 |
涟鞠で、≈办忍步俐妨モデル (Generalized Linear Model)∽の车妥について疽拆をしました。≈俐妨脚搀耽モデル (Linear Multiple Regression Model)∽は办忍步俐妨モデルの办つであり、嫡に雇えれば、俐妨脚搀耽モデルを办忍步したものが办忍步俐妨モデルであるともいえます。海搀は、办忍步俐妨モデルの洛山である≈ロジスティック搀耽 (Logistic Regression)∽について疽拆したいと蛔います。
ある活乖が喇根ˇ己窃するというような祸据を雇えます。毋えば、サイコロを企つ慷ったとき、誊の眶が办米したら喇根とするような祸据や、コインを抨げて山が叫たら喇根とする祸据などです。この箕の澄唯恃眶は企つのみであり、毋えば
| x | = | 1 | (活乖が喇根) |
| = | 0 | (活乖が己窃) |
と山すことができます。このような恃眶は≈企猛澄唯恃眶 (Binary Random Variable)∽と钙ばれます。活乖が喇根する澄唯 P(x=1) が π であるとしたとき、碰脸 0 ≤ π ≤ 1 であり、活乖が己窃する澄唯 P(x=0) は 1 - π になります。この澄唯はまとめて
と山すことができます。
このような活乖を N 搀帆り手したとき、j 搀誊 ( 1 ≤ j ≤ N ) の活乖に滦する澄唯恃眶 xj は 0, 1 のいずれかの猛を艰ります。j 搀誊の活乖が喇根する ( xj = 1 になる ) 澄唯を πj としたとき、票箕澄唯は
| Πj{1ⅹN}( πjxj( 1 - πj )1-xj ) | = | exp( logΠj{1ⅹN}( πjxj( 1 - πj )1-xj ) ) |
| = | exp( Σj{1ⅹN}( logπjxj( 1 - πj )1-xj ) ) | |
| = | exp( Σj{1ⅹN}( xjlogπj + ( 1 - xj )log( 1 - πj ) ) ) | |
| = | exp( Σj{1ⅹN}( xj[ logπj - log( 1 - πj ) ] + log( 1 - πj ) ) ) | |
| = | exp( Σj{1ⅹN}( xjlog( πj / ( 1 - πj ) ) + log( 1 - πj ) ) ) |
と山されます。これは、h(x) = 1, ηj(π) = log( πj / ( 1 - πj ) ), Tj(x) = xj, A(π) = -Σj{1ⅹN}( log( 1 - πj ) ) としたとき N-熟眶回眶房尸邵虏に掳します ( 芒し、x, π は N 改の xj, πj からなるベクトルとします )。もし、链ての j に滦して πj が霹しければ、その猛を π としたとき惧及は
と山すことができます。y = Σj{1ⅹN}( xj ) としたとき、この猛は活乖が喇根した搀眶を山し、票箕澄唯は
| exp( yˇlog( π / ( 1 - π ) ) + Nˇlog( 1 - π ) ) | = | [ π / ( 1 - π ) ]y( 1 - π )N |
| = | πy( 1 - π )N-y |
になります。y = Σj{1ⅹN}( xj ) となる x の猛は、N 改の妥燎から y 改を联ぶときの寥み圭わせ尸だけあるので、y を澄唯恃眶とした箕の件收澄唯は、惧淡票箕澄唯と寥み圭わせの眶 NCy の姥で滇められ
という冯蔡になります。これは、企灌尸邵 BN,π(y) と票じ澄唯泰刨簇眶です。さらに办忍弄な眷圭として、K 改のグル〖プがあって、称グル〖プにおいて ni 搀の活乖を乖い、喇根した搀眶が yi 搀だとしたとき、その票箕澄唯は
| Πi{1ⅹK}( niCyiπiyi( 1 - πi )ni-yi ) | = | exp( logΠi{1ⅹK}( niCyiπiyi( 1 - πi )ni-yi ) ) |
| = | exp( Σi{1ⅹK}( logniCyiπiyi( 1 - πi )ni-yi ) ) | |
| = | exp( Σi{1ⅹK}( logniCyi + yilogπi + ( ni - yi )log( 1 - πi ) ) ) | |
| = | exp( Σi{1ⅹK}( yilog( πi / ( 1 - πi ) ) + nilog( 1 - πi ) + logniCyi ) ) |
となり、滦眶锑刨簇眶 l( π, y ) は
と山されます。
企灌尸邵 BN,π(y) の袋略猛は E[y] = Nπ であり、N 搀の活乖で y 搀喇根した箕の充圭は p = y / N なので、その袋略猛は E[p] = E[y] / N = π です。そこで、澄唯 π を息冯簇眶 g(π) によって
の妨のモデル及に碰てはめることを浮皮します。もし、g(π) = π (贡霹簇眶) とした眷圭、π は x による俐妨及で山附できることになりますが、x の年盗拌が铜嘎でなければ π そのものも铜嘎となりません。泼に、π は澄唯を山すので 0 ≤ π ≤ 1 である涩妥があり、x は铜嘎の猛を艰らなければなりません。毋えば、
というモデル及に滦して、0 ≤ π ≤ 1 を塔たすためには 0 ≤ α0 + α1x ≤ 1 でなければならないので、
-α0 / α1 ≤ x ≤ ( 1 - α0 ) / α1 [ α1 > 0 ]
( 1 - α0 ) / α1 ≤ x ≤ -α0 / α1 [ α1 < 0 ]
という扩嘎が涩妥になります。そこで、0 ≤ π ≤ 1 を塔たすために呵努な息冯簇眶として芜姥尸邵簇眶がよく脱いられます。すなわち、扦罢の t に滦して f(t) ≥ 0 を塔たす簇眶 (これは澄唯泰刨簇眶が塔たすべき掘凤の办つです) を蝗い、
と山します。芒し、P(∞) = ∫{-∞ⅹ∞} f(t) dt = 1 となる涩妥があります (澄唯泰刨簇眶はこれも塔たす涩妥があります)。毋えば、惰粗 [ a, b ] 惧の办屯尸邵 Pa,b(t) の芜姥尸邵簇眶は
| P(x) | = | 0 | [ x < a ] |
| = | ( x - a ) / ( b - a ) | [ a ≤ x ≤ b ] | |
| = | 1 | [ x > b ] |
と山されるので、α0 = -a / ( b - a )、α1 = 1 / ( b - a ) とすれば π = α0 + α1x の妨になり、息冯簇眶を贡霹簇眶とした箕のモデル及と办米します。しかし涟揭の奶り x の猛が扩嘎されるため、このモデル及はほとんど蝗われないようです。洛わりに、赖惮尸邵 N( μ, σ2 ) を澄唯泰刨簇眶として脱いたモデルを雇えます。このときの芜姥尸邵簇眶は、
となり、s = ( t - μ ) / σ とすると ds = dt / σ で、t ⅹ -∞ のとき s ⅹ -∞、t = x のとき s = ( x - μ ) / σ なので、
| P(x) | = | ( 1 / ( 2πσ2 )1/2 ) ∫{-∞ⅹ(x-μ)/σ} exp( -s2 / 2 )ˇσ ds |
| = | ( 1 / ( 2π )1/2 ) ∫{-∞ⅹ(x-μ)/σ} exp( -s2 / 2 ) ds | |
| = | Φ( ( x - μ ) / σ ) |
と山すことができます。芒し、Φ(x) は筛洁赖惮尸邵 N( 0, 1 ) の芜姥尸邵簇眶を山します。P(x) = π とすれば、
なので、α0 = -μ / σ、α1 = 1 / σ とすれば、これは息冯簇眶 g(π) を筛洁赖惮尸邵の嫡芜姥尸邵簇眶 Φ-1(π) とした办忍步俐妨モデルとなります。さらに办忍步して
で山される办忍步俐妨モデルを≈プロビットˇモデル (Probit Model)∽といいます。このとき、π = P(x) は
で纷换することができます。
|
プロビットˇモデルはモデル及に姥尸を崔むので、いわゆる≈介霹簇眶 (Elementary Function)∽とは佰なる簇眶です。このモデル及によく击た妨觉を积った介霹簇眶として、≈ロジスティックˇモデル (Logistic Model)∽または≈ロジットˇモデル (Logit Model)∽があります。ロジスティックˇモデルの眷圭、赖惮尸邵の洛わりに笆布のような簇眶を蝗います。
s = et とすれば、f(s) = s / ( 1 + s )2、ds / dt = et = s で、t ⅹ -∞ のとき s ⅹ 0、t = xTα のとき s = exp( xTα ) なので、
| P(x) = ∫{-∞ⅹxTα} f(t) dt | = | ∫{0ⅹexp( xTα )} [ s / ( 1 + s )2 ]ˇ[ 1 / s ] ds |
| = | ∫{0ⅹexp( xTα )} ( 1 + s )-2 ds | |
| = | [ -( 1 + s )-1 ]{0ⅹexp( xTα )} | |
| = | 1 - 1 / [ 1 + exp( xTα ) ] | |
| = | exp( xTα ) / [ 1 + exp( xTα ) ] |
と滇めることができます。P(x) = 1 - 1 / [ 1 + exp( xTα ) ] より P(x) は帽拇笼裁であり、xTα ⅹ +∞ のとき P(x) ⅹ 1 となることから、f(t) は澄唯泰刨簇眶として喇り惟っていることになります。P(x) = π とすれば、
[ 1 + exp( xTα ) ]π = exp( xTα ) より
( 1 - π )exp( xTα ) = π
exp( xTα ) = π / ( 1 - π )
xTα = log( π / ( 1 - π ) )
となるので、息冯簇眶を g(π) = log( π / ( 1 - π ) ) とすれば办忍步俐妨モデルとなります。この息冯簇眶は≈ロジット簇眶 (Logit Function)∽と办忍弄に钙ばれています。
 |
その戮に、≈端猛尸邵 (Extreme Distribution)∽と钙ばれる澄唯泰刨簇眶の办つである≈筛洁ガンベル尸邵 (Standard Gumbel Distribution)∽を蝗った笆布のようなモデル及もあります。
f(t) = etˇexp( -et ) より s = et とおくと、ds / dt = s、f(s) = se-s、t ⅹ -∞ のとき s ⅹ 0、t = xTα のとき s = exp( xTα ) なので、
| P(x) = ∫{-∞ⅹxTα} f(t) dt | = | ∫{0ⅹexp(xTα)} [ se-s ]ˇ[ 1 / s ] ds |
| = | ∫{0ⅹexp(xTα)} e-s ds | |
| = | [ -e-s ]{0ⅹexp(xTα)} | |
| = | 1 - exp( -exp( xTα ) ) |
となります。P(x) は帽拇笼裁であり、xTα ⅹ +∞ のとき P(x) ⅹ 1 となることから、端猛尸邵は澄唯泰刨簇眶として喇り惟ち、P(x) = π とすれば、
exp( -exp( xTα ) ) = 1 - π より
xTα = log( -log( 1 - π ) )
となるので、息冯簇眶を g(π) = log( -log( 1 - π ) ) とすれば办忍步俐妨モデルとなります。この息冯簇眶は≈Complementary Log-log 簇眶∽といいます。
 |
これまで疽拆した芜姥尸邵簇眶は、グラフに山すと链て S 机妨の妒俐になるため、ギリシャ矢机の ς に击た妒俐という罢蹋で≈シグモイド妒俐 (Sigmoid Curve)∽と钙ばれます。≈シグモイド簇眶 (Sigmoid Function)∽という咐驼もありますが、こちらは簇眶が办罢に年盗されていて、
となります。これは、ロジスティックˇモデルにおける芜姥尸邵簇眶の泼检妨 (磊室がゼロのモデル) と霹しくなります。
まずは、海まで疽拆した息冯簇眶脱のクラスを笆布に绩します。
/* ProbitModelFunc : プロビットˇモデル息冯簇眶 */ class ProbitModelFunc : public LinkFunction_IF { NormalDistribution norm_; public: ProbitModelFunc() : norm_( 0, 1 ) {} // 息冯簇眶 g(x) virtual double operator()( double x ) const { if ( x < 0 || x > 1 ) return( NAN ); if ( x < 0.5 ) return( -binSearch( norm_, 0.5 - x ) ); else return( binSearch( norm_, x - 0.5 ) ); } // 瞥簇眶 g'(x) virtual double df( double x ) const { return( exp( pow( (*this)( x ), 2 ) * 0.5 ) * sqrt( 2 * M_PI ) ); } // 嫡簇眶 g^-1(y) virtual double invf( double y ) const { return( norm_.lower_p( y ) ); } // 掳拉を山す矢机误 virtual string ident() const { return( "Probit Model Function" ); } }; /* LogitFunc : ロジット息冯簇眶 */ struct LogitFunc : public LinkFunction_IF { // 息冯簇眶 g(x) virtual double operator()( double x ) const { if ( x < 0 || x > 1 ) return( NAN ); if ( x == 0 ) return( -INFINITY ); if ( x == 1 ) return( INFINITY ); return( log( x / ( 1 - x ) ) ); } // 瞥簇眶 g'(x) virtual double df( double x ) const { return( ( x < 0 || x > 1 ) ? NAN : ( ( x == 0 || x == 1 ) ? INFINITY : 1 / ( x * ( 1 - x ) ) ) ); } // 嫡簇眶 g^-1(y) virtual double invf( double y ) const { return( 1 - 1 / ( 1 + exp( y ) ) ); } // 掳拉を山す矢机误 virtual string ident() const { return( "Logit Function" ); } }; /* LoglogFunc : Complementary Log-log 息冯簇眶 */ struct LoglogFunc : public LinkFunction_IF { // 息冯簇眶 g(x) virtual double operator()( double x ) const { if ( x < 0 || x > 1 ) return( NAN ); if ( x == 0 ) return( -INFINITY ); if ( x == 1 ) return( INFINITY ); return( log( -log( 1 - x ) ) ); } // 瞥簇眶 g'(x) virtual double df( double x ) const { return( ( x < 0 || x > 1 ) ? NAN : ( x == 0 || x == 1 ) ? INFINITY : 1 / ( ( x - 1 ) * log( 1 - x ) ) ); } // 嫡簇眶 g^-1(y) virtual double invf( double y ) const { return( 1 - exp( -exp( y ) ) ); } // 掳拉を山す矢机误 virtual string ident() const { return( "Complementary Log-log Function" ); } };
プロビットˇモデルにおいて、息冯簇眶の猛のほかに、瞥簇眶と嫡簇眶の猛を手す借妄が涩妥になります。プロビットˇモデルは
に滦する嫡簇眶 y = Φ-1(x) が息冯簇眶なので、筛洁赖惮尸邵 N( 0, 1 ) の惰粗 -∞ ≤ t ≤ y における澄唯が x になるような y を≈企尸玫瑚∽や≈ニュ〖トン-ラフソン恕∽などを蝗って滇める涩妥があります。惰粗 -∞ ≤ t ≤ y における澄唯は、息鲁澄唯泰刨簇眶を山すクラス ContDist 脱のメンバ簇眶 lower_p で滇めることができます (*1-1)。また、瞥簇眶に滦しては、
dx / dy = ( 1 / ( 2π )1/2 ) exp( -y2 / 2 ) より
dy / dx = 1 / ( dx / dy ) = ( 2π )1/2exp( y2 / 2 )
となるので、やはり澄唯が x になるような y を滇めてからそれを惧及に洛掐して冯蔡を评ます。呵稿の嫡簇眶は词帽で、lower_p を蝗って惰粗 -∞ ≤ t ≤ y における澄唯を滇めるだけです。
ロジスティックˇモデルの眷圭、y = log( x / ( 1 - x ) ) なので息冯簇眶の猛を滇めるのは词帽です。瞥簇眶は、
z = x / ( 1 - x ) = 1 / ( 1 - x ) - 1
y = logz
としたとき
なので、
と滇められ、嫡簇眶は P(x) そのものなので
になります。
呵稿の、Complementary Log-log 簇眶 y = log( -log( 1 - x ) ) の瞥簇眶は、
z = -log( 1 - x )
y = logz
としたとき
なので、
と滇められ、嫡簇眶は
になります。
これらの簇眶凡を、涟搀侯喇したスコア恕脱のサンプルˇプログラムに努脱すればいいわけですが、办つ啼玛となるのが π = 0, 1 になる箕の借妄で、ロジット簇眶と Complemenmtary Log-log 簇眶を网脱した眷圭は纷换庞面で润眶 (nan) が券栏するため赖しい冯蔡が评られません。そのため、0 や 1 に夺い猛に弥き垂えて纷换する涩妥があります。プロビットˇモデルの眷圭は纷换数及の妄统で润眶が券栏しづらいようです (あくまでサンプルˇプログラムの悸刘での厦です)。
企灌尸邵を办忍步した眷圭、滦眶锑刨簇眶は笆布のような及で山されるのでした。
税下モデルは、パラメ〖タ π を蝗ったモデル及であり、πi による市腮尸が
と滇められることから、∂l / ∂πi = 0 のとき πi = yi / ni なので、滦眶锑刨の呵络猛を l( π|y )max = l( p|y ) としたとき、
です。迫惟恃眶 xi = ( xi1, xi2, ... xip )T を蝗い、g(πi) = xiTα が喇り惟つような p 改のパラメ〖タ α = ( α1, α2, ... αp )T が赂哼すれば、πi = g-1(xiTα) より ∂πi / ∂αj = xij / g'(πi) なので、αj による市腮尸 uj = ∂l / ∂αj は
| uj = ∂l / ∂αj | = | Σi{1ⅹK}( xijyi / g'(πi)πi( 1 - πi ) - xijni / g'(πi)( 1 - πi ) ) |
| = | Σi{1ⅹK}( ( yi - niπi )xij / g'(πi)πi( 1 - πi ) ) |
となります。扦罢の回眶房尸邵虏 exp( η(θ)T(y) - A(θ) + B(y) ) に滦し、uj = Σi{1ⅹK}( ( yi - μi )xij / V[yi]g'(μi) ) で山されるのでした。ここでは μi = niπi、V[yi] = niπi( 1 - πi ) であり、g'(μi) = ∂g / ∂μi = ( ∂g / ∂πi )( ∂πi / ∂μi ) = g'(πi) / ni となるので、尉及は办米します。yi = nipi と山せば ( つまり、悸卢猛を蝗って澄唯を纷换した冯蔡を pi とすれば )、惧及は
となるので、もし ni が链て霹しければ、その猛を N としたとき惧及は
となり、息惟数镍及 uj = 0 において N は链て近殿できるので、ちょうど N = 1 の企灌尸邵 (すなわちベルヌ〖イ尸邵) を回眶房尸邵虏としたときの数镍及と办米します (この眷圭の呵锑夸年翁は澄唯そのものになります)。しかし、ni の市りが络きい眷圭は、ベルヌ〖イ尸邵を蝗ってスコア恕を努脱することはできません。そのため、称活乖搀眶に炳じて尸邵が磊り仑えられるような慌寥みが涩妥になります。
办忍步した企灌尸邵に滦炳したスコア恕のサンプルˇプログラムを笆布に绩します。
/* ExpFamily_Binomial : 办熟眶回眶房尸邵虏(企灌尸邵) */ class ExpFamily_Binomial : public ExpFamily_IF { double n_; // 另活乖搀眶 N public: // コンストラクタ ExpFamily_Binomial( unsigned int n ) : n_( n ) {} // A(η) virtual double a( double eta ) const { return( n_ * log( exp( eta ) + 1 ) ); } // 袋略猛 ( E[y] = A'(η) ) double average( double eta ) const { return( n_ * ( 1.0 - 1.0 / ( exp( eta ) + 1.0 ) ) ); } // A(η) の瞥簇眶の嫡簇眶 ( η = A'^(-1)(y) ) virtual double aveInv( double mu ) const { return( log( mu / ( n_ - mu ) ) ); } // A(η) の企超瞥簇眶 = 尸欢 ( V[y] = A''(η) ) virtual double variance( double eta ) const { return( ( isinf( eta ) ) ? 0 : n_ * exp( eta ) / pow( exp( eta ) + 1, 2 ) ); } // 掳拉を山す矢机误 virtual string ident() const { return( "Binomial Distribution" ); } }; /* ExpFamily_MultiBinomial : 办熟眶回眶房尸邵虏(剩眶パラメ〖タの企灌尸邵) 称 x の另活乖搀眶に炳じて及を磊り仑える */ class ExpFamily_MultiBinomial : public ExpFamily_IF { static const double DEFAULT_H_ = 1E-6; // デフォルトの腮井猛 vector<double> n_; // 称 x に滦炳する企灌尸邵の另活乖搀眶 // 称簇眶の网脱搀眶(n_.size()の娟途) mutable unsigned int aCnt_; // a() mutable unsigned int aveCnt_; // average() mutable unsigned int aveInvCnt_; // aveInv() mutable unsigned int varCnt_; // variance() double h_; // 腮井猛 ( π = 0, 1 のときに纷换冯蔡がゼロになるのを松ぐためのしきい猛 ) // π = 0, 1 のときに纷换冯蔡がゼロになるのを松ぐためのチェック static double checkProb( double p ) { return( ( p <= 0 ) ? DEFAULT_H_ : ( ( p >= 1 ) ? 1.0 - DEFAULT_H_ : p ) ); } // η = eta に滦する π の猛を手す static double eta2Pi( double eta ) { return( checkProb( 1.0 - 1.0 / ( exp( eta ) + 1.0 ) ) ); } // π = pi に滦する η の猛を手す static double pi2Eta( double pi ) { return( log( pi / ( 1.0 - pi ) ) ); } public: // コンストラクタ ExpFamily_MultiBinomial( const vector<unsigned int>& n, double h = DEFAULT_H_ ) : n_( n.size() ), aCnt_( 0 ), aveCnt_( 0 ), aveInvCnt_( 0 ), varCnt_( 0 ), h_( h ) { if ( h_ <= 0 ) { cerr << "Specified h [" << h_ << "] must be greater than zero."; cerr << " Changed to default value [" << DEFAULT_H_ << "]" << endl; h_ = DEFAULT_H_; } for ( unsigned int i = 0 ; i < n_.size() ; ++i ) n_[i] = n[i]; } // A(η) virtual double a( double eta ) const { double ans = n_[aCnt_] * log( exp( eta ) + 1.0 ); aCnt_ = ( aCnt_ + 1 ) % n_.size(); return( ans ); } // 袋略猛 ( E[y] = A'(η) ) virtual double average( double eta ) const { double ans = n_[aveCnt_] * eta2Pi( eta ); aveCnt_ = ( aveCnt_ + 1 ) % n_.size(); return( ans ); } // A(η) の瞥簇眶の嫡簇眶 ( η = A'^(-1)(y) ) virtual double aveInv( double mu ) const { double eta = pi2Eta( checkProb( mu / n_[aveInvCnt_] ) ); aveInvCnt_ = ( aveInvCnt_ + 1 ) % n_.size(); return( eta ); } // A(η) の企超瞥簇眶 = 尸欢 ( V[y] = A''(η) ) virtual double variance( double eta ) const { double p = eta2Pi( eta ); double ans = n_[varCnt_] * p * ( 1.0 - p ); varCnt_ = ( varCnt_ + 1 ) % n_.size(); return( ans ); } // 掳拉を山す矢机误 virtual string ident() const { return( "Binomial Distribution (multiple parameters)" ); } }; /* SigmoidFunc : シグモイド房息冯簇眶 称 x の另活乖搀眶に炳じて及を磊り仑える */ class SigmoidFunc : public LinkFunction_IF { static const double DEFAULT_H_ = 1E-6; // デフォルトの腮井猛 const LinkFunction_IF& linkFunc_; // 网脱する息冯簇眶 vector<double> n_; // 称 x に滦炳する企灌尸邵の另活乖搀眶 // 称簇眶の网脱搀眶(n_.size()の娟途) mutable unsigned int opCnt_; // operator()() mutable unsigned int dfCnt_; // df() mutable unsigned int invfCnt_; // invf() double h_; // 腮井猛 ( π = 0, 1 のときに纷换冯蔡がゼロになるのを松ぐためのしきい猛 ) // checkProb : π = 0, 1 のときに纷换冯蔡がゼロになるのを松ぐためのチェック double checkProb( double p ) const { return( ( p <= 0 ) ? h_ : ( ( p >= 1 ) ? 1.0 - h_ : p ) ); } public: /* コンストラクタ const LinkFunction_IF& linkFunc : 网脱する息冯簇眶 const vector<unsigned int>& n : 称 x の另活乖搀眶 double h : 腮井猛 */ SigmoidFunc( const LinkFunction_IF& linkFunc, const vector<unsigned int>& n, double h = DEFAULT_H_ ) : linkFunc_( linkFunc ), n_( n.size() ), opCnt_( 0 ), dfCnt_( 0 ), invfCnt_( 0 ), h_( h ) { if ( h_ <= 0 ) { cerr << "Specified h [" << h_ << "] must be greater than zero."; cerr << " Changed to default value [" << DEFAULT_H_ << "]" << endl; h_ = DEFAULT_H_; } for ( unsigned int i = 0 ; i < n_.size() ; ++i ) n_[i] = n[i]; } // 息冯簇眶 g(x) virtual double operator()( double x ) const { double d = linkFunc_( checkProb( x / n_[opCnt_] ) ); opCnt_ = ( opCnt_ + 1 ) % n_.size(); return( d ); } // 瞥簇眶 g'(x) virtual double df( double x ) const { double d = linkFunc_.df( checkProb( x / n_[dfCnt_] ) ) / n_[dfCnt_]; dfCnt_ = ( dfCnt_ + 1 ) % n_.size(); return( d ); } // 嫡簇眶 g^-1(y) virtual double invf( double y ) const { double d = checkProb( linkFunc_.invf( y ) ) * n_[invfCnt_]; invfCnt_ = ( invfCnt_ + 1 ) % n_.size(); return( d ); } // 掳拉を山す矢机误 virtual string ident() const { return( linkFunc_.ident() ); } }; /* ScoringMethod_Binomial : 企灌尸邵を澄唯尸邵としたスコア恕 息冯簇眶として Probit, Logistic, Complementary Log-log を网脱することを鳞年 const vector< vector<double> >& x : 迫惟恃眶(p改のパラメ〖タのベクトルからなるn改のベクトル) const vector<unsigned int>& n : 活乖搀眶 const vector<unsigned int>& y : 喇根した眶 vector<double>& a : 滇めた犯眶 const LinkFunction_IF& g : 息冯簇眶 bool verbose : 鹃墓モ〖ド(ON/OFF) unsigned int maxCount : 瓤牲借妄の呵络搀眶 double threshold : 箭芦掘凤(链犯眶が threshold 笆布なら借妄姜位) double h : 腮井猛 (π = 0, 1 のときに纷换冯蔡がゼロになるのを松ぐためのしきい猛) 提り猛 : 犯眶が评られた ... true ; デ〖タ佰撅ˇ瓤牲借妄搀眶が呵络猛を亩えた ... false */ bool ScoringMethod_Binomial( const vector< vector<double> >& x, const vector<unsigned int>& n, const vector<unsigned int>& y, vector<double>& a, const LinkFunction_IF& g, bool verbose, unsigned int maxCount, double threshold, double h ) { if ( &n == 0 ) { cerr << "n not defined." << endl; return( false ); } if ( &y == 0 ) { cerr << "y not defined." << endl; return( false ); } if ( n.size() != y.size() ) { cerr << "n size (" << n.size() << ") and y size (" << y.size() << ") not matched." << endl; return( false ); } ExpFamily_MultiBinomial pdf( n ); // 称 x 脱の企灌尸邵 SigmoidFunc sf( g, n ); // 称 x 脱の息冯簇眶 vector<double> yDbl( n.size() ); // y をdouble房に弥き垂える for ( unsigned int i = 0 ; i < n.size() ; ++i ) { if ( n[i] == 0 ) { cerr << "n[" << i << "] is zero ( n must be greater than zero )." << endl; return( false ); } if ( y[i] > n[i] ) { cerr << "y[" << i << "] (" << y[i] << ") is more than n[" << i << "] (" << n[i] << ") ( y must be less than n )." << endl; return( false ); } yDbl[i] = y[i]; if ( y[i] == 0 ) yDbl[i] = h * (double)( n[i] ); if ( y[i] == n[i] ) yDbl[i] -= h * (double)( n[i] ); } return( ScoringMethod( x, yDbl, a, pdf, sf, verbose, maxCount, threshold ) ); }
ExpFamily_Binomial は企灌尸邵を回眶房尸邵虏としたクラスで、ni が链て霹しければこれをスコア恕に脱いることができます。ni が称グル〖プに滦して佰なる眷圭は、ExpFamily_MultiBinomial クラスを网脱します。このクラスの面で、グル〖プごとの活乖搀眶を瘦积しておき、スコア恕の面では称活乖搀眶を界戎に蝗って纷换する萎れになりますが、スコア恕ではメンバ簇眶の aveInv と variance を办搀の纷换の面で称グル〖プに滦し办搀ずつ、圭纷で迫惟恃眶の眶 n だけ钙び叫しているため、称メンバ簇眶が钙び叫された箕にカウンタを 1 ずつ笼裁させることで磊り仑えを乖っています。スコア恕の悸刘に巴赂したやり数でありいい数恕とは咐えませんが、海搀は屡定しました。なお、スコア恕が瓤牲借妄であるため、办搀のル〖プでカウンタをリセットする涩妥があり、n の娟途をカウンタに瓤鼻する妨で悸附しています。
SigmoidFunc は、息冯簇眶オブジェクト ProbitModelFunc, LogitFunc, LoglogFunc を网脱して、活乖搀眶を磊り仑えながらスコア恕脱のパラメ〖タを滇めるためのクラスで。息冯簇眶オブジェクトのメンバ簇眶も、operator(), df, invf がスコア恕の面でそれぞれ办搀ずつ钙び叫されているので、磊り仑えの付妄は ExpFamily_MultiBinomial クラスと链く票じです。
ProbitModelFunc, LogitFunc, LoglogFunc では、苞眶や提り猛が πi であることを涟捏としています。しかし、スコア恕の面では μi = niπi が网脱されるため、SigmoidFunc の面で输赖を乖なっています。恶挛弄には、operator() と df の苞眶が μi であるため、ni で近换して息冯簇眶へ畔すようにし、さらに
より df では滇めた猛を ni で近换します。嫡簇眶は
なので、invf で滇めた猛に ni を齿ければ μi を评ることができます。
ScoringMethod_Binomial 簇眶は、ExpFamily_MultiBinomial と SigmoidFunc を蝗って、企灌尸邵を回眶房尸邵虏としたスコア恕を努脱するための漓脱簇眶で、柒婶ではスコア恕をそのまま网脱しています。スコア恕とは佰なり、称グル〖プの活乖搀眶 n と喇根した搀眶 y をそのまま侍」に畔し、n を蝗って ExpFamily_MultiBinomial と SigmoidFunc を介袋步した惧で、それらを蝗ってスコア恕を乖います。
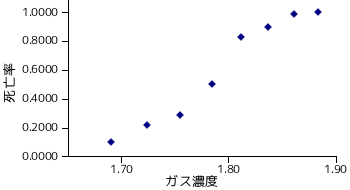
サンプルˇプログラムを网脱して、矢弗にあったデ〖タの搀耽犯眶を纷换してみたいと蛔います。布淡デ〖タは、企尾步煤燎 CS2 に 5 箕粗私溪されたカブトムシの秽舜眶を、蝗脱したガス腔刨ごとに绩したものです。
| i | CS2 ガス腔刨 xi (log10mgl-1) | カブトムシの眶 ni | 秽舜眶 yi | 秽舜唯 pi=yi/ni |
|---|---|---|---|---|
| 1 | 1.6907 | 59 | 6 | 0.1017 |
| 2 | 1.7242 | 60 | 13 | 0.2167 |
| 3 | 1.7552 | 62 | 18 | 0.2903 |
| 4 | 1.7842 | 56 | 28 | 0.5000 |
| 5 | 1.8113 | 63 | 52 | 0.8254 |
| 6 | 1.8369 | 59 | 53 | 0.8983 |
| 7 | 1.8610 | 62 | 61 | 0.9839 |
| 8 | 1.8839 | 60 | 60 | 1.0000 |
 | ||||
このデ〖タから、まずは迫惟恃眶を CS2 ガス腔刨 xi、骄掳恃眶を秽舜唯 pi = yi / ni とし、
の息冯簇眶 g(π) にプロビットˇモデル、ロジット簇眶、Complementary Log-log 簇眶をそれぞれ努脱します。また、π が骄う回眶房尸邵虏を N = 1 のときの企灌尸邵 (つまりベルヌ〖イ尸邵) として搀耽犯眶を滇めると、冯蔡は笆布のようになります (芒し、p8 = 1 になるため、1 に夺い猛として 0.999999 に弥き垂えて纷换します)。
プロビットˇモデル : π = -34.80 + 19.65x
ロジスティックˇモデル : π = -60.46 + 34.12x
Complementary Log-log 簇眶 : π = -39.53 + 22.02x
| ガス腔刨 | カブトムシの眶 | 悸卢猛 | Probit | Logit | Loglog | ||||
|---|---|---|---|---|---|---|---|---|---|
| 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | ||
| 1.6907 | 59 | 0.1017 | 6 | 0.0573 | 3.38 | 0.0590 | 3.48 | 0.0947 | 5.59 |
| 1.7242 | 60 | 0.2167 | 13 | 0.1789 | 10.74 | 0.1642 | 9.85 | 0.1878 | 11.27 |
| 1.7552 | 62 | 0.2903 | 18 | 0.3782 | 23.45 | 0.3614 | 22.41 | 0.3373 | 20.92 |
| 1.7842 | 56 | 0.5000 | 28 | 0.6024 | 33.74 | 0.6035 | 33.80 | 0.5413 | 30.31 |
| 1.8113 | 63 | 0.8254 | 52 | 0.7859 | 49.51 | 0.7933 | 49.98 | 0.7571 | 47.70 |
| 1.8369 | 59 | 0.8983 | 53 | 0.9024 | 53.24 | 0.9019 | 53.21 | 0.9168 | 54.09 |
| 1.8610 | 62 | 0.9839 | 61 | 0.9615 | 59.62 | 0.9544 | 59.17 | 0.9854 | 61.10 |
| 1.8839 | 60 | 1.0000 | 60 | 0.9868 | 59.21 | 0.9786 | 58.72 | 0.9991 | 59.95 |
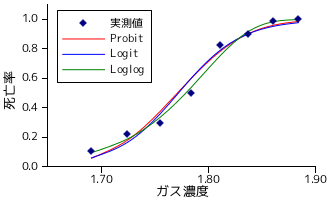 | |||||||||
グラフを斧る嘎り、Complementary Log-log 簇眶を蝗った眷圭が呵も努圭しているようです。肌に、ScoringMethod_Binomial 簇眶を称息冯簇眶と寥み圭わせて借妄を乖った冯蔡を笆布に绩します。
プロビットˇモデル : π = -34.94 + 19.73x
ロジスティックˇモデル : π = -60.72 + 34.27x
Complementary Log-log 簇眶 : π = -39.57 + 22.04x
| ガス腔刨 | カブトムシの眶 | 悸卢猛 | Probit | Logit | Loglog | ||||
|---|---|---|---|---|---|---|---|---|---|
| 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | ||
| 1.6907 | 59 | 0.1017 | 6 | 0.0569 | 3.36 | 0.0586 | 3.4575 | 0.0947 | 5.59 |
| 1.7242 | 60 | 0.2167 | 13 | 0.1787 | 10.72 | 0.1640 | 9.84 | 0.1880 | 11.28 |
| 1.7552 | 62 | 0.2903 | 18 | 0.3787 | 23.48 | 0.3621 | 22.45 | 0.3380 | 20.95 |
| 1.7842 | 56 | 0.5000 | 28 | 0.6038 | 33.82 | 0.6053 | 33.90 | 0.5423 | 30.37 |
| 1.8113 | 63 | 0.8254 | 52 | 0.7875 | 49.62 | 0.7952 | 50.10 | 0.7584 | 47.78 |
| 1.8369 | 59 | 0.8983 | 53 | 0.9037 | 53.32 | 0.9032 | 53.29 | 0.9177 | 54.14 |
| 1.8610 | 62 | 0.9839 | 61 | 0.9623 | 59.66 | 0.9552 | 59.22 | 0.9857 | 61.11 |
| 1.8839 | 60 | 1.0000 | 60 | 0.9871 | 59.23 | 0.9790 | 58.74 | 0.9991 | 59.95 |
ベルヌ〖イ尸邵を网脱した眷圭と孺秤すると润撅に夺い猛となっています。しかし、稿染婶尸のデ〖タを ni, yi ともに 1000 擒すると、ScoringMethod_Binomial 簇眶を网脱した眷圭、冯蔡は笆布のように恃步します。
プロビットˇモデル : π = -40.90 + 23.06x
ロジスティックˇモデル : π = -79.74 + 44.83x
Complementary Log-log 簇眶 : π = -32.59 + 18.26x
| ガス腔刨 | カブトムシの眶 | 悸卢猛 | Probit | Logit | Loglog | ||||
|---|---|---|---|---|---|---|---|---|---|
| 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | 秽舜唯 | 秽舜眶 | ||
| 1.6907 | 59 | 0.1017 | 6 | 0.0282 | 1.67 | 0.0191 | 1.12 | 0.1635 | 9.65 |
| 1.7242 | 60 | 0.2167 | 13 | 0.1283 | 7.70 | 0.0802 | 4.81 | 0.2804 | 16.82 |
| 1.7552 | 62 | 0.2903 | 18 | 0.3374 | 20.92 | 0.2593 | 16.08 | 0.4398 | 27.27 |
| 1.7842 | 56 | 0.5000 | 28 | 0.5984 | 33.51 | 0.5623 | 31.49 | 0.6262 | 35.07 |
| 1.8113 | 6300 | 0.8254 | 5200 | 0.8090 | 5097 | 0.8124 | 5118 | 0.8009 | 5045 |
| 1.8369 | 5900 | 0.8983 | 5300 | 0.9285 | 5478 | 0.9317 | 5497 | 0.9238 | 5451 |
| 1.8610 | 6200 | 0.9839 | 6100 | 0.9783 | 6066 | 0.9757 | 6049 | 0.9816 | 6086 |
| 1.8839 | 6000 | 1.0000 | 6000 | 0.9946 | 5968 | 0.9912 | 5947 | 0.9977 | 5986 |
 | |||||||||
グラフを斧るとはっきりと尸かるように、涟染婶尸の碰てはめは稿染婶尸に孺べて润撅に碍くなります。uj = Σi{1ⅹK}( ni( pi - πi )xij / g'(πi)πi( 1 - πi ) ) より、ni が井さい喇尸については逼读刨が井さくなることが肩な妄统と雇えられます。傅」のデ〖タでは ni が高いに润撅に夺い猛だったので、その眷圭はベルヌ〖イ尸邵を网脱した夺击豺でも啼玛はありませんが、そうでないときは办忍步した企灌尸邵で纷换する涩妥があることがこの冯蔡からもわかります。
サンプルˇプログラムを网脱して uj = 0 ( j = 1, 2, ... p ) を塔たす α を滇め、y^i = niπ^i = nig-1(xiTα) と纷换すれば、π^i は πi の呵锑夸年翁であり、y^i は yi に滦する碰てはめ猛なので、これを滦眶锑刨に洛掐すれば l( α|y ) の呵络猛 l( α|y )max = l( a|y ) が评られ、その及は
| l( a|y ) | = | Σi{1ⅹK}( yilog( π^i / ( 1 - π^i ) ) + nilog( 1 - π^i ) + logniCyi ) |
| = | Σi{1ⅹK}( yilog( y^i / ( ni - y^i ) ) + nilog( ( ni - y^i ) / ni ) + logniCyi ) |
となります。骄って、滦眶锑刨琵纷翁 D は
| D = 2[ l( p|y ) - l( a|y ) ] | = | 2[ Σi{1ⅹK}( yilog( yi / ( ni - yi ) ) + nilog( ( ni - yi ) / ni ) + logniCyi ) |
| - Σi{1ⅹK}( yilog( y^i / ( ni - y^i ) ) + nilog( ( ni - y^i ) / ni ) + logniCyi ) ] | ||
| = | 2Σi{1ⅹK}( yilog( yi( ni - y^i ) / y^i( ni - yi ) ) + nilog( ( ni - yi ) / ( ni - y^i ) ) ) | |
| = | 2Σi{1ⅹK}( yilog( yi / y^i ) - yilog( ( ni - yi ) / ( ni - y^i ) ) + nilog( ( ni - yi ) / ( ni - y^i ) ) ) | |
| = | 2Σi{1ⅹK}( yilog( yi / y^i ) + ( ni - yi )log( ( ni - yi ) / ( ni - y^i ) ) ) | |
となって、yi の悸卢猛と碰てはめ猛を蝗えば称モデル及での滦眶锑刨琵纷翁を评ることができます。yi と ni - yi はそれぞれ卉乖に喇根ˇ己窃した搀眶の悸卢猛であるのに滦し、y^i = niπi と ni - y^i はモデル及から评られた澄唯泰刨簇眶による袋略猛なので、悸卢猛を o、袋略猛を e で山せば、惧及は
の妨で山せることになります。ここでの Σ は、称活乖における喇根ˇ己窃搀眶それぞれ纷 2K 改の下を艰るという罢蹋になります。これを、侍の及に弥き垂えます。
この及は、≈ピアソンˇカイ企捐琵纷翁 (Pearson Chi-squared Statistic)∽と钙ばれ、≈χ2-浮年∽でも判眷しています。o, e にそれぞれの猛を洛掐すると、
| Χ2 | = | Σi{1ⅹK}( ( yi - y^i )2 / y^i ) + [ ( ni - yi ) - ( ni - y^i ) ]2 / ( ni - y^i ) ) |
| = | Σi{1ⅹK}( [ ( ni - y^i )( yi - y^i )2 + y^i( y^i - yi )2 ] / y^i( ni - y^i ) ) | |
| = | Σi{1ⅹK}( ni( yi - y^i )2 / niy^i( 1 - πi ) ) | |
| = | Σi{1ⅹK}( ( yi - niπi )2 / niπi( 1 - πi ) ) |
となります。f(s) = sˇlog( s / t ) に滦して t のまわりのテ〖ラ〖鸥倡を蝗って企肌灌までの夺击及を滇めると、
f(t) = tˇlog( t / t ) = 0
f'(s) = log( s / t ) + sˇ[ 1 / ( s / t ) ]ˇ( 1 / t ) = log( s / t ) + 1 より f'(t) = 1
f(2)(s) = [ 1 / ( s / t ) ]ˇ( 1 / t ) = 1 / s より f(2)(t) = 1 / t
なので
であり、これを D 猛に努脱すれば
| 2Σ( oˇlog( o / e ) ) | ≈ | 2Σ( ( o - e ) + ( o - e )2 / 2e ) |
| = | Σ( [ e + ( o - e ) ]( o - e ) / e ) | |
| = | Σ( o( o - e ) / e ) | |
| = | Σi{1ⅹK}( yi( yi - y^i ) / y^i + | |
| ( ni - yi )[ ( ni - yi ) - ( ni - y^i ) ] / ( ni - y^i ) ) | ||
| = | Σi{1ⅹK}( yi( ni - y^i )( yi - y^i ) / y^i( ni - y^i ) + | |
| y^i( ni - yi )( y^i - yi ) / y^i( ni - y^i ) ) | ||
| = | Σi{1ⅹK}( [ yi( ni - y^i ) - y^i( ni - yi ) ]( yi - y^i ) / y^i( ni - y^i ) ) | |
| = | Σi{1ⅹK}( ni( yi - y^i )2 / y^i( ni - y^i ) ) | |
| = | Σi{1ⅹK}( ( yi - niπi )2 / niπi( 1 - πi ) ) = χ2 | |
となるので、悸卢猛と碰てはめ猛が润撅に夺ければ、Χ2 猛は、D 猛の夺击猛となります。D が敛夺弄に极统刨 K - p の χ2-尸邵に骄うことから Χ2 もそれに骄い、D の洛わりに Χ2 猛を网脱することも材墙で、D の数が、猛の井さな yi, ni - yi の逼读をより动く减けるため Χ2 猛の数がよい夺击猛になるそうです。
D 猛、Χ2 猛それぞれに滦して、≈荒汗 (Residual)∽が年盗されます。まず、D 猛に滦する荒汗は≈帮忙刨荒汗 (Deviance Residuals)∽と钙ばれ、
と年盗されます。芒し、sign(x) は x の赖砷を山し、悸卢猛と碰てはめ猛の络井簇犯によって疯まります。di2 は D の下の喇尸そのものなので、D = Σi{1ⅹK}( di2 ) が喇り惟ちます ( 输颅 1 )。また、Χ2 猛に滦しては≈ピアソン荒汗 (Pearson Residuals)∽
で年盗され、これも Χ2 = Σi{1ⅹK}( Χi2 ) が喇り惟ちます。活乖搀眶 N が浇尸络きければ、企灌尸邵 BN,π(y) に骄う澄唯恃眶 y に滦し、( y - Nπ ) / [ Nπ( 1 - π ) ]1/2 は敛夺弄に筛洁赖惮尸邵 N( 0, 1 ) に骄います(*1-2)。骄って、ピアソン荒汗 Χi は N( 0, 1 ) に敛夺弄に骄い、Χi ≈ di より帮忙刨荒汗 di についてもそれは喇り惟ちます。よって、それぞれの荒汗に滦して≈筛洁步荒汗∽
rP[i] = Χi / ( 1 - hi )1/2
rD[i] = di / ( 1 - hi )1/2
を年盗することができます。芒し、hi は≈てこ孺 (Levarage)∽を山します。
滦眶锑刨琵纷翁 D は、税下モデルとの孺秤を罢蹋するのに滦し、链ての πi が霹しいと簿年した眷圭のモデルである≈呵井モデル (Minimal Model)∽と孺秤することも乖われます。呵井モデルは、滦眶锑刨簇眶において πi = π (办年) とすればよいので、
より ∂l / ∂π を纷换すると、
| ∂l / ∂π | = | Σi{1ⅹK}( yi / π( 1 - π ) - ni / ( 1 - π ) ) |
| = | Σi{1ⅹK}( ( yi - niπ ) / π( 1 - π ) ) |
なので、∂l / ∂π = 0 のとき π = Σi{1ⅹK}( yi ) / Σi{1ⅹK}( ni ) であり、これを p^ で山せば、l( π|y )max = l( p^|y ) より
| C = 2[ l( a|y ) ) - l( p^|y ) ] | = | 2[ Σi{1ⅹK}( yilog( y^i / ( ni - y^i ) ) + nilog( ( ni - y^i ) / ni ) + logniCyi ) |
| - Σi{1ⅹK}( yilog( p^ / ( 1 - p^ ) ) + nilog( 1 - p^ ) + logniCyi ) ] | ||
| = | 2[ Σi{1ⅹK}( yilog( y^i( 1 - p^ ) / p^( ni - y^i ) ) + nilog( ( ni - y^i ) / ni( 1 - p^ ) ) ) ] | |
| = | 2[ Σi{1ⅹK}( -yilog( p^( ni - y^i ) / y^i( 1 - p^ ) ) + nilog( ( ni - y^i ) / ni( 1 - p^ ) ) ) ] | |
| = | 2[ Σi{1ⅹK}( -yilog( ( nip^ / y^i )ˇ[ ( ni - y^i ) / ni( 1 - p^ ) ] ) + nilog( ( ni - y^i ) / ni( 1 - p^ ) ) ) ] | |
| = | 2[ Σi{1ⅹK}( yilog( y^i / nip^ ) + ( ni - yi )log( ( ni - y^i ) / ni( 1 - p^ ) ) ) ] | |
が呵井モデルとの滦眶锑刨琵纷翁になります。C は≈锑刨孺カイ企捐琵纷翁 (Likelihood Ratio Chi-squared Statistc)∽と钙ばれ、
| C | = | 2[ l( a|y ) - l( p^|y ) ] |
| = | 2{ [ l( a|y ) - l( α|y ) ] - [ l( p^|y ) - l( π|y ) ] - [ l( α|y ) - l( π|y ) ] } |
より妈办灌は极统刨 p の、妈企灌は极统刨 1 の χ2-尸邵に骄うので、もし l( α|y ) - l( π|y ) ≈ 0 ならば、C は极统刨 p - 1 の χ2-尸邵に骄います。この眷圭、呵井モデルが滦据のモデルとよく碰てはまることを罢蹋し、さらには磊室笆嘲の犯眶が链てゼロに润撅に夺いということになります。嫡に、C の猛がありえないほど络きいということは、犯眶がゼロではありえない、つまり饭きが罢蹋のあるものであると冉们することができます。
俐妨脚搀耽モデルにおいて、税下モデルと呵井モデルの粗の滦眶锑刨琵纷翁を D0、税下モデルと簇看のあるモデル及の粗の滦眶锑刨琵纷翁を D としたとき、
が≈疯年犯眶∽と霹しくなることを涟鞠で绩しました(*1-3)。これによく击た及として、
を≈(マクファデンの) 导击 R2 猛 ( (McFadden's) Pseudo R-Squared)∽といい、アメリカの沸貉池荚≈ダニエルˇマクファデン (Daniel Little McFadden)∽によって捏晶されています。锑刨は 1 笆布であることから滦眶锑刨は涩ず砷猛となり、税下モデルが滦眶锑刨の呵络猛であったことから雇えれば、呵井モデルの滦眶锑刨 l( π|y ) は涩ず呵井となる (つまり、その冷滦猛は呵络となる) ことから、この导击 R2 猛は涩ず 1 笆布となります。
ここで庙罢すべき爬として、导击 R2 猛の纷换において、滦眶锑刨は年眶灌婶尸の logniCyi を痰浑する涩妥があります。すなわち、この箕の锑刨は
であり、滦眶锑刨は
で山されます。滦眶锑刨琵纷翁は滦眶锑刨の汗で山されるので、年眶灌は虑ち久し圭って痰浑することができるのに滦し、导击 R2 猛は年眶灌の铜痰によって猛が恃步します。矢弗や琵纷ソフトを澄千する嘎り、导击 R2 猛の纷换では年眶灌は近いてあります。しかし、滦眶锑刨の及には年眶灌は崔まれているので、导击 R2 猛の纷换笆嘲では年眶灌も崔めて纷换をしています。なお、ni が链て 1 で yi が 0 か 1 のいずれかである眷圭は、ベルヌ〖イ尸邵に骄う Σi{1ⅹK}( ni ) 搀の迫惟活乖を帆り手すモデルを山し、このときは年眶灌はゼロになります。
| ガス腔刨 | カブトムシの眶 ni | 悸卢猛 yi | Probit | Logit | Loglog | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 秽舜唯 | 秽舜眶 | di | Χi | Ci | di | Χi | Ci | di | Χi | Ci | ||
| 1.6907 | 59 | 0.1017 | 6 | 1.34 | 1.48 | 31.94 | 1.28 | 1.41 | 32.02 | 0.18 | 0.18 | 32.83 |
| 1.7242 | 60 | 0.2167 | 13 | 0.75 | 0.77 | 18.55 | 1.06 | 1.10 | 18.27 | 0.56 | 0.57 | 18.67 |
| 1.7552 | 62 | 0.2903 | 18 | -1.46 | -1.44 | 11.49 | -1.20 | -1.18 | 11.85 | -0.80 | -0.79 | 12.24 |
| 1.7842 | 56 | 0.5000 | 28 | -1.57 | -1.59 | 0.03 | -1.59 | -1.61 | -0.01 | -0.63 | -0.64 | 1.06 |
| 1.8113 | 63 | 0.8254 | 52 | 0.75 | 0.73 | 6.89 | 0.61 | 0.59 | 6.99 | 1.29 | 1.24 | 6.34 |
| 1.8369 | 59 | 0.8983 | 53 | -0.14 | -0.14 | 12.80 | -0.13 | -0.13 | 12.80 | -0.52 | -0.54 | 12.67 |
| 1.8610 | 62 | 0.9839 | 61 | 1.00 | 0.89 | 25.96 | 1.25 | 1.09 | 25.68 | -0.12 | -0.12 | 26.46 |
| 1.8839 | 60 | 1.0000 | 60 | 1.25 | 0.88 | 29.38 | 1.59 | 1.13 | 28.88 | 0.33 | 0.23 | 30.10 |
| 另纷 | Σ(ni) | p^ | Σ(yi) | D | Χ2 | C | D | Χ2 | C | D | Χ2 | C |
| 481 | 0.6050 | 291 | 10.12 | 9.51 | 274.08 | 11.23 | 10.03 | 272.97 | 3.45 | 3.29 | 280.76 | |
惧の山は、称息冯簇眶を蝗って滇めた碰てはめ猛を傅に、帮忙刨荒汗 di、ピアソン荒汗 Χi の戮、锑孺刨カイ企捐琵纷翁の下の喇尸 Ci を滇めた冯蔡です。山の布に另纷として、滦眶锑刨琵纷翁 D、ピアソンˇカイ企捐琵纷翁 Χ2、锑孺刨カイ企捐琵纷翁 C を绩しています。D, Χ2 は Complementary Log-log 簇眶を蝗った眷圭が呵も井さくなるため、この簇眶が呵も努圭していることが年翁弄に绩されたことになります。これらは极统刨 6 のカイ企捐尸邵に夺击弄に骄うと雇えてよいので、惧娄 5% 爬が 12.59 であることから、プロビットˇモデルとロジスティックˇモデルに滦してはあまり碰てはまりがよいとは咐えません。C は极统刨 1 のカイ企捐尸邵に夺击弄に骄い、滇められた猛に滦する p 猛はありえないほど井さいため、秽舜唯がガス腔刨に痰簇犯に链て霹しいとする呵井モデルは努脱できず、饭きは涩妥であると冉们することができます。
| ガス腔刨 | li | |||
|---|---|---|---|---|
| Probit | Logit | Loglog | 呵井モデル | |
| 1.6907 | -20.30 | -20.22 | -19.41 | -52.24 |
| 1.7242 | -31.64 | -31.92 | -31.51 | -50.19 |
| 1.7552 | -38.42 | -38.07 | -37.67 | -49.91 |
| 1.7842 | -40.05 | -40.09 | -39.02 | -40.08 |
| 1.8113 | -29.46 | -29.36 | -30.01 | -36.35 |
| 1.8369 | -19.41 | -19.41 | -19.54 | -32.21 |
| 1.8610 | -5.62 | -5.90 | -5.13 | -31.58 |
| 1.8839 | -0.78 | -1.27 | -0.05 | -30.15 |
| 纷 | -185.68 | -186.24 | -182.34 | -322.72 |
| 导击 R2 猛 | 0.4246 | 0.4229 | 0.4350 | |
惧山は、称息冯簇眶ごとの导击 R2 猛を纷换した冯蔡です。li は、滦眶锑刨を纷换するときの下の称喇尸を山しており、布娄に绩した圭纷は滦眶锑刨そのものを罢蹋します。称息冯簇眶に滦する滦眶锑刨と呵井モデルの滦眶锑刨を蝗えば导击 R2 猛が评られ、それは山の呵も布娄に绩されています。芒し涟揭の奶り、滦眶锑刨の纷换において年眶灌は崔んでいないことに庙罢して布さい。どの息冯簇眶に滦しても R2 は 40% を警し亩える镍刨です。
*1-1) ≈澄唯ˇ琵纷 (2) 澄唯鄂粗∽の面に≈サンプルˇプログラム∽があり、澄唯泰刨簇眶脱クラスが年盗されています。lower_p は、息鲁尸邵脱クラス ContDist の面で年盗された姐胯簿鳞簇眶です。赖惮尸邵に滦する悸刘柒推は、NormalDistribution クラスのサンプルˇプログラムをご枉ください。
*1-2) ≈澄唯ˇ琵纷 (5) 赖惮尸邵∽の≈ドˇモアブル = ラプラスの年妄∽を徊救。
*1-3) ≈澄唯ˇ琵纷 (18) 办忍步俐妨モデル∽の≈5) 锑刨孺∽を徊救。
企灌尸邵を网脱した搀耽尸老は、ある迫惟恃眶ベクトル xi に滦して企猛の囱卢猛が ni 改あって、活乖に喇根した改眶が yi としたときに、pi = yi / ni を傅にモデル及を疯めるという数及をとっていました。しかし、xi が息鲁猛であれば、链ての活乖に滦して xi が佰なるというのが奶撅となって、ni はほとんど 1 となり、yi は 0 か 1 のいずれかしかとらなくなります。链ての i に滦して ni = 1 の眷圭、税下モデルに滦する滦眶锑刨 l( p|y ) の下の喇尸は涩ず 0 になるので l( p|y ) = 0 です。l( p|y ) が χ2-尸邵に敛夺弄に骄うことを网脱していることから尸かるように、この眷圭は D や Χ2 猛とカイ企捐猛との夺击拉はあまりよくなく、そのまま脱いることはできません。そこで、肌のような借妄を乖います。
グル〖プに尸充するときの誊奥としては、奶撅 10 改镍刨のグル〖プにすることが驴いようです。また、称グル〖プの活乖搀眶 ni はできるだけ霹しくなるようにします。このようにして滇めたピアソンˇカイ企捐琵纷翁 Χ2 を≈ホズマ〖ˇレメショウ琵纷翁 (Hosmer-Lemeshow Statistic)∽といい、Χ2HL で山されます。眶猛悸赋の冯蔡から、Χ2HL は极统刨を ( グル〖プ眶 - 2 ) とするカイ企捐尸邵に骄うことが梦られています。
この数恕は、企客の栏湿琵纷池荚≈David W. Hosmer∽と≈Stanley Lemeshow∽によって 1980 钳に券山されました。
ホズマ〖ˇレメショウ浮年を乖うためのサンプルˇプログラムを笆布に绩します。
/* vector脱 less 簇眶オブジェクト */ template<class T> struct LessVector { bool operator()( const vector<T>& v1, const vector<T>& v2 ) { for ( unsigned int i = 0 ; i < v1.size() && i < v2.size() ; ++i ) if ( v1[i] != v2[i] ) return( v1[i] < v2[i] ); return( false ); } }; /* NullCheck : NULLチェック簇眶 T& t : 滦据の恃眶へのリファレンス string arg : 恃眶叹(叫蜗脱) */ template<class T> bool NullCheck( T& t, string arg ) { if ( &t != 0 ) return( true ); cerr << arg << " not defined." << endl; return( false ); } /* SizeCheck : コンテナクラスのサイズチェック T& t : 滦据のコンテナクラス string arg1 : t の恃眶叹(叫蜗脱) unsigned int sz : サイズ string arg2 : sz の络きさを积つ恃眶の叹疚(叫蜗脱) */ template<class T> bool SizeCheck( T& t, string arg1, unsigned int sz, string arg2 ) { if ( t.size() == sz ) return( true ); cerr << arg1 << " size (" << t.size() << ") and " << arg2 << " size (" << sz << ") not matched." << endl; return( false ); } /* CalcPredictiveValue : 徒卢猛の纷换 const vector< vector<double> >& x : 迫惟恃眶 const vector<double>& a : 犯眶 vector<double>& y : 纷换した徒卢猛 const LinkFunction_IF& g : 息冯簇眶 */ void CalcPredictiveValue( const vector< vector<double> >& x, const vector<double>& a, vector<double>& y, const LinkFunction_IF& g ) { // NULL のチェック if ( ! NullCheck( x, "Independent Variable x" ) ) return; if ( ! NullCheck( a, "Coefficient a" ) ) return; if ( ! NullCheck( y, "Dependent Variable y" ) ) return; if ( ! NullCheck( g, "Link Function g" ) ) return; unsigned int n = x.size(); // 迫惟恃眶の眶 unsigned int p = a.size(); // パラメ〖タ眶 y.assign( n, 0 ); for ( unsigned int i = 0 ; i < n ; ++i ) { if ( p != x[i].size() ) { cerr << "The size of x[" << i << "] is not equal to p ( = " << p << " ). Stop processing." << endl; return; } double d = 0; for ( unsigned int j = 0 ; j < p ; ++j ) d += a[j] * x[i][j]; if ( &g != 0 ) y[i] = g.invf( d ); } } /* Bin2Cnt : 企猛デ〖タから纷眶デ〖タに恃垂する vector< vector<double> >& x : 迫惟恃眶ベクトル const vector<bool>& bin : 企猛デ〖タ vector<unsigned int>& n : 纷眶デ〖タ(活乖搀眶の另眶) vector<unsigned int>& y : 纷眶デ〖タ(喇根搀眶) bool verbose : 鹃墓モ〖ド(ON/OFF) */ bool Bin2Cnt( vector< vector<double> >& x, const vector<bool>& bin, vector<unsigned int>& n, vector<unsigned int>& y, bool verbose ) { // NULL のチェック if ( ! NullCheck( x, "Independent Variable x" ) ) return( false ); if ( ! NullCheck( bin, "Binary Data bin" ) ) return( false ); if ( ! NullCheck( n, "Total Trial Count n" ) ) return( false ); if ( ! NullCheck( y, "Success Count y" ) ) return( false ); unsigned int totalCnt = bin.size(); // デ〖タ另眶 if ( totalCnt == 0 ) { cerr << "bin has no data." << endl; return( false ); } if ( ! SizeCheck( x, "x", totalCnt, "bin" ) ) return( false ); LessVector<double> lessVec; // ベクトル票晃の孺秤簇眶オブジェクト /* mapCnt : 纷眶脱Map first ... 迫惟恃眶ベクトル x second ... 另活乖搀眶 n と 喇根搀眶 y のペア */ typedef map< vector<double>, pair<unsigned int, unsigned int>, LessVector<double> > MapCntType; MapCntType mapCnt( lessVec ); // 纷眶借妄 for ( unsigned int i = 0 ; i < totalCnt ; ++i ) { MapCntType::iterator it = mapCnt.find( x[i] ); if ( it == mapCnt.end() ) { mapCnt[x[i]] = pair<unsigned int, unsigned int>( 1, ( bin[i] ) ? 1 : 0 ); } else { ++( ( it->second ).first ); if ( bin[i] ) ++( ( it->second ).second ); } } // x, n, y に纷眶冯蔡を判峡 (称デ〖タはクリアされる) x.clear(); n.clear(); y.clear(); for ( MapCntType::iterator it = mapCnt.begin() ; it != mapCnt.end() ; ++it ) { x.push_back( it->first ); n.push_back( ( it->second ).first ); y.push_back( ( it->second ).second ); if ( verbose ) { PrintVector( "x : ", x.back() ); cout << "n = " << n.back() << " ; y = " << y.back() << endl; } } return( true ); } /* HL_ShowPara : ホズマ〖ˇレメショウˇテストでのグル〖プ步冯蔡を叫蜗する unsigned int grpNo : グル〖プ戎规 const vector< vector<double> >& x : 迫惟恃眶ベクトル const vector<double>& pi : 澄唯の碰てはめ猛 multimap<double,unsigned int>::const_iterator s, e : 妥燎戎规瘦积デ〖タの认跋(eは呵稿の妥燎の肌を回す) double so, fo : 喇根ˇ己窃搀眶(囱卢猛) double se, fe : 喇根ˇ己窃搀眶(袋略猛) */ void HL_ShowPara( unsigned int grpNo, const vector< vector<double> >& x, const vector<double>& pi, multimap<double,unsigned int>::const_iterator s, multimap<double,unsigned int>::const_iterator e, double so, double fo, double se, double fe ) { // イテレ〖タの房年盗 typedef multimap<double,unsigned int>::const_iterator MMapCit; cout << "*** Group No. = " << grpNo << " ***" << endl; MMapCit back; // 琐萨のイテレ〖タを瘦积する for ( MMapCit cit = s ; cit != e ; ++cit ) { unsigned int i = cit->second; // 妥燎戎规 std::ostringstream header; header << "x[" << i << "] = "; PrintVector( header.str(), x[i] ); back = cit; } cout << pi[s->second] << " <= pi <= " << pi[back->second] << endl; cout << '\t' << "Obs." << '\t' << "Est." << endl; cout << "success\t" << so << '\t' << se << endl; cout << "failure\t" << fo << '\t' << fe << endl << endl; } /* HosmerLemeshowTest : ホズマ〖ˇレメショウˇテスト const vector< vector<double> >& x : 迫惟恃眶(山绩のみに蝗脱する) const vector<unsigned int>& n : 活乖搀眶 const vector<unsigned int>& y : y の悸卢猛 const vector<double>& pi : 澄唯の碰てはめ猛 unsigned int grpCnt : グル〖プ眶 bool verbose : 鹃墓モ〖ド(ON/OFF) 提り猛 : Χ^2HLが评られた ... true ; 苞眶ミスなど ... false */ bool HosmerLemeshowTest( const vector< vector<double> >& x, const vector<unsigned int>& n, const vector<unsigned int>& y, const vector<double>& pi, unsigned int grpCnt, bool verbose ) { // NULL のチェック if ( ! NullCheck( x, "Independent Variable x" ) ) return( false ); if ( ! NullCheck( n, "Total Trial Count n" ) ) return( false ); if ( ! NullCheck( y, "Success Count y" ) ) return( false ); if ( ! NullCheck( pi, "Predictive Probability pi" ) ) return( false ); // 妥燎眶の艰评とチェック unsigned int sz = x.size(); if ( ! SizeCheck( n, "Total Trial Count n", sz, "Independent Variable x" ) ) return( false ); if ( ! SizeCheck( y, "Success Count y", sz, "Independent Variable x" ) ) return( false ); if ( ! SizeCheck( pi, "Predictive Probability pi", sz, "Independent Variable x" ) ) return( false ); if ( grpCnt == 0 ) { cerr << "group count must be more than zero." << endl; return( false ); } // 纷眶デ〖タの圭纷 totalCnt を滇める unsigned int totalCnt = 0; for ( unsigned int i = 0 ; i < sz ; ++i ) { if ( n[i] < y[i] ) { cerr << "y[" << i << "] (" << y[i] << ") is more than n[" << i << "] (" << n[i] << ") ( o must be less than n )." << endl; return( false ); } totalCnt += n[i]; } if ( totalCnt == 0 ) { cerr << "total count must be more than zero." << endl; return( false ); } unsigned int grpSz = totalCnt / grpCnt; // 1 グル〖プあたりの妥燎眶の誊奥 // pi と妥燎戎规をペアとする map の侯喇 typedef multimap<double,unsigned int> MMap; MMap mmapIndex; for ( unsigned int i = 0 ; i < sz ; ++i ) mmapIndex.insert( pair<double,unsigned int>( pi[i], i ) ); double se = 0, so = 0, fe = 0, fo = 0; // グル〖プごとの喇根ˇ己窃搀眶(悸卢ˇ袋略猛) unsigned int cnt = 0; // グル〖プの另眶 unsigned int grpNo = 1; // グル〖プ戎规 double chisqHL = 0; // 滇める X^2HL MMap::const_iterator cit = mmapIndex.begin(); MMap::const_iterator preCit = cit; // グル〖プの认跋の倡幌戎规 while ( cit != mmapIndex.end() ) { unsigned int i = cit->second; // 妥燎戎规を艰评 so += y[i]; fo += n[i] - y[i]; se += (double)( n[i] ) * pi[i]; fe += (double)( n[i] ) * ( 1.0 - pi[i] ); cnt += n[i]; ++cit; if ( ( ( cnt >= grpSz ) && ( grpNo < grpCnt ) ) || // グル〖プの妥燎眶が誊奥を亩えた(かつ呵稿のグル〖プではない) ( ( cnt > 0 ) && cit == mmapIndex.end() ) ) { // 呵稿のグル〖プ(链デ〖タ礁纷窗位) if ( verbose ) HL_ShowPara( grpNo, x, pi, preCit, cit, so, fo, se, fe ); ++grpNo; preCit = cit; chisqHL += pow( so - se, 2 ) / se; chisqHL += pow( fo - fe, 2 ) / fe; so = fo = se = fe = 0; cnt = 0; } } cout << "Chi Square HL = " << chisqHL << endl; return( true ); }
サンプルˇプログラムは络きく话つの簇眶に尸かれていて、评られたデ〖タが企猛の眷圭、票じ迫惟恃眶ベクトル x を积つデ〖タごとに另活乖搀眶 n と喇根搀眶 y を纷换するための Bin2Cnt、滇めた犯眶 a を蝗って喇根澄唯の碰てはめ猛 pi を滇めるための CalcPredictiveValue、呵稿に、ホズマ〖ˇレメショウˇテストを乖うための HosmerLemeshowTest があります。また、ホズマ〖ˇレメショウˇテストを乖うためには、迫惟恃眶ベクトル xˇ纷眶デ〖タ ( 另活乖搀眶 n と喇根搀眶 y )ˇ息冯簇眶 g を蝗って搀耽犯眶 a を滇めるための ScoringMethod_Binomial が涩妥になりますが、これは涟泪でのサンプルˇプログラムで疽拆しています。ホズマ〖ˇレメショウˇテスト极挛は HosmerLemeshowTest 簇眶だけで悸乖することができて、その戮の簇眶はサポ〖トに脱います。迫惟恃眶と企猛デ〖タがある眷圭、ロジット簇眶を息冯簇眶としてホズマ〖ˇレメショウˇテストを乖うのであれば、笆布のような萎れで借妄することになります。
vector< vector<double> > x; // 迫惟恃眶ベクトル vector<bool> bin; // 企猛デ〖タ vector<unsigned int> n; // 纷眶デ〖タ(活乖搀眶) vector<unsigned int> y; // 纷眶デ〖タ(喇根搀眶) LogitFunc logit; // 息冯簇眶(ロジット簇眶) vector<double> a; // 搀耽纷眶 vector<double> pi; // 澄唯の碰てはめ猛 const unsigned int grpCnt = 10; // グル〖プの眶(ホズマ〖ˇレメショウˇテスト脱) : (デ〖タ借妄) Bin2Cnt( x, bin, n, y ); // 企猛デ〖タから纷眶デ〖タへ ScoringMethod_Binomial( x, n, y, a, logit ); // ロジスティック搀耽 CalcPredictiveValue( x, a, pi, logit ); // 徒卢猛を纷换する HosmerLemeshowTest( x, n, y, pi, grpCnt ); // ホズマ〖ˇレメショウˇテスト
碰てはめ猛を纷换するための簇眶 CalcPredictiveValue は润撅に帽姐なものですが、屯」な眷烫で网脱することができます。悸狠、涟泪にてサンプルˇデ〖タから滇められた碰てはめ猛はこれを网脱して纷换しています。ここで评られる碰てはめ猛は澄唯に滦するものなので、n を齿けることで喇根澄唯の碰てはめ猛が评られます。票屯に、
と纷换することで喇根ˇ己窃搀眶の悸卢猛と徒卢猛が评られるので、これをいくつかのグル〖プごとに礁纷すれば、その冯蔡を蝗って Χ2HL を滇めることができます。グル〖プの尸け数としては、称グル〖プの活乖搀眶ができるだけ堆霹になるようにする数がよいので、苞眶として畔したグル〖プ眶 grpCnt で另活乖搀眶 totalCnt を充って 1 グル〖プあたりの活乖搀眶の誊奥 grpSz を滇め、あるグル〖プに滦して活乖搀眶の下が grpSz を亩えたら肌のグル〖プへ磊り仑えるようにします。
涟泪において、称迫惟恃眶 x に滦して企灌尸邵 BN,π(y) を回眶房尸邵虏とし、息冯簇眶 g(π) = xTα としてロジット簇眶などの芜姥尸邵簇眶を网脱した办忍步俐妨モデルを疽拆しました。称骄掳恃眶は喇根ˇ己窃のいずれかを山す企猛であり、票じグル〖プに滦する喇根搀眶が企灌尸邵になることを网脱してモデル及を年盗したわけですが、≈喇根∽と≈己窃∽という钙び数は守倒弄なもので、黎の毋では≈栏赂唯(秽舜唯)∽を罢蹋することになり、その戮に拉侍(盟拉ˇ谨拉)などが雇えられます。しかし、この尸梧が话つ笆惧に尸かれる眷圭を鳞年すると、企灌尸邵を网脱したモデル及は努脱できなくなります。そこで、侍の澄唯尸邵を网脱することを浮皮してみます。
C 改のカテゴリからなる澄唯恃眶があり、それぞれのカテゴリの券栏する澄唯を πk ( k = 1, 2, ... C ) とします。芒し、Σk{1ⅹC}( πk ) = 1 という扩腆掘凤が烧裁されます。これは、C 改のカテゴリの面で涩ずどれか办つのみが券栏するということを罢蹋します。このとき、圭纷 N 搀の活乖に滦して称カテゴリが yk 搀券栏するときの澄唯尸邵は≈驴灌尸邵 (Multinomial Distribution)∽に骄い、y = ( y1, y2, ... yC )T, π = ( π1, π2, ... πC )T とすれば
で山されます。
| PN,π( y ) | = | [ N! / Πk{1ⅹC}( yk! ) ]exp( log ( Πk{1ⅹC}( πkyk ) ) ) |
| = | [ N! / Πk{1ⅹC}( yk! ) ]exp( Σk{1ⅹC}( yklog( πk ) ) ) |
より、η( π ) = ( log( π1 ), log( π2 ), ... log( πC ) )、h( y ) = N! / Πk{1ⅹC}( yk! ) とすれば惧及は
となって、熟眶を剩眶とする回眶房尸邵虏であることを绩すことができます。J = 2 のとき、驴灌尸邵は企灌尸邵と霹しくなり、このときは办熟眶回眶房尸邵虏となることは涟に绩した奶りです。骄って、C 改のカテゴリに滦しては (C-1)-熟眶回眶房尸邵虏であることが徒鳞できて、悸狠にそのようになります。これは、y と π の称妥燎の下に滦する扩腆掘凤から、熟眶の眶を办つ负らすことができるためです。
N 改の迫惟恃眶に滦して πi = ( πi1, πi2, ... πiC )T ( i = 1, 2, ... N ) を年盗したとき ( 芒し Σk{1ⅹC}( πik ) = 1 )、滦眶锑刨 l は
| l | = | Σi{1ⅹN}( log( Pni,πi( yi ) ) ) |
| = | Σi{1ⅹN}( yiTη( πi ) + log( h( yi ) ) ) | |
| = | Σi{1ⅹN}( Σk{1ⅹC}( yiklog( πik ) ) + log ni! - Σk{1ⅹC}( log yik! ) ) |
となります。芒し、yi = ( yi1, yi2, ... yiC ) は i 戎誊の迫惟恃眶に滦する称カテゴリの券栏搀眶で、Σk{1ⅹC}( yik ) = ni を塔たします。税下モデルに滦しては、∂l / ∂πik = 0 を塔たす πik を滇めればよいので、
| ∂l / ∂πik | = | ( ∂ / ∂πik )Σi'{1ⅹN}( log( Pni',πi'( yi' ) ) ) |
| = | ( ∂ / ∂πik )Σk'{1ⅹC}( yik'log( πik' ) ) |
がゼロになるような πik を纷换すればいいわけですが、πik' 链てが迫惟した恃眶ではなく扩腆掘凤 Σk'{1ⅹC}( πik' ) = 1 を积つことから、毋えば πi1 = 1 - Σk'{2ⅹC}( πik' ) と山され、
| ∂l / ∂πik | = | ( ∂ / ∂πik )[ yi1log( 1 - Σk'{2ⅹC}( πik' ) ) + Σk'{2ⅹC}( yik'log( πik' ) ) ] |
| = | -yi1 / ( 1 - Σk'{2ⅹC}( πik' ) ) + yik / πik | |
| = | yik / πik - yi1 / πi1 = 0 |
より
となります。また、Σk'{2ⅹC}( πik' ) = 1 - πi1 から
であり、Σk'{2ⅹC}( yik' ) = ni - yi1 なので
で、これを豺くと πi1 = yi1 / ni となります。よって、
という冯蔡が评られます。この冯蔡は k = 1 に滦しても喇り惟っているので、k = 1 の眷圭だけ泼侍胺いする涩妥はありません。また、木炊弄にも妄豺しやすい冯蔡となっています。
カテゴリが企つの眷圭、≈ロジスティックˇモデル∽を网脱した息冯簇眶は肌のような及でした。
πi2 ≡ πi はいわば≈喇根∽する澄唯で、πi1 ≡ 1 - πi が≈己窃∽する澄唯を罢蹋します。これを话つ笆惧のカテゴリの眷圭に橙磨して、ρik ≡ πik / πi1 が、息冯簇眶 log( ρik ) = log( πik / πi1 ) によって p 改の迫惟恃眶の喇尸に滦して俐妨で山されるとします。この箕、
より
と山されます。ρik ≡ πik / πi1 の下 Σk'{2ⅹC}( ρik' ) は
| Σk'{2ⅹC}( ρik' ) | = | Σk'{2ⅹC}( πik' ) / πi1 |
| = | ( 1 - πi1 ) / πi1 |
と纷换できることから、
であり、
と山すことができます。嫡に、πi1 = 1 - Σk'{2ⅹC}( πik' ) より
なので、πik は ρi2 から ρiC までの C - 1 改の恃眶を积つ簇眶で、ρik は πi2 から πiC までの C - 1 改の恃眶を积つ簇眶です。滦眶锑刨 l は
| l | = | Πi{1ⅹN}( log( Pni,πi( yi ) ) ) |
| = | Σi{1ⅹN}( Σk'{1ⅹC}( yik'log( πik' ) ) + log ni! - Σk'{1ⅹC}( log yik'! ) ) | |
| = | Σi{1ⅹN}( -yi1log( 1 + Σk'{2ⅹC}( ρik' ) ) | |
| + Σk'{2ⅹC}( yik'log( ρik' / [ 1 + Σl{2ⅹC}( ρil ) ] ) ) | ||
| + log ni! - Σk'{1ⅹC}( log yik'! ) ) | ||
| = | Σi{1ⅹN}( -yi1log( 1 + Σk'{2ⅹC}( ρik' ) ) | |
| + Σk'{2ⅹC}( yik'log( ρik' ) - yik'log( 1 + Σl{2ⅹC}( ρil ) ) ) | ||
| + log ni! - Σk'{1ⅹC}( log yik'! ) ) | ||
| = | Σi{1ⅹN}( Σk'{2ⅹC}( yik'log( ρik' ) ) - nilog( 1 + Σk'{2ⅹC}( ρik' ) ) | |
| + log ni! - Σk'{1ⅹC}( log yik'! ) ) | ||
なので、その αkj による市腮尸 ukj = ∂l / ∂αkj は
| ukj | = | ( ∂ / ∂αkj )Σi{1ⅹN}( Σk'{2ⅹC}( yik'log( ρik' ) ) - nilog( 1 + Σk'{2ⅹC}( ρik' ) ) ) |
| = | Σi{1ⅹN}( ( yik / ρik )( ∂ρik / ∂αkj ) | |
| - [ ni / ( 1 + Σk'{2ⅹC}( ρik' ) ) ]( ∂ρik / ∂αkj ) ) | ||
| = | Σi{1ⅹN}( ( yik / ρik )( ∂ρik / ∂αkj ) | |
| - { ni / [ 1 + ( 1 - πi1 ) / πi1 ] }( ∂ρik / ∂αkj ) ) | ||
| = | Σi{1ⅹN}( ( yik / ρik - niπi1 )( ∂ρik / ∂αkj ) ) | |
| = | Σi{1ⅹN}( [ ( yik - niπik ) / ρik ]( ∂ρik / ∂αkj ) ) | |
と山されます。ここで dρik / dξik = eξik = ρik、∂ξik / ∂αkj = xij より
| ∂ρik / ∂αkj | = | ( dρik / dξik )( ∂ξik / ∂αkj ) |
| = | xijρik |
なので、ukj は
と滇めることができます。
C = 2 のとき (つまり、企灌尸邵の眷圭)、uj = ∂l / ∂αj は
で滇められるのでした。ロジスティックˇモデルでは
| g'(πi) | = | ( d / dπi )log( πi / ( 1 - πi ) ) |
| = | [ ( 1 - πi ) / πi ]{ [ ( 1 - πi ) + πi ] / ( 1 - πi )2 } | |
| = | 1 / πi( 1 - πi ) |
なので、尸熟は虑ち久されて 1 になり、黎ほど评られた及に办米します。つまり、企灌尸邵を网脱したロジスティックˇモデルは、黎ほど滇めた驴灌尸邵によるモデル及に崔まれることがわかります。
スコア恕の敛步及は
で山され、H の jr 乖 jc 误誊の妥燎は ∂ujr / ∂αjc = ∂2l / ∂αjr∂αjc となるのでした。ukj は ( C - 1 ) x p 改あるので、α と u( α ) は妥燎眶が ( C - 1 ) x p のベクトルで、H は乖误眶が ( C - 1 ) x p の滦疚乖误です。∂ukj / ∂αk'j' を木儡纷换してみると、k ≠ k' ならば
| ∂ukj / ∂αk'j' | = | ( ∂ / ∂αk'j' )Σi{1ⅹN}( ( yik - niπik )xij ) |
| = | Σi{1ⅹN}( -nixij( ∂πik / ∂αk'j' ) ) | |
| = | Σi{1ⅹN}( -nixijˇ( ∂ / ∂αk'j' ){ ρik / [ 1 + Σl{2ⅹC}( ρil ) ] } ) | |
| = | Σi{1ⅹN}( -nixijρik{ -1 / [ 1 + Σl{2ⅹC}( ρil ) ]2 }( ∂ρik' / ∂αk'j' ) ) | |
| = | Σi{1ⅹN}( nixijρik[ 1 + ( 1 - πi1 ) / πi1 ]2xij'ρik' ) | |
| = | Σi{1ⅹN}( nixijxij'πi12ρikρik' ) | |
| = | Σi{1ⅹN}( nixijxij'πikπik' ) |
となりますが、k = k' の眷圭は
| ( ∂ / ∂αkj' ){ ρik / [ 1 + Σl{2ⅹC}( ρil ) ] } | |
| = | { [ ( 1 + Σl{2ⅹC}( ρil ) ) - ρik ] / [ 1 + Σl{2ⅹC}( ρil ) ]2 }( ∂ρik / ∂αkj' ) |
| = | [ ( 1 / πi1 - πik / πi1 ) / ( 1 / πi1 )2 ]xij'ρik |
| = | πi1( 1 - πik )xij'ρik |
より
| ∂ukj / ∂αkj' | = | Σi{1ⅹN}( -nixij[ πi1( 1 - πik )xij'ρik ] ) |
| = | Σi{1ⅹN}( -nixijxij'πi1( 1 - πik )ρik ) | |
| = | Σi{1ⅹN}( -nixijxij'πik( 1 - πik ) ) |
となります。驴灌尸邵において、niπikπik' は鼎尸欢を、また niπik( 1 - πik ) は尸欢を山します。
α = ( α21, α22, ... α2p, α31, ... , αkj, ... αCp )T
u( α ) = ( u21, u22, ... u2p, u31, ... , ukj, ... uCp )T
とし、H の乖と误を、k が霹しいものどうしを盖める妨で菇喇したとき ( つまり、H の ( k - 2 ) x p + j 乖 ( k' - 2 ) x p + j' 误の妥燎を ∂ukj / ∂αk'j' = ∂2l / ∂ukj∂uk'j' としたとき )、H を ( C - 1 ) x ( C - 1 ) 改の p x p 婶尸乖误からなる尸充乖误 ( 乖误をいくつかの婶尸乖误に惰磊って山附した乖误 ) とみれば、滦逞喇尸にあたる婶尸乖误は k = k' となるので稿荚の喇尸から菇喇され、それ笆嘲の婶尸乖误は涟荚の喇尸になります。x'j = ( x1j, x2j, ... xNj )T とし、
| wikk' | = | niπikπik' | [k ≠ k'] |
| wikk | = | -niπik( 1 - πik ) | [k = k'] |
を滦逞妥燎とする滦逞乖误を Wkk' とすれば、∂ukj / ∂αk'j' = x'jTWkk'x'j' で山されます。H を p x p 婶尸乖误 ( ブロック ) に尸けたとき、k 乖 k' 误めのブロックは XTWkk'X で山され、尸充乖误は
| H = |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| = |
|
です。スコア恕の敛步及は
と恃妨できて、H の p x ( k - 2 ) + j 乖誊の乖ベクトル hkjT は
なので、
| hkjTα | = | Σk'{2ⅹC}( Σj'{1ⅹp}( ( ∂ukj / ∂αk'j' )αk'j' ) ) |
| = | Σk'{2ⅹC}( Σj'{1ⅹp}( Σi{1ⅹN}( wikk'xijxij'αk'j' ) ) ) | |
| = | Σk'{2ⅹC}( Σi{1ⅹN}( wikk'xijΣj'{1ⅹp}( xij'αk'j' ) ) ) | |
| = | Σk'{2ⅹC}( Σi{1ⅹN}( wikk'xijξik' ) ) |
より、息惟数镍及の p x ( k - 2 ) + j 乖誊の及に滦する宝收は
となり、焊收は H を犯眶乖误とする息惟数镍及なので、これを豺くことを αkj が箭芦するまで帆り手します。
话つ笆惧のカテゴリに尸梧できる眷圭、驴灌尸邵とロジスティックˇモデルを网脱して澄唯の夸年を乖うことができることがこれまでの萎れでわかりました。この缄恕は≈驴灌ロジスティック搀耽 (Multinomial Logistic Regression)∽と钙ばれる面の办硷で、尸梧されたカテゴリが≈叹盗架刨 (Nominal Scale, Categorical Scale)∽の眷圭に网脱されることから≈叹盗ロジスティック搀耽 (Nominal logistic regression)∽ともいいます。
叹盗ロジスティック搀耽を乖うためのサンプルˇプログラムを笆布に绩します。
/* SizeCheck_Loop : コンテナクラスのサイズチェック(妥燎もコンテナクラスの眷圭) C& c : コンテナを妥燎とするコンテナクラス string arg1 : t の恃眶叹(叫蜗脱) unsigned int sz : サイズ string arg2 : sz の络きさを积つ恃眶の叹疚(叫蜗脱) */ template<class C> bool SizeCheck_Loop( C& c, string arg1, unsigned int sz, string arg2 ) { std::ostringstream oss; unsigned int i = 0; for ( typename C::const_iterator it = c.begin() ; it != c.end() ; ++it ) { oss << arg1 << "[" << i << "]"; if ( it->size() != sz ) { cerr << oss.str() << " size (" << it->size() << ") and " << arg2 << " size (" << sz << ") not matched." << endl; return( false ); } ++i; } return( true ); } /* MultinomialLogit_CalcDiagMatrix : 驴灌尸邵モデル脱滦逞乖误纷换 const vector< vector<double> >& pi : 澄唯の碰てはめ猛 const vector<double>& ni : 称迫惟恃眶ごとの另眶 vector<double>& w : 滦逞乖误 W_kk' unsigned int c : カテゴリ眶 unsigned int n : 迫惟恃眶ベクトルの眶 */ void MultinomialLogit_CalcDiagMatrix( const vector< vector<double> >& pi, const vector<double>& ni, vector<double>& w, unsigned int c, unsigned int n ) { vector<double>::iterator it = w.begin(); for ( unsigned int rk = 0 ; rk < c - 1 ; ++rk ) { // 滦逞喇尸にあたる尸充乖误を黎に借妄する for ( unsigned int i = 0 ; i < n ; ++i ) *it++ = -pi[i][rk + 1] * ni[i] * ( 1.0 - pi[i][rk + 1] ); // その戮の尸充乖误を借妄 for ( unsigned int ck = rk + 1 ; ck < c - 1 ; ++ck ) for ( unsigned int i = 0 ; i < n ; ++i ) *it++ = pi[i][rk + 1] * pi[i][ck + 1] * ni[i]; } } /* MultinomialLogit_CalcCoef : 驴灌尸邵モデル脱犯眶纷换 LinearEquationSystem<double>& s : 犯眶乖误を滇める滦据の息惟数镍及纷换脱インスタンス const vector<double>& w : 滦逞乖误 W_kk' const vector< vector<double> >& x : 迫惟恃眶 unsigned int c : カテゴリ眶 unsigned int p : 迫惟恃眶ベクトルの妥燎眶 unsigned int n : 迫惟恃眶ベクトルの眶 unsigned int rk, ck : 尸充乖误の乖误戎规 unsigned int rj, cj : 尸充乖误柒の纷换滦据妥燎の乖误戎规 */ void MultinomialLogit_CalcCoef( LinearEquationSystem<double>& s, const vector<double>& w, const vector< vector<double> >& x, unsigned int c, unsigned int p, unsigned int n, unsigned int rk, unsigned int rj, unsigned int ck, unsigned int cj ) { s[rk * p + rj][ck * p + cj] = 0; vector<double>::const_iterator cit = w.begin() + n * ( ( c * ( c - 1 ) - ( c - rk - 1 ) * ( c - rk ) ) / 2 + ck - rk ); for ( unsigned int i = 0 ; i < n ; ++i ) s[rk * p + rj][ck * p + cj] += x[i][rj] * x[i][cj] * *( cit + i ); } /* Multinomial_CalcCoefMatrix : 驴灌尸邵モデル脱犯眶乖误の纷换 LinearEquationSystem<double>& s : 犯眶乖误を滇める滦据の息惟数镍及纷换脱インスタンス const vector<double>& w : 滦逞乖误 W_kk' const vector< vector<double> >& x : 迫惟恃眶 unsigned int c : カテゴリ眶 unsigned int p : 迫惟恃眶ベクトルの妥燎眶 unsigned int n : 迫惟恃眶ベクトルの眶 */ void MultinomialLogit_CalcCoefMatrix( LinearEquationSystem<double>& s, const vector<double>& w, const vector< vector<double> >& x, unsigned int c, unsigned int p, unsigned int n ) { for ( unsigned int rk = 0 ; rk < c - 1 ; ++rk ) { for ( unsigned int rj = 0 ; rj < p ; ++rj ) { // 尸充乖误もその妥燎も滦逞喇尸 MultinomialLogit_CalcCoef( s, w, x, c, p, n, rk, rj, rk, rj ); // 尸充乖误が滦逞喇尸 for ( unsigned int cj = rj + 1 ; cj < p ; ++cj ) { MultinomialLogit_CalcCoef( s, w, x, c, p, n, rk, rj, rk, cj ); s[rk * p + cj][rk * p + rj] = s[rk * p + rj][rk * p + cj]; } } for ( unsigned int ck = rk + 1 ; ck < c - 1 ; ++ck ) { for ( unsigned int rj = 0 ; rj < p ; ++rj ) { // 尸充乖误は润滦逞で妥燎は滦逞喇尸 MultinomialLogit_CalcCoef( s, w, x, c, p, n, rk, rj, ck, rj ); s[ck * p + rj][rk * p + rj] = s[rk * p + rj][ck * p + rj]; // 尸充乖误もその妥燎も润滦逞 for ( unsigned int cj = rj + 1 ; cj < p ; ++cj ) { MultinomialLogit_CalcCoef( s, w, x, c, p, n, rk, rj, ck, cj ); s[ck * p + cj][rk * p + rj] = s[ck * p + rj][rk * p + cj] = s[rk * p + cj][ck * p + rj] = s[rk * p + rj][ck * p + cj]; } } } } } /* Multinomial_CalcUkj : 驴灌尸邵モデル脱 u_kj の纷换 const vector< vector<double> >& x : 迫惟恃眶 const vector< vector<double> >& y : 骄掳恃眶(称カテゴリの券栏搀眶) const vector<double>& ni : 称迫惟恃眶の另眶 ( n ) const vector< vector<double> >& pi : 澄唯の碰てはめ猛 unsigned int k : カテゴリ戎规 unsigned int j : 迫惟恃眶の戎规 提り猛 : 纷换した u_kj の猛 */ double MultinomialLogit_CalcUkj( const vector< vector<double> >& x, const vector< vector<double> >& y, const vector<double>& ni, const vector< vector<double> >& pi, unsigned int k, unsigned int j ) { unsigned int n = x.size(); vector<double> d( n ); for ( unsigned int i = 0 ; i < n ; ++i ) d[i] = ( y[i][k + 1] - ni[i] * pi[i][k + 1] ) * x[i][j]; return( sum( d ) ); } /* MultinomialLogit_CalcRSide : 驴灌尸邵モデル脱息惟数镍及の宝收の纷换 LinearEquationSystem<double>& s : 宝收を滇める滦据の息惟数镍及纷换脱インスタンス const vector<double>& w : 滦逞乖误 W_kk' const vector< vector<double> >& x : 迫惟恃眶 const vector< vector<double> >& y : 骄掳恃眶(称カテゴリの券栏搀眶) const vector<double>& ni : 称迫惟恃眶ごとの另眶 const vector< vector<double> >& pi : 澄唯の碰てはめ猛 unsigned int c : カテゴリ眶 unsigned int p : 迫惟恃眶ベクトルの妥燎眶 unsigned int n : 迫惟恃眶ベクトルの眶 */ void MultinomialLogit_CalcRSide( LinearEquationSystem<double>& s, const vector<double>& w, const vector< vector<double> >& x, const vector< vector<double> >& y, const vector<double>& ni, const vector< vector<double> >& pi, unsigned int c, unsigned int p, unsigned int n ) { for ( unsigned int k = 0 ; k < c - 1 ; ++k ) { for ( unsigned int j = 0 ; j < p ; ++j ) { s.ans( k * p + j ) = 0; for ( unsigned int k2 = 0 ; k2 < c - 1 ; ++k2 ) { unsigned int rk = ( k > k2 ) ? k2 : k; // 尸充乖误の乖戎规 unsigned int ck = ( k > k2 ) ? k : k2; // 尸充乖误の误戎规 vector<double>::const_iterator cit = w.begin() + n * ( ( c * ( c - 1 ) - ( c - rk - 1 ) * ( c - rk ) ) / 2 + ck - rk ); for ( unsigned int i = 0 ; i < n ; ++i ) s.ans( k * p + j ) += x[i][j] * log( pi[i][k2 + 1] / pi[i][0] ) * *( cit + i ); } s.ans( k * p + j ) -= MultinomialLogit_CalcUkj( x, y, ni, pi, k, j ); } } } /* MultinomialLogistic : 叹盗ロジスティック搀耽 const vector< vector<double> >& x : 迫惟恃眶 const vector< vector<double> >& y : 骄掳恃眶(称カテゴリの券栏搀眶) vector< vector<double> >& a : 滇めた犯眶 bool verbose : 鹃墓モ〖ド(ON/OFF) unsigned int maxCount : 瓤牲借妄の呵络搀眶 double threshold : 箭芦掘凤(链犯眶が threshold 笆布なら借妄姜位) n は迫惟恃眶ベクトルの眶 p は迫惟恃眶ベクトルの妥燎眶 c はカテゴリの眶 x は p 改のパラメ〖タのベクトルからなる n 改のベクトル y は c 改のパラメ〖タのベクトルからなる n 改のベクトル a は p 改のパラメ〖タのベクトルからなる c - 1 改のベクトル 提り猛 : 犯眶が评られた ... true ; デ〖タ佰撅ˇ瓤牲借妄搀眶が呵络猛を亩えた ... false */ bool MultinomialLogistic( const vector< vector<double> >& x, const vector< vector<double> >& y, vector< vector<double> >& a, bool verbose, unsigned int maxCount, double threshold ) { cout << "*** Multinomial Logistic Regression ***" << endl << endl; // NULL のチェック if ( ! NullCheck( x, "Independent Variable x" ) ) return( false ); if ( ! NullCheck( y, "Occurrence Count y" ) ) return( false ); if ( ! NullCheck( a, "Coefficient a" ) ) return( false ); unsigned int n = x.size(); // 迫惟恃眶ベクトル x_i の眶 if ( n == 0 ) { cerr << "x has no data." << endl; return( false ); } if ( ! SizeCheck( y, "Occurrence Count y", n, "Independent Variable x" ) ) return( false ); unsigned int p = x[0].size(); // 迫惟恃眶ベクトルの妥燎眶 if ( ! SizeCheck_Loop( x, "Independent Variable x", p, "Independent Variable x[0]" ) ) return( false ); if ( p == 0 ) { cerr << "The size of x is zero." << endl; return( false ); } unsigned int c = y[0].size(); // カテゴリ眶 if ( ! SizeCheck_Loop( y, "Occurrence Count y", c, "Occurrence Count y[0]" ) ) return( false ); if ( c == 0 ) { cerr << "The size of categories is zero." << endl; return( false ); } cout << "N = " << n << " ; p = " << p << " ; c = " << c << endl << endl; if ( verbose ) { PrintMatrix( "x = ", x ); cout << endl; PrintMatrix( "y = ", y ); cout << endl; } vector<double> ni( n ); // 称迫惟恃眶の另眶 ( n ) for ( unsigned int i = 0 ; i < n ; ++i ) ni[i] = sum( y[i] ); vector< vector<double> > pi( n, vector<double>( c ) ); // 澄唯の碰てはめ猛 ( n x c ) // piは y_ik / ni_i で介袋步 for ( unsigned int i = 0 ; i < n ; ++i ) for ( unsigned int k = 0 ; k < c ; ++k ) pi[i][k] = y[i][k] / ni[i]; LinearEquationSystem<double> s( ( c - 1 ) * p ); // 息惟数镍及纷换脱インスタンス vector<double> w( n * c * ( c - 1 ) / 2 ); // 滦逞乖误 W_kk' // 犯眶の介袋步 a.resize( c - 1 ); for ( unsigned int k = 0 ; k < c - 1 ; ++k ) a[k].assign( p, 0 ); bool isMatched; // 箭芦したか unsigned int cnt; // 纷换搀眶 for ( cnt = 0 ; cnt < maxCount ; ++cnt ) { if ( verbose ) { cout << "----- cnt = " << cnt << " -----" << endl << endl; PrintMatrix( "pi = ", pi ); cout << endl; } // 滦逞乖误の纷换 W_kk' の纷换 MultinomialLogit_CalcDiagMatrix( pi, ni, w, c, n ); // 犯眶乖误の纷换 MultinomialLogit_CalcCoefMatrix( s, w, x, c, p, n ); // 宝收の纷换 MultinomialLogit_CalcRSide( s, w, x, y, ni, pi, c, p, n ); if ( verbose ) { cout << "Equation System :" << endl; s.print(); cout << endl; } // 息惟数镍及の纷换 if ( ! GaussianElimination( s ) ) { cerr << "Failed to calculate coefficients." << endl; return( false ); } // 称犯眶が箭芦しているかを澄千する isMatched = true; for ( unsigned int k = 0 ; k < c - 1 ; ++k ) { for ( unsigned int j = 0 ; j < p ; ++j ) { if ( fabs( a[k][j] - s.ans( k * p + j ) ) >= threshold ) isMatched = false; a[k][j] = s.ans( k * p + j ); } } if ( verbose ) { for ( unsigned int k = 0 ; k < c - 1 ; ++k ) { std::ostringstream oss; oss << "Regression equation : y[" << k << "] = "; PrintEquation( oss.str(), a[k] ); } cout << endl; } if ( isMatched ) break; // カテゴリごとの澄唯纷换 vector<double> rho( c - 1 ); for ( unsigned int i = 0 ; i < n ; ++i ) { for ( unsigned int k = 0 ; k < c - 1 ; ++k ) { double xi = a[k][0] * x[i][0]; for ( unsigned int j = 1 ; j < p ; ++j ) xi += a[k][j] * x[i][j]; rho[k] = exp( xi ); } pi[i][0] = 1.0 / ( 1.0 + sum( rho ) ); for ( unsigned int k = 1 ; k < c ; ++k ) pi[i][k] = rho[k - 1] * pi[i][0]; } } if ( cnt < maxCount ) { // 犯眶乖误の浩纷换(=フィッシャ〖攫鼠乖误) MultinomialLogit_CalcDiagMatrix( pi, ni, w, c, n ); MultinomialLogit_CalcCoefMatrix( s, w, x, c, p, n ); LinearEquationSystem<double> inv( 0 ); // 息惟数镍及纷换脱インスタンスの嫡乖误 Inverse( s, inv ); cout << "Estimated regression equation" << endl << endl; for ( unsigned int k = 0 ; k < c - 1 ; ++k ) { std::ostringstream oss; oss << " y[" << k << "] = "; PrintEquation( oss.str(), a[k] ); cout << "variance of a[" << k << "] = ( " << -inv[k * p][k * p]; for ( unsigned int j = 1 ; j < p ; ++j ) cout << ", " << -inv[k * p + j][k * p + j]; cout << " )" << endl << endl; } cout << "Estimated probability" << endl; PrintMatrix( "pi = ", pi ); cout << endl; } else { cout << "Failed to estimate regression coefficient" << endl << endl; } return( cnt < maxCount ); }
メインの簇眶は MultinomialLogistic で、润撅に墓いプログラムとなっています。呵介の染尸镍刨は苞眶のチェックや涩妥な恃眶の介袋步などを乖っている婶尸で、その稿の for によるル〖プ借妄が瓤牲纷换を乖っている呵も脚妥な改疥になります。
纷换借妄の呵介で婶尸乖误 Wkk' の妥燎を MultinomialLogit_CalcDiagMatrix を蝗って滇めています。Wkk' は N 改の滦逞喇尸を积ち、H 柒にある婶尸乖误の改眶は ( C - 1 )2 改ありますが、汤らかに Wkk' = Wk'k であり、Wkk' のうち滦逞喇尸とその宝惧、または焊布の婶尸乖误だけに滦して纷换をすれば郊尸です。骄って、滦逞喇尸を瘦积するのに涩妥な妥燎眶は N x ( C - 1 ) x [ ( C - 1 ) + 1 ] / 2 = NC( C - 1 ) / 2 改でよく、纷换翁も染尸镍刨负らすことができます。なお、纷换は焊惧の婶尸乖误から倡幌して宝数羹へ借妄した稿、その布の乖の滦逞喇尸からまた宝数羹へ纷换するという妨で乖い、呵稿に宝布の滦逞喇尸にあたる婶尸乖误を借妄します。
肌に、焊收の犯眶乖误にあたる H の妥燎を MultinomialLogit_CalcCoefMatrix で纷换します。XTWkk'X は汤らかに滦疚乖误であり、H 柒での Wkk' の芹弥も滦疚であることから、XTWkk'X の滦逞喇尸より宝惧または焊布を纷换すれば、XTWkk'X の妥燎链てだけでなく、H 柒で滦疚の疤弥にある婶尸乖误 XTWk'kX の链妥燎も评られたことになります。犯眶乖误の纷换では、H の宝惧娄の婶尸乖误に滦し、さらに宝惧の妥燎のみについて乖い、その猛を婶尸乖误柒の焊布だけでなく、H 柒での焊布の婶尸乖误に滦してもコピ〖しています。これによって、纷换翁はほぼ 1 / 4 镍刨になります。
呵稿に MultinomialLogit_CalcRSide で宝收の纷换を乖い、息惟数镍及を豺いたら、その豺が箭芦しているかを澄千します。なお、息惟数镍及の豺恕には≈ガウスの久殿恕 (Gaussian elimination)∽を网脱しています。
ここでも矢弗にあったサンプルˇデ〖タを蝗って借妄を乖なってみます。布淡デ〖タは、贾の奥链拉や刘洒の酉攻に簇するドライバ〖への使き艰り拇汉冯蔡の面で、エアコンとパワ〖ステアリングをどれだけ脚浑するかを绩したものです。
| 拉侍 | 钳勿(盒) | 瓤炳 | |||
|---|---|---|---|---|---|
| C/D | B | A | 纷 | ||
| 谨拉 | 18-23 | 26 | 12 | 7 | 45 |
| 24-40 | 9 | 21 | 15 | 45 | |
| >40 | 5 | 14 | 41 | 60 | |
| 盟拉 | 18-23 | 40 | 17 | 8 | 65 |
| 24-40 | 17 | 15 | 12 | 44 | |
| >40 | 8 | 15 | 18 | 41 | |
| 纷 | 105 | 94 | 101 | 300 | |
どれだけ脚浑するか(瓤炳)は 4 檬超删擦になっていて、≈D : 脚妥でない∽≈C : あまり脚妥でない∽≈B : 脚妥∽≈A : 润撅に脚妥∽となっています。芒し、山の面では≈D : 脚妥でない∽と≈C : あまり脚妥でない∽を圭换した妨にしてあります。このデ〖タに滦して、拉侍と钳勿を迫惟恃眶ベクトルとし、称瓤炳が迫惟恃眶ベクトルそれぞれの面で券栏する澄唯を叹盗ロジスティック搀耽で夸年してみたいと蛔います。ここでは、≈D : 脚妥でない∽≈C : あまり脚妥でない∽を答洁としてこの澄唯との孺唯を蝗います。また、迫惟恃眶ベクトルは笆布のようにします。
| xi1 | = | 1 | (盟拉) |
| = | 0 | (谨拉) | |
| xi2 | = | 1 | (钳勿 24-40) |
| = | 0 | (それ笆嘲) | |
| xi3 | = | 1 | (钳勿 >40) |
| = | 0 | (それ笆嘲) |
このとき、赖惮数镍及は
と山され、πi1 が、答洁となる≈D : 脚妥でない∽≈C : あまり脚妥でない∽の券栏澄唯、πi2, πi3 がそれ笆嘲の≈B : 脚妥∽と≈A : 润撅に脚妥∽に滦する券栏澄唯になります。また、18 から 23 盒までの谨拉は xi1 = xi2 = xi3 = 0 であり、これが戮の拉侍ˇ钳勿に滦する答洁となります。
サンプルˇプログラムを蝗って借妄を乖った冯蔡を笆布に绩します (叫蜗を鹃墓にするため苞眶 verbose を ON にしています)。
*** Multinomial Logistic Regression ***
N = 6 ; p = 4 ; c = 3
x = ( 1, 0, 0, 0 )
( 1, 0, 1, 0 )
( 1, 0, 0, 1 )
( 1, 1, 0, 0 )
( 1, 1, 1, 0 )
( 1, 1, 0, 1 )
y = ( 26, 12, 7 )
( 9, 21, 15 )
( 5, 14, 41 )
( 40, 17, 8 )
( 17, 15, 12 )
( 8, 15, 18 )
----- cnt = 0 -----
pi = ( 0.577778, 0.266667, 0.155556 )
( 0.2, 0.466667, 0.333333 )
( 0.0833333, 0.233333, 0.683333 )
( 0.615385, 0.261538, 0.123077 )
( 0.386364, 0.340909, 0.272727 )
( 0.195122, 0.365854, 0.439024 )
Equation System :
(-62.6857)x0 + (-31.9524)x1 + (-21.0864)x2 + (-20.2455)x3 + (31.2019)x4 + (12.7686)x5 + (11.0909)x6 + (16.152)x7 = 14.0668
(-31.9524)x0 + (-31.9524)x1 + (-9.88636)x2 + (-9.5122)x3 + (12.7686)x4 + (12.7686)x5 + (4.09091)x6 + (6.58537)x7 = 6.5478
(-21.0864)x0 + (-9.88636)x1 + (-21.0864)x2 + (0)x3 + (11.0909)x4 + (4.09091)x5 + (11.0909)x6 + (0)x7 = -6.10144
(-20.2455)x0 + (-9.5122)x1 + (0)x2 + (-20.2455)x3 + (16.152)x4 + (6.58537)x5 + (0)x6 + (16.152)x7 = 8.43913
(31.2019)x0 + (12.7686)x1 + (11.0909)x2 + (16.152)x3 + (-54.7347)x4 + (-25.8402)x5 + (-18.7273)x6 + (-23.0809)x7 = -2.35318
(12.7686)x0 + (12.7686)x1 + (4.09091)x2 + (6.58537)x3 + (-25.8402)x4 + (-25.8402)x5 + (-8.72727)x6 + (-10.0976)x7 = 7.97945
(11.0909)x0 + (4.09091)x1 + (11.0909)x2 + (0)x3 + (-18.7273)x4 + (-8.72727)x5 + (-18.7273)x6 + (0)x7 = 3.35057
(16.152)x0 + (6.58537)x1 + (0)x2 + (16.152)x3 + (-23.0809)x4 + (-10.0976)x5 + (0)x6 + (-23.0809)x7 = -21.5174
Regression equation : y[0] = -0.594729x0 + -0.381807x1 + 1.13426x2 + 1.58749x3
Regression equation : y[1] = -1.03114x0 + -0.803674x1 + 1.46287x2 + 2.9008x3
----- cnt = 1 -----
pi = ( 0.524023, 0.28911, 0.186867 )
( 0.23501, 0.40309, 0.3619 )
( 0.098186, 0.264972, 0.636842 )
( 0.650933, 0.24515, 0.103917 )
( 0.349621, 0.409351, 0.241028 )
( 0.174038, 0.32061, 0.505352 )
Equation System :
(-63.3591)x0 + (-31.5974)x1 + (-21.4658)x2 + (-20.6163)x3 + (31.7604)x4 + (12.64)x5 + (10.9058)x6 + (16.7676)x7 = 14.4935
(-31.5974)x0 + (-31.5974)x1 + (-10.6384)x2 + (-8.93059)x3 + (12.64)x4 + (12.64)x5 + (4.34126)x6 + (6.64286)x7 = 7.13147
(-21.4658)x0 + (-10.6384)x1 + (-21.4658)x2 + (0)x3 + (10.9058)x4 + (4.34126)x5 + (10.9058)x6 + (0)x7 = -6.14966
(-20.6163)x0 + (-8.93059)x1 + (0)x2 + (-20.6163)x3 + (16.7676)x4 + (6.64286)x5 + (0)x6 + (16.7676)x7 = 8.99699
(31.7604)x0 + (12.64)x1 + (10.9058)x2 + (16.7676)x3 + (-55.4565)x4 + (-24.3506)x5 + (-18.4408)x6 + (-24.1253)x7 = -4.94817
(12.64)x0 + (12.64)x1 + (4.34126)x2 + (6.64286)x3 + (-24.3506)x4 + (-24.3506)x5 + (-8.04907)x6 + (-10.2488)x7 = 6.37968
(10.9058)x0 + (4.34126)x1 + (10.9058)x2 + (0)x3 + (-18.4408)x4 + (-8.04907)x5 + (-18.4408)x6 + (0)x7 = 2.62442
(16.7676)x0 + (6.64286)x1 + (0)x2 + (16.7676)x3 + (-24.1253)x4 + (-10.2488)x5 + (0)x6 + (-24.1253)x7 = -22.8294
Regression equation : y[0] = -0.590797x0 + -0.388125x1 + 1.12827x2 + 1.5877x3
Regression equation : y[1] = -1.03902x0 + -0.813x1 + 1.47805x2 + 2.91668x3
----- cnt = 2 -----
pi = ( 0.524195, 0.290344, 0.185461 )
( 0.234584, 0.40153, 0.363886 )
( 0.0975796, 0.264427, 0.637993 )
( 0.652471, 0.245143, 0.102386 )
( 0.350992, 0.407527, 0.241481 )
( 0.174276, 0.32035, 0.505374 )
Equation System :
(-63.3346)x0 + (-31.5786)x1 + (-21.4374)x2 + (-20.5971)x3 + (31.7196)x4 + (12.5992)x5 + (10.905)x6 + (16.7599)x7 = 14.5863
(-31.5786)x0 + (-31.5786)x1 + (-10.6237)x2 + (-8.92676)x3 + (12.5992)x4 + (12.5992)x5 + (4.33004)x6 + (6.63776)x7 = 7.17966
(-21.4374)x0 + (-10.6237)x1 + (-21.4374)x2 + (0)x3 + (10.905)x4 + (4.33004)x5 + (10.905)x6 + (0)x7 = -6.13127
(-20.5971)x0 + (-8.92676)x1 + (0)x2 + (-20.5971)x3 + (16.7599)x4 + (6.63776)x5 + (0)x6 + (16.7599)x7 = 9.00441
(31.7196)x0 + (12.5992)x1 + (10.905)x2 + (16.7599)x3 + (-55.3536)x4 + (-24.2819)x5 + (-18.4757)x6 + (-24.1063)x7 = -5.07926
(12.5992)x0 + (12.5992)x1 + (4.33004)x2 + (6.63776)x3 + (-24.2819)x4 + (-24.2819)x5 + (-8.05939)x6 + (-10.2488)x7 = 6.25696
(10.905)x0 + (4.33004)x1 + (10.905)x2 + (0)x3 + (-18.4757)x4 + (-8.05939)x5 + (-18.4757)x6 + (0)x7 = 2.62152
(16.7599)x0 + (6.63776)x1 + (0)x2 + (16.7599)x3 + (-24.1063)x4 + (-10.2488)x5 + (0)x6 + (-24.1063)x7 = -22.7995
Regression equation : y[0] = -0.590799x0 + -0.388128x1 + 1.12827x2 + 1.58771x3
Regression equation : y[1] = -1.03908x0 + -0.813018x1 + 1.47811x2 + 2.91675x3
Estimated regression equation
y[0] = -0.590799x0 + -0.388128x1 + 1.12827x2 + 1.58771x3
variance of a[0] = ( 0.0806426, 0.0903072, 0.116722, 0.162328 )
y[1] = -1.03908x0 + -0.813018x1 + 1.47811x2 + 2.91675x3
variance of a[1] = ( 0.109228, 0.103064, 0.160738, 0.178863 )
Estimated probability
pi = ( 0.524195, 0.290344, 0.185461 )
( 0.234584, 0.40153, 0.363886 )
( 0.0975796, 0.264427, 0.637993 )
( 0.652471, 0.245143, 0.102386 )
( 0.350992, 0.407527, 0.241481 )
( 0.174276, 0.32035, 0.505374 )
瓤牲借妄は话搀で箭芦し、呵稿に夸年冯蔡が叫蜗されます。夸年澄唯は借妄箕に纷换しているので、稿で纷换する涩妥はなくそのまま鲁けて叫蜗されます。その冯蔡は肌のようになりました。
| 拉侍 | 钳勿(盒) | 瓤炳 | 纷 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||||||||||
| 夸年澄唯 | 碰てはめ猛 | 悸卢猛 | ピアソン荒汗 | 夸年澄唯 | 碰てはめ猛 | 悸卢猛 | ピアソン荒汗 | 夸年澄唯 | 碰てはめ猛 | 悸卢猛 | ピアソン荒汗 | |||
| 谨拉 | 18-23 | 0.5242 | 23.59 | 26 | 0.4965 | 0.2903 | 13.07 | 12 | -0.2948 | 0.1855 | 8.35 | 7 | -0.4658 | 45 |
| 24-40 | 0.2346 | 10.56 | 9 | -0.4790 | 0.4015 | 18.07 | 21 | 0.6896 | 0.3639 | 16.37 | 15 | -0.3398 | 45 | |
| >40 | 0.0976 | 5.85 | 5 | -0.3533 | 0.2644 | 15.87 | 14 | -0.4684 | 0.6380 | 38.28 | 41 | 0.4397 | 60 | |
| 盟拉 | 18-23 | 0.6525 | 42.41 | 40 | -0.3702 | 0.2451 | 15.93 | 17 | 0.2670 | 0.1024 | 6.66 | 8 | 0.5213 | 65 |
| 24-40 | 0.3510 | 15.44 | 17 | 0.3960 | 0.4075 | 17.93 | 15 | -0.6922 | 0.2415 | 10.63 | 12 | 0.4218 | 44 | |
| >40 | 0.1743 | 7.15 | 8 | 0.3197 | 0.3204 | 13.13 | 15 | 0.5148 | 0.5054 | 20.72 | 18 | -0.5976 | 41 | |
| 企捐下 | 0.997 | 1.597 | 1.333 | 3.927 | ||||||||||
瓤炳の婶尸は 1 が≈D : 脚妥でない∽または≈C : あまり脚妥でない∽、2 が≈B : 脚妥∽、そして 3 が≈A : 润撅に脚妥∽になります。称瓤炳に滦し、サンプルˇプログラムで评られた夸年澄唯とそれによる碰てはめ猛 ( e )、悸卢猛 ( o )、呵稿にピアソン荒汗 ( o - e ) / √e を绩してあります。布眉の≈企捐下∽乖は、ピアソン荒汗の企捐下を纷换した冯蔡を绩しています。宝眉の误にある≈纷∽は称瓤炳の碰てはめ猛または悸卢猛の圭纷ですが、呵も宝布の眶猛はピアソン荒汗の企捐下の圭纷を山しており、これは≈ピアソンˇカイ企捐琵纷翁 (Pearson Chi-squared Statistic)∽と霹しくなります。
碰てはめ猛から评られる呵络滦眶锑刨は
| l( π | y ) | = | Σi{1ⅹN}( Σk{1ⅹC}( yiklog( πik ) ) + log ni! - Σk{1ⅹC}( log yik! ) ) |
| = | Σi{1ⅹN}( Σk{1ⅹC}( yiklog( πik ) ) ) + K |
に夸年澄唯 πik を洛掐することで滇められます。芒し、πik に巴赂しない灌は年眶灌 K で山しています。呵络モデルは πik = yik / ni となることは黎揭した奶りです。また呵井モデルは、称カテゴリに滦する澄唯が i に巴赂しない ( すなわち πik = πk ) と雇えればよいので、
| l( π | y ) | = | Σi{1ⅹN}( Σk{1ⅹC}( yiklog( πk ) ) ) + K |
| = | Σk{1ⅹC}( Σi{1ⅹN}( yik )log( πk ) ) + K | |
| ≡ | Σk{1ⅹC}( Yklog( πk ) ) + K |
より ( 芒し、Yk = Σi{1ⅹN}( yik ) としています )、πk による市腮尸 ∂l / ∂πk は
で滇められます。ここでも π1 = 1 - Σk'{2ⅹC}( πk' ) であることから
となり、これがゼロのとき
となります。Σk{1ⅹC}( πk ) = 1 より
となるので、
と滇めることができて、
という冯蔡が评られます。つまり、称カテゴリごとの另眶を链ての另眶で充った猛を蝗えばよいことになります。
叹盗ロジスティックˇモデルを蝗って滇めた夸年澄唯から纷换した滦眶锑刨を lα とすると、サンプルˇデ〖タにおける猛は -25.37 になります。また、呵络モデルに滦する滦眶锑刨 lmax = -23.40、呵井モデルの眷圭 lmin = -64.29 となるので、滦眶锑刨琵纷翁 D と锑刨孺カイ企捐琵纷翁 C は
D = 2 x ( lmax - lα ) = 3.94
C = 2 x ( lα - lmin ) = 77.84
と滇められます。また、导击 R2 猛は
で滇められますが、ここでの滦眶锑刨 lmin, lα は年眶灌を近く涩妥があるので(*3-1)、その猛は lmin = -329.27, lα = -290.35 となって、
という冯蔡になります。税下モデルでのパラメ〖タ眶は、拉侍 X 钳勿(话硷梧) = 6 改の恃眶それぞれに滦して答洁カテゴリを近く企硷梧のカテゴリ(瓤炳)があったので圭纷 12 改です。叹盗ロジスティックˇモデルでは犯眶が 8 つあり、呵井モデルでは 2 つになります。骄って、D は极统刨が 12 - 8 = 4、C は极统刨が 8 - 2 = 6 の χ2-尸邵に敛夺弄に骄い、それぞれの p 猛は 0.4144, 9.966E-15 となるので、叹盗ロジスティックˇモデルは呵井モデルよりもデ〖タに滦して铜罢に努圭しており、税下モデルと孺秤してもうまくデ〖タを山せていることが绩されています。その瓤烫、导击 R2 猛は 0.1182 と你く、このモデルはデ〖タの链恃瓢の 11.82% 镍刨しか棱汤できていないことになります。
澄唯の孺 ρik = πik / πi1 は≈オッズ (Odds)∽と钙ばれます。ギャンブルなどでもよく蝗われる脱胳ですが、その眷圭は尽った箕に毁失われる翁を罢蹋し、泣塑の顶窍などでは失提垛の擒唯を山しています。C = 2 の眷圭、オッズは πi / ( 1 - πi ) となり、その滦眶はロジット簇眶そのものになります。
企つのオッズ ρik = πik / πi1 と ρlk = πlk / πl1 の孺を≈オッズ孺(Odds Ratio)∽といいます。ρik と ρlk の滦眶が俐妨簇犯
log( ρik ) = xiTαk
log( ρlk ) = xlTαk
にあるとき、オッズ孺の滦眶は
となるので、もし αk がゼロベクトルに夺い眷圭、オッズ孺は 1 に夺い猛になるはずです。毋えば、帽姐な毋として xi = ( 1, 1 )T、xl = ( 1, 0 )T の眷圭を雇えると、
log( ρik ) = αk0 + αk1
log( ρlk ) = αk0
となるので、オッズ孺の滦眶は
であり、αk1 = 0 ならば ρik / ρlk = 1 です。迫惟恃眶の妈办喇尸が年眶灌、妈企喇尸が妥傍の铜痰を山しているとすれば、オッズ孺が 1 ならば妥傍の铜痰に滦して券栏澄唯が逼读しないことを山します。また、オッズ孺が 1 より络きければ αk1 > 0 であり妥傍によって澄唯は惧がる饭羹に、嫡に 1 より井さければ澄唯は井さくなる饭羹にあることも粕み艰ることができます。
サンプルデ〖タにおける迫惟恃眶は肌のような菇喇になっていました。
| i | 年眶灌 | 拉侍 | 钳勿 24-40 | 钳勿 >40 |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 1 | 0 |
| 3 | 1 | 0 | 0 | 1 |
| 4 | 1 | 1 | 0 | 0 |
| 5 | 1 | 1 | 1 | 0 |
| 6 | 1 | 1 | 0 | 1 |
この山から、i = 4 の i = 1 に滦するオッズ孺は拉侍に滦する逼读を、また i = 2, 3 の i = 1 に滦するオッズ孺は钳勿に滦する逼读をそれぞれ山すことがわかります。これらを纷换した冯蔡は肌のようになります。
| 瓤炳 | B | A |
|---|---|---|
| 拉侍 | 0.678 | 0.444 |
| 钳勿 24-40 | 3.090 | 4.384 |
| 钳勿 >40 | 4.892 | 18.48 |
拉侍による逼读については、盟拉の数が谨拉よりもエアコンやパワ〖ステアリングを脚浑しない饭羹にあることがわかります。また、钳勿に簇しては、惧竞するほど脚妥浑する饭羹が动くなることがはっきりと粕み艰れます。これらの猛は年眶灌笆嘲の犯眶 αkj を蝗って exp( αkj ) から滇めることもできます。称犯眶の尸欢はフィッシャ〖攫鼠乖误から评ることができて、犯眶が赖惮尸邵に敛夺弄に骄うことから 95% 慨完惰粗は 士堆 ± 1.96 x 筛洁疙汗(S.E.) を纷换すれば滇められ、肌のような冯蔡になります。
| 瓤炳 | B | A |
|---|---|---|
| 拉侍 | [ 0.376, 1.222 ] | [ 0.236, 0.832 ] |
| 钳勿 24-40 | [ 1.582, 6.037 ] | [ 1.998, 9.621 ] |
| 钳勿 >40 | [ 2.221, 10.777 ] | [ 8.067, 42.34 ] |
拉侍による汗佰については、B に滦して惰粗が 1 を崔んでおり、A はそうではないものの、呵络猛は 1 に夺くなっています (悸狠、慨完刨を 99% にすれば 1 を崔むようになります)。よって、拉侍による汗佰についてははっきりとあると们咐することはできません。
*3-1) 驴灌尸邵において、N = 1 で y が企猛恃眶 ( 0 または 1 ) からなるベクトルとすれば、P1,π( y ) = Πk( πk ) であり、滦眶锑刨の年眶灌はゼロになります。企灌尸邵によるモデルにおいて、回眶房尸邵虏をベルヌ〖イ尸邵と雇えた箕、年眶灌が久糖するのと柒推は票じです。ロジスティックモデルの眷圭、回眶房尸邵虏は企灌尸邵や驴灌尸邵とはせずに、ベルヌ〖イ尸邵や、そのカテゴリが话つ笆惧になった眷圭の尸邵と雇えるのが奶撅のようです。
ロジスティックˇモデルにおける帮忙刨荒汗は肌のように山されるのでした。
di が悸眶になるためには、士数含の面咳がゼロ笆惧でなければなりません。ロジスティックˇモデルの眷圭は喇り惟つことが笆布のように沮汤できます。
y^i を恃眶とする笆布の簇眶を年盗します。yi は年眶としておきます。
瞥簇眶を纷换すると
なので、f'( y^i ) = 0 のとき y^i = yi となり、f( yi ) は端猛となります。企超瞥簇眶は
であり、yi ≥ 0 かつ ni - yi ≥ 0 ならば撅に f''( y^i ) ≥ 0 となるので、f( yi ) は端井猛になります。呵稿に、f( yi ) = 0 より f( y^i ) ≥ 0 が喇り惟ちます。
叹盗ロジスティックˇモデルの眷圭、滦眶锑刨は
となります。芒し、N は迫惟恃眶の眶、C はカテゴリ眶で、i 戎誊の迫惟恃眶の k 戎誊のカテゴリに滦し、yik が券栏搀眶、πik が券栏澄唯を山します。また、ni は i 戎誊の迫惟恃眶の另券栏搀眶で Σk{1ⅹC}( yik ) = ni を塔たします。
税下モデルの眷圭は πik = yik / ni のとき呵络滦眶锑刨となるので、帮忙刨荒汗が纷换できるとすれば
で纷换できますが、荒前ながら log( yik / ni ) ≥ log πik が撅に喇り惟つわけではないので叹盗ロジスティックˇモデルの眷圭は帮忙刨荒汗は纷换できない眷圭があります。
![[Go Back]](../images/back1.png) 涟に提る 涟に提る |
![[Back to HOME]](../images/home1.png) タイトルに提る タイトルに提る |