前章に引き続き、「ハフマン符号化 ( Huffman Coding )」について説明します。
前章では静的ハフマン圧縮と符号表の表現方法について紹介しましたが、この章ではハフマン符号を正規化する方法と、符号表を残さなくても元のデータに変換することが可能になる「動的ハフマン圧縮 ( 適応型ハフマン符号法 ; Adaptive Huffman Coding)」を紹介します。
前回は符号表を表現する方法として、符号とその長さを配列に格納するやり方と、木構造の形のままで保持するやり方の二つを紹介しましたが、三つめとして、符号そのものは残さずにその長さのみを保持するやり方を紹介します。これが実現できると、バイト列 ( 0 - 255 ) に対して符号は最大 255 ビットで表現できるようになり、その長さは 1 バイトで収めることができるので、符号表に必要なエリアは 256 バイトだけになります。
この方法を利用するには、ハフマン木を、接頭符号の形を損なうことなく変形させる必要があります。この処理を文献では「ハフマン符号の正規化」と名付けていますが、一般的にどう呼ばれているのかは不明です。
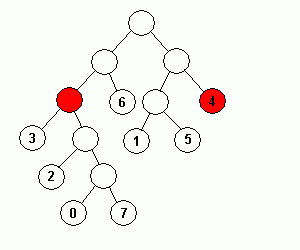
具体的には、同じレベルの節をその下の部分木ごと交換して、ハフマン木の右側 ( 左側でも可 ) ほどレベルが深くなるようにしてから、同じレベルにある葉の中のデータを左側から昇順で並べ替えるだけです。
| 1 | 2 | 3 |
|---|---|---|
|
|
|
| データ | 元の接頭符号 | 正規化した接頭符号 |
|---|---|---|
| 4 | 11 | 00 |
| 6 | 01 | 01 |
| 1 | 100 | 100 |
| 3 | 000 | 101 |
| 5 | 101 | 110 |
| 2 | 0010 | 1110 |
| 0 | 00110 | 11110 |
| 7 | 00111 | 11111 |
上の例では、赤で塗られた同レベルの節を入れ替えて木の右側ほどレベルが深くなるようにしてから、黄色で塗られた同レベルの葉を入れ替えてデータ番号が昇順に並ぶようにしています。
正規化によって得られたハフマン符号には強い規則性が見られます。最も符号長が短く、かつデータの一番若い葉は全てのビットが 0 になり、逆に符号長が最も長く、かつデータが最大の葉は全てのビットが 1 になります。符号長の等しい葉の符号は、データの若いものから順に 1 ずつ増えていき、符号長が 1 ビット長くなると、符号に 1 を加えた後で末尾に 0 を付加した形になっていることが上の例からもわかると思います。
この規則性を利用して、次のような手順で符号長からハフマン符号を再現させることができます。
ハフマン符号の正規化を行うためのサンプル・プログラムを以下に示します。
// ハフマン符号の型 typedef unsigned int HuffmanCode; // ハフマン符号長の型 typedef unsigned char HuffmanLen; // ハフマン符号型変数の構成 struct HuffmanCodeType { HuffmanCode code; // 符号 HuffmanLen len; // 符号長 // コンストラクタ HuffmanCodeType( HuffmanCode c, HuffmanLen l ) : code( c ), len( l ) {} }; /* LessHuffmanCode : ハフマン符号どうしの比較関数オブジェクト 符号長の長い方を"大"とする 符号長が等しい場合は符号化される値そのものを比較する */ template<class T> class LessHuffmanCode { typedef typename std::pair<T,HuffmanCodeType> PairHuffman; public: // c1 の方が小さい場合は true を返す bool operator()( const PairHuffman& c1, const PairHuffman& c2 ) const { if ( c1.second.len != c2.second.len ) return( c1.second.len < c2.second.len ); else return( c1.first < c2.first ); } }; /* NormalizeHuffmanCode : ハフマン符号 huffmanCode を正規化する huffmanCode は符号 ( code ) のみが置き換えられ、他の要素は変化しない。 また、符号 ( code ) そのものは処理の中では利用されない。 そのため huffmanCode の中に符号長と要素さえあれば元の符号が復元できる。 */ template<class T> void NormalizeHuffmanCode ( std::map<T,HuffmanCodeType>* huffmanCode ) { typedef typename std::map<T,HuffmanCodeType>::iterator MapIt; typedef typename std::vector< std::pair<T,HuffmanCodeType> >::const_iterator VecCit; // ハフマン符号(map)を正規化符号配列(vector)へコピーして並べ替え std::vector< std::pair<T,HuffmanCodeType> > vec( huffmanCode->begin(), huffmanCode->end() ); std::sort( vec.begin(), vec.end(), LessHuffmanCode<T>() ); if ( huffmanCode->size() == 0 ) return; VecCit cit = vec.begin(); // 正規化符号への現在の反復子 HuffmanLen len = ( cit->second ).len; // 現在の符号の符号長 HuffmanCode code = 0; // 正規化符号 for ( ; cit != vec.end() ; ++cit ) { // 符号長が変化したら符号を差分だけビットシフト if ( len < ( cit->second ).len ) { code <<= ( cit->second ).len - len; len = ( cit->second ).len; } // 符号を正規化符号へ変換 MapIt it = huffmanCode->find( cit->first ); ( it->second ).code = code++; } }
前章では、ハフマン符号用変数の中に符号長もまとめて保持する方式を採用していましたが、符号長のみ保持すれば復元ができるので、ここでは符号と符号長を別々の変数で保持するように変更します。それらを保持する構造体として新たに HuffmanCodeType を用意しています。ハフマン木からハフマン符号への変換・逆変換や、データの符号化において符号と符号長の処理内容を見直す必要がありますが、引数の変更や、ビットシフトからメンバ変数へのアクセスに切り替える作業だけで済むので対応はそれほど難しくありません。
正規化処理は NormalizeHuffmanCode で行います。引数の huffmanCode は符号化する値と正規化前のハフマン符号を保持した STL ( Standard Template Library ) のコンテナ・クラス map へのポインタです。まずはこの内容を可変長配列 vector 型の変数 vec へコピーして、関数オブジェクト LessHuffmanCode を比較用関数として STL の sort 関数で並べ替えをしています。LessHuffmanCode はまず符号長を比較し、符号長が等しい場合は符号化される値そのものを比較します。sort 関数はデフォルトで値の大小から並べ替えをしますが、三つ目の引数に要素比較用の関数を渡すことで任意の条件で並べ替えを行うことが可能で、ここではその典型的な利用方法を示しています。
並べ替えた後、その先頭から順に要素を取得して正規化符号を割り当てていきます。この処理の中で元の符号は全く利用していないので、必要なデータは符号化される値と符号の長さのみです。従って、データとしてこの二つさえ記録しておけば、符号がなくても復号することが可能であることを意味します。符号長の型は unsigned char ( 通常 8 ビット ) としているので、そのまま保持したとしても (要素数) x ( 値の大きさ + 8 ) ビットの領域があれば符号表として保持することができます。さらに、最大符号長がわかっていれば、より小さな領域に符号長を保持することで符号表をより小さくすることも可能です。
静的ハフマン符号化では、まずデータ毎の出現数をカウントしてからハフマン木を作成して符号化を行っていました。最初に全てのデータを読み込んでから処理を行うことになるため、データを逐次読み込みながら同時に符号化を行うようなことは不可能です。また、処理後の符号を保持する必要があることから、データ量はその分若干増えることになります。この問題は、全データの頻度解析をしてからハフマン木の作成を行う以上、避けることのできないものです。この前処理を省略することはできるのでしょうか。
まず、ハフマン木の作成をせずに、はじめから各データに対するハフマン符号を決めておく方法が考えられます。しかし、よほど特殊な用途に限定しない限り、どのデータにも対応させることなど不可能です。様々なパターン用のハフマン符号を作っておいて、最も圧縮率の高いものを利用するようにするのはどうでしょうか。しかしこれも全てのデータに対応することなど不可能に近く、圧縮率の高いハフマン符号を選択するために、全てのパターンに対して一度圧縮をしなければならないので処理時間にも影響が及びます。
しかし、このやり方はテキストファイルに利用できます。アルファベットの出現比率は、普通の英文の場合 'E' が最も高く、逆に 'Q' や 'J' などはほとんど使われなくなります。この性質を利用して、あらかじめハフマン符号を固定しておくのも一つの手でしょう。ただ、この方式ですと、日本語などの多バイト文字には対応できません。
ハフマン木の作成とデータの圧縮処理を同時に行うのはどうでしょうか。データを一つ読み込む毎にハフマン木を更新し、その時のハフマン木を使って符号化するようにしても、データ圧縮は可能です。
データの展開はどうでしょうか。符号を読み込みながらハフマン木を作成し、初めて出現した符号であったのならば、データ列 ( または別のエリア ) からその符号に対するデータを読み込みます ( 初めて符号化されたデータは、その符号の次に格納するのが一番処理しやすいでしょう )。そうやって、逐次符号を取り出しながらハフマン木を更新して、対応する符号からデータを決定していけば展開も可能です。
このやり方ならば、ハフマン符号を符号表などにまとめる必要はなく ( 対応するデータが埋め込まれるだけで、圧縮率にはほとんど影響しません )、さらにデータを読み込みながら同時に圧縮を行うことも可能になります。
このようなハフマン符号化を「動的ハフマン符号法 ( Dynamic Huffman Coding )」または「適応型ハフマン符号法 ( Adaptive Huffman Coding )」といいます ( 海外では後者の言い方が一般的に使われるようです )。それに対して、前回のような符号法は「静的ハフマン符号法 ( Static Huffman Coding)」と呼ばれています。
適応型ハフマン圧縮の処理の流れを以下に示します。
圧縮データを展開する処理の流れは以下のようになります。
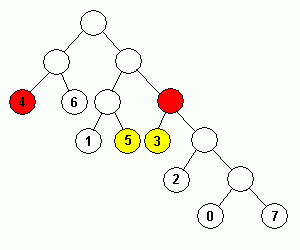
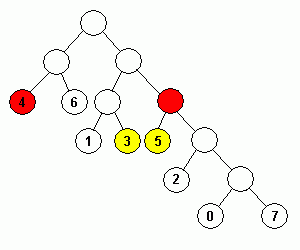
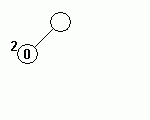
| 初期状態 | 符号 0, データ 0 を出力 | 符号 0 を出力 | 符号 1, データ 1 を出力 |
|---|---|---|---|
 |
 |
 |
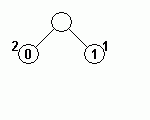 |
| 符号 11, データ 2 を出力 | 符号 10 を出力 | 符号 10 を出力 | |
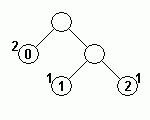 |
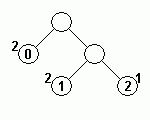 |
 |
上記ハフマン木の、節を表す円中にある数値がデータを、その左上の数値は出現回数を示しています。
ハフマン木の更新前に符号を出力しているところに注意してください。更新後の符号を出力してしまうと、後で正常な復元ができなくなります。
適応型ハフマン符号化の処理方法はわかりましたが、ハフマン木の更新はどのようにすればいいでしょうか。データを読み込む度に、静的ハフマン圧縮法と同じやり方でハフマン木をはじめから作り直しているのでは、処理時間が大幅に増えてしまうことは容易に想像できます。適応型ハフマン符号化は「Newton Faller」と「Robert G. Gallager」によって 1970 年代に考案されましたが、その後「Donald E. Knuth」によって改良が加えられ高速化されています。この手法を、それぞれの名前の頭文字から「FGK 符号化 (FGK Algorithm)」といいます。
この手法は、ハフマン木が成り立つための必要十分条件として
が成り立つことを利用しています。この条件は「兄弟条件」と呼ばれています。
ここで言う重みとは各データの出現回数を表わし、葉ではない節の部分では二つの子の節の重みの和となります。つまり、根は全ての葉の重みを合計した値を持つことになります。「静的ハフマン圧縮」でハフマン木を作成するときに行った処理を思い浮かべてもらえば、ハフマン木がこの兄弟条件を満たしていることは理解できると思います。
「FGK 符号化」の処理は以下のような流れになります。
5 番目の、重みが等しい節どうしの交換処理がミソで、交換を行ってもその上位にある節の重みには変化はないため、重みを再計算する必要はありません。その後に、重みに 1 を加えていた時点で、重みは交換された側の節よりも大きくなるので、重みの大きな節に対して符号長が小さくなるように更新することができます。
重みが等しい節を探す場合、根の節から順に比較をしながら下側へたどる操作が必要になります。すぐに対象の節が見つかればよいのですが、重みが等しい節がない場合は末尾まで探索を行うことになり、データを読み込む度にこれを毎回繰り返すのは非常に時間がかかります。また、節の交換がある度に通し番号を毎回付け直すことも非常に時間がかかるので、これらの処理に対して何らかの手段を考える必要があります。
適応型ハフマン符号化 ( FGK符号化 ) を行う関数群は共通のデータを多く利用するため、一つのクラスにまとめておきます。まずは、その定義内容を以下に示します。
// ハフマン木の節を表す構造体 template<typename T> struct HuffmanTreeNode { // 子の節の添字(節番号)に対する型 typedef typename std::vector< HuffmanTreeNode<T> >::size_type size_type; T value; // 値 size_t count; // 出現頻度 size_type left; // 左の子の節番号 size_type right; // 右の子の節番号 size_type parent; // 親の節番号 HuffmanCodeType code; // 符号とその長さ /* コンストラクタ */ /// 全要素を指定して構築 /// /// t 値 /// c 出現頻度 /// l 左の子の節番号 /// r 右の子の節番号 HuffmanTreeNode( T t, size_t c, size_type l, size_type r, size_type p = 0 ) : value( t ), count( c ), left( l ), right( r ), parent( p ), code( 0, 0 ) {} /* メンバ関数 */ /// 節の大小関係を評価する /// /// 自分自身が引数の節よりも小さければ true を返す。 /// 大小関係は出現頻度 count で評価する。 /// /// dest 比較対象の節 bool operator<( const HuffmanTreeNode& dest ) const { return( count < dest.count ); } }; /* HuffmanTree : ハフマン木 T は符号化するデータの型を表す。 */ template<typename T> struct HuffmanTree { // ハフマン木の型 typedef typename std::vector< HuffmanTreeNode<T> > type; }; /* AdaptiveHuffmanCoding : 適応型ハフマン符号化処理クラス T は符号化するデータの型、Counter は各節の出現回数を保持・管理するオブジェクトの型をそれぞれ表す。 */ template<class T,template<class T> class Counter> class AdaptiveHuffmanCoding { public: // ハフマン木の型 typedef typename HuffmanTree<T>::type HuffmanTree; private: /* LessByHuffmanCode : 符号による節の大小比較関数オブジェクト */ class LessByHuffmanCode { // 比較対象の節を持つハフマン木への参照 HuffmanTree& tree_; // 比較対象外の節の添字 // 通し番号のより大きな節を探索するとき、対象の節の親が選択されることを防ぐために指定する typename HuffmanTree::size_type ignoreIdx_; public: // コンストラクタ // 比較対象の節を持つハフマン木への参照による初期化 LessByHuffmanCode( HuffmanTree& tree, typename HuffmanTree::size_type ignoreIdx ) : tree_( tree ), ignoreIdx_( ignoreIdx ) {} // operator() : st1 番目の節が st2 番目の節より「小さい」なら true を返す bool operator() ( const typename HuffmanTree::size_type& st1, const typename HuffmanTree::size_type& st2 ) const; }; HuffmanTree huffmanTree_; // ハフマン木 Counter<T> counter_; // 各節の出現回数を保持・管理するオブジェクト // setHuffmanCode : nodeIdx 番目の節に対するハフマン符号を求め、登録する void setHuffmanCode( typename HuffmanTree::size_type nodeIdx ); // addNewValue : 0-node の下に未登録の値 newValue を持つ節と新たな 0-node を追加する // 戻り値として新たな 0-node の節の添字を返す typename HuffmanTree::size_type addNewValue ( const T& newValue, typename HuffmanTree::size_type oldZeroNodeIdx ); // searchSwapNode : nodeIdx と同じカウント値を持つ通し番号最大の節の添字を返す typename HuffmanTree::size_type searchSwapNode ( typename HuffmanTree::size_type nodeIdx ); // swapNode : i1 番目と i2 番目の節を交換する void swapNode ( typename HuffmanTree::size_type i1, typename HuffmanTree::size_type i2 ); // addCounter : nodeIdx 番目の節のカウント値を 1 増加させる void addCounter( typename HuffmanTree::size_type nodeIdx ); // updateHuffmanTree : nodeIdx 番目の節からハフマン木を更新する // この中で節の交換とカウント値の増加を行う void updateHuffmanTree( typename HuffmanTree::size_type nodeIdx ); // readFromTree : ハフマン符号列を cit で始まる反復子から読み取りながら、 // ハフマン木 huffmanTree をたどって値を value に取得する typename HuffmanTree::size_type readFromTree ( typename HuffmanTree::difference_type root, std::vector<HuffmanCode>::const_iterator* cit, std::vector<HuffmanCode>::const_iterator encEnd, T* value, HuffmanCodeType* bitData ); // nullNode : 空の節を表すインデックスを返す typename HuffmanTree::size_type nullNode() const { return( huffmanTree_.max_size() ); } public: // encode : valueList のハフマン符号化を行い、ハフマン符号列を encData に書き込む void encode ( const typename std::vector<T>& valueList, std::vector<HuffmanCode>* encData ); // decode : ハフマン符号 decData を復元して result に書き込む // count はデータ数を表す void decode ( const std::vector<HuffmanCode>& decData, typename std::vector<T>::size_type count, typename std::vector<T>* result ); };
ハフマン木の節を表す HuffmanTreeNode 構造体は前回の「静的ハフマン符号化」にも登場していますが、今回はその節の符号と符号長を保持する HuffmanCodeType 型の変数 code を新たに追加しています。節の符号や符号長は処理中に頻繁に使用するので、毎回計算する処理を省くために必要になります。但し、節の交換によって符号は変化するので、その時は毎回再計算する必要があります。
HuffmanTree 構造体は、ハフマン木のデータ型を定義するだけに利用します。本来なら
template<typename T> typedef typename std::vector< HuffmanTreeNode<T> > HuffmanTree;
と書きたいところですが、テンプレート引数を含めた型の定義を typedef で行うことは今のところできないため、クラス・テンプレート内で定義してそれを利用するようにしています。また、次に説明する AdaptiveHuffmanCoding の中で定義すればよさそうに見えますが、他のクラス内でも利用したいためわざわざ外側で定義するようにしています。
AdaptiveHuffmanCoding が適応型ハフマン符号化関数をまとめたクラスの本体です。メンバ変数としてハフマン木本体の huffmanTree_ の他に counter_ があり、counter_ の型は Counter という、テンプレート引数で外側から渡される任意の型となっています。この counter_ 変数によって各節の出現回数を管理し、同じ出現回数を持った節を素早く探索できるようにします。この変数の具体的な内容は後の方で示したいと思います。
テンプレート引数が少々ややこしい書き方になっています。
Counter 型オブジェクトは T 型のテンプレート引数を持ったテンプレート・クラスになるので、テンプレートの引数の中にさらにテンプレート引数を持った形になっています。
内部クラスの LessByHuffmanCode は符号により節の大小を比較するための関数オブジェクトで、符号長の短い方が大きく、符号長が等しければ符号の大きい方が「大きい」と判定されるように処理を行います。クラス変数として対象のハフマン木への参照 (tree_) の他に比較対象外の添字 (ignoreIdx_) というものがありますが、この詳細については後述します。
外部に公開されているメンバ関数は、符号化を行うための encode と復元するための decode の二種類で、以下のような実装になっています。
/* AdaptiveHuffmanCoding<T,Counter>::setHuffmanCode : 親のノードの内容を元に、ハフマン木の nodeIdx 番目のノードに対する符号と符号長をセットする */ template<class T,template<class T> class Counter> void AdaptiveHuffmanCoding<T,Counter>::setHuffmanCode ( typename HuffmanTree::size_type nodeIdx ) { // nodeIdx に対する反復子 typename HuffmanTree::iterator node = huffmanTree_.begin() + nodeIdx; if ( node->parent != nullNode() ) { // node の親 typename HuffmanTree::iterator parent = huffmanTree_.begin() + node->parent; // noed の親から符号を計算 ( node->code ).code = ( parent->code ).code * 2; ( node->code ).len = ( parent->code ).len + 1; if ( parent->right == nodeIdx ) ++( ( node->code ).code ); } // 子に対して再帰的に処理 if ( node->left != nullNode() ) setHuffmanCode( node->left ); if ( node->right != nullNode() ) setHuffmanCode( node->right ); } /* AdaptiveHuffmanCoding<T,Counter>::addNewValue : oldZeroNodeIdx を添え字に持つ0-node の下に新たな 0-node と 値 newValue を持つ節を追加し、新たな 0-node への添字を返す */ template<class T,template<class T> class Counter> typename AdaptiveHuffmanCoding<T,Counter>::HuffmanTree::size_type AdaptiveHuffmanCoding<T,Counter>::addNewValue ( const T& newValue, typename HuffmanTree::size_type oldZeroNodeIdx ) { // 左側に新たな 0-node を追加 huffmanTree_.push_back( HuffmanTreeNode<T>( T(), 0, nullNode(), nullNode(), oldZeroNodeIdx ) ); huffmanTree_[oldZeroNodeIdx].left = huffmanTree_.size() - 1; setHuffmanCode( huffmanTree_.size() - 1 ); // 右側に新たな色成分を追加 huffmanTree_.push_back( HuffmanTreeNode<T>( newValue, 0, nullNode(), nullNode(), oldZeroNodeIdx ) ); huffmanTree_[oldZeroNodeIdx].right = huffmanTree_.size() - 1; setHuffmanCode( huffmanTree_.size() - 1 ); return( huffmanTree_[oldZeroNodeIdx].left ); } /* AdaptiveHuffmanCoding<T,Counter>::encode : 適応型ハフマン符号圧縮 */ template<class T,template<class T> class Counter> void AdaptiveHuffmanCoding<T,Counter>::encode ( const typename std::vector<T>& valueList, std::vector<HuffmanCode>* encData ) { // MapIndex : 値と節に対する添字を登録する Map コンテナの型 typedef typename std::map<T,typename std::vector< HuffmanTreeNode<T> >::size_type> MapIndex; // ハフマン木は一つの 0-node で初期化 huffmanTree_.assign( 1, HuffmanTreeNode<T>( T(), 0, nullNode(), nullNode(), nullNode() ) ); // 0-node の添字 typename HuffmanTree::size_type zeroNodeIdx = 0; // 値と節に対する添字を登録する Map コンテナ MapIndex treeIdx; if ( &valueList == 0 || encData == 0 ) return; // カウンタと出力先の初期化 counter_.clear(); encData->clear(); HuffmanCodeType bitData( 0, 0 ); // 符号化ビットのキャッシュ for ( typename std::vector<T>::const_iterator cit = valueList.begin() ; cit != valueList.end() ; ++cit ) { // 対象の値に対する節の添字を取得する typename HuffmanTree::size_type nodeIdx; typename MapIndex::iterator mapIt = treeIdx.find( *cit ); bool isFirstData = ( mapIt == treeIdx.end() ); if ( isFirstData ) { // 対象の値が初めて出現した場合は現在の 0-node の符号を取得して出力 HuffmanCodeType& code = huffmanTree_[zeroNodeIdx].code; WriteToArray( code.code, code.len, &(bitData.code), &(bitData.len), encData ); // 新たな節を追加する zeroNodeIdx = addNewValue( *cit, zeroNodeIdx ); nodeIdx = huffmanTree_.size() - 1; treeIdx.insert( typename MapIndex::value_type( *cit, nodeIdx ) ); // 初めて出現した値をそのまま出力 WriteToArray( *cit, static_cast<HuffmanLen>( sizeof(T) * CHAR_BIT / sizeof( char ) ), &(bitData.code), &(bitData.len), encData ); } else { nodeIdx = mapIt->second; // 符号を取得して出力 HuffmanCodeType& code = huffmanTree_[nodeIdx].code; WriteToArray( code.code, code.len, &(bitData.code), &(bitData.len), encData ); } // ハフマン木の更新 updateHuffmanTree( nodeIdx ); } // 残りビット列の出力 if ( bitData.len > 0 ) encData->push_back( bitData.code << ( HUFFMAN_CODE_BIT - bitData.len ) ); } /* AdaptiveHuffmanCoding<T,Counter>::decode : 適応型ハフマン符号展開 */ template<class T,template<class T> class Counter> void AdaptiveHuffmanCoding<T,Counter>::decode ( const std::vector<HuffmanCode>& decData, typename std::vector<T>::size_type count, typename std::vector<T>* result ) { // ハフマン木 huffmanTree_.assign( 1, HuffmanTreeNode<T>( T(), 0, nullNode(), nullNode(), nullNode() ) ); // 0-node の添字 typename HuffmanTree::size_type zeroNodeIdx = 0; if ( &decData == 0 || result == 0 ) return; // カウンタと出力先の初期化 counter_.clear(); result->clear(); HuffmanCodeType bitData( 0, 0 ); // 符号化ビットのキャッシュ typename std::vector<HuffmanCode>::const_iterator cit = decData.begin(); T value; for ( typename std::vector<T>::size_type i = 0 ; i < count ; ++i ) { // 符号を読み取りながらハフマン木をたどる typename HuffmanTree::size_type nodeIdx = readFromTree( 0, &cit, decData.end(), &value, &bitData ); if ( nodeIdx == nullNode() ) return; if ( nodeIdx == zeroNodeIdx ) { // 0-node にたどり着いたら値をそのままビット列から読み込んで新たな節を追加 if ( ! ReadFromArray( &cit, decData.end(), &(bitData.code), &(bitData.len), &value, static_cast<HuffmanLen>( sizeof(T) * CHAR_BIT / sizeof( char ) ) ) ) break; zeroNodeIdx = addNewValue( value, zeroNodeIdx ); nodeIdx = huffmanTree_.size() - 1; } result->push_back( value ); // ハフマン木の更新 updateHuffmanTree( nodeIdx ); } }
ハフマン木の節の交換は親子のリンクを付け替えるすることで実現できるので、節の中身そのものを交換する必要はありません。そのため、ある値に対する節を配列に追加したら、その添字は変更しないことを保証させることができます。encode の中の変数 treeIdx は値を "キー"、添字を "値" とする map 型のコンテナで、値から添字を素早く探索するために利用します。ハフマン木は「二分探索木」のように値を素早く探索できるような構成になっていないため、もしそのまま値を探索する場合は線形探索で行う必要があります。
encode では、初期化の後にデータ列 valueList から一つずつ読み込み、すでに出現している値ならその符号をそのまま配列 encData へ出力するのに対し、初めて出現した値の場合は 0-node の符号を出力してから節を新たに追加し (addNewValue)、値そのものも出力します。符号や値の出力には WriteToArray という関数を利用します。出力後にハフマン木の更新を後述する updateHuffmanTree で行い、一回のパスが終了します。
decode では、符号を decData から読み取りながらハフマン木をたどり (readFromTree)、値を持つ節に到達した場合はその値を変数 value に取り込みますが、0-node にたどり着いた場合は値が新規に出現したと判断して decData からその値を取り込み、addNewValue によって節を新規に追加します。最後に updateHuffmanTree でハフマン木を更新し、一回のパスが終了します。なお、配列から値を読み込むときは関数 ReadFromArray を利用します。
addNewValue は、0-node の子として新たな 0-node を左側に、新たな値を持つ節を右側に追加する処理を行います。二つの節は配列 huffmanTree_ の末尾に順番に追加するだけなので、末尾から二番目に新しい 0-node が登録され、末尾の要素が新たな値を持つ節になります。節を追加した後、それらの節の符号を setHuffmanCode を使って更新します。setHuffmanCode では、その節の親の符号を使って計算をするだけで、根の節までたどって計算するようなことはしていません。このように、親の節の符号があれば、子の節の符号の更新は簡単にできます。
/* W2A_PushOnce : キャッシュ bitData の残り部分を code で埋める キャッシュが満杯になった場合は encData へキャッシュを登録する length は code の長さを表す。 */ template<class Data,typename Code,typename Len> void W2A_PushOnce ( const Data& data, Len* length, Code* cacheCode, Len* cacheLen, std::vector<Code>* encData ) { const Len CODE_BIT = std::numeric_limits<Code>::digits; Len mod = CODE_BIT - *cacheLen; // キャッシュに登録可能なビット数 if ( *length >= mod ) { // キャッシュが満杯になった場合はキャッシュを出力 if ( mod == CODE_BIT ) encData->push_back( data >> ( *length - mod ) ); else encData->push_back( ( *cacheCode << mod ) | ( data >> ( *length - mod ) ) ); *cacheLen = 0; // 保持しているビット列はゼロに *length -= mod; // 登録するビット列の残りを計算 } else { // キャッシュがまだ満杯にならない場合キャッシュとそのビット長を更新 *cacheLen += *length; *cacheCode = ( *cacheCode << *length ) | data; *length = 0; // ビット列の残りはゼロに } } /* W2A_PushLoop : data をそのままデータ列 encData へ登録する length は W2A_PushOnce 登録後の残りビット列の長さを保持するとする length がキャッシュのビット長よりも長い場合、直接プッシュしてしまう */ template<class Data,typename Code,typename Len> void W2A_PushLoop ( const Data& data, Len* length, std::vector<Code>* encData ) { const Len CODE_BIT = std::numeric_limits<Code>::digits; while ( *length >= CODE_BIT ) { encData->push_back( ( data >> ( *length - CODE_BIT ) ) & ~( static_cast<Code>( Code() ) ) ); *length -= CODE_BIT; } } /* W2A_SetLastCode : data の残りビット列を bitData へ登録する length は残りビット列の長さを保持するものとする */ template<class Data,typename Code,typename Len> void W2A_SetLastCode ( const Data& data, Len length, Code* cacheCode, Len* cacheLen ) { if ( length > 0 ) { *cacheCode = data & ~( ~( static_cast<Code>( Code() ) ) << length ); // 残ったビット列をキャッシュに保持 *cacheLen = length; } } /* WriteToArray : 長さ length のデータ data を encData に書き込む bitData は途中まで書き込んだビット列を保持するキャッシュである。 data の length 以上の上位ビットは全てクリアされていることを前提として処理する。 */ template<class Data,typename Code,typename Len> void WriteToArray ( const Data& data, Len length, Code* cacheCode, Len* cacheLen, std::vector<Code>* encData ) { W2A_PushOnce( data, &length, cacheCode, cacheLen, encData ); W2A_PushLoop( data, &length, encData ); W2A_SetLastCode( data, length, cacheCode, cacheLen ); } /* RFA_GetFromCache : キャッシュ bitData から読み込める分だけ data へ取り込む bitData が空になったら *cit から新たに読み込む data は下詰めで登録される */ template<class Data,typename Code,typename Len> bool RFA_GetFromCache ( typename std::vector<Code>::const_iterator* cit, typename std::vector<Code>::const_iterator decEnd, Code* cacheCode, Len* cacheLen, Data* data, Len* length ) { const Len CODE_BIT = std::numeric_limits<Code>::digits; // キャッシュが足りない場合 if ( *cacheLen < *length ) { if ( *cit == decEnd ) return( false ); // キャッシュの残りを書き出す *data = *cacheCode & ~( ~( static_cast<Code>( Code() ) ) << *cacheLen ); // 新たなデータをキャッシュに取り込む *cacheCode = *( ( *cit )++ ); *length -= *cacheLen; // data に書き込む残りのビット数 *cacheLen = CODE_BIT; // キャッシュは満杯 // キャッシュが足りる場合 } else { *cacheLen -= *length; // キャッシュの残りを更新 if ( *length == CODE_BIT ) *data = *cacheCode; else *data = ( *cacheCode >> *cacheLen ) & ~( ( ~( static_cast<Code>( Code() ) ) ) << *length ); *length = 0; } return( true ); } /* RFA_GetLoop : *cit から直接 data へ取り込む */ template<class Data,typename Code,typename Len> bool RFA_GetLoop ( typename std::vector<Code>::const_iterator* cit, typename std::vector<Code>::const_iterator decEnd, Code* cacheCode, Len* cacheLen, Data* data, Len* length ) { const Len CODE_BIT = std::numeric_limits<Code>::digits; while ( *length >= CODE_BIT ) { *data = ( *data << CODE_BIT ) | *cacheCode; *length -= CODE_BIT; if ( *length > 0 && *cit == decEnd ) return( false ); if ( *cit != decEnd ) *cacheCode = *( ( *cit )++ ); } return( true ); } /* RFA_GetLastCode : data の未登録部分をキャッシュ bitData から取得して埋め込む */ template<class Data,typename Code,typename Len> void RFA_GetLastCode ( Data* data, Len length, Code* cacheCode, Len* cacheLen ) { const Len CODE_BIT = std::numeric_limits<Code>::digits; if ( length > 0 ) { *data = ( *data << length ) | ( *cacheCode >> ( CODE_BIT - length ) ); *cacheLen -= length; } } /* ReadFromArray : 長さ length のデータ data を *cit から取り込む bitData は途中まで読み込んだビット列を保持するキャッシュである。 */ template<class Data,typename Code,typename Len> bool ReadFromArray ( typename std::vector<Code>::const_iterator* cit, typename std::vector<Code>::const_iterator decEnd, Code* cacheCode, Len* cacheLen, Data* data, Len length ) { if ( ! RFA_GetFromCache( cit, decEnd, cacheCode, cacheLen, data, &length ) ) return( false ); if ( ! RFA_GetLoop( cit, decEnd, cacheCode, cacheLen, data, &length ) ) return( false ); RFA_GetLastCode( data, length, cacheCode, cacheLen ); return( true ); } /* DecreaseBitData : キャッシュの再読み込み キャッシュの符号長を一つ減らす。ゼロだった場合はキャッシュを更新する。 */ bool DecreaseBitData ( std::vector<HuffmanCode>::const_iterator* cit, std::vector<HuffmanCode>::const_iterator encEnd, HuffmanCodeType* bitData ) { if ( bitData->len == 0 ) { if ( *cit == encEnd ) return( false ); bitData->code = *( ( *cit )++ ); bitData->len = HUFFMAN_CODE_BIT; } --( bitData->len ); return( true ); } /* AdaptiveHuffmanCoding<T,Counter>::readFromTree : ハフマン符号列を cit で始まる反復子から読み取りながら、ハフマン木 huffmanTree をたどって値を value に取得する root はハフマン木の根を表し、encEnd はハフマン符号列のある配列の末尾の次を表す。 bitData は cit から読み込んだビット列を保持するキャッシュで、bitLen が残りのビット長を保持する。 */ template<class T,template<class T> class Counter> typename AdaptiveHuffmanCoding<T,Counter>::HuffmanTree::size_type AdaptiveHuffmanCoding<T,Counter>::readFromTree ( typename HuffmanTree::difference_type root, std::vector<HuffmanCode>::const_iterator* cit, std::vector<HuffmanCode>::const_iterator encEnd, T* value, HuffmanCodeType* bitData ) { typename HuffmanTree::iterator tree = huffmanTree_.begin() + root; // たどる開始位置は root から while ( tree->left != nullNode() || tree->right != nullNode() ) { if ( ! DecreaseBitData( cit, encEnd, bitData ) ) return( nullNode() ); if ( ( ( bitData->code >> bitData->len ) & 1 ) == 1 ) { if ( tree->right == nullNode() ) return( nullNode() ); // 右側がたどれない tree = huffmanTree_.begin() + tree->right; } else { if ( tree->left == nullNode() ) return( nullNode() ); // 左側がたどれない tree = huffmanTree_.begin() + tree->left; } } *value = tree->value; return( std::distance( huffmanTree_.begin(), tree ) ); }
配列には、符号や値のビット列がすき間なく詰められています。そのため、途中まで読み書きしたビット列は何らかの形で保持しておかなければなりません。ここでは専用のキャッシュを変数として用意して、それが満杯になったら配列へ出力したり次の要素を読み込むようにしています。ここで問題となるのがデータ列の要素のサイズが任意であるというところで、符号用の配列は HuffmanCode 型 ( ここでは unsigned int 型 ) なので、通常 4 バイトであるのに対し、データ列の要素がそれよりも大きなサイズである場合は一つの符号用配列から一度に値を読み書きすることができないことになります。従って、キャッシュの残りを処理する関数 (W2A_PushOnce, RFA_GetFromCache) と要素をそのまま代入する関数 (W2A_PushLoop, RFA_GetLoop)、末尾の余剰分を処理する関数 (W2A_SetLastCode, RFA_GetLastCode) にそれぞれ分解して順番に処理するようにしています。readFromTree の場合、キャッシュから 1 ビットずつ読み込みながらハフマン木をたどり、値のある節にたどり着いたらその値を value に取り込んで、その節の添字を返します。
ハフマン木の更新を行う部分は以下のような実装になります。
/* AdaptiveHuffmanCoding<T,Counter>::LessByHuffmanCode::operator() : ハフマン符号による大小比較 ( st1 < st2 なら true を返す ) */ template<class T,template<class T> class Counter> bool AdaptiveHuffmanCoding<T,Counter>::LessByHuffmanCode::operator() ( const typename HuffmanTree::size_type& st1, const typename HuffmanTree::size_type& st2 ) const { if ( st2 == tree_.max_size() ) return( false ); // st1, st2 に対する反復子 typename std::vector< HuffmanTreeNode<T> >::const_iterator cit1 = tree_.begin() + st1; typename std::vector< HuffmanTreeNode<T> >::const_iterator cit2 = tree_.begin() + st2; // st1 が無視すべき添字なら常に true if ( st1 == ignoreIdx_ ) return( true ); // st2 が無視すべき添字なら常に false if ( st2 == ignoreIdx_ ) return( false ); // 符号長は短い方が通し番号が大きい if ( ( cit1->code ).len != ( cit2->code ).len ) return( ( cit1->code ).len > ( cit2->code ).len ); // 同じ符号長ならば符号が大きい方が通し番号が大きい return( ( cit1->code ).code < ( cit2->code ).code ); } /* AdaptiveHuffmanCoding<T,Counter>::searchSwapNode : 同じcountで nodeIdx より上位の節を探す */ template<class T,template<class T> class Counter> typename AdaptiveHuffmanCoding<T,Counter>::HuffmanTree::size_type AdaptiveHuffmanCoding<T,Counter>::searchSwapNode ( typename HuffmanTree::size_type nodeIdx ) { /* nodeIdx 番目の節の出現回数と等しいグループへの参照を求める */ size_t count = huffmanTree_[nodeIdx].count; typename Counter<T>::CounterType::iterator it = counter_.find( count ); if ( it == counter_.end() ) // ありえないが念のため return( nullNode() ); // 比較対象のグループへの参照 typename Counter<T>::NodeIdArrayType& nodes = it->second; /* nodeIdx より上位の節から符号が最大のものを探す */ typename Counter<T>::NodeIdArrayType::iterator result = std::max_element( nodes.begin(), nodes.end(), LessByHuffmanCode( huffmanTree_, huffmanTree_[nodeIdx].parent ) ); return( ( *result == nodeIdx ) ? nullNode() : *result ); } /* AdaptiveHuffmanCoding<T,Counter>::swapNode : 節の交換 */ template<class T,template<class T> class Counter> void AdaptiveHuffmanCoding<T,Counter>::swapNode ( typename HuffmanTree::size_type i1, typename HuffmanTree::size_type i2 ) { if ( i1 == i2 ) return; // i1, i2 に対する反復子 typename std::vector< HuffmanTreeNode<T> >::iterator t1 = huffmanTree_.begin() + i1; typename std::vector< HuffmanTreeNode<T> >::iterator t2 = huffmanTree_.begin() + i2; // 親とのリンクを交換 if ( huffmanTree_[t1->parent].left == i1 ) huffmanTree_[t1->parent].left = i2; else huffmanTree_[t1->parent].right = i2; if ( huffmanTree_[t2->parent].left == i2 ) huffmanTree_[t2->parent].left = i1; else huffmanTree_[t2->parent].right = i1; std::swap( t1->parent, t2->parent ); // 符号の再計算 setHuffmanCode( i1 ); setHuffmanCode( i2 ); } /* AdaptiveHuffmanCoding<T,Counter>::addCounter : 節のカウンタを 1 増加させる */ template<class T,template<class T> class Counter> void AdaptiveHuffmanCoding<T,Counter>::addCounter ( typename HuffmanTree::size_type nodeIdx ) { // nodeIdx 番目の節のカウントへの参照 size_t& count = huffmanTree_[nodeIdx].count; // 現在 counter_ に登録されている要素をいったん削除する if ( count > 0 ) { typename Counter<T>::CounterType::iterator it = counter_.find( count ); if ( it != counter_.end() ) { typename Counter<T>::NodeIdArrayType& nodes = it->second; typename Counter<T>::NodeIdArrayType::iterator i = std::find( nodes.begin(), nodes.end(), nodeIdx ); if ( i != nodes.end() ) nodes.erase( i ); if ( nodes.size() == 0 ) counter_.erase( it ); } } ++count; // counter_ に再登録 typename Counter<T>::CounterType::iterator it = counter_.insert( count ); ( it->second ).push_back( nodeIdx ); } /* AdaptiveHuffmanCoding<T,Counter>::updateHuffmanTree : 節を交換しつつ,重さを更新する */ template<class T,template<class T> class Counter> void AdaptiveHuffmanCoding<T,Counter>::updateHuffmanTree ( typename HuffmanTree::size_type nodeIdx ) { while ( nodeIdx != 0 ) { typename HuffmanTree::size_type swapIdx = searchSwapNode( nodeIdx ); if ( swapIdx != nullNode() ) swapNode( nodeIdx, swapIdx ); addCounter( nodeIdx ); nodeIdx = huffmanTree_[nodeIdx].parent; } addCounter( nodeIdx ); }
ハフマン木の更新用関数 updateHuffmanTree は非常に短いプログラムで、searchSwapNode で同じ出現頻度を持つ通し番号のより大きな節を探し、もしあれば swapNode で交換します。その後、addCounter で出現頻度を更新し、次の節として親へ移動します。これを一回のパスとして、根の節に到達するまで (根の節は必ず先頭になります) 同じ処理を繰り返します。
searchSwapNode ではメンバ変数 counter_ が登場します。最初に、対象の節の出現回数と等しい節のグループを counter_ オブジェクトのメンバ関数 find で探索します。探索結果は反復子で返され、変数 it に代入されます。Counter クラスで定義されている型 NodeIdArrayType は it->second のそれを表しており (後述しますが、it が指し示す実体は STL にある pair 型オブジェクトで、キーが出現頻度、値が節のグループを保持した配列となっています)、その参照を nodes に代入します。この配列から、STL の関数 max_element を使って最大値を取得すれば通し番号最大の節が得られるわけですが、ここで比較処理に利用する関数オブジェクトは LessByHuffmanCode となっています。この関数オブジェクトは符号長がより短く、符号長が等しければ符号そのものが大きいものを "より大きい" と判定するのでした。実は、通し番号の大小はこの判定で決まるので、わざわざ通し番号を付ける操作は不要ということになります。LessByHuffmanCode を構築する時、対象のハフマン木への参照の他に、判定対象外とする(常に最小値とみなす)節の添字を渡し、この添字に対しては常に "より小さい" 判定がされるように処理しています。また、この添字として対象の節の親のそれを渡しています。根の節から葉までたどる間の節の中で、葉の節と出現回数が等しくなるものは存在しませんが (親の節の出現回数は二つの子の節の出現回数の和であることを思い出して下さい)、0-node を子に持つ場合は親の節ともう片側の子の節の出現回数は等しくなってしまいます。根から葉までのルート間で節を交換するとハフマン木の構成が崩れてしまうので、それを避けるためにこのような判定が必要になります。
配列の nodes に STL の map や set クラスを利用することで、あらかじめソートした状態でデータを保持しておくことが可能になり、常に末尾の要素を取得すれば済むようにできます。しかし、通し番号は節の交換によって変化するので、結局はその処理ごとに再構築する必要が生じます。ここでは、nodes として vector クラスを使い、毎回最大値を探索するようにしています。
addCounter は節の出現頻度を更新するためのメンバ関数ですが、出現頻度が変わるということは counter_ 内での移動が発生することになるので、更新前にグループからの削除を行い、更新してから新たなグループへ再登録する処理を行なっています。0-node は counter_ には登録されないため更新頻度ゼロの要素は counter_ には存在せず、削除処理のときに無視することができます。また削除した結果、グループ内の要素数がゼロになった場合は、そのグループごと削除するため counter_ オブジェクトのメンバ関数 erase を呼び出しています。
Counter 型として渡されるクラスは以下の型が定義されています。
| 型名 | 用途 |
|---|---|
| NodeIdArrayType | 出現頻度の節を保持するグループの型 |
| CounterType | 出現頻度をキー、NodeIdArrayType 型配列を値とする連想配列の型 |
CounterType 型の連想配列から出現頻度をキーに NodeIdArrayType 型配列を取得し、さらに節の添字を取得する構成となっており、それらにアクセスするために以下のメンバ関数を必要とします。
| メンバ関数 | 用途 |
|---|---|
| find | 出現頻度をキーに CounterType 型連想配列への反復子を返す |
| insert | 出現頻度が未登録なら CounterType 型連想配列へ登録した上でその反復子を返す |
| erase | CounterType 型連想配列から指定した反復子の要素を削除する |
| clear | CounterType 型連想配列の要素をすべて消去する |
| begin | CounterType 型連想配列の先頭の要素に対する反復子を返す |
| end | CounterType 型連想配列の末尾の次の要素に対する反復子を返す |
Counter はテンプレート引数なので、上記のメンバ関数が存在すればどのようなオブジェクトでも渡すことができます。このような構成にしたのは、利用する配列の形式によって処理時間が大きく左右されるので、後でより効率のよいオブジェクトに置き換えることができるようにするためです。ハフマン木の更新処理は全体のほとんどの処理時間を占める部分であり、実装の内容により処理時間に大きな影響を与えます。以下は、STL にある map クラスを利用した場合の Counter クラスです。
/* AHC_Counter_Map : 適応型ハフマン符号化処理用カウンタ・コンテナ(std::map版) */ template<class T> class AHC_Counter_Map { // ハフマン木の型 typedef typename HuffmanTree<T>::type HuffmanTree; public: // NodeIdArrayType : 節の添字を登録するコンテナの型 typedef std::vector< typename HuffmanTree::size_type > NodeIdArrayType; // CounterType : カウントと節に対する添字を登録するコンテナの型 typedef typename std::map< size_t, NodeIdArrayType > CounterType; private: CounterType counter_; // カウンタ・コンテナの実体 public: // find : count をキーとする要素の反復子を返す typename CounterType::iterator find( size_t count ) { return( counter_.find( count ) ); } // insert : count をキーとする要素がない場合追加する // 戻り値として count をキーとする要素の反復子を返す typename CounterType::iterator insert( size_t count ) { typename CounterType::iterator it = find( count ); if ( it != end() ) return( it ); else return( ( counter_.insert( typename CounterType::value_type( count, NodeIdArrayType() ) ) ).first ); } // erase : 反復子 it を消去する void erase( typename CounterType::iterator it ) { counter_.erase( it ); } // clear : 要素を全て消去する void clear() { counter_.clear(); } // begin : 開始位置の反復子を返す typename CounterType::iterator begin() { return( counter_.begin() ); } // end : 末尾の次の反復子を返す typename CounterType::iterator end() { return( counter_.end() ); } };
出現頻度の等しい節への添字を保持するコンテナ・クラス(NodeIdArrayType)として vector が、このコンテナを出現頻度をキーとして保持するコンテナ・クラス(CounterType)として map が使われ、メンバ関数は全て CounterType のコンテナ・クラスに対するアクセスに利用されます。今回は、NodeIdArrayType 型のコンテナ・クラスを全て同じ型として外側で直接アクセスしているので専用のメンバ関数は用意していませんが、NodeIdArrayType 型コンテナに対しても最適化を検討したい場合は用意する必要があります。具体的には、通し番号最大の節の探索と、節の添字の追加・削除が最低限必要となります。
前章で使ったテスト用の画像を使い、ハフマン符号化による圧縮率を検証した結果を以下に示します。まずは、前章で利用した「風景」画像 10 枚を使った結果を以下に示します。テスト画像は全て 1024 x 768 のサイズで、1 ピクセルあたり 3 バイトとすれば 2359296 バイトのデータ量です。圧縮率は、符号サイズをこのデータ量で割った比率です。比較対象として、前章の「静的ハフマン符号化」での圧縮率を併せて示してあります。
| 画像 | 適応型ハフマン符号化 | 静的ハフマン符号化 | ||
|---|---|---|---|---|
| 符号サイズ (Bytes) | 圧縮率 (%) | 符号サイズ (Bytes) | 圧縮率 (%) | |
| 画像 1 | 2203288 | 93.39 | 2202552 | 93.36 |
| 画像 2 | 2314352 | 98.10 | 2313704 | 98.07 |
| 画像 3 | 2271316 | 96.27 | 2270524 | 96.24 |
| 画像 4 | 2293412 | 97.21 | 2292740 | 97.18 |
| 画像 5 | 2346216 | 99.45 | 2345188 | 99.40 |
| 画像 6 | 2317652 | 98.23 | 2316912 | 98.20 |
| 画像 7 | 2317252 | 98.22 | 2316604 | 98.19 |
| 画像 8 | 2311220 | 97.96 | 2310320 | 97.92 |
| 画像 9 | 2277568 | 96.54 | 2277032 | 96.51 |
| 画像 10 | 2337516 | 99.08 | 2336908 | 99.05 |
静的ハフマン符号化と比較すると、圧縮率は若干下がっています。静的ハフマン符号化の場合は符号表も必要となり、「風景」画像の場合は全ての RGB 成分が使われていたのでデータ数は 256 となりますが、正規化処理を利用すれば符号表は 256 バイトで済むので、それを加えても静的ハフマン符号化の方がデータサイズは小さくなります。符号長は処理途中でのデータ出現頻度に依存するため、処理途中での符号長が最終的に最適な符号長と等しくなる保証がないことが圧縮率を下げる要因となります。従って、符号表が不要になるというメリットはあまりなさそうです。
「アニメ調」の画像での検証結果は以下のようになります。
| 画像 | 適応型ハフマン符号化 | 静的ハフマン符号化 | ||
|---|---|---|---|---|
| 符号サイズ (Bytes) | 圧縮率 (%) | 符号サイズ (Bytes) | 圧縮率 (%) | |
| 画像 1 | 1782180 | 75.54 | 1781536 | 75.51 |
| 画像 2 | 2026724 | 85.90 | 2026120 | 85.88 |
| 画像 3 | 1607904 | 68.15 | 1607240 | 68.12 |
| 画像 4 | 1917484 | 81.27 | 1916812 | 81.25 |
| 画像 5 | 945736 | 40.09 | 945192 | 40.06 |
| 画像 6 | 2314820 | 98.11 | 2313912 | 98.08 |
| 画像 7 | 2005324 | 85.00 | 2004736 | 84.97 |
| 画像 8 | 2021164 | 85.67 | 2020492 | 85.64 |
| 画像 9 | 1247516 | 52.88 | 1246972 | 52.85 |
| 画像 10 | 2224268 | 94.28 | 2223492 | 94.24 |
| 画像 | 適応型ハフマン符号化 | 静的ハフマン符号化 | ||||
|---|---|---|---|---|---|---|
| 符号サイズ (Bytes) | 圧縮率 (%) | 符号サイズ (Bytes) | 符号表サイズ (Bytes) | 合計サイズ (Bytes) | 圧縮率 (%) | |
| 画像 1 | 1039696 | 44.07 | 1039256 | 206 | 1039462 | 44.06 |
| 画像 2 | 1211116 | 51.33 | 1210788 | 167 | 1210955 | 51.33 |
| 画像 3 | 613660 | 26.01 | 613224 | 245 | 613469 | 26.00 |
| 画像 4 | 987836 | 41.87 | 987364 | 237 | 987601 | 41.86 |
| 画像 5 | 1222592 | 51.82 | 1222364 | 113 | 1222477 | 51.82 |
| 画像 6 | 958712 | 40.64 | 958320 | 175 | 958495 | 40.63 |
| 画像 7 | 648564 | 27.49 | 648060 | 203 | 648263 | 27.48 |
| 画像 8 | 851260 | 36.08 | 850436 | 105 | 850541 | 36.05 |
| 画像 9 | 978000 | 41.45 | 977524 | 241 | 977765 | 41.44 |
| 画像 10 | 953700 | 40.42 | 953200 | 209 | 953409 | 40.41 |
傾向は静的ハフマン符号化と変化はなく、データサイズは適応型ハフマン符号化の方がやはり若干大きくなります。「アニメ調」GIF画像の場合だけ、符号表サイズを加算した合計サイズでの圧縮率を示していますが、符号表サイズは、正規化処理を行ったとして符号一つあたり 1 バイトとして計算しています。
実際にサンプルプログラムを走らせるとわかるのですが、適応型ハフマン圧縮処理にかかる時間は静的ハフマン圧縮と比較すると圧倒的に長いので、圧縮率がほとんど変わらないのなら、よほどの理由がない限りは適応型ハフマン圧縮を選択する意味はありません。データを読み込みながら符号化を行わなければならない場合のみ有効な手段となります。しかし、それでも必要な場合、処理時間をできるだけ短くする工夫が必要になります。今回は Counter クラスを最適化することで処理時間が短縮できるかどうか、以下の三つの場合で検証してみました。
| オブジェクト名 | CounterType |
|---|---|
| AHC_Counter_Map | std::map< size_t, NodeIdArrayType > |
| AHC_Counter_Vector | std::vector< std::pair< size_t, NodeIdArrayType > > |
| AHC_Counter_UnorderedMap | std::unordered_map< size_t, NodeIdArrayType > |
AHC_Counter_Map はサンプル・プログラムでも示したもので、出現頻度と対応する節のグループをリンクするために STL の map コンテナを利用したものです。map コンテナは連想配列であり、出現頻度から対象の節のグループを得る場合はその出現頻度を使って map クラスのメンバ関数 find を呼び出すだけで実現できます。AHC_Counter_Vector は、出現頻度と対応する節のグループを pair オブジェクトで連結し、その値を可変長配列 vector に保持する方式を採用しています。節のグループの探索には「線形探索」を利用することになり、map と比べると効率は落ちます。最後の AHC_Counter_UnorderedMap は、2011 年に制定された C++ の ISO 標準 (C++11) で新たに導入されたコンテナ・クラスで、いわゆるハッシュ・テーブルのことです。map や set では、反復子を使って先頭から順に要素を見た時すでにソートされた状態であることが保証されていますが、unordered_map の場合はそれが保証されていないため "unordered" と付けられています。使い方は map の場合とほとんど同じですが、節のグループに一つも節が存在しなくなった時にグループごと消去する処理 (erase) を行っていないという大きな違いがあります。他の二つでは消去した方が処理は早くなりますが、AHC_Counter_UnorderedMap では逆に遅くなるという結果が得られました。なお、いずれの場合も節のグループの型 (NodeIdArrayType) は全て同じ std::vector< typename HuffmanTree::size_type > 型です。
下の図表は、各 CounterType に対してデータ数ごとの符号化・復号化処理時間を計測した結果を示したものです。unsigned char 型のデータを乱数で作成してテストする操作を各条件に対して 10 回ずつ行い、その平均値を表に示しています。また、右側はそのグラフで、X, Y 軸ともに対数目盛りとしてあります。
|

| |||||||||||||||||||||||||||
結果として、AHC_Counter_UnorderedMap にて圧倒的に高速な処理を行うことができました。AHC_Counter_Vector は最初は AHC_Counter_Map より処理速度が速いものの、途中で 逆転されてしまいます。従って、C++11 に対応できるのなら AHC_Counter_UnorderedMap を、そうでなければ AHC_Counter_Map を採用するのが無難です。いずれの場合もデータ量に比例して処理時間が増加しているので、データ量に対して急激に処理時間が大きくなることはありませんが、1000000 データ ( 画像の場合 1000 x 1000 程度のサイズで RGB 成分は 3000000 個になります ) で 1 秒程度かかるのでパフォーマンスの面からも静的ハフマン符号化の方が有利になります。
◆◇◆更新履歴◆◇◆
◎ サンプル・プログラムの中の WriteToArray, ReadFromArray の内容を少し変更しました (2015-05-10)
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |