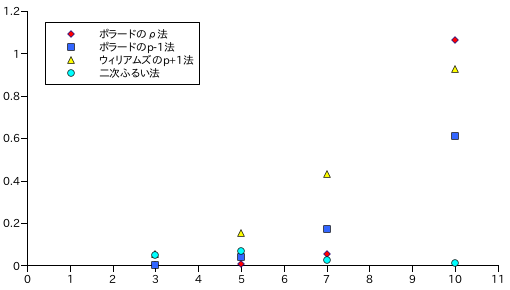
| N | ||||
|---|---|---|---|---|
| 3 | 5 | 7 | 10 | |
| ポラードのρ法 | 0.00020 | 0.0068 | 0.052 | 1.1 |
| ポラードのp-1法 | 0.0017 | 0.039 | 0.17 | 0.61 |
| ウィリアムズのp+1法 | 0.053 | 0.15 | 0.43 | 0.93 |
| 二次ふるい法 | 0.051 | 0.067 | 0.023 | 0.013 |
|
以前紹介した「RSA 暗号」は、大きな素数どうしの積を実用的な時間内に素因数分解することが非常に困難であることを利用した手法でした。しかし、素因数分解を効率よく行うためのアルゴリズムは存在し、かなり大きな数でも素因数分解は可能なので、鍵に使う数をさらに大きくすることで対処するというのが現状です。新たな手法が見つかれば、さらに数を大きくしたり、場合によっては RSA 暗号自体が利用できなくなる可能性もありますが、今のところはそのような手法は見つかっていないようです。今回は、素因数分解の手法について紹介したいと思います。
素因数分解の最も単純な方法は、与えられた数が割り切れるかを 2 から順番に試すやり方です。与えられた数を N としたとき、√N を超えない最大の整数まで割ってみて、割り切れる数がなければそれは素数であることになります。この手法は素数判定法としても利用することが可能で、「数値演算法 (6) 素数判定法」の「1) エラトステネスのふるい」の中でも紹介しています。
この方法は、小さな素因数から構成された数であれば有効ですが、そうでない場合は非常に時間がかかります。もし、N の素因数が √N に近い数であることがあらかじめわかっているのなら、次に紹介するフェルマーのアルゴリズムが有効な手法となります。フェルマーとは、「フェルマーの最終定理」で有名な「ピエール・ド・フェルマー ( Pierre de Fermat )」のことです。
与えられた数 N は奇数であると仮定します ( 偶数なら奇数になるまで 2 で割り続けて奇数の因数を得ます )。N = a x b ( 但し a ≥ b ) の形で因数の積に分解できるとしたとき、a, b も奇数となり、
x = ( a + b ) / 2
y = ( a - b ) / 2
とすると、二式の両辺の和と差を計算することによって
a = x + y
b = x - y
という結果が得られるので
となり、N は必ず平方数の差で表すことができます。N = ( x + y )( x - y ) なので、平方数の差で表すことができれば、因数 x + y, x - y に分解することができます。
x, y を見つけるために、以下のようなアルゴリズムを使用します。
x を 1 増やしたとき、x2 から ( x + 1 )2 への増分は 2x + 1 になります。y についても同様なので、上記アルゴリズムは次のようにすることができます。
このようにすると、ループの中で乗算がなくなり、より高速に処理ができるようになります。
フェルマーのアルゴリズムのサンプル・プログラムを以下に示します。
/* SquareRoot : t の平方根を求める ニュートン法を利用した平方根算出ルーチン t は符号なし整数であることを前提とし、√t を超えない最大数を返す */ template< class T > T SquareRoot( T t ) { T a = t; T b = ( t + 1 ) / 2; while ( b < a ) { a = b; b = ( a * a + t ) / ( 2 * a ); } return( a ); } /* Factorization_fermat : フェルマーのアルゴリズムを使い素因数分解を行う すでに試し割りによって小さな素因数を持たない( 0 や 1、偶数でない )ことを想定していることに注意 n 素因数分解を行う対象の数 a, b 素因数分解を行った結果を返す変数へのポインタ */ template< class T > void Factorization_fermat( T n, T* a, T* b ) { // √t 以上の最小数を求める T x = SquareRoot( n ); if ( n > x * x ) ++x; T x2 = x * x; T s = x * 2 + 1; T t; for ( ; ; ) { t = 3; T m = x2 - 1; while ( m > n ) { m -= t; t += 2; } if ( m == n ) break; x2 += s; s += 2; } *a = ( s + t - 2 ) / 2; *b = ( s - t ) / 2; }
SquareRoot は平方根を算出するための関数です。算出には「ニュートン-ラフソン法 ( Newton-Raphson method )」を利用しています。Factorization_fermat がメイン・ルーチンで、前述のアルゴリズムをそのまま適用しています。なお、あらかじめ試し割りで小さな素因数を持たないこと、特に 0 や 1、偶数でないことを想定していることに注意して下さい。n = 1, 2, 4 のときは無限ループになります。
フェルマーのアルゴリズムは、素数 p に対しては [ ( p + 1 ) / 2 ]2 - [ ( p - 1 ) / 2 ]2 = p・1 となります。これが最大処理回数となるので、あらかじめ素数判定を行ってから実行する必要があります。また、小さな素因数からなる数に対しては試し割りによる方法よりも遅くなる場合もあります。例えば、176891 = 1237 x 143 の素因数分解には 0.1 秒以内で完了しているの対し、176893 = 7691 x 23 を素因数分解するのに約 1 秒かかっています。処理の内容からも明らかなように、大きな素因数からなる数に対して有効な方法ということになります。
「ポラードの ρ 法 ( Pollard's Rho Algorithm )」は、イギリスの数学者「ジョン・ポラード ( John Pollard )」によって 1975 年に考案された手法です。
N を素因数分解する対象の数、d を N が持つ未知の因数と仮定します。f(x) を多項式 ( 例えば x2 + 1 ) として、初期値 x0 から始めて以下の漸化式を使って数列を計算します。
上式は「合同式 ( Modular arithmetic )」と呼ばれ、xi - f( xi-1 ) が N で割り切れることを意味します。例えば、N = 247, x0 = 2, f(x) = x2 + 1 とすると、数列は以下のようになります。
次に、以下の漸化式を計算します。
例えば、247 の素因数として d = 13 を使うと、数列は次のようになります。
xi ≡ f( xi-1 ) ( mod N ) のとき、yi ≡ f( yi-1 ) ( mod d ) が成り立ちます ( 補足 1 )。d の剰余は有限個しかないので、いずれ値が等しくなる二数 yi, yj ( i ≠ j ) が現れます。漸化式 yi ≡ f( yi-1 ) ( mod d ) が成り立つことから、一度等しいニ数が現れるとそれ以降は循環し、任意の正数 t に対して yi+t = yj+t が成り立ちます。よって、そのような等しいニ数 yi, yj が見つかれば、
より
を満たす整数 ki が存在することから
となって xi ≡ xj ( mod d ) が成り立ちます。つまり、d が xi - xj を割り切ることになり、xi - xj と N との最大公約数に少なくとも d は必ず含まれることになります。最大公約数は「ユークリッドの互除法」を使えば簡単に求められるので、これで素因数分解ができたことになります。
ところが、d の値は本来求めたい値なので今はわかりません。従って、yi の値もわからず、いつ等しいニ数 yi, yj が現れるかも不明な状態です。そこで、i と j をいろいろと変えながら xi - xj と N との最大公約数を計算し、1 と N 以外の値が見つかるまでその処理を繰り返していきます。i と j を選ぶ方法はいろいろとありますが、1980 年に「リチャード・ブレント ( Richard Brent )」によって考案された方法が単純かつ高速に処理を行えます。
x1 - x3
x3 - x6
x3 - x7
x7 - x12
x7 - x13
x7 - x14
x7 - x15
x2k-1 - xj ( 2k+1 - 2k-1 ≤ j ≤ 2k+1 - 1 )
ポラードの ρ 法のサンプル・プログラムを以下に示します。
/* ユークリッドの互除法を使った最大公約数の計算 a, b : 最大公約数を求める二つの自然数 戻り値 : 最大公約数 */ template< class T > T gcd( T a, T b ) { if ( a < b ) std::swap( a, b ); do { T r = a % b; a = b; b = r; } while ( b != 0 ); return( a ); } /* ポラードの ρ 法を使い素因数分解を行う n 素因数分解を行う対象の数 a,b 素因数分解を行った結果を返す変数へのポインタ p 多項式計算関数へのポインタ x0 初期値 maxCnt 最大試行回数 戻り値 : 素因数分解に成功したら true を返す */ template< class T > bool Factorization_pollardsRho( T n, T* a, T* b, T (*p)( T ), T x0, unsigned int maxCnt ) { // xi = x1 で初期化 T xi = (*p)( x0 ) % n; // xj = x2 で初期化(内部ループで先行して更新するため x3 ではないことに注意) T xj = (*p)( xi ) % n; // 内部ループのカウント unsigned int count = 1; // xj の更新回数 unsigned int inc = 3; for ( unsigned int cnt = 0 ; cnt < maxCnt ; cnt += count / 2 ) { for ( unsigned int i = 0 ; i < count ; ++i ) { xj = (*p)( xj ) % n; T diff = ( xi > xj ) ? xi - xj : xj - xi; T d = gcd( diff, n ); if ( d != 1 && d != n ) { *a = d; *b = n / d; return( true ); } } xi = xj; for ( unsigned int i = 0 ; i < inc ; ++i ) xj = (*p)( xj ) % n; count *= 2; inc += count; } return( false ); }
引数の中にある T (*p)( T ) は変数名が p の部分で「型 T をとる引数を一つ持ち、型 T を戻り値とする関数へのポインタ」を意味します。多項式として任意のものを利用できるようにするためにこのような形にしています。また x0 は数列 xi の初期値、maxCnt は最大試行回数をそれぞれ表しています。多項式 x2 + 1 を使った場合の例を以下に示します。
template< class T >
T Poly( T x )
{
return( x * x + 1 );
}
:
if ( Factorization_pollardsRho( num, &a, &b, &Poly, 2, 100000 ) )
std::cout << a << " x " << b << " = " << a * b << std::endl;
次に紹介するアルゴリズムも「ジョン・ポラード ( John Pollard )」によって 1974 年に考案されました。この手法には「フェルマーの小定理」が利用されています。
素因数分解したい数 N の素因数の一つを p とします。p - 1 の素因数が小さく、ある数 k に対して k! が p - 1 で割り切れると仮定すると、N を法とする数 c の k! 乗
は、フェルマーの小定理から法を p として 1 に合同になります。なぜなら、整数 a, a' を使い
と表せることから m は法 p に対しても ck! に合同であり、整数 b を使って
と表せるので、フェルマーの小定理より
となるからです。従って、p は m - 1 を割り切ることになり、N が m - 1 を割りきらなければ N と m - 1 の最大公約数が N の 1, N 以外の約数になる可能性があります。
残念ながら、p は未知数です。従って、c や k の数をいろいろ変えながら試してみるような方法をとります。幸い、ck! = (...(((c1)2)3)4...)k なので、c からスタートしてべき数を 1 ずつ増やしながらべき乗を計算していけば非常に早く m を求めることができます ( *3-1 )。
ポラードの p - 1 法のサンプル・プログラムを以下に示します。
/* ModularPower : 繰り返し自乗法を使った法 n のべき乗計算( a の k 乗を n で割った余りを求める ) テンプレート引数の I は、乗法・剰余・ビットシフト・AND・比較演算子が使える型である必要がある。 剰余演算子やビットシフトなどを使うため、整数型であることを前提としている。 底 a や法 n が 0 の場合は 0 を返す。 指数が 0 の場合は法 n における 1 を返す。 a 底 k 指数 n 法 戻り値 : べき乗 */ template< class I > I ModularPower( const I& a, I k, const I& n ) { if ( a == I() || n == I() ) return( I() ); // 底や法が 0 の場合は 0 を返す if ( k == I() ) return( 1 % n ); // 指数が 0 の場合は法 n における 1 I mod( a % n ); // n を法とした a I ans( ( ( k & 1 ) > I() ) ? mod : 1 ); // 求める値 for ( k >>= 1 ; k > I() ; k >>= 1 ) { mod = ( mod * mod ) % n; if ( ( k & 1 ) > I() ) ans = ( ans * mod ) % n; } return( ans ); } /* Factorization_pollardsP_1 : ポラードの p-1 法を使い素因数分解を行う n 素因数分解を行う対象の数 a,b 素因数分解を行った結果を返す変数へのポインタ c 底 maxCnt 最大処理回数(指数の最大値 + 1) 戻り値 : 素因数分解に成功したら true を返す */ template< class T > bool Factorization_pollardsP_1( T n, T* a, T* b, T c, unsigned long int maxE ) { T m( c ); for ( unsigned long int cnt = 0 ; cnt < maxE ; ++cnt ) { m = ModularPower( m, T( cnt + 1 ), n ); T g = gcd( m - 1, n ); if ( g == 1 ) continue; if ( g == n ) return( false ); *a = g; *b = n / g; return( true ); } return( false ); }
処理の内容は非常にシンプルで、関数 ModularPower を使って n を法とする m のべき乗を繰り返し計算しながら m - 1 と n との最大公約数を求めることを繰り返し、1, n 以外の約数が見つかったら素因数分解できたことになります。もし最大公約数が n になったら、m - 1 は n で割り切れることになるので m ≡ 1 ( mod n ) となり、m をこれ以上べき乗しても 1 に合同であるままとなります。従って、そうなった段階で処理を終了します。
*3-1) 「暗号化アルゴリズム (3) 公開鍵暗号」の「4) 繰り返し自乗法 ( Exponentiation by squaring )」を参照
整数 P, Q を係数とする二次方程式 x2 + Px + Q = 0 の二つの解を α, β としたとき、これらは
α = ( P + √D ) / 2
β = ( P - √D ) / 2
D = P2 - 4Q
と表すことができます。このとき、
Un = ( αn - βn ) / ( α - β ) = ( αn - βn ) / √D
Vn = αn + βn
で表される数列 { Un }, { Vn } を「リュカ数列 ( Lucas Sequence )」といいます。二つの数列から
| Vn + Un√D | = | ( αn + βn ) + [ ( αn - βn ) / √D ]√D |
| = | 2αn | |
| = | 21-n( P + √D )n |
という式が生成できます。
D = P2 - 4Q より Q = ( P2 - D ) / 4 なので、Q が整数ならば P2 - D は 4 で割り切れなければなりません。すなわち P2 ≡ D ( mod 4 ) なので D は法 4 の平方剰余であり、「ルジャンドル記号 ( Legendre Symbol )」を用いて ( D / 4 ) = 1 と表されます ( *4-1 )。よって、D ≡ 0 または 1 ( mod 4 ) が成り立ち、D ≡ 0 ( mod 4 ) のとき P ≡ 0 または 2 ( mod 4 )、D ≡ 1 ( mod 4 ) のとき P ≡ 1 または 3 ( mod 4 ) となります。
リュカ数列については様々な漸化式が成り立ちます。まず、
| Vn+1 + Un+1√D | = | 21-(n+1)( P + √D )n+1 |
| = | ( P + √D )2-n( P + √D )n | |
| = | (1/2)( P + √D )( Vn + Un√D ) | |
| = | (1/2)[ ( PVn + DUn ) + ( Vn + PUn )√D ] |
より
Vn+1 = (1/2)( PVn + DUn )
Un+1 = (1/2)( Vn + PUn )
という漸化式が得られます。また、同じ式に異なる変形を行うと
| Vn+1 + Un+1√D | = | 21-(n+1)( P + √D )n+1 |
| = | 21-n( P + √D )n-1・2-1( P + √D )2 | |
| = | 21-n( P + √D )n-1・2-1( P2 + 2P√D + D ) | |
| = | 21-n( P + √D )n-1[ P2 + P√D + ( D - P2 ) / 2 ] | |
| = | 21-n( P + √D )n-1( P2 + P√D - 2Q ) | |
| = | 21-nP( P + √D )n - 21+(1-n)Q( P + √D )n-1 | |
| = | P( Vn + Un√D ) - Q( Vn-1 + Un-1√D ) | |
| = | ( PVn - QVn-1 ) + ( PUn - QUn-1 )√D |
より
Vn+1 = PVn - QVn-1
Un+1 = PUn - QUn-1
となります。P = 1, Q = -1 のとき、Un+1 = Un + Un-1 でこれは「フィボナッチ数列 ( Fibonacci Numbers )」です。また、この結果から、{ Un }, { Vn } は ( P, Q は整数なので ) 全て整数になることがわかります。
| Vm+n + Um+n√D | = | 21-(m+n)( P + √D )m+n |
| = | (1/2)21-m( P + √D )m・21-n( P + √D )n | |
| = | (1/2)( Vm + Um√D )( Vn + Un√D ) | |
| = | (1/2)[ ( VmVn + DUmUn ) + ( VmUn + VnUm )√D ] |
より
Vm+n = (1/2)( VmVn + DUmUn )
Um+n = (1/2)( VmUn + VnUm )
で、特に m = n のとき
が成り立ちます。さらに、
| ( Vn + √DUn )( Vn - √DUn ) | = | Vn2 - DUn2 |
| = | ( αn + βn )2 - ( αn - βn )2 | |
| = | 4αnβn | |
| = | 4[ ( P + √D )( P - √D ) / 4 ]n | |
| = | 4[ ( P2 - D ) / 4 ]n | |
| = | 4Qn |
より
を利用して、
| Vm-n + Um-n√D | = | 21-(m-n)( P + √D )m-n |
| = | 2( Vm + Um√D )( Vn + Un√D )-1 | |
| = | 2( Vm + Um√D )( Vn - Un√D ) / 4Qn | |
| = | [ ( VmVn - DUmUn ) + ( VnUm - VmUn )√D ] / 2Qn |
となるので
Vm-n = ( VmVn - DUmUn ) / 2Qn
Um-n = ( VnUm - VmUn ) / 2Qn
という結果が得られます。また、Vm+n と Vm-n の式から
Vm+n + QnVm-n = VmVn より
Vm+n = VmVn - QnVm-n
となるので、m = n とすれば
となり、m = n + 1 とすれば
となります。以上の公式を以下にまとめておきます。
| Vn+1 = (1/2)( PVn + DUn ) | --- (4.1.1) |
| Un+1 = (1/2)( Vn + PUn ) | --- (4.1.2) |
| Vn+1 = PVn - QVn-1 | --- (4.2.1) |
| Un+1 = PUn - QUn-1 | --- (4.2.2) |
| Vm+n = (1/2)( VmVn + DUmUn ) | --- (4.3.1) |
| Um+n = (1/2)( VmUn + VnUm ) | --- (4.3.2) |
| U2n = VnUn | --- (4.4) |
| Vn2 - DUn2 = 4Qn | --- (4.5) |
| Vm-n = ( VmVn - DUmUn ) / 2Qn | --- (4.6.1) |
| Um-n = ( VnUm - VmUn ) / 2Qn | --- (4.6.2) |
| V2n = Vn2 - 2Qn | --- (4.7) |
| V2n+1 = VnVn+1 - PQn | --- (4.8) |
(4.4) 式より U2n = VnUn なので Un は U2n を割り切ります。ある整数 k について、Un が Ukn を割り切ると仮定すると、(4.3.2)式より
なので、帰納法より Un は 2U(k+1)n を割り切ります。また、(4.4) 式は Vn が U2n を割り切ることも示しています。Vn が Vkn を割り切ると仮定すると、(4.3.1) と (4.4) より
となって、帰納法より Vn は 2V(2k+1)n を割り切ります。このことから、次の定理が導かれます。
例として、フィボナッチ数列は U1 = 1 から始まって次のようになります
| U1 | U2 | U3 | U4 | U5 | U6 | U7 | U8 | U9 | U10 | U11 | U12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | 89 | 144 |
U4 = 3 は 3 で割り切れますが、同様に U8 = 21, U12 = 144 も 3 で割り切れます。また、U5 = 5 は 5 で割り切れ、U10 = 55 も 5 で割り切れます。同じ初期値 ( P = 1, Q = -1 ) で Vn の方を見ると次のようになります。
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 4 | 7 | 11 | 18 | 29 | 47 | 76 | 123 | 199 | 322 |
V4 = 7 は 7 で割り切れるのに対し、V8 = 47 は 7 では割り切れません。しかし、V12 = 322 は 7 で割り切れます。
Vn + Un√D = 21-n( P + √D )n を二項展開すると
となります。n を素数 p としたとき、pCk = p! / k!( p - k )! は、p > k ならば k は p を割り切らないので、必ず p で割り切れることになります。また、21-p は p を法として 1 に合同なので ( 補足 2 )、
Vp ≡ Pp ≡ P ( mod p )
Up ≡ √Dp-1 = D(p-1)/2 ≡ ( D / p ) ( mod p )
となります。なお、Pp ≡ P ( mod p ) は「フェルマーの小定理」Pp-1 ≡ 1 ( mod p ) から導かれます。
この結果は、Vp を p で割った余りが必ず P であり、Up を p で割った余りが 0, 1, -1 のいずれかになることを示しています。これは、先ほど示した P = 1, Q = -1 の場合の Un, Vn でも成り立っていることが容易にわかります。
さらに、(4.3.2) より
| 2Up+1 | = | VpU1 + V1Up |
| = | Vp + PUp | |
| ≡ | P + P( D / p ) ( mod p ) | |
| ≡ | P[ ( D / p ) + 1 ] ( mod p ) |
(4.6.2) より
| 2QUp-1 | = | V1Up - VpU1 |
| = | PUp - Vp | |
| ≡ | P( D / p ) - P ( mod p ) | |
| ≡ | P[ ( D / p ) - 1 ] ( mod p ) |
(4.3.1) より
| 2Vp+1 | = | VpV1 + DUpU1 |
| = | PVp + DUp | |
| ≡ | P2 + D( D / p ) ( mod p ) |
(4.6.1) より
| 2QVp-1 | = | VpV1 - DUpU1 |
| = | PVp - DUp | |
| ≡ | P2 - D( D / p ) ( mod p ) |
が成り立ちます。p が D を割り切るならば、( D / p ) = 0 なので Up ≡ 0 ( mod p ) となり、p は Up を割り切ります。( D / p ) = -1 のとき、2Up+1 ≡ 0 ( mod p ) より ( p が奇素数なら ) p は Up+1 を割り切り、( D / p ) = 1 のとき、2QUp-1 ≡ 0 ( mod p ) より ( p と 2Q が互いに素なら ) p は Up-1 を割り切ります。
また、( D / p ) = -1 のとき、p が奇素数なら次が成り立ちます。
2Vp+1 ≡ P2 - D = 4Q ( mod p ) より
Vp+1 ≡ P2 - D = 2Q ( mod p )
( D / p ) = 1 のときは、
となり、p と 2Q が互いに素なら
が成り立ちます。これらをまとめると次のようになります。
p を 2Q と互いに素な素数とする。このとき、p は Up-(D/p) を割り切る。また、p が D とも互いに素なら次が成り立つ。
Vp-(D/p) ≡ 2Q[1-(D/p)]/2 ( mod p )
最後に、リュカ数列を利用して二次合同式 x2 ≡ n ( mod p ) の解 x を解くアルゴリズムを紹介します。但し、p は奇素数であるとします。当然、n は p を法とする平方剰余、すなわち ( n / p ) = 1 です。
Q = n とし、( D / p ) = ( ( P2 - 4Q ) / p ) = -1 になるような P を選んでリュカ数列を生成します。このとき、(4.7) より
なので、先ほど示した定理から Vp+1 ≡ 2n ( mod p ) が成り立つことを利用して
| V(p+1)/22 | = | Vp+1 + 2n(p+1)/2 |
| = | Vp+1 + 2n・n(p-1)/2 | |
| ≡ | 2n + 2n( n / p ) ( mod p ) | |
| ≡ | 4n ( mod p ) |
となります。V(p+1)/2 が奇数であった場合を考慮して、上式を以下のように表します。
すなわち、[ ( p + 1 ) / 2 ]・V(p+1)/2 は二次合同式 x2 ≡ n ( mod p ) の解 x となります。この結果を利用したアルゴリズムは、「デリック・ヘンリー・レーマー ( Derrick Henry Lehmer )」によって 1969 年に考案されました。
「レーマーのアルゴリズム」のサンプル・プログラムを以下に示します。
/* Diff : ( u1 - u2 ) % p を解く u1 < u2 の場合、( u1 + Np - u2 ) % p として負数にならないようにする */ template< class U > U Diff( U u1, U u2, U p ) { if ( u1 < u2 ) { u1 += ( ( u2 - u1 ) / p + 1 ) * p; } return( ( u1 - u2 ) % p ); } /* LehmerAlgorithm : レーマーのアルゴリズムで V_n ( 実際には r の剰余 ) を求める 漸化式に v_2i = v_i^2 - 2n^i, v_2i+1 = v_i * v_i+1 - h x n^i を使う。 ステップ数が対数となるため高速に処理できる。 p リュカ数列のパラメータ P ( ルジャンドル記号 ( p^2 - 4q / r ) = -1 となる数 ) q リュカ数列のパラメータ Q ( r を法とする平方剰余とする ) r 法 n 処理回数 戻り値 : 二次合同式 x^2 = q ( mod r ) の解 x */ template< class U > U LehmerAlgorithm( U p, U q, U r, U n ) { U m( q ); // q のべき乗 q^i U v0( p ); // v_i U v1( Diff( p * p, 2 * q, r ) ); // v_i+1 // n をビット列で表す(最上位ビットを除いていることに注意) std::vector< bool > bit; while ( n > 1 ) { bit.push_back( ( n & 1 ) == 1 ); n /= 2; } for ( std::vector< bool >::reverse_iterator i = bit.rbegin() ; i != bit.rend() ; ++i ) { U v( Diff( v0 * v1, p * m, r ) ); // v_2i+1 = v_i * v_i+1 - pq^i v0 = Diff( v0 * v0, 2 * m, r ); // v_2i = v_i^2 - 2q^i v1 = Diff( v1 * v1, 2 * q * m, r ); // v_2i+2 = v_i+1^2 - 2q^(i+1) m = ( m * m ) % r; if ( ! *i ) { // 偶数(2)回分なら v_2i, v_2i+1 を採用 v1 = v; } else { // 奇数(3)回分なら v_2i+1, v_2i+2 を採用 v0 = v; m = ( q * m ) % r; } } return( v0 ); } /* QC_Solver : レーマーのアルゴリズムを使い二次合同式を解く q リュカ数列のパラメータ Q ( r を法とする平方剰余とする ) r 法 戻り値 : 二次合同式 x^2 = q ( mod r ) の解 x */ template< class U > U QC_Solver( U q, U r ) { // ルジャンドル記号 ( p^2 - 4q / r ) = -1 となる数 U p = 2 * ( SquareRoot( q ) + 1 ); for ( ; ; ++p ) if ( Jacobi( p * p - U( 4 ) * q, r ) < 0 ) break; U n( ( r + 1 ) / 2 ); // 処理回数 U v0 = LehmerAlgorithm( p, q, r, n ); v0 = ( v0 * ( r + 1 ) / 2 ) % r; if ( v0 >= ( r + 1 ) / 2 ) v0 = r - v0; return( v0 ); }
LehmerAlgorithm は指定した添字 n のリュカ数列 Vn を求めるための関数です。但し、変数 r を法とする値を返します。Vn の計算は、(4.7) と (4.8) を使えば高速に計算することができます。V2n, V2n+1, V2n+2 を漸化式を使って計算し、上位ビット側 ( 但し、最上位ビットを除きます ) から順に、ビットが立っていたら Vn = V2n+1, Vn+1 = V2n+2 とし、そうでなければ Vn = V2n, Vn+1 = V2n+1 とします。例えば ( p + 1 ) / 2 = 22 ( ビット列 10110 ) だった場合、V1, V2 からスタートして
| ビット列 | Vn | Vn+1 | |
| 10 | : | V1 → V2 | V2 → V3 |
| 101 | : | V2 → V5 | V3 → V6 |
| 1011 | : | V5 → V11 | V6 → V12 |
| 10110 | : | V11 → V22 | V12 → V23 |
となります。ビット列が増えるごとに n の値は二倍され、ビットが立っている場合は 1 を加えることで、左側のビット列と Vn の添字が対応することが理解できると思います。
QC_Solver は、LehmerAlgorithm を利用して二次合同式 x2 ≡ q ( mod r ) の解 x を求めるための関数です。最初にパラメータ P の値を決めるため、( ( P2 - 4q ) / r ) = -1 となる P を探索します。なお、ルジャンドル記号 ( ヤコビ記号 ) の計算には「3) Solovay-Strassen 素数判定法」の節で紹介した関数 Jacobi を使っています。あとは求めるリュカ数列の添字 n に ( r + 1 ) / 2 を指定して LehmerAlgorithm を呼び出し Vn を求め、r を法として Vn x ( r + 1 ) / 2 を計算すれば解が得られます。なお、解 x に対して r - x も同様の解となります。なぜなら
となるからです。LehmerAlgorithm でどちらが得られるかはわからないので、( r + 1 ) / 2 より大きい値が得られた場合は r - Vn を計算してより小さい側を返すようにしています。
*4-1) 平方剰余やルジャンドル記号についての内容は「数値演算法 (6) 素数判定法」の「3) Solovay-Strassen 素数判定法」を参照
リュカ数列の特徴として、p が 2Q と互いに素な素数であるなら次の式が成り立つというものがありました。
Up-(D/p) ≡ 0 ( mod p )
Vp-(D/p) ≡ 2Q[1-(D/p)]/2 ( mod p )
Q = 1 で、p が ( D / p ) = -1 となるような素数であるとき、上式は次のようになります。
Up+1 ≡ 0 ( mod p )
Vp+1 ≡ 2 ( mod p )
奇素数 p が Un を割り切るとき、p は Ukn を割り切るのでした。よって、
も成り立ちます。それでは Vk(p+1) ≡ 2 ( mod p ) は成り立つのでしょうか。そこで、次のように式を変形していきます。
| Vk(p+1) | ≡ | Vk(p+1) + Uk(p+1)√D ( mod p ) |
| = | 21-m(p+1)( P + √D )m(p+1) | |
| = | 21-m・[ 21-(p+1)( P + √D )p+1 ]m | |
| = | 21-m・( Vp+1 + Up+1√D )m | |
| ≡ | 21-m・2m ( mod p ) | |
| ≡ | 2 ( mod p ) |
となり、成り立つことが証明できました。
これを利用して、ポラードの p - 1 法に似た素因数分解の方法が得られます。素因数分解したい数 N の素因数の一つを p として、p + 1 の素因数が小さく、ある数 m に対して m! が p + 1 で割り切れると仮定します。Q = 1 とし、D = P2 - 4 が ( D / p ) = -1 を満たすようなリュカ数列を Vn とします。p + 1 は m! を割り切るので、先ほどの結果から p は Vm! - 2 を割り切ります。従って、Vm! - 2 と N の最大公約数は N の素因数となる可能性があります。しかし、p は未知の数であり、( D / p ) = -1 であるかどうかもわかりません。従って、ポラードの p - 1 法と同じように、D の値を変えながら試行錯誤することになります。
ここで Un の方を利用しなかった理由は処理速度の違いにあります。Vn に対しては V2n, V2n+1 を求める方法があるため、圧倒的に早く計算することができます。これは、ポラードの p - 1 法において ck! の計算速度が非常に早いことと類似しています。
この手法は「ヒュー・ウィリアムズ ( Hugh Williams )」によって考案されたため「ウィリアムズの p + 1 法 ( Williams's p + 1 Algorithm )」といいます。
「ウィリアムズの p + 1 法」のサンプル・プログラムを以下に示します。
/* Factorization_WilliamsP_1 : ウィリアムズの p+1 法を使い素因数分解を行う n 素因数分解を行う対象の数 a,b 素因数分解を行った結果を返す変数へのポインタ p リュカ数列のパラメータ P maxCnt 最大処理回数 戻り値 : 素因数分解に成功したら true を返す */ template< class T > bool Factorization_WilliamsP_1( T n, T* a, T* b, T p, unsigned long int maxCnt ) { T v( p ); for ( unsigned long int k = 1 ; k <= maxCnt ; ) { T g = gcd( v - 2, n ); if ( g != 1 && g != n ) { *a = g; *b = n / g; return( true ); } for ( unsigned long int i = 0 ; i < 10 ; ++i ) { v = LehmerAlgorithm( p, T( 1 ), n, T( k ) ); p = v; ++k; } } return( false ); }
変数 v はリュカ数列 Vn を表し、最初は P で初期化しています。変数 k を 1 で初期化して、前節で紹介した関数 LehmerAlgorithm で Vk を計算します。求めた Vn は次のパラメータ P として処理を行っていますが、LehmerAlgorithm の中で Vn の初期値を P としていることから、k を 1 ずつ増やしながら計算を繰り返すことと同じこととなり、Vk! を求めていることになります。なお、Vk! - 2 と n の最大公約数は、k を 10 ずつ増やしながら行うようにしていますが、これは参考文献の処理内容をそのまま反映しています。
フェルマーのアルゴリズムは、x2 - y2 = N となるような x, y を探すことで素因数分解を行うというものでした。この条件を緩めて x2 - y2 ≡ 0 ( mod N ) とすると、ある整数 k について
となるので、x ± y は N の因数の一部で構成されている可能性があります。このとき、x ± y と N の最大公約数を求めることで因数が見つかるかもしれません。そこで、√N 以上の整数を x とし、x2 - N を求めていき、その中で平方数を探すことを検討します。例えば、N = 33 のとき、√33 < 6 なので、
とすると、
が見つかり、左辺は ( 7 + 4 )( 7 - 4 ) = 11・3 で素因数分解できたことになります。
ところが 137069 というような大きな数の場合、√137069 < 371 より
となって、簡単には平方数が見つからなくなります。素因数分解のために何度も素因数分解を行うのは効率が悪いため、あらかじめ小さな素数を決めておいて、それらで割り切れる数を探すことにします。すると、
となります。まだ平方数になる数は現れていませんが、よく見ると 3772 - 137069, 3812 - 137069, 3822 - 137069 を掛け合わせたときの右辺は 24 x 52 x 72 x 112 x 172 x 232 = ( 22 x 5 x 7 x 11 x 17 x 23 )2 となって、平方数になります。従って、
| ( 3772 - 137069 )( 3812 - 137069 )( 3822 - 137069 ) | = | ( 377・381・382 )2 - ( 377・381 + 381・382 + 382・377 )・137069 + ( 377 + 381 + 382 )・1370692 - 1370693 |
| ≡ | ( 377・381・382 )2 ( mod 137069 ) | |
| ≡ | ( 22 x 5 x 7 x 11 x 17 x 23 )2 ( mod 137069 ) |
となり、377・381・382 ± 22 x 5 x 7 x 11 x 17 x 23 = 55471474, 54267194 で、137069 との最大公約数を求めると 113 と 1213 が得られ、これらがそのまま素因数となります。
素因数分解したい数 N に対し、√N より大きな最小値を k として、r = k, k + 1, k + 2 ... に対して f(r) = r2 - N を計算し、その中から小さな素数で素因数分解できる数を集めます。小さな素数が例えば 10 個だった場合、素因数分解できる数が 11 個集まれば、素数の数よりも式のほうが多くなるので必ず平方数にすることができるようになります ( これについては後述するガウスの消去法のところで説明します )。ここで問題となるのが、素因数分解できる数をすぐに集めることができるかという点です。素因数の大きさは数により様々ですが、素数でない限りは N より小さな値になります。N が 10j より小さな数だとして、j 桁の数がどの程度の割合であるかを見積もると、その値は 10j-1 から 10j - 1 までの 10j - 10j-1 個あるので、ゼロを含めて全部で 10j 個の数に対して
となります。少なくとも j - 1 桁の数は 99% であり、少なくとも j - 2 桁の数は 99.9% です。このことは、N の桁数が大きくなるほど最大素因数の桁数が小さな数の割合は少なくなっていくことを表しています。素因数の数を増やして最大素因数を大きくすれば割合は増えますが、その分割り切れる数をより多く集める必要があり、簡単にそうすることもできません。そこで、割り切れる数を探索するための"ふるい"を用意します。
まず、利用する素数は k 未満であるとします。k 未満の任意の素数 p は素因数分解対象の数 N を割り切らないことはすでにわかっているものとします。f(r) が p で割り切れるならば、
なので、ルジャンドル記号 ( N / p ) = 1 でなければならず、およそ半数の素数は除外できることになります。こうして得られた素数の集合を「因数基地 ( Factor Base )」といいます。
N が法 p の平方剰余ならば、二次合同式の解 t が存在して
が成り立ちます。よって、
r2 ≡ t2 ( mod p ) より
( r + t )( r - t ) ≡ 0 ( mod p )
で、r は p を法として t か -t のいずれかに合同になります。
f(r) の値のリストに対して、p を法として t に合同な最初の r がわかれば、その r に対する f(r) は p で割り切れます。従って、その後の p 番目ごとの f(r) も同様に p で割り切れます。また、-t に合同な r がわかれば、同じ操作によって p で割り切れる f(r) を見つけることができます。ここで、実際に p での割り算を試す代わりに、ゼロで初期化した変数に p の対数を加算することにします。その値が最終的に f(r) の対数に近ければ、f(r) が素因数分解できる可能性のある r が見つかったことになります。
ここで、f(r) は同じ素数 p で何度も割り切れる可能性があるので、
となるような合同式も解く必要があります。しかし、高次のべきを持つ素数 p はたいてい小さな値になり、そのような値を何度も繰り返して加算するという効率の悪い処理となるため、高次のべきは無視して代わりに素因数分解可能だと判定する値を緩くすることにします。そもそも、p が大きい場合は高次のべきは少ないだろうと考えることもできます。
判定にパスした f(r) の候補は最終的に試し割り除算で本当に素因数分解できるかを確認します。候補数はかなり絞られるため、試し割りをする回数は最小限に抑えることができます。候補を絞り込む判定方法は正確ではないため、試し割りの結果、素因数分解できない数もあれば、逆に素因数分解できるのに見逃した数も含まれるかもしれませんが、処理の高速化の効果がそれを補って余ります。
先ほどの例 137069 を使って実際に二次ふるい処理を行ってみます。まず、素数 2 は特別扱いします。素因数するべき数 N は奇数なので、8 を法として 1, 3, 5, 7 のいずれかに合同です。r が奇数ならば、
| f(r) | = | r2 - N |
| = | ( 2k + 1 )2 - ( 8m + s ) | |
| = | 4k( k + 1 ) - 8m - s + 1 |
と表すことができて、k( k + 1 ) は偶数なので 4k( k + 1 ) - 8m は 8 の倍数です。s = 3, 7 のとき、-s + 1 = -2, -6 なので、f(r) は 2 より大きい 2 のべき乗では割りきれません。s = 5 のとき、-s + 1 = -4 で、f(r) は 4 で割り切れますが、8 では割りきれません。s = 1 のとき、f(r) は少なくとも 8 で割り切れます。よって、N は 8 を法として 1 に合同であれば、少なくとも 8 を素因数とすることができます。そこで、N が 8 を法として 3 に合同であれば 3 を、5 に合同であれば 5 を、7 に合同であれば 7 を N に掛けることによって、1 に合同であるようにします。137069 は 8 を法として 5 に合同なので、5 を掛けて 685345 とします。
因数基地として、100 までの素因数を使います。2 を除く素因数は次のようになります。
この中で、( 685345 / p ) = 1 を満たす素数 p は次の 7 つしかありません。計算には「3) Solovay-Strassen 素数判定法」の節で紹介した関数 Jacobi を使いました。
次に、二次合同式 x2 ≡ 685345 ( mod p ) となる解 x を求めます。これには「4) リュカ数列 ( Lucas Sequence )」の節で示したサンプル・プログラムの関数 QC_Solver が利用できます。ここで、解 x に対しては -x も解になることに注意して下さい。例えば、x2 ≡ 685345 ( mod 3 ) について 1 が解になっていますが、同時に -1 ≡ 3 - 1 = 2 ( mod 3 ) も解となります。
√685345 = 827.9 なので、f(r) を計算してみる対象を 1000 個とした場合、r は 828 から 1827 となります。しかし、√685345 が中央値になるようにして 328 から1327 とすると、f(r) の値は小さな値になるので素因数分解できる見込みは高くなります。こうすることで負数が発生しますが、-1 を新たな因数として加えることで解決することができます。
素因数分解する数を N、ふるいにかける r の個数を M としたとき、i 番目の f(r) の値は、
で求められます。実際に計算すると
| f(r) | ≅ | N + ( M / 2 )2 + i2 - √N・M - Mi + 2√N・i - N |
| = | ( M / 2 )2 + i2 - √N・M - Mi + 2√N・i | |
| = | - √N・( M - 2i ) + ( M / 2 )2 + i2 - Mi |
となりますが、N >> M, N >> i ならば、
なので、絶対値の対数は
程度になります。ふるい終わったときにこの値に近くなったものを選択して試し割りをすることになりますが、その最低値としては
という式が提案されています。T は 2 前後の定数で、pmax は因数基地の素因数の最大値を表します。
これで、ふるいを掛ける準備が整いました。まず最初に 8 について考えると、r の初期値は 828 で偶数なので、r2 - N が偶数になるのは 829 からで、一つおきに log 8 を加算していきます。3 に対しては 828 ≡ 0 ( mod 3 ) なので、3 で割り切れるのは x2 ≡ 685345 ( mod 3 ) の解 1 から 0 を引いた 1 番目の 829 からで、二つおきに log 3 を加えます。このとき、-1 ≡ 2 ( mod 3 ) も解であることに注意して、2 から 0 を引いた 2 番目の 830 からも二つおきに log 3 を加えます。
11 については 828 ≡ 3 ( mod 11 ) です。11 で割り切れるのは 1 から 3 を引いた -2 = 9 番目の 837 からで、10 個おきに log 11 を加えます。また、-1 ≡ 10 ( mod 11 ) も解なので、10 から 3 を引いた 7 番目の 835 からで、10 個おきに log 11 を加えます。これを繰り返していきます。
f(r) の判定基準の最低値は
なので、それより値の大きな log f(r) を持つものから実際に素因数分解できる値を探索すると次のようになります。
| r | log f(r) | 素因数分解の結果 |
|---|---|---|
| 538 | 10.6917 | 890 x 790 x 590 x 431 x 311 x 111 x 33 x 20 x (-1)1 |
| 591 | 10.6456 | 891 x 790 x 591 x 430 x 310 x 110 x 30 x 26 x (-1)1 |
| 593 | 9.9454 | 890 x 791 x 590 x 430 x 310 x 111 x 31 x 27 x (-1)1 |
| 623 | 6.93925 | 890 x 790 x 590 x 431 x 310 x 110 x 33 x 28 x (-1)1 |
| 671 | 10.9815 | 890 x 791 x 590 x 430 x 311 x 110 x 31 x 25 x (-1)1 |
| 709 | 11.0168 | 890 x 790 x 591 x 431 x 310 x 110 x 32 x 23 x (-1)1 |
| 751 | 7.5475 | 890 x 791 x 590 x 430 x 310 x 110 x 31 x 29 x (-1)1 |
| 769 | 10.0646 | 891 x 790 x 590 x 430 x 310 x 111 x 31 x 25 x (-1)1 |
| 826 | 6.93049 | 890 x 790 x 590 x 430 x 311 x 111 x 32 x 20 x (-1)1 |
| 827 | 7.25559 | 890 x 790 x 591 x 430 x 310 x 110 x 31 x 23 x (-1)1 |
| 829 | 7.5475 | 890 x 791 x 590 x 430 x 310 x 110 x 31 x 23 x (-1)0 |
| 833 | 7.66669 | 891 x 790 x 590 x 430 x 310 x 110 x 31 x 25 x (-1)0 |
| 839 | 6.93925 | 890 x 790 x 590 x 431 x 310 x 110 x 33 x 24 x (-1)0 |
| 848 | 6.93049 | 890 x 790 x 590 x 430 x 311 x 112 x 32 x 20 x (-1)0 |
| 857 | 9.00994 | 890 x 790 x 590 x 430 x 311 x 111 x 32 x 24 x (-1)0 |
| 879 | 7.91132 | 890 x 790 x 590 x 430 x 311 x 111 x 30 x 28 x (-1)0 |
| 881 | 9.33715 | 890 x 790 x 590 x 431 x 310 x 111 x 31 x 26 x (-1)0 |
| 943 | 7.25559 | 890 x 790 x 591 x 430 x 310 x 110 x 33 x 27 x (-1)0 |
| 947 | 10.0646 | 891 x 790 x 590 x 430 x 310 x 111 x 33 x 23 x (-1)0 |
| 967 | 9.33715 | 890 x 790 x 590 x 431 x 310 x 112 x 31 x 24 x (-1)0 |
| 1011 | 12.7272 | 891 x 790 x 590 x 431 x 310 x 111 x 30 x 23 x (-1)0 |
| 1096 | 8.2938 | 890 x 790 x 590 x 432 x 311 x 110 x 32 x 20 x (-1)0 |
| 1167 | 7.91132 | 890 x 790 x 590 x 430 x 312 x 111 x 30 x 26 x (-1)0 |
| 1189 | 13.4986 | 891 x 790 x 590 x 430 x 311 x 111 x 31 x 23 x (-1)0 |
| 1297 | 9.65349 | 890 x 790 x 591 x 430 x 310 x 111 x 31 x 29 x (-1)0 |
| 1303 | 12.0361 | 891 x 791 x 590 x 430 x 310 x 110 x 32 x 24 x (-1)0 |
次に、得られた素因数分解の結果を組み合わせて平方数となる数を生成する処理を「ガウスの消去法 ( Gaussian Elimination )」を使って行います。ガウスの消去法は連立方程式を解くためのアルゴリズムですが、これを応用することで機械的に平方数を得ることができます。
まず、左辺の係数部分に各素因数の指数を並べます ( 上位側ほど大きな素数に対する指数を表していることに注意して下さい。後述する処理方法からわかるように、出現頻度の少ないと思われる大きな素数の指数を上位に並べたほうが処理が高速化できます )。このとき、2 を法にして 0, 1 のいずれかで表します。また、右辺は単位行列を生成します。
| r | 係数行列 | 解行列 |
|---|---|---|
| 538 | 000111101 | 10000000000000000000000000 |
| 591 | 101000001 | 01000000000000000000000000 |
| 593 | 010001111 | 00100000000000000000000000 |
| 623 | 000100101 | 00010000000000000000000000 |
| 671 | 010010111 | 00001000000000000000000000 |
| 709 | 001100011 | 00000100000000000000000000 |
| 751 | 010000111 | 00000010000000000000000000 |
| 769 | 100001111 | 00000001000000000000000000 |
| 826 | 000011001 | 00000000100000000000000000 |
| 827 | 001000111 | 00000000010000000000000000 |
| 829 | 010000110 | 00000000001000000000000000 |
| 833 | 100000110 | 00000000000100000000000000 |
| 839 | 000100100 | 00000000000010000000000000 |
| 848 | 000010000 | 00000000000001000000000000 |
| 857 | 000011000 | 00000000000000100000000000 |
| 879 | 000011000 | 00000000000000010000000000 |
| 881 | 000101100 | 00000000000000001000000000 |
| 943 | 001000110 | 00000000000000000100000000 |
| 947 | 100001110 | 00000000000000000010000000 |
| 967 | 000100100 | 00000000000000000001000000 |
| 1011 | 100101010 | 00000000000000000000100000 |
| 1096 | 000010000 | 00000000000000000000010000 |
| 1167 | 000001000 | 00000000000000000000001000 |
| 1189 | 100011110 | 00000000000000000000000100 |
| 1297 | 001001110 | 00000000000000000000000010 |
| 1303 | 110000000 | 00000000000000000000000001 |
係数行列の左端の値に着目して、1 になっている行を上側から探索します。上記の例では、r = 591 が対象の行となります。次に、同じく左端が 1 になっている行を探索し、両者を足し合わせます。このとき、値は 2 を法としているので、0 + 0 = 0, 0 + 1 = 1, 1 + 0 = 1, 1 + 1 = 0 となります。これは、ビットどうしの排他的論理和を表します。上記の例では r = 769 が対象で、以下のような計算結果になります。このとき、右辺は足し合わせた行の位置を表すことに注意して下さい。
| 101000001 | 01000000000000000000000000 |
| + | + |
| 100001111 | 00000001000000000000000000 |
| || | || |
| 001001110 | 01000001000000000000000000 |
この操作を繰り返すと、一番上側の行以外は左端の値が全てゼロになります。操作が完了したら、足し合わせた一番上側の行は削除します。これは「ガウスの消去法」の「前進消去 ( Forward Elimination )」に似た処理ですが、係数は 0, 1 のいずれかであり除算をして 1 になるようにする必要はない分、通常の前進消去よりも高速に処理できます。左端の処理が全て完了したら、次は左から 2 番目という形で順番に処理を行うと、いずれ全ての係数がゼロになる行が現れます。これは、行どうしを掛け合わせたことで素因数の指数が全て偶数になり、平方数が完成したことを意味します。また、どの因数を掛け合わせたかは右辺の行を見ればわかります。上記の例では次の結果が見つかります。
| 000000000 | 10111000000000000000000000 |
これは、次の素因数を掛け合わせたことを意味します。
| r = 538 | 890 x 790 x 590 x 431 x 311 x 111 x 33 x 20 x (-1)1 |
| r = 593 | 890 x 791 x 590 x 430 x 310 x 111 x 31 x 27 x (-1)1 |
| r = 623 | 890 x 790 x 590 x 431 x 310 x 110 x 33 x 28 x (-1)1 |
| r = 671 | 890 x 791 x 590 x 430 x 311 x 110 x 31 x 25 x (-1)1 |
| ↓ | |
| 890 x 792 x 590 x 432 x 312 x 112 x 38 x 220 x (-1)4 |
これで x, y の組み合わせが見つかりました。
x - y = 123509 で、685345 との最大公約数は 113 となります。これで 685345 = 113 x 6065 と素因数分解することができました。最初に 5 を掛けているので、6065 を 5 で割って、答えは 113 x 1213 になります。
係数の長さよりも式の数のほうが多ければ、係数が全てゼロになる行は必ず出現します。これは、前進消去によって一つの式でビット列の一列が全てゼロにできることから明らかです。しかし、式の数が係数の長さ以下だった場合は出現しない可能性のほうが高くなります。また、係数がゼロになる行が出現しても、x - y が 1 や素因数分解対象の数そのものになることもあるため、必ずしも成功するとは限りません。失敗した場合は、因数基地の数を増やすか、f(r) を計算する対象を増やして再度試してみることになります。
二次ふるい法のサンプル・プログラムを以下に示します。
/* Pow : t の n 乗を計算する関数 テンプレート引数の I は、乗法・除法・減算・剰余・等号演算子が使える型である必要がある。 剰余演算子を使うため、整数型であることを前提としている。 0 の 0 乗は 0 ではなく 1 を返す。 また、べき数が負数の場合は assert を呼び出すので注意。 t べき乗される数 n べき数 */ template< class I > I Pow( const I& t, const I& n ) { assert( n >= I() ); if ( n == I() ) return( 1 ); if ( n % 2 == I() ) { I t2 = Pow( t, n / 2 ); return( t2 * t2 ); } else { return( t * Pow( t, n - 1 ) ); } } /* Log10 : 整数 n に対して 10 を底とする対数を求める */ template< class U > double Log10( U n ) { double d0 = 0; double d1 = 0; while ( n > 0 ) { U r = n % 10; n /= 10; d0 += r[0]; d0 /= 10; d1 += 1; } return( d1 + ( ( d0 == 0 ) ? 0 : std::log10( d0 ) ) ); } /* Log : 整数 n に対して自然対数を求める */ template< class U > double Log( U n ) { return( Log10( n ) / std::log10( std::exp( 1.0 ) ) ); } /* FindPrime : max を最大数とする素数を因数基地 base に登録する 但し、対象は ( n / p ) = 1 ( 平方剰余 ) となる素数 p に限定する */ void FindPrime( BigNum::Unsigned n, BigNum::Digit max, std::vector< BigNum::Digit >* base ) { Eratosthenes( max, base ); for ( std::vector< BigNum::Digit >::size_type i = 0 ; i < base->size() ; ) { if ( Jacobi( n, BigNum::Unsigned( ( *base )[i] ) ) <= 0 ) base->erase( base->begin() + i ); else ++i; } } /* FindFactor : | r^2 - n | を因数基地 base で素因数分解する exp : 各素因数の指数を登録する配列へのポインタ coef : 各素因数の指数が奇数なら true とする二値を登録する配列へのポインタ exp と coef では登録する並び順が逆であることに注意 戻り値 : 本登録を行ったら(因数基地の素因数で完全に割り切れたら) true を返す */ bool FindFactor( BigNum::Unsigned r, BigNum::Unsigned n, const std::vector< BigNum::Digit >& base, std::vector< std::vector< BigNum::Digit > >* exp, std::vector< std::vector< bool > >* coef ) { std::vector< BigNum::Digit > e( base.size() + 2, 0 ); // exp 用バッファ std::vector< bool > c( base.size() + 2, false ); // coef 用バッファ // exp と coef で登録する並び順は逆にする std::vector< BigNum::Digit >::iterator ei = e.begin(); std::vector< bool >::reverse_iterator ci = c.rbegin(); // fr = | r^2 - n | の計算 // 同時に -1 の指数を登録する BigNum::Unsigned fr; if ( r * r < n ) { fr = n - r * r; *ei = 1; *ci = true; } else { fr = r * r - n; } ++ei; ++ci; // 2 の指数の登録 while ( ( fr % 2 ) == 0 ) { ++( *ei ); fr /= 2; } if ( ( *ei % 2 ) > 0 ) *ci = true; ++ei; ++ci; // 3 以上の素因数の指数の登録 for ( std::vector< BigNum::Digit >::const_iterator b = base.begin() ; b != base.end() ; ++b ) { while ( ( fr % ( *b ) ) == 0 ) { ++( *ei ); fr /= *b; } if ( ( *ei % 2 ) > 0 ) *ci = true; ++ei; ++ci; } // 完全に割り切れた場合だけ本登録を行う if ( fr == 1 ) { exp->push_back( e ); coef->push_back( c ); return( true ); } else { return( false ); } } /* SearchEvenRow : 指数が全て偶数となった(coefの要素が全てゼロの)行を探索する 戻り値 : 指数が全て偶数となった行の番号 + 1 (ゼロなら見つからなかった) */ size_t SearchEvenRow( const std::vector< std::vector< bool > >& coef ) { size_t rows = coef.size(); size_t cols = coef[0].size(); for ( size_t r = 0 ; r < rows ; ++r ) { size_t c = 0; for ( ; c < cols ; ++c ) if ( coef[r][c] ) break; if ( c >= cols ) return( r + 1 ); } return( 0 ); } /* GaussianElimination : 2 を法とする数値に対するガウスの消去法 coef : 係数行列 ans : 解行列 戻り値 : 指数が全て偶数となった行の番号 + 1 (ゼロなら見つからなかった) */ size_t GaussianElimination( std::vector< std::vector< bool > >* coef, std::vector< std::vector< bool > >* ans ) { // 係数行列の行列数を取得する size_t rows = coef->size(); if ( rows == 0 ) return( 0 ); size_t cols = (*coef)[0].size(); for ( size_t c = 0 ; c < cols ; ++c ) { // 左端から順に 1 を持つ最初の行を探索する size_t sr = 0; while ( ! (*coef)[sr][c] ) { ++sr; if ( sr >= rows ) break; } // 見つかった行を、同じ列に 1 を持つ行に加算する for ( size_t r = sr + 1 ; r < rows ; ++r ) { if ( (*coef)[r][c] ) { for ( size_t i = 0 ; i < cols ; ++i ) (*coef)[r][i] = (*coef)[r][i] ^ (*coef)[sr][i]; for ( size_t i = 0 ; i < (*ans)[0].size() ; ++i ) (*ans)[r][i] = (*ans)[r][i] ^ (*ans)[sr][i]; } } // 加算した行は削除する if ( sr < rows ) { coef->erase( coef->begin() + sr ); ans->erase( ans->begin() + sr ); --rows; if ( rows == 0 ) return( 0 ); } // 全てがゼロの要素からなる係数を持った行を探索する size_t evenRow = SearchEvenRow( *coef ); if ( evenRow > 0 ) return( evenRow ); } return( 0 ); } /* FindFactorFromSquare : ガウスの消去法を使って完全平方を見つけ、素因数分解を試す coef : 連立方程式の係数行列 ans : 連立方程式の解行列 exp : 各因数基地の指数 r : f(r) が因数基地で割り切れた平方完成の候補 base : 因数基地 n : 素因数分解する対象の数 a, b : 分解した数を返す変数へのポインタ 戻り値 : 素因数分解できたら true を返す */ bool FindFactorFromSquare ( std::vector< std::vector< bool > >* coef, std::vector< std::vector< bool > >* ans, const std::vector< std::vector< BigNum::Digit > >& exp, const std::vector< BigNum::Unsigned >& r, const std::vector< BigNum::Digit >& base, const BigNum::Unsigned& n, BigNum::Unsigned* a, BigNum::Unsigned* b ) { for ( ; ; ) { // ガウスの消去法 size_t i = GaussianElimination( coef, ans ); if ( i == 0 ) return( false ); --i; // 平方数が見つかったら x, y を計算する std::vector< BigNum::Digit > expSum( base.size() + 1, 0 ); // 指数の和 BigNum::Unsigned x( 1 ); for ( std::vector< BigNum::Unsigned >::size_type k = 0 ; k < (*ans)[i].size() ; ++k ) { if ( ! (*ans)[i][k] ) continue; x *= r[k]; x %= n; for ( std::vector< BigNum::Digit >::size_type j = 1 ; j < exp[k].size() ; ++j ) { expSum[j - 1] += exp[k][j]; } } BigNum::Unsigned y( Pow( BigNum::Unsigned( 2 ), BigNum::Unsigned( expSum[0] / 2 ) ) ); for ( std::vector< BigNum::Digit >::size_type k = 0 ; k < expSum.size() - 1 ; ++k ) { y *= Pow( BigNum::Unsigned( base[k] ), BigNum::Unsigned( expSum[k + 1] / 2 ) ); y %= n; } // 一度平方数となった行は削除 coef->erase( coef->begin() + i ); ans->erase( ans->begin() + i ); // x - y と n の最大公約数が真約数なら終了 BigNum::Unsigned g = gcd( n, ( x > y ) ? x - y : y - x ); if ( g != 1 && g != n ) { *a = g; *b = n / g; break; } } return( true ); } /* QSieve : 二次篩 (QS) による n の素因数分解 n : 素因数分解する対象の数 a, b : 分解した数を返す変数へのポインタ baseMax : 因数基地(Factor Base)の最大素因数 rMax : 探索を行う最大幅 ( n を中央値として √n - rMax / 2 から √n + rMax / 2 までを対象とする 戻り値 : 素因数分解できたら true を返す */ bool QSieve( BigNum::Unsigned n, BigNum::Unsigned* a, BigNum::Unsigned* b, BigNum::Digit baseMax, BigNum::Digit rMax ) { // r^2 - n が 8 を因数として持つようにするため // n は法を 8 として 1 に合同になるようにする BigNum::Unsigned rem = n % 8; n *= rem; // r の最小値 BigNum::Unsigned r0 = SquareRoot( n ) - rMax / 2 + 1; // 因数基地を求める std::vector< BigNum::Digit > base; FindPrime( n, baseMax, &base ); if ( base[0] == 2 ) base.erase( base.begin() ); // 2 は除く // 因数基地を法とする n の平方根を求める std::vector< BigNum::Digit > sqrt( base.size() ); for ( size_t i = 0 ; i < base.size() ; ++i ) { sqrt[i] = QC_Solver( n, BigNum::Unsigned( base[i] ) )[0]; } // 因数基地の素数の対数を割り切れる対象に加算する std::vector< double > logSum( rMax, double() ); for ( std::vector< double >::size_type i = ( ( r0 + 1 ) % 2 )[0] ; i < logSum.size() ; i += 2 ) logSum[i] += std::log( 8 ); for ( std::vector< BigNum::Digit >::size_type i = 0 ; i < sqrt.size() ; ++i ) { BigNum::Digit start = ( r0 % base[i] )[0]; if ( start < sqrt[i] ) start = sqrt[i] - start; else start = base[i] + sqrt[i] - start; for ( size_t u = start ; u < logSum.size() ; u += base[i] ) logSum[u] += std::log( base[i] ); start += base[i] - 2 * sqrt[i]; for ( size_t u = start ; u < logSum.size() ; u += base[i] ) logSum[u] += std::log( base[i] ); } // ターゲット値の計算 double target = Log( n ) / 2.0 + std::log( rMax ) - 1.5 * log( base.back() ); // ガウスの消去法用の係数行列を求める std::vector< std::vector< BigNum::Digit > > exp; std::vector< std::vector< bool > > coef; std::vector< BigNum::Unsigned > r; for ( size_t i = 0 ; i < logSum.size() ; ++i ) { if ( logSum[i] <= target ) continue; if ( FindFactor( r0 + i, n, base, &exp, &coef ) ) { r.push_back( r0 + i ); } } // 解行列は単位行列で初期化 std::vector< std::vector< bool > > ans; for ( size_t i = 0 ; i < coef.size() ; ++i ) { ans.push_back( std::vector< bool >( coef.size(), false ) ); ans.back()[i] = true; } // ガウスの消去法を使い、平方数となる組み合わせを探す while ( FindFactorFromSquare( &coef, &ans, exp, r, base, n, a, b ) ) { if ( *a % rem == 0 ) *a /= rem; else *b /= rem; if ( *a != 1 && *b != 1 ) return( true ); // 割り算の後で 1 になっていないか再確認 } return( false ); }
今まで紹介した素因数分解と比較するとかなり長いプログラムになっています。関数 QSieve がメインの関数で、素因数分解する対象の数 n を渡して結果をポインタ *a, *b に返します。また、baseMax を因数基地の最大素因数、rMax を f(r) を求める幅として渡します。計算には以前作成した「多倍長整数クラス ( BigNum::Unsigned )」を利用します。BigNum::Digit は多倍長整数の一桁分 ( 配列とみなしたときの要素の型 ) を表し、因数基地の最大素因数や f(r) を求める幅についてはこの型の大きさに制限されることに注意して下さい。
多倍長整数の対数を計算する必要があるため、関数 Log10 を用意しています。実装している内容は非常にシンプルで、
N = 0.xxx... x 10m より
log10 N = m + log10 0.xxx...
となることを利用して計算を行っています。また、Log10 を使えば、底の変換公式
を使うことで自然対数などを求めることもできます。
関数 FindPrime は、因数基地を得るための関数で、max までの素数 p の中からルジャンドル記号 ( n / p ) = 1 ( 平方剰余 ) となるものを配列 base に登録します。素数の探索には「エラトステネスのふるい」を利用しています。
因数基地を求めたら、その中の各素数 p に対して x2 ≡ n ( mod p ) の解 x を求めます。これには「リュカ数列」のサンプル・プログラム QC_Solver を利用します。あとは前述の通り、因数基地の素数の対数を加算し、判定値 target を超えたものに対して関数 FindFactor を使って素因数分解を試みます。素因数分解に成功したものだけを係数行列として登録し、ガウスの消去法 GaussianElimination を使って完全平方を見つけ、素因数分解できるかを試します。
フェルマーのアルゴリズムを除く各素因数分解アルゴリズムについて、処理速度を計測した結果を以下に示します。計測は、ランダムに作成した素数を二つ掛け合わせた値を 10 個作成して行い、その処理時間 ( 秒 ) の平均値を求めています。表の N は素因数分解したときの素数の桁数を表します。従って、N = 3 のときに得られる合成数は、100 x 100 = 10000 ( 5 桁 ) から 999 x 999 < 1000000 ( 6 桁 ) の間となります。
ポラードの ρ 法において、多項式には x2 + 1 を使い、初期値を 2 としました。ポラードの p - 1 法の底は 2 としています。ウィリアムズの p + 1 法において、リュカ数列のパラメータ P は 7 とし、二次ふるい法においては因数基地の素因数の最大値を 400、f(r) の幅を 10000 としました。
| |||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||
二次ふるい法以外は、桁数の増大に従って処理時間も急激に増大します。二次ふるい法は桁数よりも因数基地の大きさや f(r) の幅に依存して処理速度が増大します。
残念ながら、二次ふるい法でも素因数分解に成功した最大桁数は素因数が 12 桁のところまでで、約 10 秒かかりました。このときのパラメータは因数基地の素因数が 30000 未満、f(r) の幅が 200000 です。パラメータをもっと大きくすればさらに大きな桁数でも成功すると思いますが、かなりの時間がかかるようになるでしょう。
xi ≡ f( xi-1 ) ( mod N ) より xi - f( xi-1 ) は N で割り切れるので、
を満たす整数 k が存在します。さらに d が N の素因数ならば
を満たす整数 k' が存在します。同様に、yi ≡ xi ( mod d ) なので、
xi - yi = kid --- (2)
xi-1 - yi-1 = ki-1d --- (3)
を満たす整数 ki, ki-1 が存在します。(1) を(2) に代入して整理すると
となり、両辺から f( yi-1 ) を引くと
| yi - f( yi-1 ) | = | f( xi-1 ) - f( yi-1 ) + k'd - kid |
| = | f( xi-1 ) - f( xi-1 - ki-1d ) + k'd - kid |
となります。但し、二番目の変形には (3) を使っています。f( xi-1 ) - f( xi-1 - ki-1d ) が d で割り切れるなら、右辺は d で割り切れるので証明できたことになります。そこで、
とすると、
| f( xi-1 ) - f( xi-1 - ki-1d ) | = | Σk( akxi-1k ) - Σk( ak( xi-1 - ki-1d )k ) |
| = | Σk( akxi-1k ) - Σk( akΣl( kClxi-1l( -ki-1d )k-l ) ) | |
| ≡ | Σk( akxi-1k ) - Σk( akkCkxi-1k ) ( mod d ) | |
| = | Σk( akxi-1k ) - Σk( akxi-1k ) = 0 |
となって、f( xi-1 ) - f( xi-1 - ki-1d ) が d で割り切れることが証明され、命題も証明されたことになります。
k と n が互いに素なら、ka ≡ kb ( mod n ) のとき a ≡ b ( mod n ) が成り立つのでした ( 「暗号化アルゴリズム (3) 公開鍵暗号」の「3) 合同式 ( Modular Arithmetic )」参照 )。特に、n が素数 p ならば、k < p のとき k と p は必ず互いに素になります。
ここで、素数 p を法として a / b がどんな値に合同になるのかを考えます。a が b に割り切れるとは限らないので、普通に考えれば整数ではなく有理数となりますが、
と考えることで、ちょうど割り切ることのできるような k を見つければ整数にできそうです。例として 5 / 3 ( mod 7 ) を考えると、
なので、4 に合同であると考えることができます。このとき、
となって、乗算の逆算となっていることに注意して下さい。
任意の数 a, b に対して a / b ≡ c ( mod p ) となる c が存在するかについては、a / b - c = kp より a - bc = kbp = dp と変形することで
となる c, d が存在すれば成り立ちます。ここで、「一次方程式定理」より、p, b が互いに素であれば
は必ず解 x, y を持つので、両辺を a 倍すれば解が得られることになります。さらに上式は
であることを示しているので、
ということになり、a / b を計算する代わりに、一次方程式 bx + py = 1 を求めて ax を計算することでも c が得られることになります。
本章にあった合同式 21-p ( mod p ) は、2p-1 ( mod p ) の逆数です。2p-1 ≡ 1 ( mod p ) なので、
より 21-p ≡ 1 ( mod p ) となります。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |