ とおいて N→∞ としたときの極限がこの分布になるのでした。試行回数 N 回に対してその結果が r = ( r1, r2, ... rN ) ( 但し ri = { 0, 1 } ) であれば、λ を変数 θ とした尤度は
| P( r | θ ) | = | Πi{1→N}( θrie-θ / ri! ) |
| ∝ | θΣi{1→N}(ri)e-Nθ | |
| = | θre-Nθ |
となります。但し、r = Σi{1→N}( ri ) としました。このとき、事前分布として
を仮定すれば、ベイズの定理は
| P( θ | x ) | ∝ | θα-1e-θ/β・θre-Nθ |
| = | θα+r-1e-(1/β+N)θ | |
| = | θα+r-1e-θ/[β/(βN+1)] |
になります。この事前分布は「ガンマ分布(Gamma Distribution)」と呼ばれ(補足 3)、形状母数(Shape Parameter) α と尺度母数(Scale Parameter) β をパラメータとして持っています。上記結果は、ベイズの定理によって事後分布の α が α + r に、β が β / ( βN + 1 ) にそれぞれ更新されることを示しています。N は試行回数、r はその試行に対して 1 となった回数を表すので、r が小さければ α はほとんど変化しないのに対して、β は試行回数 N によって小さくなっていきます。
ベイズの定理を応用した仕組みの中で最も有名なものの一つが「ベイジアン・フィルタ(Bayesian Filter)」です。「ベイジアン・フィルタ」は「単純(ナイーブ)ベイズ分類器(Naive Bayes Classifier)」を利用してデータの分類やフィルタリングを行う機能で、e-メールのスパム判定などに利用されています。「ベイジアン・フィルタ」を理解するには、「単純ベイズ分類器」で利用されている確率モデルである「単純ベイズ確率モデル(Naive Bayes Probabilistic Model)」の知識が必要になります。
まず、スパムや非スパムといった分類対象を「クラス(Class)」とし、クラスが持っている特徴を「特徴ベクトル(Feature Vector)」とします。「特徴ベクトル」という言葉からわかるように、クラスの特徴は一つとは限らず、複数持つことができます。スパム・フィルタに利用するのなら、クラスは通常「スパム」と「非スパム(これをハムともいいます)」の二つ存在し、それぞれの特徴として、メールの中で使われている単語を使用するのが一般的です。しかし、メールの判別に対して三つ以上のクラスを用意してはいけないというわけではなく、例えば「サポートメール」「友人からのメール」「その他のメール」というような分類をするようなことも可能です。
M 個の要素からなる特徴ベクトルを f = ( f1, f2 ... fM ) とし、あるクラスを ci ( i = 1, 2, ... N ) で表した時、求めたい値はある特徴ベクトル f を前提としたときクラス ci に属するときの条件付確率 P( ci | f ) で、この確率が高いクラス ci が選択対象となります。例えば、メールの中の単語を特徴ベクトルの要素とするなら、ある単語列が利用された場合に、そのメールがあるクラスに属する可能性を求めることになります。
クラスへの分類を行うためには、あらかじめ P( ci | f ) を求めておく必要があります。この操作を「学習(Learning)」といい、学習に使う特徴ベクトルは「学習パターン(Learning Pattern)」などと呼ばれます。ある学習パターン f が fk と等しい時、そのクラスが ci であるとして学習させるのならば、そのような学習パターンの個数を N( ci, fk ) として
で求められます。但し、N( fk )は、特徴ベクトルが fk である要素の合計を表し、特徴ベクトルが fk である要素の中でクラスが ci である比率を求めていることになります。例えば、非常に単純なモデルとしてクラスを c1, c2 の二つ、特徴ベクトルは二次元ベクトル f = ( f1, f2 ) で、0 か 1 のいずれかを取るものとします。次のような表の場合、
| No. | f1 | f2 | クラス | No. | f1 | f2 | クラス |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | c1 | 11 | 0 | 0 | c2 |
| 2 | 1 | 0 | c1 | 12 | 1 | 1 | c2 |
| 3 | 1 | 0 | c1 | 13 | 1 | 0 | c2 |
| 4 | 1 | 1 | c1 | 14 | 0 | 1 | c2 |
| 5 | 1 | 0 | c1 | 15 | 0 | 1 | c2 |
| 6 | 1 | 0 | c1 | 16 | 0 | 1 | c2 |
| 7 | 0 | 0 | c1 | 17 | 1 | 1 | c2 |
| 8 | 1 | 0 | c1 | 18 | 0 | 0 | c2 |
| 9 | 1 | 0 | c1 | 19 | 0 | 1 | c2 |
| 10 | 1 | 1 | c1 | 20 | 0 | 0 | c2 |
N( c1, f = ( 0, 0 ) ) = 1 ; N( c1, f = ( 0, 1 ) ) = 0
N( c1, f = ( 1, 0 ) ) = 7 ; N( c1, f = ( 1, 1 ) ) = 2
N( c2, f = ( 0, 0 ) ) = 3 ; N( c2, f = ( 0, 1 ) ) = 4
N( c2, f = ( 1, 0 ) ) = 1 ; N( c2, f = ( 1, 1 ) ) = 2
N( f = ( 0, 0 ) ) = 4 ; N( f = ( 0, 1 ) ) = 4
N( f = ( 1, 0 ) ) = 8 ; N( f = ( 1, 1 ) ) = 4
P( c1 | f = ( 0, 0 ) ) = 1 / 4 ; P( c2 | f = ( 0, 0 ) ) = 3 / 4
P( c1 | f = ( 0, 1 ) ) = 0 / 4 ; P( c2 | f = ( 0, 1 ) ) = 4 / 4
P( c1 | f = ( 1, 0 ) ) = 7 / 8 ; P( c2 | f = ( 1, 0 ) ) = 1 / 8
P( c1 | f = ( 1, 1 ) ) = 2 / 4 ; P( c2 | f = ( 1, 1 ) ) = 2 / 4
と計算できるので、f = ( 1, 0 ) なら c1、f = ( 0, 0 ) か ( 0, 1 ) なら c2、f = ( 1, 1 ) なら五分五分なので判定不能として結果を出力することができます。
しかし、次元 M の特徴ベクトルの取りうる値は 2M 通りとかなり大きな数になる上に、要素数 M は学習の度に増えることが予想されます。そのような状態では分類時に特徴ベクトルが完全に一致する場合はほとんど稀になって、かなりの量の学習パターンを用意しない限り正常に分類することは不可能です。そこで、P( ci | fk ) を別の手段で求める必要があります。
P( ci | fk ) は、ベイズの定理を利用すると
となるので、あるクラス ci に対して特徴ベクトルが fk となるときの条件付確率 P( fk | ci ) と、ci が全事象の中で発生する確率 P( ci ) を使って P( ci | fk ) を求めることができます。P( fk | ci ) は
と書き表すことができます。但し、fk = ( fk1, fk2 ... fkM ) とします。つまり、ci を前提とした、各要素が発生したという事象の積集合に対する確率を表していることになります。条件付確率の定義から、
P( A | B ) = P( A ∩ B ) / P( B ) より
を利用すると、右辺の式は
と表されます。但し、fj = fkj ( j = 1, 2, ... M ) という事象は fkj と略記しています。再度、条件付確率の定義を使って
| P( A ∩ B ∩ C ) | = | P( A | B ∩ C )・P( B ∩ C ) |
| = | P( A | B ∩ C )・P( B | C )・P( C ) |
であることを再帰的に利用すると、
| P( fk1 ∩ fk2 ∩ ... ∩ fkM ∩ ci ) | |
| = | P( fk1 | fk2 ∩ ... ∩ fkM ∩ ci )・P( fk2 ∩ ... ∩ fkM ∩ ci ) |
| = | P( fk1, | fk2 ∩ ... ∩ fkM ∩ ci )・P( fk2 | fk3 ∩ ... ∩ fkM ∩ ci )・P( fk3 ∩ ... ∩ fkM ∩ ci ) |
| : | |
| = | P( fk1 | fk2 ∩ ... ∩ fkM ∩ ci )・P( fk2 | fk3 ∩ ... ∩ fkM ∩ ci ) ... P( fkM | ci )・P( ci ) |
と表すことができます。ここで、次のような式が成り立つと仮定します。
これは、ci を前提とした条件付確率について、fkj と fkl が互いに独立であるということを表します。条件付確率の定義から、
| P( fkj ∩ fkl | ci ) | = | P( fkj ∩ fkl ∩ ci ) / P( ci ) |
| = | P( fkj | fkl ∩ ci )・P( fkl ∩ ci ) / P( ci ) | |
| = | P( fkj | fkl ∩ ci )・P( fkl | ci )・P( ci ) / P( ci ) | |
| = | P( fkj | fkl ∩ ci )・P( fkl | ci ) |
なので、先ほどの等式が成り立つならば
| P( fkj | fkl ∩ ci ) | = | P( fkj ∩ fkl | ci ) / P( fkl | ci ) |
| = | P( fkj | ci )・P( fkl | ci ) / P( fkl | ci ) | |
| = | P( fkj | ci ) |
が成り立つことにもなります。これは、fkl を条件に含めても含めなくても、fkj の ci を前提とした条件付確率に影響しないという事を示しています。これを「条件付独立性(Conditional Independence)」といいます。条件となる事象の中に fkl がどれだけ含まれていてもそれらは無視できるので、
P( fk1 ∩ fk2 ∩ ... ∩ fkM ∩ ci ) = P( fk1 | ci )・P( fk2 | ci ) ... P( fkM | ci )・P( ci ) より
P( fk | ci ) = P( fk1 | ci )・P( fk2 | ci ) ... P( fkM | ci )
P( ci | fk ) = P( fk1 | ci )・P( fk2 | ci ) ... P( fkM | ci )・P( ci ) / P( fk )という結果が得られます。P( fkj | ci ) はクラス ci について fj = fkj となる確率を表すので、fkj の発生頻度を ci について学習した総数で割れば簡単に得ることができます。このように、条件付独立性を仮定することによって非常に単純な計算だけで処理できるという点が「単純(ナイーブ)ベイズ」という名の由来となっています。仕組みが単純なのにも関わらず、実際には非常に精度よく分類することが可能であることから、メールの判別だけでなく、Web 上にあるドキュメントのカテゴリ分類などにも利用されているようです。主に、テキストのカテゴリ分類に利用されることから、そのような処理をベイジアン・フィルタとしている場合もよく見かけますが、今までの説明内容からわかるように、テキスト以外のデータに対しても応用は可能です。
ベイジアン・フィルタの具体的な処理について説明する前に、メールなどの文章から単語を抽出するためのサンプル・プログラムを以下に示します。
typedef unsigned int UInt; /* isDelim : 区切り文字の判定 char c : 対象の文字 戻り値 : 判定結果 空白文字・印字不可能な文字・','・'.' を区切り文字対象とする */ bool isDelim( char c ) { if ( ! isgraph( c ) ) return( true ); return( c == ',' || c == '.' ); } /* skipDelim : 文字列中の区切り文字をスキップする const string& str : 対象文字列 string::size_type s : 文字列中の処理開始位置 戻り値 : スキップ後の位置(末尾まで区切り文字ならnposを返す) */ string::size_type skipDelim( const string& str, string::size_type s ) { while ( s < str.length() ) { if ( ! isDelim( str[s] ) ) break; ++s; } if ( s >= str.length() ) return( string::npos ); else return( s ); } /* findDelim : 文字列中の区切り文字を探索する const string& str : 対象文字列 string::size_type s : 文字列中の処理開始位置 戻り値 : 区切り文字の位置(末尾まで達したならnposを返す) */ string::size_type findDelim( const string& str, string::size_type s ) { if ( s == string::npos ) return( string::npos ); while ( s < str.length() ) { if ( isDelim( str[s] ) ) break; ++s; } if ( s >= str.length() ) return( string::npos ); else return( s ); } /* Create_BagOfWords : bag-of-wordsを作成する istream& is : 入力ストリーム map<string,UInt>& bagOfWords : bag-of-words */ void Create_BagOfWords( istream& is, map<string,UInt>& bagOfWords ) { string lineData; // 文字列のバッファ bagOfWords.clear(); // bag-of-wordsの初期化 while ( getline( is, lineData ) ) { // 単語の開始と終了位置 string::size_type s = skipDelim( lineData, 0 ); string::size_type e = findDelim( lineData, s ); while ( e != string::npos ) { if ( e > s ) { string word = lineData.substr( s, e - s ); // 抽出した単語 if ( bagOfWords.find( word ) == bagOfWords.end() ) bagOfWords[word] = 0; ++( bagOfWords[word] ); } // 次の単語の開始と終了位置を取得 s = skipDelim( lineData, e + 1 ); e = findDelim( lineData, s ); } // 最後の単語を抽出 if ( s != string::npos ) { string word = lineData.substr( s ); // 抽出した単語 if ( bagOfWords.find( word ) == bagOfWords.end() ) bagOfWords[word] = 0; ++( bagOfWords[word] ); } } }
文章から抽出した単語は、文章中での順序やそれぞれの関係などは無視され、単語の単純な集合として表現されます。このようなモデルは "bag-of-words" と呼ばれます。Create_BagOfWords は bag-of words を生成するための関数で、入力ストリームの is から読み込んだ文字列から単語を抽出して、string 型をキー、unsigned int型 (サンプル・プログラム内では UInt と型名を定義しています) を値とするコンテナクラス map 型の変数 bagOfWords に登録します。bagOfWords のキーは単語そのもので、値はその単語が文章中で発生した回数を表します。この関数の中で使われている getline は STL で標準装備されているヘルパ関数で、入力ストリームから一行分のデータを取得することができます。istream クラスのメンバ関数にも同じ名称・目的のものが存在しますが、こちらは char 型の配列へデータを取り込むため扱いが面倒です。文字列の取り込みをする場合はヘルパ関数を利用した方が便利です。
読み込んだ一行分の文字列は、区切り文字で各単語に分割しています。区切り文字を判別する関数は isDelim で、ここでは空白文字・表示できない文字・',' (カンマ)・'.' (ピリオド) を区切り文字として扱っています。この関数を利用して、skipDelim で単語の先頭を探索し、findDelim で単語の末尾にある区切り文字を探索します。抽出した単語はそのまま bagOfWords へ登録します。
抽出した単語に対して、大文字または小文字に統一したり、余分な文字 (例えば and や or などの接続詞や in, on, at などの前置詞) は無視するなどの処理を取り込むことも検討の余地があります。また、単語の先頭や末尾に余計な文字が付加している場合、同じ単語に対して異なると判断されてしまうので、それを除外する処理を加えることも考えられますが、例えば感嘆子などが付加されるかどうかも判別の材料になるならば、除外しない方が判別力が向上することも想定されるので、このあたりは試験や調整が必要になる部分になります。今回はサンプルということで、そのような処理は一切入っていません。
最後に、このサンプル・プログラムは、空白で単語を区切らない日本語などの文章に対しては利用できません。日本語を単語に分解する手法は、それ自身が一つの大きなテーマとなり簡単には実装できません。この分野は「形態素解析」と呼ばれ、専用のライブラリなども存在しているので、本格的な実装をする場合はそのようなライブラリを利用するのが最も簡単なやり方です。
文章などの要素の集合から「単純(ナイーブ)ベイズ」を利用する方法としては代表的なものが二種類あります。まず、bag-of-words 内にある要素の発生回数は無視して、その要素が発生したかどうかのみを扱う手法について紹介します。
P( fj | ci ) を、クラスが ci のときに fj が発生する確率とします。このとき、fj の取りうる値は
| fj | = | 1 | (fjがあるとき) |
| = | 0 | (fjがないとき) |
の二つと考えることができるので、fj = 1 となる個数を N( ci, fj )、ci に属する学習パターンの総数を N( ci ) とすれば、
になります。ci に対して、fj が存在する確率は P( fj | ci ) で、存在しない確率は 1 - P( fj | ci ) から求めることができるので、これはベルヌーイ分布 (Bernoulli Distribution) と呼ばれる確率密度関数の一つです。よって、この方式は「多変数ベルヌーイ・モデル(Multivariate Bernoulli Model)」と呼ばれています。
先ほどの例において、fj = 1 が要素があった場合、fj = 0 が要素がなかった場合と考えれば、
N( c1, f1 ) = 9 ; N( c1, f2 ) = 2
N( c2, f1 ) = 3 ; N( c2, f2 ) = 6
N( c1 ) = 10 ; N( c2 ) = 10 より
P( f1 | c1 ) = 9 / 10 ; P( f2 | c1 ) = 2 / 10
P( f1 | c2 ) = 3 / 10 ; P( f2 | c2 ) = 6 / 10
であり、
P( f = ( 0, 0 ) ) = 4 / 20 ; P( f = ( 0, 1 ) ) = 4 / 20
P( f = ( 1, 0 ) ) = 8 / 20 ; P( f = ( 1, 1 ) ) = 4 / 20
P( c1 ) = P( c2 ) = 1 / 2
となるので、
| P( c1 | f = ( 0, 0 ) ) | = | [ 1 - P( f1 | c1 ) ]・[ 1 - P( f2 | c1 ) ]・P( c1 ) / P( f = ( 0, 0 ) ) |
| = | ( 1 / 10 )・( 8 / 10 )・( 1 / 2 ) / ( 4 / 20 ) | |
| = | 4 / 20 | |
| P( c1 | f = ( 0, 1 ) ) | = | 1 / 20 |
| P( c1 | f = ( 1, 0 ) ) | = | 18 / 20 |
| P( c1 | f = ( 1, 1 ) ) | = | 9 / 20 |
| P( c2 | f = ( 0, 0 ) ) | = | 14 / 20 |
| P( c2 | f = ( 0, 1 ) ) | = | 21 / 20 |
| P( c2 | f = ( 1, 0 ) ) | = | 3 / 20 |
| P( c2 | f = ( 1, 1 ) ) | = | 9 / 20 |
となります。先ほど計算した正確な確率と比較するといくらかの誤差があり、なかには 1 を超えている場合もありますが、これは条件付独立性を仮定して計算したのに対して、実際にはそれが成り立たない部分もあるためです。しかし、f の値が等しい条件において、c1 と c2 の確率の大小関係は、正確な確率で比較した場合と一致します。
なお、確率の大小関係を比較するのであれば、分母の P( f ) は比較対象の間では全て等しいので無視することができます。従って、分母を除いて分子の項だけを計算すればフィルタ処理のためには充分です。
多変数ベルヌーイ・モデルによるベイジアン・フィルタのサンプル・プログラムを以下に示します。
typedef unsigned int UInt; /* Bernoulli_NaiveBayesClass : 多変数ベルヌーイ・モデルを使ったナイーブ・ベイズ */ template<class T> class Bernoulli_NaiveBayesClass { map<string, UInt> className_; // クラス名の配列 vector<UInt> trainCount_; // 学習パターンの数 map<T, vector<UInt> > count_; // 各特徴の数 public: // 学習処理 void training( const string& name, const map<T,UInt>& data ); // 発生比率の積の対数を返す void prob( const map<T,UInt>& data, map<string,double>& totalProb ) const; // 学習結果の出力 template<class T2> friend ostream& operator<<( ostream& os, const Bernoulli_NaiveBayesClass<T2>& nbClass ); }; /* Bernoulli_Bernoulli_NaiveBayesClass<T>::training : 学習 const string& name : クラス名 const map<T,UInt>& data : 学習パターン */ template<class T> void Bernoulli_NaiveBayesClass<T>::training( const string& name, const map<T,UInt>& data ) { // 未登録クラスの場合の処理 if ( className_.find( name ) == className_.end() ) { UInt i = className_.size(); // クラス数(新クラスの添字になる) className_[name] = i; // 各要素の発生回数を初期化(あらかじめ 1 加算しておく) for ( typename map< T, vector<UInt> >::iterator it = count_.begin(); it != count_.end() ; ++it ) ( it->second ).push_back( 1 ); trainCount_.push_back( 2 ); // 学習パターンの数にはあらかじめ要素の種類(0,1)の数を加算しておく } UInt index = className_[name]; // 指定したクラスに対する添字 ++( trainCount_[index] ); // 学習処理メイン for ( typename map<T,UInt>::const_iterator dataCit = data.begin(); dataCit != data.end() ; ++dataCit ) { // 学習パターンが count_ 内に登録された位置 typename map< T, vector<UInt> >::iterator cntIt = count_.find( dataCit->first ); // count_ に登録済みの要素の処理 if ( cntIt != count_.end() ) { ++( ( cntIt->second )[index] ); // count_ に未登録の要素の処理 } else { count_[dataCit->first] = vector<UInt>( className_.size(), 1 ); ++( count_[dataCit->first][index] ); } } } /* Bernoulli_NaiveBayesClass<T>::prob : 発生比率の積の対数を返す const map<T,UInt>& data : 対象の特徴ベクトル map<string,double>& totalProb : クラスごとの発生比率の積の対数 count_内の各要素に対して P( count_[key] ) = prob( key ) [keyがdataに存在する時] 1 - prob( key ) [keyがdataに存在しない時] */ template<class T> void Bernoulli_NaiveBayesClass<T>::prob( const map<T,UInt>& data, map<string,double>& totalProb ) const { // totalProbの初期化 totalProb.clear(); for ( map<string, UInt>::const_iterator nameCit = className_.begin(); nameCit != className_.end() ; ++nameCit ) totalProb[nameCit->first] = 0; for ( typename map< T, vector<UInt> >::const_iterator cntCit = count_.begin(); cntCit != count_.end() ; ++cntCit ) { const vector<UInt>& vecCnt = cntCit->second; // 対象要素に対する頻度ベクトルへの参照 for ( map<string, UInt>::const_iterator nameCit = className_.begin(); nameCit != className_.end() ; ++nameCit ) { UInt i = nameCit->second; // 対象クラスの添字 // data に対象要素が含まれていれば P、そうでなければ 1 - P totalProb[nameCit->first] += ( data.find( cntCit->first ) != data.end() ) ? log( (double)( vecCnt[i] ) / (double)( trainCount_[i] ) ) : log( 1.0 - (double)( vecCnt[i] ) / (double)( trainCount_[i] ) ); } } // 総学習パターン数の計算 UInt totalSum = 0; for ( UInt i = 0 ; i < trainCount_.size() ; ++i ) totalSum += trainCount_[i]; totalSum -= 2 * trainCount_.size(); // 2 だけ余分に加算した分を補正 // 総数に対する各クラスの学習パターン数から頻度を算出して追加 for ( map<string, UInt>::const_iterator nameCit = className_.begin(); nameCit != className_.end() ; ++nameCit ) totalProb[nameCit->first] += log( (double)( trainCount_[nameCit->second] - 2 ) / (double)( totalSum ) ); } /* operator<< : 結果の出力 ostream& os : 出力ストリーム const Bernoulli_NaiveBayesClass<T>& nbClass : 対象の NaiveBayesClass 戻り値 : 出力ストリーム os への参照 */ template<class T> ostream& operator<<( ostream& os, const Bernoulli_NaiveBayesClass<T>& nbClass ) { // クラス名の出力 for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << nameCit->first; os << endl; // 要素ごとの出現頻度を出力 for ( typename map<T, vector<UInt> >::const_iterator cntCit = nbClass.count_.begin(); cntCit != nbClass.count_.end() ; ++cntCit ) { os << cntCit->first; for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << ( cntCit->second )[nameCit->second] - 1; os << endl; } // クラスごとの学習パターン数を出力 os << "[TOTAL]"; for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << nbClass.trainCount_[nameCit->second] - 2; os << endl; return( os ); }
Bernoulli_NaiveBayesClass は、多変数ベルヌーイ・モデルを使ったベイジアン・フィルタ処理を行うためのクラスです。メンバ変数は三つあり、className_ は、クラス名とそのクラスの登録位置(添字)を格納する map 型の変数、trainCount_ はクラスごとの学習回数を格納する vector 型の変数、最後の count_ は、各要素ごとの出現回数を登録するための map 型の変数です。count_ のキーは要素を表し、その値は vector 型の可変長配列で、あるクラスに対する値は className_ から得られる添字を使ってアクセスできるようにしています。なお、trainCount_ から学習回数を得るときも、添字を使ってアクセスします。
P( fj | ci ) を求めるためには、クラス ci に対して学習した回数 N( ci ) と fj が出現した回数 N( ci, fj ) をあらかじめ求めておく必要があります。この処理を行うのがメンバ関数 training です。ここでは、クラス名 name として渡された学習パターン data の要素を抽出して、要素ごとの発生回数と name に対して学習を行った総回数をカウントします。対象のクラスが初めてカウントされる場合は、メンバ変数 className_ にそのクラス名を登録して新たな添字を作成し、trainCount_ と count_ を初期化します。学習処理では data から要素を一つずつ抽出し、その要素の出現回数に 1 を加えます。count_ 内にその要素が存在しない場合は、まだどのクラスにも出現していないことになるので、その要素と新たな可変長配列を用意してから出現回数を更新するようになっています。
新たなクラスや要素が出現した時の初期化処理において、count_ に対してゼロではなく 1 で初期化を行なっています。また、trainCount_ は 2 で初期化をしているので、各要素ははじめから 1 回は出現していることになり、学習回数もあらかじめ 2 回行われていたと見なされます。各要素の出現回数をゼロで初期化した場合、要素 fj がクラス ci においては一度も発生していなかったとすれば、P( fj | ci ) = 0 になります。他の要素に対する出現頻度がいくら多くても、一つでも頻度ゼロの要素があれば P( ci | f ) = 0 です。これでは正しく判断することができないので、あらかじめ 1 を加えておくことでゼロになるのを防いでいるわけです。しかし、count_ を補正しただけでは今度は確率が 1 を超えてしまう場合があるので、trainCount_ も補正が必要になります。但し、trainCount_ に対しては 1 ではなく 2 で補正します。一般に、fj の取りうる値が N 個あれば、trainCount_ を N で補正しておく必要があります。fj の取りうる値それぞれを 1 で初期化した場合、trainCount_ を N とすれば、各値が出現する確率ははじめ 1 / N で初期化されることになります。この時点ではどの値も等しい確率で発生し、その確率の合計は 1 になります。その後、例えば値が K の要素が渡されれば、fj = K の出現回数が 2 になり、trainCount_ は N + 1 なので、fj = K の確率のみ 2 / ( N + 1 ) でその他は全て 1 / ( N + 1 ) です。このときも、確率の和は 2 / ( N + 1 ) + ( N - 1 ) / ( N + 1 ) = 1 なので、確率としてきちんと成り立っています。
頻度ゼロの要素によって確率がゼロになってしまう問題は「ゼロ頻度問題 (Zero Frequency Problem)」または「スパースネスの問題(Sparseness Problem)」と呼ばれ、それを回避する手法を「スムージング(Smoothing)」といいます。あらかじめ 1 を加えておくことでゼロ頻度問題を回避する手法は「ラプラス・スムージング(Laplacian Smoothing)」といいます。
メンバ関数 prob は、渡された特徴ベクトル data が各クラスに対して属している確率 P( ci | data ) を求めるためのものです。前にも述べたように、計算式の分母にあたる data の発生確率は全体に対して共通なことから無視することができるので、分子部分の、各要素における出現確率と学習総数中に占めるクラスの比率の積から求めたい値を得ることができます。count_ にある各要素に対し、それが data にあれば出現頻度そのものの値を、なければ出現頻度を 1 から引いた差を使って積を求めていきます。しかし、ここでも一つ問題があり、求めたい値はたいてい非常に小さな値となるため、計算するうちに精度が悪くなります。これを回避するため、通常は対数を求めてその和を返します。対数にしても値の大小関係は変化しませんが、確率は 1 以下であるため得られる値は負値となります。なお、data に含まれる要素が count_ にない場合、その要素は無視されます。この場合、出現する場合としない場合でどちらの方が確率が高いのかを知る術はないので、「理由不十分の原則」からどの確率も等しいと考えるのが妥当です。従って、値の大小には影響せず、無視しても問題はありません。
もう一つの代表的な方法は、要素の発生回数も加味したモデルを利用するというものです。ここでは、クラス ci で fj が出現した回数を nij = N( ci , fj )、ci で出現した全ての要素の数を Ni = Σj{1→N}( nij ) とします。この場合、クラス ci で fj が発生する確率 P( fj | ci ) は
になります。fj の出現回数を要素とする特徴ベクトル n = ( n1, n2, ... nM ) がクラス ci で出現する確率 P( n | ci ) は、n の各要素が出現回数を表していることから「多項分布」に従うと考えることができて、
| P( n | ci ) | = | Πj{1→M}( P( fj | ci )nj )・{ [ Σj{1→M}( nj ) ]! / nj! } |
| ∝ | Πj{1→M}( P( fj | ci )nj ) |
より、Πj{1→M}( P( fj | ci )nj ) が最大になるような ci を求めればよいことになります。この手法は、多項分布をモデルにしていることから「多項モデル(Multinominal Model)」と呼ばれます。
多変数ベルヌーイ・モデルでは、各クラスの出現有無のみで判定を行なっていました。先に示した例において、各クラスの出現回数が以下のような結果だったとして、多項モデルを使って P( n | ci ) を求めててみます。
| No. | n1 | n2 | クラス | No. | n1 | n2 | クラス |
|---|---|---|---|---|---|---|---|
| 1 | 3 | 0 | c1 | 11 | 0 | 0 | c2 |
| 2 | 1 | 0 | c1 | 12 | 4 | 2 | c2 |
| 3 | 5 | 0 | c1 | 13 | 7 | 0 | c2 |
| 4 | 4 | 1 | c1 | 14 | 0 | 2 | c2 |
| 5 | 2 | 0 | c1 | 15 | 0 | 3 | c2 |
| 6 | 3 | 0 | c1 | 16 | 0 | 2 | c2 |
| 7 | 0 | 0 | c1 | 17 | 4 | 3 | c2 |
| 8 | 1 | 0 | c1 | 18 | 0 | 0 | c2 |
| 9 | 6 | 0 | c1 | 19 | 0 | 3 | c2 |
| 10 | 2 | 2 | c1 | 20 | 0 | 0 | c2 |
N( c1, f1 ) = 27 ; N( c1, f2 ) = 3
N( c2, f1 ) = 15 ; N( c2, f2 ) = 15
N1 = 30 ; N2 = 30 より
P( f1 | c1 ) = 27 / 30 ; P( f2 | c1 ) = 3 / 30
P( f1 | c2 ) = 15 / 30 ; P( f2 | c2 ) = 15 / 30
であり、例えば、特徴ベクトル n = ( 5, 0 ) の場合は
P( n | c1 ) ∝ ( 27 / 30 )5( 3 / 30 )0 ≅ 0.590
P( n | c2 ) ∝ ( 15 / 30 )5( 15 / 30 )0 ≅ 0.031
となるので c1 と判断することができて、n = ( 1, 3 ) の場合は
P( n | c1 ) ∝ ( 27 / 30 )1( 3 / 30 )3 ≅ 0.0009
P( n | c2 ) ∝ ( 15 / 30 )1( 15 / 30 )3 ≅ 0.0625
より c2 と判断することができます。多変数ベルヌーイ・モデルの場合、n = ( 1, 3 ) は f = ( 1, 1 ) に相当するため、両クラスに対する確率が等しくなって判断することはできなかったのですが、発生回数という情報が増えたことによって判断することが可能になります。
多項モデルによるベイジアン・フィルタのサンプル・プログラムを以下に示します。
typedef unsigned int UInt; /* Multinominal_NaiveBayesClass : 多項モデルを使ったナイーブ・ベイズ */ template<class T> class Multinominal_NaiveBayesClass { map<string, UInt> className_; // クラス名の配列 vector<UInt> totalCount_; // 要素数の合計 vector<UInt> trainCount_; // 学習パターンの数 map<T, vector<UInt> > count_; // 各特徴の数 public: // 学習処理 void training( const string& name, const map<T,UInt>& data ); // 発生比率の積の対数を返す void prob( const map<T,UInt>& data, map<string,double>& totalProb ) const; // 学習結果の出力 template<class T2> friend ostream& operator<<( ostream& os, const Multinominal_NaiveBayesClass<T2>& nbClass ); }; /* Multinominal_Bernoulli_NaiveBayesClass<T>::training : 学習 const string& name : クラス名 const map<T,UInt>& data : 学習パターン */ template<class T> void Multinominal_NaiveBayesClass<T>::training( const string& name, const map<T,UInt>& data ) { // 未登録クラスの場合の処理 if ( className_.find( name ) == className_.end() ) { UInt i = className_.size(); // クラス数(新クラスの添字になる) className_[name] = i; // 各要素の発生回数を初期化(あらかじめ 1 加算しておく) for ( typename map< T, vector<UInt> >::iterator it = count_.begin(); it != count_.end() ; ++it ) ( it->second ).push_back( 1 ); totalCount_.push_back( count_.size() ); // 総要素数にはあらかじめ要素の種類の数を加算しておく trainCount_.push_back( 0 ); } UInt index = className_[name]; // 指定したクラスに対する添字 ++( trainCount_[index] ); // 学習処理メイン for ( typename map<T,UInt>::const_iterator dataCit = data.begin(); dataCit != data.end() ; ++dataCit ) { totalCount_[index] += dataCit->second; // 学習パターンが count_ 内に登録された位置 typename map< T, vector<UInt> >::iterator cntIt = count_.find( dataCit->first ); // count_ に登録済みの要素の処理 if ( cntIt != count_.end() ) { ( cntIt->second )[index] += dataCit->second; // count_ に未登録の要素の処理 } else { count_[dataCit->first] = vector<UInt>( className_.size(), 1 ); count_[dataCit->first][index] += dataCit->second; // 総要素数を補正 for ( UInt i = 0 ; i < totalCount_.size() ; ++i ) ++( totalCount_[i] ); } } } /* Multinominal_NaiveBayesClass<T>::prob : 発生比率の積の対数を返す const map<T,UInt>& data : 対象の特徴ベクトル map<string,double>& totalProb : クラスごとの発生比率の積の対数 count_内の各要素に対して P( count_[key] ) = pow( prob( key ), count( key ) ) */ template<class T> void Multinominal_NaiveBayesClass<T>::prob( const map<T,UInt>& data, map<string,double>& totalProb ) const { // totalProbの初期化 totalProb.clear(); for ( map<string, UInt>::const_iterator nameCit = className_.begin(); nameCit != className_.end() ; ++nameCit ) totalProb[nameCit->first] = 0; for ( typename map< T, vector<UInt> >::const_iterator cntCit = count_.begin(); cntCit != count_.end() ; ++cntCit ) { const vector<UInt>& vecCnt = cntCit->second; // 対象要素に対する頻度ベクトルへの参照 for ( map<string, UInt>::const_iterator nameCit = className_.begin(); nameCit != className_.end() ; ++nameCit ) { UInt i = nameCit->second; // 対象クラスの添字 // 特徴ベクトル内の対象要素の位置 typename map<T,UInt>::const_iterator dataCit = data.find( cntCit->first ); if ( dataCit != data.end() ) totalProb[nameCit->first] += log( pow( (double)( vecCnt[i] ) / (double)( totalCount_[i] ), dataCit->second ) ); } } // 総学習パターン数の計算 UInt totalSum = 0; for ( UInt i = 0 ; i < trainCount_.size() ; ++i ) totalSum += trainCount_[i]; // 総数に対する各クラスの学習パターン数から頻度を算出して追加 for ( map<string, UInt>::const_iterator nameCit = className_.begin(); nameCit != className_.end() ; ++nameCit ) totalProb[nameCit->first] += log( (double)( trainCount_[nameCit->second] ) / (double)( totalSum ) ); } /* operator<< : 結果の出力 ostream& os : 出力ストリーム const Multinominal_NaiveBayesClass<T>& nbClass : 対象の NaiveBayesClass 戻り値 : 出力ストリーム os への参照 */ template<class T> ostream& operator<<( ostream& os, const Multinominal_NaiveBayesClass<T>& nbClass ) { // クラス名の出力 for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << nameCit->first; os << endl; // 要素ごとの要素数を出力 for ( typename map<T, vector<UInt> >::const_iterator cntCit = nbClass.count_.begin(); cntCit != nbClass.count_.end() ; ++cntCit ) { os << cntCit->first; for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << ( cntCit->second )[nameCit->second] - 1; os << endl; } // クラスごとの要素数合計を出力 os << "[FEATURE TOTAL]"; for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << nbClass.totalCount_[nameCit->second] - nbClass.count_.size(); // クラスごとの学習パターン数を出力 os << endl << "[TRAINING TOTAL]"; for ( map<string, UInt>::const_iterator nameCit = nbClass.className_.begin(); nameCit != nbClass.className_.end() ; ++nameCit ) os << '\t' << nbClass.trainCount_[nameCit->second]; return( os ); }
多項モデルを使ったベイジアン・フィルタ処理を行うクラスは Multinominal_NaiveBayesClass としています。メンバ変数は、Bernoulli_NaiveBayesClass より一つ増えて、新たに要素の総数を格納するための vector 型変数である totalCount_ が追加されています。メンバ関数として、学習のための training と確率計算のための prob が用意されているのは Bernoulli_NaiveBayesClass と同じです。
Multinominal_NaiveBayesClass の場合もゼロ頻度問題は発生するので、各要素に対しては最初から 1 だけ余分に加算してあります。また要素数の合計は要素の種類だけ余分に増えることになるので、totalCount_ にはその数分だけ補正する必要があります。多変数ベルヌーイ・モデルでは、各要素が取りうる値が 0 か 1 のいずれかだったため補正する値は 2 としていました。今回は各要素は全て任意の値をとることになります。そこで、初期化時に要素の数の分だけあらけじめ totalCount_ に加算しておくと、要素数が N ならば各要素の確率は 1 / N で、その和は 1 になります。学習パターンのある要素 fk の個数が M で、その他はゼロだったとき、fk の総個数は M + 1 に、totalCount_ は N + M になり、fk に対する確率は ( M + 1 ) / ( N + M )、その他の要素に対する確率は 1 / ( N + M ) なので、その和は ( M + 1 ) / ( N + M ) + ( N - 1 ) / ( N + M ) = 1 で、やはり確率として成り立っています。多変数ベルヌーイ・モデルの場合は要素が取りうる値の数、多項モデルの場合は要素そのものの数で初期化するという違いはありますが、どちらも初期化時に各要素に対して 1 を加算することによる補正であることに変わりはありません。
「多変数ベルヌーイ・モデル」と「多項モデル」の両サンプル・プログラムを利用して、先に示したデータで学習をさせてみます。以下に、もう一度そのデータを示しておきます。ここでは、一番目の要素を "a"、二番目の要素を "b" で表し、データはその出現回数とします。
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
上記結果は、スムージング処理が入っていないことに注意してください。サンプル・プログラムでも、補正分を外して出力するようにしてあります。学習後の出力結果は、多変数ベルヌーイ・モデルが出現の有無だけを見ているのに対し、多項モデルではその回数もカウントするため、値に差が生じていることがわかります。a はどちらの場合も比率に大きな違いがないのに対して、b は回数までを考慮すると c1 と c2 で差がなくなることがこの結果から読み取れます。この学習結果を元に、いくつかの特徴ベクトルを使って判定をした結果は以下のようになります。
| Bernoulli | Multinominal | |||||
|---|---|---|---|---|---|---|
| c1 | c2 | 結果 | c1 | c2 | 結果 | |
| a=5, b=0 | -1.16 | -2.67 | c1 | -1.36 | -4.16 | c1 |
| a=3, b=3 | -2.26 | -2.33 | c1 | -7.33 | -4.85 | c2 |
| a=0, b=5 | -3.87 | -1.64 | c2 | -11.09 | -4.16 | c2 |
どちらの場合も、a のみのデータに対しては c1 が、b のみのデータに対しては c2 が選ばれているのに対し、a と b の値がともに 3 の場合は判定結果が異なっています。多変数ベルヌーイ・モデルの場合は僅差ではありますが c1 の方が確率は高くなっています。それに対し、多項モデルでは c2 の確率の方が大きくなります。c2 での a と b の出現回数は同じ値なので、多項モデルで b が選ばれるのは納得できる結果です。また、各クラスの出現有無から見ると、c1 は a の方が、c2 は b の方が大きいので、両者ともに出現したパターンではどちらとも判別ができず、多変数ベルヌーイ・モデルでは確率が僅差となっています。
もうひとつ、実際のデータを使ってサンプル・プログラムで判定を行った結果を以下に示します。利用したデータは AMAZON(アメリカ) のある商品に対するレビュー記事で、5 star (この商品はよい) と 1 star (この商品は悪い) の両カテゴリから 20 個ずつ記事を抽出して学習し、さらに他の 5 star / 1 star 記事をそれぞれ 5 つずつ抽出して判定を行いました。
| Bernoulli | Multinominal | |||||
|---|---|---|---|---|---|---|
| 5 star | 1 star | 結果 | 5 star | 1 star | 結果 | |
| 5 star (1) | -391.629 | -400.947 | 5 star | -1654.67 | -1681.01 | 5 star |
| 5 star (2) | -411.063 | -437.944 | 5 star | -2098.16 | -2168.6 | 5 star |
| 5 star (3) | -265.849 | -269.732 | 5 star | -555.519 | -581.609 | 5 star |
| 5 star (4) | -402.377 | -434.273 | 5 star | -1832.2 | -1910.33 | 5 star |
| 5 star (5) | -247.153 | -228.312 | 1 star | -240.37 | -252.744 | 5 star |
| 1 star (1) | -249.264 | -218.413 | 1 star | -293.564 | -285.501 | 1 star |
| 1 star (2) | -238.793 | -209.908 | 1 star | -147.289 | -143.717 | 1 star |
| 1 star (3) | -255.878 | -229.066 | 1 star | -375.625 | -369.086 | 1 star |
| 1 star (4) | -239.579 | -227.732 | 1 star | -325.064 | -341.753 | 5 star |
| 1 star (5) | -284.201 | -271.002 | 1 star | -546.631 | -551.636 | 5 star |
表の中で、判定結果が赤くなっているのは誤判定した箇所です。学習回数がまだ少ないのか全問正解とまではいきませんが、それでもある程度正しい判定結果が得られています。今回は単語に対する後処理などは全くおこなっていないため、さらに見直しを行えば精度を向上させることは可能だと思います。これだけシンプルな実装だけである程度の精度が得られるというのは少々驚きです。
特徴ベクトル f を前提とした ci の発生確率 P( ci | f ) は、ベイズの定理から
で表されるのでした。ベイズ推定では P( f | ci ) が尤度、P( ci ) が事前分布を表し、左辺の P( ci | f ) が事後分布となります。fk ( k = 1, 2, ... Ki ) を使った学習に対し、多変数ベルヌーイ・モデルでは、尤度 P( f | ci ) は
| P( f | ci ) | = | Πk{1→Ki}( P( fk | ci ) ) |
| ∝ | Πk{1→Ki}( Πj{1→M}( pijfkj( 1 - pij )1-fkj ) ) | |
| = | Πj{1→M}( pijnj( 1 - pij )Ki-nj ) |
と表すことができます。但し、nj = Σk{1→Ki}( fkj ) で、fkj はその要素が発生した時 1、そうでない時 0 なので、j 番目の要素の発生回数を表します。また、pij は、ci における一回の試行での fj の発生確率を表します。P( f | ci ) が極値になるときの pij は、
より pij = nj / Ki で、このとき尤度は最大になります。しかしベイズ推定では事前分布も含まれているので、それを多項分布 { [ Σi{1→N}( Ki ) ]! / Πi{1→N}( Ki! ) }piKi ∝ piKi とすると
が成り立ちます。ここで、pi はクラス i の発生確率を表し、Σi{1→N}( pi ) = 1 が制約条件としてあるので pi は互いに独立な変数ではありません。この制約条件のもとで、Πi{1→N}( P( ci | f ) ) が最大となる pi と pij を求める場合、「ラグランジュの未定乗数法(Lagrange Multiplier)」を利用することができます。まず、
| F( pi, pij, λ ) | = | log Πi{1→N}( P( ci | f ) ) - λ[ Σi{1→N}( pi ) - 1 ] |
| = | log Πi{1→N}( piKiΠj{1→M}( pijnj( 1 - pij )Ki-nj ) ) - λ[ Σi{1→N}( pi ) - 1 ] | |
| = | Σi{1→N}( Kilog pi + Σj{1→M}( njlog pij + ( Ki - nj )log( 1 - pij ) ) ) - λ[ Σi{1→N}( pi ) - 1 ] |
とすると、
∂F / ∂ pij = ( nj - Kipij ) / pij( 1 - pij ) = 0
∂F / ∂ pi = Ki / pi - λ = 0
∂F / ∂ λ = Σi{1→N}( pi ) - 1 = 0
が成り立てばいいことになります。第一式は、先ほど最尤法で求めた式と同じです。第二式は pi = Ki / λ となるので、Σi{1→N}( pi ) = Σi{1→N}( Ki ) / λ であり、これを第三式に代入すれば λ = Σi{1→N}( Ki ) という結果が得られます。従って、
pij = nj / Ki
pi = Ki / Σi{1→N}( Ki )
という結果が得られ、多変数ベルヌーイ・モデルで仮定した値と一致します。これらはごく自然な考え方に基づいて利用していたのですが、ベイズ推定においての最尤推定量であることがこれで証明されたことになります。ここで、事前分布の初期値として
を利用してベイズ推定を行うと、制約条件は変わらないので、ラグランジュの未定乗数法から
| F( pi, pij, λ ) | = | log Πi{1→N}( P( ci | f ) ) - λ[ Σi{1→N}( pi ) - 1 ] |
| = | Σi{1→N}( ( Ki + α - 1 )log pi + Σj{1→M}( ( nj + α - 1 )log pij + ( Ki - nj + α - 1 )log( 1 - pij ) ) ) - λ[ Σi{1→N}( pi ) - 1 ] |
より
∂F / ∂ pij = [ ( nj + α - 1 ) - ( Ki + 2α - 2 )pij ] / pij( 1 - pij ) = 0
∂F / ∂ pi = ( Ki + α - 1 ) / pi - λ = 0
∂F / ∂ λ = Σi{1→N}( pi ) - 1 = 0
であり、これを先ほどと同じように解けば
pij = ( nj + α - 1 ) / [ Ki + 2( α - 1 ) ]
pi = ( Ki + α - 1 ) / [ Σi{1→N}( Ki ) + N( α - 1 ) ]
となります。α = 1 のときは前に解いた結果と一致しますが、α = 2 とすれば
pij = ( nj + 1 ) / ( Ki + 2 )
pi = ( Ki + 1 ) / [ Σi{1→N}( Ki ) + N ]
となって、ラプラス・スムージングを行った場合に相当します。
多項モデルの場合も同じ操作によって最尤推定量を求めることができます。多項モデルの場合、尤度は
と表すことができます。但し、nk = ( nk1, nk2, ... nkM ) は k 回目の試行に対する各要素の発生回数から成る特徴ベクトルで、nj = Σk{1→Ki}( nkj ) は全試行における j 番目の要素の発生回数を表します。この時 Σj{1→M}( pij ) = 1 の制約条件があるので、pij の最尤推定量は、ラグランジュの未定乗数法を使って
とおくことで
∂F / ∂pij = nj / pij - λ = 0
∂F / ∂λ = Σj{1→M}( pij ) - 1 = 0
という結果が得られます。第一式から Σj{1→M}( pij ) = Σj{1→M}( nj ) / λ となるので、これを第二式に代入して λ = Σj{1→M}( nj ) です。従って、
となります。事前分布を含めると
となって、さらにもう一つの制約条件 Σi{1→N}( pi ) = 1 が追加されます。よって、
| F( pi, pij, λ, κ ) | = | log Πi{1→N}( piKiΠj{1→M}( pijnj ) ) - λ[ Σj{1→M}( pij ) - 1 ] - κ[ Σi{1→N}( pi ) - 1 ] |
| = | Σi{1→N}( Kilog pi + njΣj{1→M}( log pij ) ) - λ[ Σj{1→M}( pij ) - 1 ] - κ[ Σi{1→N}( pi ) - 1 ] |
として
∂F / ∂pij = nj / pij - λ = 0
∂F / ∂pi = Ki / pi - κ = 0
∂F / ∂λ = Σj{1→M}( pij ) - 1 = 0
∂F / ∂κ = Σi{1→N}( pi ) - 1 = 0
を満たす値を求めればよいことになります。pij は先ほど求めた結果と等しく、pi も同様のやり方で pi = Ki / Σi{1→N}( Ki ) という結果が得られます。多変数ベルヌーイ・モデルと比べると、pi は等しくなりますが、pij は全要素数に対する対象要素の比率となっているところが異なります。事前分布の初期値を
とすれば、
より
∂F / ∂pij = ( nj + α - 1 ) / pij - λ = 0
∂F / ∂pi = ( Ki + α - 1 ) / pi - κ = 0
∂F / ∂λ = Σj{1→M}( pij ) - 1 = 0
∂F / ∂κ = Σi{1→N}( pi ) - 1 = 0
を解けば
pij = ( nj + α - 1 ) / [ Σj{1→M}( nj ) + M( α - 1 ) ]
pi = ( Ki + α - 1 ) / [ Σi{1→N}( Ki ) + N( α - 1 ) ]
なので、α = 2 ならば多項モデルでのラプラス・スムージングと同じ操作を意味します。
以上の結果から、ベイジアン・フィルタもベイズ推定の一つであると考えることができます。なお、ここで使われた事前分布は
P( x1, x2, ... ) ∝ Πi( xiαi-1 )
但し 0 < xi < 1 かつ αi > 0
という形をしていますが、これは「ディリクレ分布(Dirichlet Distribution)」と呼ばれ、ベータ分布を多変数に拡張した関数です。二項分布の共役事前分布がベータ関数であることから推測できるように、多項分布の共役事前分布はディリクレ分布になります。
今回は、ベイズの定理からはじまって、ベイジアン・フィルタの実装までを行いました。ベイズの定理は現在、パターン認識などの様々な分野で利用されています。今回だけに限らず、これからも様々な手法を紹介するつもりです。
二項分布は以下の式で表されます。
この式に対し、r を定数として固定して、その代わりに p を変数 x とすれば、
となり、r と N - r を任意の実数 α - 1, β - 1 とすれば、
となります。但し、K は全積分値が 1 になるときの定数値を表します。この値は、
によって求められ、∫{0→1} xα-1( 1 - x )β-1 dx はベータ関数(Beta Function) Β( α, β ) そのものなので、
となって、
という結果が得られます。この分布を「ベータ分布(Beta Distribution)」といいます。但し、ベータ関数が値を持つためには α > 0, β > 0 である必要があります。
平均 E[x] は
| E[x] | = | ∫{0→1} xα( 1 - x )β-1 dx / Β( α, β ) |
| = | Β( α + 1, β ) / Β( α, β ) | |
| = | [ Γ( α + 1 )Γ( β ) / Γ( α + β + 1 ) ] / [ Γ( α )Γ( β ) / Γ( α + β ) ] | |
| = | [ Γ( α + 1 ) / Γ( α ) ][ Γ( α + β ) / Γ( α + β + 1 ) ] | |
| = | α / ( α + β ) |
であり、E[x2] は
| E[x2] | = | ∫{0→1} xα+1( 1 - x )β-1 dx / Β( α, β ) |
| = | Β( α + 2, β ) / Β( α, β ) | |
| = | [ Γ( α + 2 )Γ( β ) / Γ( α + β + 2 ) ] / [ Γ( α )Γ( β ) / Γ( α + β ) ] | |
| = | [ Γ( α + 2 ) / Γ( α ) ][ Γ( α + β ) / Γ( α + β + 2 ) ] | |
| = | α( α + 1 ) / ( α + β )( α + β + 1 ) |
なので、分散 V[x] は
| V[x] | = | E[x2] - E[x]2 |
| = | α( α + 1 ) / ( α + β )( α + β + 1 ) - α2 / ( α + β )2 | |
| = | [ α( α + 1 )( α + β ) - α2( α + β + 1 ) ] / ( α + β )2( α + β + 1 ) | |
| = | [ ( α3 + α2β + α2 + αβ ) - ( α3 + α2β + α2 ) ] / ( α + β )2( α + β + 1 ) | |
| = | αβ / ( α + β )2( α + β + 1 ) |
になります。以上まとめると、次のようになります。
ベータ分布 Pα,β( x ) = xα-1( 1 - x )β-1 / Β( α, β ) ( 0 ≤ x ≤ 1 )
平均 : α / ( α + β )、分散 : αβ / ( α + β )2( α + β + 1 )
二項分布が、ベルヌーイ試行での成功の確率 p を固定した時の、試行に成功した回数に対する分布であるのに対し、ベータ分布は試行に成功した回数を固定した時に一回の試行が成功する確率に対して求めた分布であると見ることができます。α + β が全試行回数を表し、α が成功した回数であると見れば、α 回成功したという結果から、一回の試行における成功確率を (成功回数) / (試行回数) と考えることは自然であり、E[x] がその値と一致することは納得できると思います。また、分散値は、α = β となるときに最大値をとります。成功回数 = 失敗回数の場合は最もばらつきが大きくなるということをこの結果は表しています。
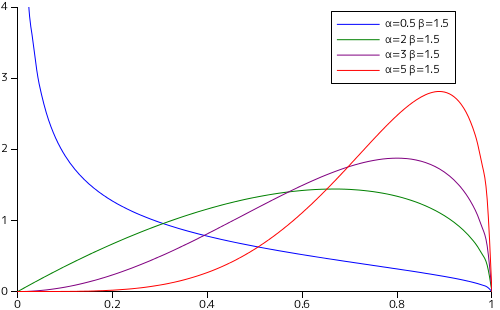
ベータ分布を、α = β の状態で値を変化させた場合と、α, β それぞれだけを変化させた場合で描画した時のグラフを以下に示します。
| α, β の変化に対する分布 | |
|---|---|
 | |
| β を固定した時の変化 | α を固定した時の変化 |
 |
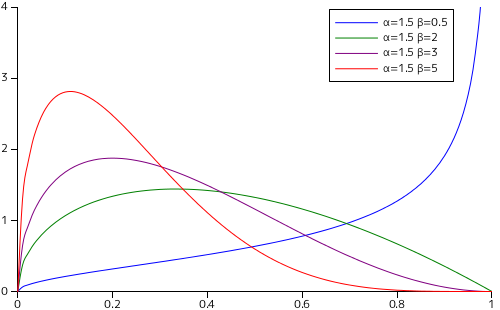 |
α = β = 1 としたときの分布は一様分布と等しくなります。また、両パラメータが 1 より小さくなると、確率密度の値は x = 0 または 1 付近で急激に大きくなります。これは確率密度関数の形からみれば明らかです。両パラメータが 1 より大きくなると、ちょうど 1 / 2 がピークになるような釣鐘型の分布になり、左右対称の形をとります。
α と β の値に偏りがあると、分布は左右対称にはなりません。α が大きくなるに従って、分布は x の大きい側にピークがシフトしていく様子が確認できます。また、β が大きくなる場合はその逆になります。α が、試行の結果が 1 になった回数であると考えれば、その回数が多くなるほど一回の試行で 1 になる確率は高いと予想できるので、分布が 1 側にシフトするのは納得のできる結果です。
「カイ二乗分布(Chi-square Distribution)」は以下のような確率密度関数でした。
N は自由度を表し、標準正規分布 N( 0 , 1 ) に従う N 個の独立な確率変数 xi ( i = 1, 2, ... N ) の二乗和 T2 = Σi{1→N}( xi2 ) は自由度 N のカイ二乗分布に従うことになります。
ここで y = 1 / x = x-1 と変数変換した確率密度関数を T-1N(y) とすると、dy = -x-2dx = -y2dx であり T-1N(y)dy = TN(x)dx なので
| T-1N(y) | = | TN(x)・| dx / dy | |
| = | [ 1 / 2N/2Γ( N / 2 ) ]y-N/2+1exp( - 1 / 2y )y-2 | |
| = | [ 1 / 2N/2Γ( N / 2 ) ]y-N/2-1exp( - 1 / 2y ) |
になります。これを「逆カイ二乗分布(Inverse Chi-Square Distribution)」といいます。T2 が自由度 N のカイ二乗分布に従うならば、その逆数 1 / T2 は自由度 N の逆カイ二乗分布に従うことになります。y = N / x = Nx-1 と変数変換して、dy = -Nx-2dx = -( y2 / N )dx より
| T-1N(y) | = | TN(x)・| dx / dy | |
| = | [ 1 / 2N/2Γ( N / 2 ) ]( N / y )N/2-1exp( - N / 2y )( Ny-2 ) | |
| = | [ ( N / 2 )N/2 / Γ( N / 2 ) ]y-N/2-1exp( - N / 2y ) |
と表す場合もあります。N / T2 = 1 / [ Σi{1→N}( xi2 ) / N ] より、標準正規分布に従う独立した確率変数の分散の逆数はこの分布に従うことになります。
また、y = Nλ / x = Nλx-1 ( λ は正の定数 ) とすれば dy = -Nλx-2dx = -( y2 / Nλ )dx なので、この分布を T-1N,λ(y) で表すと
| T-1N,λ(y) | = | TN(x)・| dx / dy | |
| = | [ 1 / 2N/2Γ( N / 2 ) ]( Nλ / y )N/2-1exp( - Nλ / 2y )( Nλy-2 ) | |
| = | [ ( Nλ / 2 )N/2 / Γ( N / 2 ) ]y-N/2-1exp( - Nλ / 2y ) |
になります。これは「尺度付き逆カイ二乗分布(Scaled Inverse Chi-Square Distribution)」といい、λ は「尺度母数(Scaling Parameter)」と呼ばれるパラメータを表します。この結果から、Nλ / T2 は自由度 N の尺度付き逆カイ二乗分布に従います。Nλ / T2 = 1 / [ Σi{1→N}( ( xi / √λ )2 ) / N ] なので、xi が標準正規分布ではなく、N( 0, λ ) に従うとしたとき、その分散の逆数が尺度付き逆カイ二乗分布に従うことになります。なお、二番目に示した逆カイ二乗分布の式は、尺度付き逆カイ二乗分布を λ = 1 としたときと見なすこともできます。
次に、自由度 N の尺度付き逆カイ二乗分布に対する平均 E[x] を求めてみます。E[x] は
で表され、y = Nλ / 2x とすると、dy = ( -Nλ / 2x2 )dx = ( -2y2 / Nλ )dx で、x→0 のとき y→∞、x→∞ のとき y→0 なので、
| E[x] | = | [ ( Nλ / 2 )N/2 / Γ( N / 2 ) ]∫{∞→0} ( Nλ / 2y )-N/2exp( -y )( -Nλ / 2y2 ) dy |
| = | [ Nλ / 2Γ( N / 2 ) ]∫{0→∞} yN/2-2exp( -y ) dy | |
| = | NλΓ( N / 2 - 1 ) / 2Γ( N / 2 ) | |
| = | NλΓ( N / 2 - 1 ) / 2( N / 2 - 1 )Γ( N / 2 - 1 ) | |
| = | Nλ / ( N - 2 ) |
と求められます。但し、ガンマ関数は正値に対してのみ値を持つことから N > 2 である必要があります。二番目に示した逆カイ二乗分布に対する平均は λ = 1 の場合を考えればよいので、
になります。さらに分子の N を 1 にすれば、一番目のときの逆カイ二乗分布に対する平均と等しくなります(計算の過程からわかるように、分母はそのままです)。すなわち
という結果が得られます。同様のやり方で、自由度 N の尺度付き逆カイ二乗分布に対する E[x2] を計算すると、
より y = Nλ / 2x とすれば、
| E[x2] | = | [ ( Nλ / 2 )N/2 / Γ( N / 2 ) ]∫{∞→0} ( Nλ / 2y )-N/2+1exp( -y )( -Nλ / 2y2 ) dy |
| = | [ ( Nλ )2 / 4Γ( N / 2 ) ]∫{0→∞} yN/2-3exp( -y ) dy | |
| = | ( Nλ )2Γ( N / 2 - 2 ) / 4Γ( N / 2 ) | |
| = | ( Nλ )2Γ( N / 2 - 2 ) / 4( N / 2 - 1 )( N / 2 - 2 )Γ( N / 2 - 2 ) | |
| = | ( Nλ )2 / ( N - 2 )( N - 4 ) |
となります。従って、分散 V[x] は
| V[x] | = | E[x2] - E[x]2 |
| = | ( Nλ )2 / ( N - 2 )( N - 4 ) - [ Nλ / ( N - 2 ) ]2 | |
| = | [ ( N - 2 ) - ( N - 4 ) ]( Nλ )2 / ( N - 2 )2( N - 4 ) | |
| = | 2( Nλ )2 / ( N - 2 )2( N - 4 ) |
と求められます。但し、平均の場合と同様にガンマ関数が正値に対してのみ値を持つことから N > 4 という制限が必要になります。また、λ = 1 とすれば二番目の逆カイ二乗分布に対する分散、さらに分子の N を 1 とすれば一番目の逆カイ二乗分布に対する分散に等しくなるので、
V[x] = 2 / ( N - 2 )2( N - 4 ) [一番目の逆カイ二乗分布]
V[x] = 2N2 / ( N - 2 )2( N - 4 ) [二番目の逆カイ二乗分布]
という結果になります。
以上まとめると、次のようになります。
■ 逆カイ二乗分布
■ 尺度付き逆カイ二乗分布 T-1N,λ(x) =[ ( Nλ / 2 )N/2 / Γ( N / 2 ) ]x-N/2-1exp( - Nλ / 2x )
平均 : Nλ / ( N - 2 ) ( 但し N > 2 )、分散 : 2( Nλ )2 / ( N - 2 )2( N - 4 ) ( 但し N > 4 )
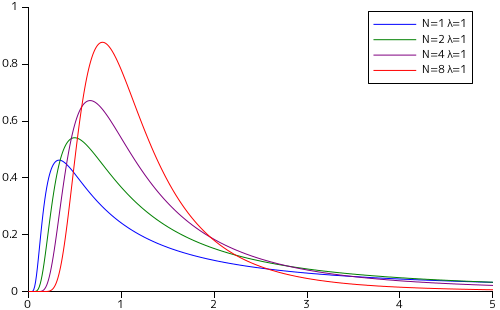
下図は、尺度付き逆カイ二乗分布のグラフを、自由度と尺度母数を変化させながら描画させた結果です。
| 自由度に対する分布形状の変化 | 尺度母数に対する分布形状の変化 |
|---|---|
 |
 |
「指数分布」は次のような確率密度関数で表される分布でした。
確率密度 t が時間を表すとすれば、モノが故障する頻度を定数 λ として、ある期間内に故障しない確率の分布として利用することができます。例えば、10 年間に平均一回故障する装置が t 年で故障しない確率は、λ = 0.1 として
と表されます。一年のうちに故障する確率は
であり、10% 未満ということになります。では、故障する確率が 50% を超えるときの年数 x はいくつになるかというと、
∫{0→x} P0.1(t) dt = [ -e-0.1t ]{0→x} = -e-0.1x - ( -1 ) ≥ 0.5 より
x ≥ -10ln( 0.5 ) = 6.93
なので、7 年を超えると故障する確率は五分五分ということになります。それでは複数の装置があった場合、処理できる総時間の中央値は 7 年の倍数となるのでしょうか。
例えば、二台の装置がそれぞれ平均して年に λ 回故障するとします。一台は予備機としてストックしておいて、もう一台が故障したら切り替えるものとします。ストック時の経年劣化はないものとして、全部の装置が故障してしまうまでの年数がどの程度になるかを求めたい場合、各装置が独立に指数分布 Pλ(t) に従うとすれば、両者の確率変数の和に対する分布を考えればいいので、その分布を Pλ2(t) として「畳み込み積分(Convolution)」から(*N3-1)
で計算できます。ここで、Pλ( t - u ) と Pλ(u) が値を持つ範囲はそれぞれ t - u ≥ 0, u ≥ 0 であることを考慮すれば、u の範囲は 0 ≤ u ≤ t となるので、
| Pλ2(t) | = | ∫{0→t} Pλ( t - u )Pλ(u) du |
| = | ∫{0→t} λe-λ(t-u)・λe-λu du | |
| = | λ2e-λt∫{0→t} du | |
| = | λ2e-λt[ u ]{0→t} | |
| = | λ2te-λt |
になります。台数を三つに増やし、故障したらやはり一台ずつ予備機に切り替えるものとして、その分布を Pλ3(t) とすれば、
| Pλ3(t) | = | ∫{-∞→∞} Pλ( t - u )Pλ2(u) du |
| = | ∫{0→t} λe-λ(t-u)・λ2ue-λu du | |
| = | λ3e-λt∫{0→t} u du | |
| = | λ3e-λt[ u2 / 2 ]{0→t} | |
| = | ( λ3 / 2 )t2e-λt |
という結果になるので、台数が N 台の場合は
と予想ができます。実際、この式を使って台数が N + 1 台の場合を計算すると
| PλN+1(t) | = | ∫{-∞→∞} Pλ( t - u )PλN(u) du |
| = | ∫{0→t} λe-λ(t-u)・[ λN / ( N - 1 )! ]uN-1e-λu du | |
| = | [ λN+1 / ( N - 1 )! ]e-λt∫{0→t} uN-1 du | |
| = | [ λN+1 / ( N - 1 )! ]e-λt[ uN / N ]{0→t} | |
| = | ( λN+1 / N! )tNe-λt |
となって、予想が正しいことが証明できます。λ = 0.1, N = 2 のとき、
なので、10 年に平均 1 回故障する装置が二台あった時、全ての装置が故障するまでの確率をこの式が表しているとすれば、その確率が 50% になるときの時間 x は
になる時で、左辺は
| ∫{0→x} P0.12(t) dt | = | 0.01∫{0→x} te-0.1t dt |
| = | 0.01{ -10[ te-0.1t ]{0→x} + 10∫{0→x} e-0.1t dt } | |
| = | 0.1{ -xe-0.1x - 10[ e-0.1t ]{0→x} } | |
| = | 0.1[ -xe-0.1x - 10( e-0.1x - 1 ) ] | |
| = | 1 - ( 0.1x + 1 )e-0.1x |
と計算できるので
を満たす x を求めればよいことになります。これを求めるのは少々面倒ですが、適当に値を代入してみれば約 16.8 年という結果が得られます。16.8 年で二台とも故障する確率は五分五分で、この年数を超えると使える装置がなくなってしまう確率の方が高くなるということになります。一台の場合は中央値が約 7 年だったことを考慮すると、予備機がある方が寿命は長くなると考えることができます。
N を実数 α にまで拡張すると、( α - 1 )! → Γ(α) より
となります。この確率密度関数を「ガンマ分布(Gamma Distribution)」といいます。λ は事象が単位時間(または距離など)あたりに発生する頻度を表し、α はその事象が発生した回数を表していると考えることができます。λ の逆数は事象が一度発生するまでの時間や距離を表していると考えれば、それを β として
と変形することもできます。一般的には下側の式のほうがよく使われるようです。
ガンマ分布の「積率母関数 (Moment Generating Function)」 g(θ) = E[eθt] は
| g(θ) | = | ∫{0→∞} eθtPβα(t) dt |
| = | [ 1 / βαΓ( α ) ]∫{0→∞} eθt・tα-1e-t/β dt | |
| = | [ 1 / ( 1 / β - θ )α-1βαΓ( α ) ]∫{0→∞} [ ( 1 / β - θ )t ]α-1e-(1/β-θ)t dt |
u = ( 1 / β - θ )t とすると du = ( 1 / β - θ )dt となって、
| g(θ) | = | [ 1 / ( 1 / β - θ )αβαΓ( α ) ]∫{0→∞} uα-1e-u du |
| = | [ 1 / ( 1 - βθ )αΓ( α ) ]Γ( α ) | |
| = | ( 1 - βθ )-α |
と求められるので、平均 E[t] は
より
になります。また、分散 V[t] は
より
になります。Pλα(t) に対しては、β = 1 / λ として置換するだけで得ることができます。以上まとめると、次のようになります。
ガンマ分布
ガンマ分布から、他の様々な確率密度関数を求めることができます。最も簡単な例として、α = 1 としたときに指数分布と等しくなることは、今までの導出過程から明らかです。また、α = N / 2 ( N は正の整数 )、β = 2 ( または λ = 1 / 2 )とすれば、
すなわち自由度 N のカイ二乗分布と等しくなります。その他に、α を正の整数に限定した分布は「アーラン分布(Erlang Distribution)」と呼ばれます。今までの説明から、指数分布に従う確率変数の和はアーラン分布に従うということになり、ガンマ分布はそれをさらに一般化したものであると考えることができます。
なお、カイ二乗分布の確率変数を逆数に変数変換することで逆カイ二乗分布が得られたように、ガンマ分布も同様の変換によって「逆ガンマ分布(Inverse-gamma Distribution)」を求めることができます。その式は
であり、平均 E[t] は
| E[t] | = | [ λα / Γ( α ) ]∫{0→∞}t・t-α-1e-λ/t dt |
| = | [ 1 / Γ( α ) ]∫{0→∞} ( λ / t )αe-λ/t dt | |
| = | [ 1 / Γ( α ) ]∫{∞→0} uαe-u ( -λu-2 )du | |
| = | [ λ / Γ( α ) ]∫{0→∞} uα-2e-u du | |
| = | λΓ( α - 1 ) / Γ( α ) | |
| = | λ / ( α - 1 ) |
E[t2] は
| E[t2] | = | [ λα / Γ( α ) ]∫{0→∞}t2・t-α-1e-λ/t dt |
| = | [ λ / Γ( α ) ]∫{0→∞} ( λ / t )α-1e-λ/t dt | |
| = | [ λ / Γ( α ) ]∫{∞→0} uα-1e-u ( -λu-2 )du | |
| = | [ λ2 / Γ( α ) ]∫{0→∞} uα-3e-u du | |
| = | λ2Γ( α - 2 ) / Γ( α ) | |
| = | λ2 / ( α - 1 )( α - 2 ) |
なので分散 V[t] は
| V[t] | = | E[t2] - E[t]2 |
| = | λ2 / ( α - 1 )( α - 2 ) - λ2 / ( α - 1 )2 | |
| = | [ λ2 / ( α - 1 ) ][ 1 / ( α - 2 ) - 1 / ( α - 1 ) ] | |
| = | λ2 / ( α - 1 )2( α - 2 ) |
となります。但し、途中で u = λt-1 として置換積分を利用しています。
下図は、ガンマ分布 [ 1 / βαΓ( α ) ]tα-1e-t/β のグラフを、α と β を変化させながら描画させた結果です。
| β に対する分布形状の変化 | α に対する分布形状の変化 |
|---|---|
 |
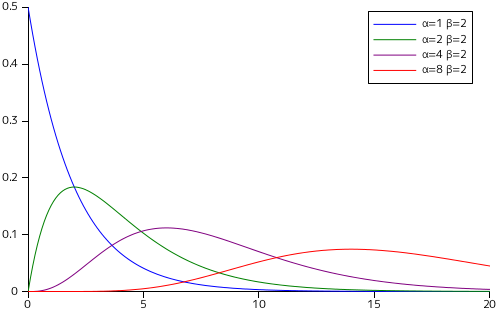 |
t が、事象が一度発生するまでの時間や距離を β としたときに事象が α 回発生するまでの時間や距離を表す確率変数であると考えれば、両パラメータとも大きくなるに従って分布は大きく広がってゆき、推定することが困難になることがこのグラフからわかります。これは、故障率が低ければいつ壊れるかは予想しづらくなり、その回数が増えるほどますますばらつきは大きくなることを表現していると考えることができます。
*N3-1) 「確率・統計 (4) 多変数の確率分布」の「3) 確率変数の変換」を参照
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |