「ニューラル・ネットワーク ( Neural Network ; NN )」とは、生物学的には相互に接続された神経細胞「ニューロン ( Neuron )」から成るネットワークを指します。これをコンピュータ上で人工的に表現したものも「(人工)ニューラル・ネットワーク ( Artifical Neural Network ; ANN )」と呼ばれます。「自己組織化写像 ( Self-organizing Maps ; SOM )」はニューラル・ネットワークの一種であり、1980 年代にフィンランドの教授である「テウヴォ・コホネン ( Teuvo Kohonen )」によって提唱されました。今回はこの自己組織化写像を紹介したいと思います。
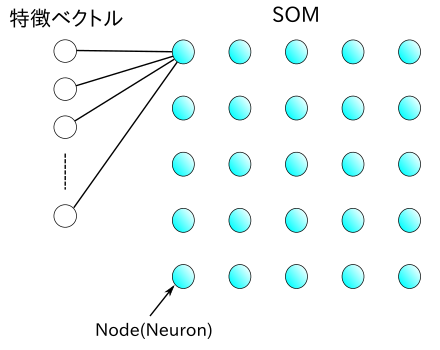
「自己組織化写像 ( Self-organizing Maps ; SOM )」の構成を下図に示します。
|
SOM は「ノード ( Node )」または「ニューロン ( Neuron )」と呼ばれる要素で構成されます。各ノードは、入力される特徴ベクトルと同じ次元の重みベクトルと SOM 上の位置が関連付けられています。ノードはある規則的な配置をとり、通常は一次元や二次元構造となっています。上図の例では二次元の格子状配置になっていますが、同じ二次元構造でも六角形に配置されるようなものもあります。また、全てのノードは特徴ベクトルの各要素が入力されるように接続されています。上図では代表のノードだけその様子を示しています。
特徴ベクトルが入力されると、重みベクトルと最も "近い" ノードを全ての中から見つけ出します。"近い" という尺度には通常ユークリッド距離が利用されます。この最も "近い" ノードは「BMU ( Best Matching Unit )」と呼ばれます。どんなに差が小さくても BMU は必ず一つだけとなります。このような "勝者が総取り" する ( Winner-Take-All ) プロセスを「競合学習 ( Competitive Learning )」といい、SOM の大きな特徴となっています。
BMU が決まったら、それを中心とした近傍のノードを含め、重みベクトルを更新します。更新式は以下のようになります。
m は BMU の近傍にあるノードを表し、wm は m の重みベクトル、x は入力された特徴ベクトル、添字の t は学習回数を表します。Θ は BMU と m との距離及び t の値によって決まる係数で、BMU との距離が離れているほど、また t が大きくなるほど小さな値をとります。
まずは、SOM の構造を定義したクラスを以下に示します。
/** SOM ( Self-Organizing Maps ; 自己組織化写像 ) **/ class SOM { typedef std::vector< double > Coef; // 係数ベクトル(ニューロン)の型 Matrix< Coef > outLayer_; // 出力層 size_t dimension_; // 係数の次元 unsigned int cnt_; // 入力回数 unsigned int maxCnt_; // 最大入力回数 bool hTorus_; // 水平方向に連結 bool vTorus_; // 垂直方向に連結 /* 勝ちニューロン(Winner)の位置を求める in 入力層の係数ベクトル row,col 求める位置を保持する変数へのポインタ */ void getWinner( const Coef& in, size_t* row, size_t* col ); public: /* 出力層の大きさ ( row, col ) と係数ベクトルの次元 dim、係数の最大値 max、最大学習回数 maxCnt を指定して構築 */ SOM( size_t row, size_t col, size_t dim, double max, unsigned int maxCnt, bool hTorus, bool vTorus ) { init( row, col, dim, max, maxCnt, hTorus, vTorus ); } /* init : 出力層を初期化する 出力層は乱数で初期化され、学習回数もリセットされる。 row,col 出力層の大きさ dim 係数ベクトルの次元 max 係数の最大値(乱数生成の最大値として利用する) maxCnt 最大学習回数 */ void init( size_t row, size_t col, size_t dim, double max, unsigned int maxCnt, bool hTorus, bool vTorus ); /* training : 学習を行う in 入力する係数ベクトル nFunc 近傍関数 戻り値 : 学習回数が最大学習回数以上なら false を返す */ bool training( const std::vector< double >& in, const SOM_NeighborhoodFunction& nFunc ); /* operator[] : 出力層の行 row の定数反復子を返す SOM オブジェクト som から som[r][c][i] で r 行 c 列の i 番目の要素へアクセスできる */ Matrix< std::vector< double > >::const_iterator operator[]( size_t row ) const { return( outLayer_.row( row ) ); } // rows : 出力層の行数を返す size_t rows() const { return( outLayer_.rows() ); } // cols : 出力層の列数を返す size_t cols() const { return( outLayer_.cols() ); } // coefSize : 係数ベクトルのサイズを返す size_t coefSize() const { return( dimension_ ); } }; /* SOM::init : SOM の初期化 row,col : 出力層の大きさ dim : 係数ベクトルの次元 max : 係数の最大値(乱数生成の最大値として利用する) maxCnt : 最大学習回数 */ void SOM::init( size_t row, size_t col, size_t dim, double max, unsigned int maxCnt, bool hTorus, bool vTorus ) { assert( row > 0 && col > 0 && dim > 0 ); // 出力層を乱数でリセット dimension_ = dim; outLayer_.assign( row, col ); for ( Matrix< Coef >::iterator out = outLayer_.begin() ; out != outLayer_.end() ; ++out ) { out->resize( dimension_ ); for ( Coef::iterator coef = out->begin() ; coef != out->end() ; ++coef ) *coef = static_cast< double >( rand() ) * max / ( static_cast< double >( RAND_MAX ) + 1 ); } // 学習回数のリセット cnt_ = 0; maxCnt_ = maxCnt; // 水平・垂直方向に連結しているか hTorus_ = hTorus; vTorus_ = vTorus; } /* SOM::getWinner : 勝ちニューロンの位置を取得する in に最も近いニューロンの位置を ( row, col ) に返す */ void SOM::getWinner( const Coef& in, size_t* row, size_t* col ) { assert( in.size() == dimension_ ); double min = std::numeric_limits< double >::max(); for ( Matrix< Coef >::size_type r = 0 ; r < outLayer_.rows() ; ++r ) { for ( Matrix< Coef >::size_type c = 0 ; c < outLayer_.cols() ; ++c ) { double d = L2Distance()( in.begin(), in.end(), outLayer_[r][c].begin() ); if ( d < min ) { *row = r; *col = c; min = d; } } } } /* GetMinRange : 更新範囲の最小値を決定する winner : 勝ちニューロン range : 更新範囲の幅(winner からの距離) isTorus : 端を連結するなら true */ int GetMinRange( size_t winner, size_t range, bool isTorus ) { if ( range <= winner || isTorus ) return( static_cast< int >( winner ) - range ); // 範囲外で端を連結させない場合はゼロを返す return( 0 ); } /* GetMinRange : 更新範囲の最大値を決定する winner : 勝ちニューロン range : 更新範囲の幅(winner からの距離) size : 出力層の大きさ isTorus : 端を連結するなら true 戻り値 : 学習回数が最大学習回数以上なら false を返す */ int GetMaxRange( size_t winner, size_t range, size_t size, bool isTorus ) { if ( winner + range < size || isTorus ) return( winner + range ); // 範囲外で端を連結させない場合は最大値を返す return( size - 1 ); } /* toSizeT : int 型の更新範囲 i を size_t 型の SOM の位置に変換する size : 出力層の大きさ */ size_t toSizeT( int i, size_t size ) { while ( i < 0 ) i += size; return( i % size ); } /* SOM::training : 学習を行う in : 入力する係数ベクトル nFunc : 近傍関数 戻り値 : 学習回数が最大学習回数以上なら false を返す */ bool SOM::training( const Coef& in, const SOM_NeighborhoodFunction& nFunc ) { assert( &in != 0 && &nFunc != 0 ); if ( cnt_ >= maxCnt_ ) return( false ); size_t wr, wc; getWinner( in, &wr, &wc ); // 勝ちニューロン(BMU)の位置を取得する // 近傍関数の値が有効な範囲をチェックする size_t range = 0; while ( nFunc( 0, 0, range, 0, cnt_, maxCnt_ ) > 1E-9 ) ++range; // 更新範囲を決定 int minR = GetMinRange( wr, range, vTorus_ ); int minC = GetMinRange( wc, range, hTorus_ ); int maxR = GetMaxRange( wr, range, outLayer_.rows(), vTorus_ ); int maxC = GetMaxRange( wc, range, outLayer_.cols(), hTorus_ ); // 出力層の更新 for ( int mr = minR ; mr <= maxR ; ++mr ) { for ( int mc = minC ; mc <= maxC ; ++mc ) { Coef& out = outLayer_[toSizeT( mr, outLayer_.rows() )][toSizeT( mc, outLayer_.cols() )]; for ( size_t i = 0 ; i < out.size() ; ++i ) { double d = nFunc( wr, wc, mr, mc, cnt_, maxCnt_ ) * ( in[i] - out[i] ); out[i] += d; } } } ++cnt_; return( true ); }
メンバ変数の outLayer_ がノードを保持する層 ( 出力層 ) を表し、その要素を Coef 型 ( 実体は double 型の配列 ) とする二次元配列 ( 行列 ) の Matrix 型で表現されています。従って、要素は重みベクトルを表し、行列の添字がノードの位置を意味することになります。cnt_ は係数ベクトルが何度入力されたか ( すなわち何回訓練されたか ) を保持し、その最大回数は maxCnt_ とします。
outLayer_ の型 Matrix は実装はされていませんが、行数を返す rows と列数を返す cols をメンバ関数として持っています。また、assign 関数は行列の大きさを変更するときに使い、begin と end は全要素へアクセスするときの反復子の開始と末尾の次を表しています。
SOM のメンバ関数 operator[] の中で outLayer_.row という Matrix のメンバ関数が登場します。これは、Matrix の行を表すランダム・アクセス反復子を返す関数で、例えば outLayer_.row( r )で r 行目の行の先頭 ( 第 1 列目 ) へアクセスすることができます。従って、SOM に対して operator[r][c] を呼び出すことで r 行 c 列目の要素にアクセスでき、要素は double 型の配列なので、operator[r][c][i] で r 行 c 列目の配列の i 番目の要素へアクセスできることを意味します。
SOM の初期化はメンバ関数 init が行います。出力層は乱数でリセットされ、学習回数もゼロ回に変更されます。training を呼び出すことで一回の学習が行われますが、ここでは getWinner を使って勝ちニューロン ( BMU ) を決定し、その近傍のノードを更新します。更新時に SOM_NeighborhoodFunction 型の関数オブジェクトを nFunc 利用していますが、これが先述した係数 Θ になります ( 実装については後述します )。なお、getWinner の中で登場する関数オブジェクト L2Distance は「パターン認識 (1) 凝集型クラスタリング」の中のサンプル・プログラムにて紹介しています。
outLayer_ は行列なので表現できるノードの配置は二次元となります。但し、行数や列数を 1 とすることで一次元にすることは可能です。三次元以上を表現したり、配置を格子以外にする場合は outLayer_ の型を見直す必要があります。また、メンバ変数の中に hTorus_ と vTorus_ があり、これを true にすることで水平・垂直方向に連結した構造とすることができます。このような構造を「トーラス ( Torus 」といい、例えば垂直方向に連結した場合は筒状の構造となり、水平方向にも連結すればドーナツ型の構造となります。
係数 Θ 用の関数オブジェクト SOM_NeighborhoodFunction のサンプル・プログラムを以下に示します。
/** SOM 専用近傍関数基底クラス **/ struct SOM_NeighborhoodFunction { /* operator() : 近傍関数の値を返す wr,wc 勝ちニューロン(BMU)の位置 mr,mc 更新するニューロンの位置 cnt 学習回数 maxCnt 最大学習回数 */ virtual double operator()( double wr, double wc, double mr, double mc, unsigned int cnt, unsigned int maxCnt ) const = 0; // 仮想デストラクタ(何もしない) virtual ~SOM_NeighborhoodFunction() {} }; /** @brief L2 ノルムを使った SOM 専用近傍関数 **/ class SOM_L2_NeighborhoodFunction : public SOM_NeighborhoodFunction { double c_; // スケール調整のための定数 public: // スケール調整のための定数 c を指定して構築 SOM_L2_NeighborhoodFunction( double c ) : c_( c ) { assert( c_ > 0 ); } // 近傍関数の値を返す virtual double operator()( double wr, double wc, double mr, double mc, unsigned int cnt, unsigned int maxCnt ) const; }; /* SOM_L2_NeighborhoodFunction::operator() : 近傍関数の値を返す wr,wc : 勝ちニューロン(BMU)の位置 mr,mc : 更新するニューロンの位置 cnt : 学習回数 maxCnt : 最大学習回数 */ double SOM_L2_NeighborhoodFunction::operator()( double wr, double wc, double mr, double mc, unsigned int cnt, unsigned int maxCnt ) const { if ( cnt == maxCnt ) return( 0 ); return( c_ * std::exp( -( ( wr - mr ) * ( wr - mr ) + ( wc - mc ) * ( wc - mc ) ) / std::pow( 1.0 - static_cast< double >( cnt ) / maxCnt, 2.0 ) ) ); }
Θ の式は以下のように実装されています。
上式において、w = ( wx, wy ) は BMU の、m = ( mx, my ) は対象となる近傍ノードの位置を表しています。また、t は学習回数、T はその最大回数で、C はスケール調整のための定数です。BMU より遠いほど、また学習回数が増加するほど Θ の値は小さくなります。なお、Θ を計算する式の実装内容は変更できるように純粋仮想関数の形で定義してあります。
下図は、SOM に 8 色の色コード ( 赤・青・緑・紫・水色・黄色・白・黒 ) をランダムに入力したときの様子を示したものです。SOM は 8 x 8 の二次元構造で、最大回数 T は 10000 とし、t は訓練回数を表しています。また、Θ に対するスケール調整のための定数は 1 です。
| t=0 (初期状態) | t=100 | t=200 | t=500 | t=1000 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
訓練を重ねるごとに、8 色の領域に分割されていく様子がこの結果から読み取れます。
下図は、トーラスに対して同じ訓練を行った結果です。色コードが両端でつながったような形になります。また、端をつながない場合よりも各色コードが等しく分配されています。
| t=0 (初期状態) | t=100 | t=200 | t=500 | t=1000 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
SOM によって高次元の特徴ベクトルはより低次元の一次元や二次元の像に写されたことになります。学習のとき BMU の近傍にあるノードほど強い影響を受けることから、距離の近いノードはより近い重みベクトルを持つことになります。この様子を下図に示します。
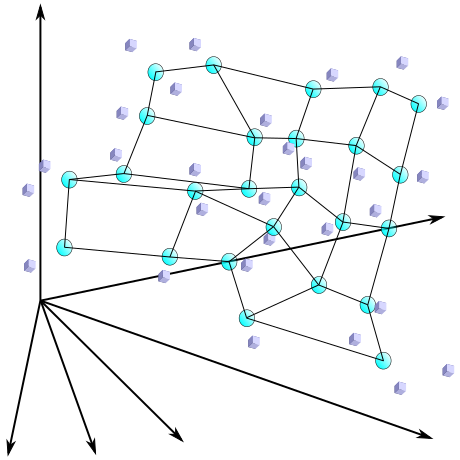 |
これにより、視覚的にとらえるには困難な高次元の特徴ベクトルを見やすい形に表現することができます。先に示した色コードの例は、赤・青・緑の三原色からなる三次元の特徴ベクトルを二次元に写像したことになります。
「巡回セールスマン問題 ( Traveling Salesman Problem ; TSP )」とは、セールスマンが複数の都市を各々一回だけ巡回するときに最短のルートを求める問題です。この問題に対しては現在のところ効率のよいアルゴリズムは見つかっていません。ちなみに全ての経路を総当たりで解く場合の計算量は n! に比例するので、10 個程度の都市でも数百万通りの計算が必要になります。
各都市の位置を特徴ベクトルとして一次元 SOM に写像すると、近傍にある都市どうしが接続された形でマップが形成されます。得られた結果は最適解とは限りませんが、近似解を得ることはできます。以下に、実際に試した結果を示します。都市の数は 20 とし、写像する SOM もサイズ 20 で、水平方向につながったリング構造としています。
 |
上図において、バツはランダムに配置した初期値、丸は訓練後の位置、三角は各都市の位置をそれぞれ表しています。ほとんどの都市は訓練後の SOM の位置と重なっていますが、残念ながら 2 点ほど外れた都市もあります。しかし、最適解ではなくても短時間である程度適したルートが得られます。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |