|
| |||||||||||||||||||||||||||||||||||||||||||
今回から、探索・検索アルゴリズムを紹介します。一言で探索アルゴリズムと言っても種類は様々で、一次元配列から目的のデータを探索したり、文字列からあるパターンを見つけ出すなどの処理が挙げられます。今回は、データ列の中から目的のデータを抽出するアルゴリズムについて紹介したいと思います。
あるデータ列から特定の要素を検索する場合、最も単純なのは、データの先頭から一つずつ要素を比較する方法です。書類の山から目的のものを探すとき、一番上から順に見ていくのと考え方は同じです。この方法は「線形探索(Linear Search)」と呼ばれています。
アルゴリズムとしては非常に単純なものなので、早速サンプルを示したいと思います。
/* LinearSearch : 線形探索 In first, last : 入力反復子(探索開始と末尾の次) const T& val : 探索する要素 戻り値 : 見つかった位置(見つからなければlastを返す) */ template<class In, class T> In LinearSearch( In first, In last, const T& val ) { while ( first != last ) { if ( *first == val ) return( first ); ++first; } return( last ); }
上記プログラムは、反復子 first から last の一つ前までの範囲の中から指定した要素 val を検索し、最初に見つかった要素の反復子を返すというシンプルなものです。引数は、STL(Standard Template Library) にある関数 find() に合わせ、データ型が可変となるようテンプレートを利用しています。In は「入力反復子(Input Iterator)」を表し、例えばキーボードから入力されたデータやファイルなどを対象に探索処理を行うことも可能です。反復子については「ソート・ルーチン (1) 遅いソート・ルーチン」の中の「1) 交換ソート(Exchange Sort)」にあるサンプル・プログラムなどでも紹介しています。
STL には、値が一致したかどうかを判定するための関数を指定することができるように find_if() が用意されています。例えば、浮動小数点数の等値判定に対して誤差を許容するような判断ができるようにしたり、文字列に対して部分一致を等しいと認めるような判定処理を組み込むことが可能になります。このプログラムは、以下のような形になります。
/* LinearSearch_If : 線形探索(叙述関数による等値判断) In first, last : 入力反復子(探索開始と末尾の次) Pred pred : 叙述関数 戻り値 : 見つかった位置(見つからなければlastを返す) */ template<class In, class Pred> In LinearSearch_If( In first, In last, Pred pred ) { while ( first != last ) { if ( pred( *first ) ) return( first ); ++first; } return( last ); }
LinearSearch_If を使って次のように処理をすれば、先ほど示したサンプル・プログラム LinearSearch と同等の結果が得られます。
/* Eq : 等値判定用関数オブジェクト */ template<class T> class Eq { T val_; // 判定対象の値 public: // コンストラクタ(比較する値を渡す) Eq( T val ) : val_( val ) {} // 等値判定 bool operator()( const T& val ) { return( val == val_ ); } }; template<class In, class T> In LinearSearch( In first, In last, const T& val ) { return( LinearSearch_If( first, last, Eq<T>( val ) ) ); }
bool 値を返す関数は「叙述関数(Predicate Functions)」と呼ばれます。Eq は叙述関数オブジェクトであり、インスタンスを生成するときに比較対象の値を渡して、その値と等しければ true、異なれば false を返すようになっています。
LinearSearch や LinearSearch_If を利用して一致した要素に対して何らかの処理をしたい場合は、次のようなプログラムを実装すれば実現できます。
/* LinearSearch_Op : 線形探索を行い、一致した要素を op で処理する In first, last : 入力反復子(探索開始と末尾の次) const T& val : 探索する要素 Op op : 処理関数オブジェクト 戻り値 : 関数オブジェクト op */ template<class In, class T, class Op> Op LinearSearch_Op( In first, In last, const T& val, Op op ) { for ( ; ; ) { first = LinearSearch( first, last, val ); if ( first == last ) break; op( first ); ++first; } return( op ); } /* LinearSearch_If_Op : 線形探索を行い、一致した要素を op で処理する(叙述関数による等値判断) In first, last : 入力反復子(探索開始と末尾の次) Pred pred : 叙述関数 Op op : 処理関数 戻り値 : 関数オブジェクト op */ template<class In, class Pred, class Op> Op LinearSearch_If_Op( In first, In last, Pred pred, Op op ) { for ( ; ; ) { first = LinearSearch_If( first, last, pred ); if ( first == last ) break; op( first ); ++first; } return( op ); }
例えば、一致した要素数を得たい場合は、次のように実装すれば実現することができます。
/* Count : 要素数カウント用関数オブジェクト */ template<class In> class Count { // カウンタ typename std::iterator_traits<In>::difference_type cnt_; public: // コンストラクタ Count() : cnt_( 0 ) {} // カウントアップする void operator()( In inIt ) { ++cnt_; } // 結果出力 void print() const { cout << "Total : " << cnt_ << endl; } }; // カウンタ用関数オブジェクト Count< vector<unsigned int>::iterator > cnt; cnt = LinearSearch_Op( first, last, 0, cnt ); cnt.print();
この処理によって、要素がゼロである反復子の数を返すことができます。しかし、関数オブジェクト Count のメンバ関数 operator() は要素が一致した反復子を引数として受け取っているものの、それは利用していないので、この実装には少し無駄があります。実際、STL の中には、一致した要素の数を返す専用の関数 count が用意されていることからもわかるように、カウント用には専用の関数を用意した方が効率よく処理できます。
サンプル・プログラムの中にある std::iterator_traits<In>::difference_type という型は、反復子の特性を表すテンプレート・クラス iterator_traits の中で定義されています。iterator_traits は次のような内容です。
template<class Iter> struct iterator_traits { typedef typename Iter::iterator_category iterator_category; // 反復子のカテゴリ typedef typename Iter::value_type value_type; // 要素の型 typedef typename Iter::difference_type difference_type; // 反復子間の距離を表現する型 typedef typename Iter::pointer pointer; // ->() の戻り値(ポインタ) typedef typename Iter::reference reference; // *() の戻り値(参照) };
この定義からわかるように、iterator_traits ではテンプレート引数 Iter が上に示した五つの型を持っていることを前提としています。反復子の基底クラス iterator は次のような定義内容になります。
template<class Cat, class T, class Dist = ptrdiff_t, class Ptr = T*, class Ref = T&> struct iterator { typedef Cat iterator_category; // 反復子のカテゴリ typedef T value_type; // 要素の型 typedef Dist difference_type; // 反復子間の距離を表現する型 typedef Ptr pointer; // ->() の戻り値(ポインタ) typedef Ref reference; // *() の戻り値(参照) };
iterator から派生したクラスは全て五つの型を持っていることが保証されます。Dist は反復子間の距離を表現する型を表しますが、デフォルトでは ptrdiff_t が指定されていて、これはポインタ間の距離を表す型としてヘッダ・ファイル stddef.h に定義されています。ポインタどうしの減算をした結果はこの型の変数に代入することになります。また、Ptr は間接参照演算子 -> の多重定義関数 operator->() の戻り値の型を、Ref は間接参照演算子 * の多重定義関数 operator*() の戻り値の型をそれぞれ表し、通常は要素に対するポインタ・参照を指定することになるので、デフォルトもそのようになっています。
このように反復子が定義されていれば、カウンタ cnt_ の型は In::difference_type でもよさそうに見えますが、通常のポインタは iterator から派生してはいないため、配列などに適用することができなくなります。例えば
void f( const char* s, const char* e, char c )
{
ptrdiff_t n = count( s, e + 1, c );
}
に対しては In は const char* を意味するので、戻り値の方は const char*::difference_type となりますが、これは有効な型ではありません。そこで、iterator_traits を使って、通常のポインタ用のクラスを用意します。
template<class T> struct iterator_traits<T*> { typedef typename random_access_iterator iterator_category; // 反復子のカテゴリ(ランダム・アクセス反復子) typedef typename T value_type; // 要素の型 typedef typename ptrdiff_t difference_type; // 反復子間の距離を表現する型 typedef typename T* pointer; // ->() の戻り値(ポインタ) typedef typename T& reference; // *() の戻り値(参照) }; template<class T> struct iterator_traits<const T*> { typedef typename random_access_iterator iterator_category; // 反復子のカテゴリ(ランダム・アクセス反復子) typedef typename T value_type; // 要素の型 typedef typename ptrdiff_t difference_type; // 反復子間の距離を表現する型 typedef typename const T* pointer; // ->() の戻り値(ポインタ) typedef typename const T& reference; // *() の戻り値(参照) };
これで、通常のポインタに対しても Count クラスがそのまま適用できるようになります。この方法は、後述する STL の count 関数でも利用されています。
STL には、その他にも探索用の関数が数多く用意されています。それらの関数を以下に紹介しておきます。
| 関数名 | 関数宣言 | 用途 |
|---|---|---|
| find | template<class In, class T> In find( In first, In last, const T& val ) |
val で指定した値を first から last の手前まで探索し、最初に見つかった要素の反復子を返す |
| find_if | template<class In, class Pred> In find_if( In first, In last, Pred pred ) |
叙述関数 pred が true を返す要素を first から last の手前まで探索し、最初に見つかった要素の反復子を返す |
| find_first_of | template<class For, class For2> For find_first_of( For first, For last, For2 first2, For2 last2 ) |
first2 から last2 の手前までの要素のいずれかと一致する要素を first から last の手前まで探索し、最初に見つかった要素の反復子を返す |
| template<class For, class For2, class BinPred> For find_first_of( For first, For last, For2 first2, For2 last2, BinPred p ) |
first2 から last2 の手前までの要素のいずれかと叙述関数 p が true を返す要素を first から last の手前まで探索し、最初に見つかった要素の反復子を返す | |
| adjacent_find | template<class For> For adjacent_find( For first, For last ) |
first から last の手前までの中から隣り合う要素が等しいものを探索し、その要素の最初の反復子を返す |
| template<class For> For adjacent_find( For first, For last, BinPred p ) |
first から last の手前までの中から隣り合う要素を叙述関数 p で比較した時に、true を返すものを探索し、その要素の最初の反復子を返す | |
| count | template<class In, class T> typename iterator_traits<In>::difference_type count( In first, In last, const T& val ) |
val で指定した値を first から last の手前まで探索し、一致した要素の個数を返す |
| count_if | template<class In, class Pred> typename iterator_traits<In>::difference_type count_if( In first, In last, Pred pred ) |
叙述関数 pred が true を返す要素を first から last の手前まで探索し、一致した要素の個数を返す |
| equal | template<class In, class In2> bool equal( In first, In last, In2 first2 ) |
first2 で始まるシーケンスの各要素が first から last の手前までの範囲で全て一致するかを判定する |
| template<class In, class In2, class BinPred> bool equal( In first, In last, In2 first2, BinPred p ) |
first2 で始まるシーケンスの各要素が first から last の手前までの範囲で一致するかを p を使って判定し、全て一致したら true を返す | |
| mismatch | template<class In, class In2> pair<In, In2> mismatch( In first, In last, In2 first2 ) |
first2 で始まるシーケンスの各要素を first から last の手前までの範囲で比較して、最初に不一致となった反復子の対を返す |
| template<class In, class In2, class BinPred> pair<In, In2> mismatch( In first, In last, In2 first2, BinPred p ) |
first2 で始まるシーケンスの各要素が first から last の手前までの範囲で叙述関数 p を使って比較して、最初に不一致となった反復子の対を返す | |
| search | template<class For, class For2> For search( For first, For last, For2 first2, For2 last2 ) |
first2 から last2 の手前までの範囲の各要素が first から last の手前までの範囲の中で一致する箇所を探索し、最初に見つかった範囲の最初の要素の反復子を返す |
| template<class For, class For2, class BinPred> For search( For first, For last, For2 first2, For2 last2, BinPred p ) |
first2 から last2 の手前までの範囲の各要素が first から last の手前までの範囲の中で叙述関数 p の判定によって一致する箇所を探索し、最初に見つかった範囲の最初の要素の反復子を返す | |
| find_end | template<class For, class For2> For find_end( For first, For last, For2 first2, For2 last2 ) |
first2 から last2 の手前までの範囲の各要素が first から last の手前までの範囲の中で一致する箇所を探索し、最後に見つかった範囲の最初の要素の反復子を返す |
| template<class For, class For2, class BinPred> For find_end( For first, For last, For2 first2, For2 last2, BinPred p ) |
first2 から last2 の手前までの範囲の各要素が first から last の手前までの範囲の中で叙述関数 p の判定によって一致する箇所を探索し、最後に見つかった範囲の最初の要素の反復子を返す | |
| search_n | template<class For, class Size, class T> For search_n( For first, For last, Size n, const T& val ) |
val で指定した値を first から last の手前まで n 回探索し、n 番目に見つかった要素の反復子を返す |
| template<class For, class Size, class T, class BinPred> For search_n( For first, For last, Size n, const T& val, BinPred p ) |
val で指定した値を first から last の手前まで叙述関数 p を使って n 回探索し、n 番目に見つかった要素の反復子を返す |
adjacent_find は重複した要素を探索するときに利用することができますが、隣り合う要素に限定されるため、離れた位置にある重複要素には効果がないことに注意が必要です。find_first_of は、first2 から last2 の手前までの範囲の中のいずれかに一致する要素が見つかればその位置を返すのに対し、search はfirst2 から last2 の手前までの範囲と完全に一致する箇所の先頭を返します。例えば、文字列 s = "aabaab" と char 型の配列 c[] = { 'b', 'a' } を比較した場合、前者は c[1] と s[0] がどちらも 'a' で等しいので &s[0] を返すのに対し、後者では s[2] と s[3] が "ba" で c[] の内容と一致するので &s[2] を返します。search は文字列用として一般的に用意されている部分文字列の一致判定 ( substrなど ) を汎用的にしたものと考えることができます。
配列の要素数が N であったとき、線形検索が行う比較の回数は平均 N / 2 回と考えることができます。よって、線形検索の処理時間は N に比例することになり、データ数が 2 倍になれば処理時間も 2 倍になります。処理時間が要素数に対して比例関係にある ( O(N) のオーダーである ) ということは処理性能としては悪くはないことから、非常にシンプルな実装なのにもかかわらず非常に広い用途に利用することができることを意味します。
|
| |||||||||||||||||||||||||||||||||||||||||||
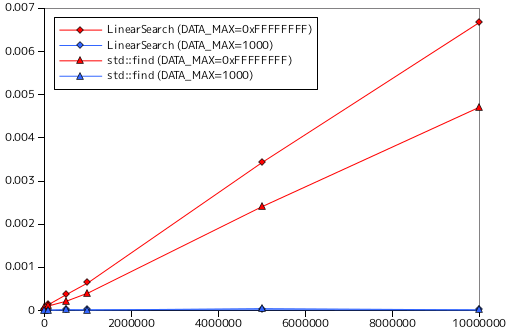
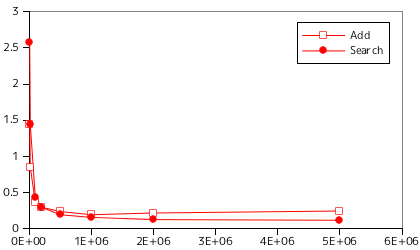
上に示した図表は、線形探索関数の処理時間を計測した結果です(*1-1)。計測に使った関数は、LinearSearch と、STL にある std::find の二種類で、対象の要素は整数値です。DATA_MAX は要素の取りうる最大値を表し、32 ビットで表現できる最大値 ( 0xFFFFFFFF ) と 1000 の二つを用いています。また、datasize は要素数を表します。テストは各条件で 10 回行い、その平均処理時間を示してあります。
DATA_MAX が大きい場合は要素が見つかる可能性が非常に低くなるため全ての要素を比較することになります。DATA_MAX = 0xFFFFFFFF のときは要素がほとんど見つからない (実際に、テスト時に要素が見つかった回数はゼロでした) ので、データサイズに応じて処理時間は線形に増加しています。逆に DATA_MAX = 1000 の場合は要素が見つかる確率が極めて高く、どれだけデータサイズを大きくしても処理時間はほとんど変化しません。当然、一致する要素全てを探索するのであれば、処理時間は要素数に応じて線形に増加するので、一致するものが含まれるかを判定するだけでなく、その個数を数えたり各要素に処理を行ったりする場合は処理時間は要素数に比例することになります。それにしても、これ以上高速化はできないだろうと考えていた LinearSearch よりも std::find は処理時間が明らかに短くなっています。どのような最適化を行なっているのでしょうか。
* 1-1) テストは、Windows7 にある VirtualBox 上の Linux でテストしています。CPU は Intel Core i7-2600 3.40GHz で 8 コアですが、ゲスト OS の Linux 上では 1 コアとして動作しています。処理時間は環境によって全く異なる結果になるので参考程度と考えてください。
線形探索はデータ量に比例して処理時間が長くなります。これに対して、配列から要素を取得する場合、添字 (index) を指定することによって処理時間はデータ量に依存しません。前者は O(N) のオーダー、後者は O(1) のオーダーということになります。大量の書類の山から目的のものを探すとき、一番上から順番に探すよりも、ある条件に従って分類しておいた方が探索は速くなります。この分類コードが目的の書類に対して一意に決められるのならば、各書類に対してそのコードで登録しておいて、コードを入力してボタンを押せばその書類が自動的にはき出されるような装置があれば、どんな書類も一発で取り出すことができます。これをコンピュータ上で実現するためのデータ構造を「ハッシュ・テーブル(Hash Table)」といいます。上記の例からわかるように、このデータ構造は、文字列など、比較的大きなデータ長を持つ要素に特に有効で、アセンブラやコンパイラなどの識別子の管理などによく利用されるようです。
ハッシュ・テーブルは、有限なサイズを持つ一次元配列で表現されます。文字列などの要素は、ハッシュ値と呼ばれる、ハッシュ・テーブルのサイズよりも小さな非負整数値に変換され、この値を添字としてハッシュ・テーブルに登録されます。ある要素からハッシュ値を求め、その値を添字として要素そのものを登録する場合、そのデータ構造は「集合(Set)」といいます。また、ハッシュ値を求めるための要素は「キー (Key) 」として利用し、そのキーに結び付けられた「値 (Value) 」を登録する場合、そのデータ構造は「連想配列(Associative Array)」といいます。集合は、キーと値が等しい連想配列と考えることもできます。要素の順序関係をハッシュ値が保持しない限り、ハッシュ・テーブルに登録されるときの順序は要素の順序関係とは一致しません。但し、同一の要素が必ず等しいハッシュ値を持つことが保証されているならば、重複した要素が発生しないように登録することができます。集合や連想配列は通常、それらの特徴を持っています。
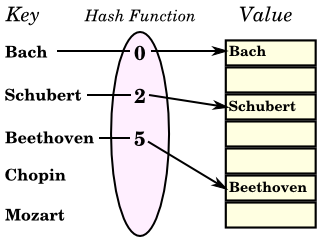
各要素からハッシュ値を求める関数は「ハッシュ関数(Hash Function)」と呼ばれます。ハッシュ関数は、入力値となる要素に対して常に同じハッシュ値を出力する必要があります。また、異なる要素に対してはできるだけ異なるハッシュ値を返すほうがよいとされています。しかし、文字列などのように要素が無限にあるような場合はハッシュ値の衝突が必ず発生するので、その場合の処理は検討しておく必要があります。全ての要素に対して必ず異なるハッシュ値を返すような関数は「完全ハッシュ関数(Perfect Hash Function)」といい、N 個の入力に対してそのハッシュ値が N 個の連続な非負整数値になる完全ハッシュ関数は「最小完全ハッシュ関数(Minimal Perfect Hash Function)」といいます。ハッシュ値が衝突する発生率が少ないためには、ハッシュ値がある範囲に集中して発生しないこと、つまり一様に分布するような関数である必要があります。完全ハッシュ関数ならば、各ハッシュ値の発生回数は 0 か 1 であり、空になる場所が少ないほど一様な分布になります。また、最小完全ハッシュ関数では全てが 1 なので、完全に一様な分布状態になります。衝突が発生するとしても、その回数が出力値全体に対して一様であれば、その発生率をある程度抑えることができるので、一様性は非常に重要な特性になります。
その他の重要な特性としては、出力値が有限な値域を持つことが挙げられます。ハッシュ・テーブルは有限長の配列なので、その範囲を超えることはできません。そのため、ハッシュ関数の値域はある範囲内に収まる必要がありますが、有限だとしても、その値が非常に大きな場合は配列のサイズが巨大になりすぎて実用的ではなくなってしまうので、たいていは出力値に対して配列のサイズで除算したときの剰余を利用します。このとき、サイズによってはハッシュ値がある範囲内に集中してしまう可能性もあるので注意が必要です。
さらにもうひとつ、関数の計算時間はできるだけ短い必要があります。線形探索は O(N) のオーダーなので、性能としては "それほど悪くない" アルゴリズムであったことに注意してください。いくら配列の探索時間が短くても、ハッシュ関数の計算が異常に長ければその利点が帳消しとなってしまいます。しかし、ハッシュ関数はその他に暗号でも活用されているので、処理時間に対してはあまり重要視されないような場面もあります。
ハッシュ・テーブルが衝突した場合の処理方法としては大きく分けて二種類存在します。ひとつは「開放番地方式 (Open Addressing) 」または「クローズド・ハッシュ (Closed Hashing) 」と呼ばれ、衝突が発生したら空いている別の場所を見つけてそこに登録する方法です。実現が比較的容易である反面、扱えるデータの総数がハッシュ・テーブルの大きさに制限されるという欠点を持つ他、別の格納場所を探す処理の仕方によってはハッシュ・テーブルの一部にデータが集中してしまい、ハッシュ値の衝突が誘発されることで探索効率が落ちてしまう可能性もあります。もうひとつの方法は「直接連鎖法 (Direct Chaining) 」または「オープン・ハッシュ (Open Hashing) 」「内部番地方式 (Closed Addressing) 」と呼ばれ、同一のハッシュ値をとるデータを線形リストの形で保持し、ハッシュ表には最初のデータのポインタや参照を登録しておきます。データ構造が多少複雑になる以外、特に大きな欠点はありません。Open Addressing に対して Closed Addressing、Closed Hashing に対して Open Hashing とややこしい呼び方が付いているのに注意してください。
「開放番地方式」で他の場所を探索する方法としては、以下のようなものがよく知られています。
初期値を a、入力する要素を k、ハッシュ関数を H(k) (ダブル・ハッシングに対しては二番目のハッシュ関数を G(k) ) としたとき、i 番目に衝突した要素の添字 Hi(k) はそれぞれ以下の式で計算されます。
| Hi(k) | = | H(k) + a・i | (Linear Probing) |
| Hi(k) | = | H(k) + i2 | (Quadratic Probing) |
| Hi(k) | = | H(k) + G(k)・i | (Double Hashing) |
式を見れば明らかなように、線形探索法は G(k) = a、つまり入力値によらない定数であるときのダブル・ハッシングと考えることができます。
ハッシュ・テーブルの実装例を以下に示します。まずは、開放番地方式を利用したサンプル・プログラムです。
// キーと値のペア struct KeyValue { K key_; T value_; KeyValue( K key = K(), T value = T() ) : key_( key ), value_( value ) {} }; // ハッシュ・テーブル(Open Addressing方式) template<class K, class T, class H = HashFunc<K>, class A = LinearProbe, class EQ = std::equal_to<K> > class HashTable_OpenAddressing { typedef std::pair<KeyValue,bool> ElementType_; // 要素の型 typedef std::vector< std::pair<KeyValue,bool> > TableType_; // 配列の型 TableType_ table_; // 要素を登録する配列 A addressFunc_; // 添字探索用関数 H hashFunc_; // ハッシュ関数 EQ eqFunc_; // キー比較(等号)関数 // st に要素を登録する bool add( size_t st, const K& key, const T& value ); public: // コンストラクタ HashTable_OpenAddressing( size_t n = 101, const A& a = A(), const H& h = H(), const EQ& eq = EQ() ) : table_( n, ElementType_( KeyValue(), false ) ), addressFunc_( a ), hashFunc_( h ), eqFunc_( eq ) {} // ハッシュ・テーブルのサイズを返す virtual size_t size() const { return( table_.size() ); } // ハッシュ・テーブルの初期化 virtual void clear() { size_t n = size(); table_.assign( n, ElementType_( KeyValue(), false ) ); } // 要素の追加 virtual bool add( const K& key, const T& value ); // 要素の探索 virtual bool find( const K& key, T& value ) const; }; /* HashTable_OpenAddressing<K,T,H,A,EQ>::add : 指定した位置に要素を追加する size_t st : 追加する位置 const K& key : キー const T& value : 値 戻り値 : true ... 追加成功またはすでに同じキー要素が見つかった : false ... すでに異なるキーの要素が登録されている */ template<class K, class T, class H, class A, class EQ > bool HashTable_OpenAddressing<K,T,H,A,EQ>::add( size_t st, const K& key, const T& value ) { if ( ! table_[st].second ) { table_[st].second = true; table_[st].first.key_ = key; table_[st].first.value_ = value; return( true ); } return( eqFunc_( table_[st].first.key_, key ) ); } /* HashTable_OpenAddressing<K,T,H,A,EQ>::add : 要素の追加 const K& key : キー const T& value : 値 戻り値 : true ... 追加成功またはすでに同じキー要素が見つかった : false ... 登録する位置が見つからなかった */ template<class K, class T, class H, class A, class EQ > bool HashTable_OpenAddressing<K,T,H,A,EQ>::add( const K& key, const T& value ) { if ( &key == 0 || &value == 0 ) return( false ); size_t h = hashFunc_( key ) % size(); // ハッシュ値 size_t st = h; do { if ( add( st, key, value ) ) return( true ); st = ( st + addressFunc_() ) % size(); } while ( st != h ); return( false ); } /* HashTable_OpenAddressing<K,T,H,A,EQ>::find : 要素の探索 const K& key : キー T& value : 取得した値(見つからなかった場合は変化しない) 戻り値 : true ... 要素が見つかった : false ... 要素が見つからなかった */ template<class K, class T, class H, class A, class EQ > bool HashTable_OpenAddressing<K,T,H,A,EQ>::find( const K& key, T& value ) const { if ( &key == 0 || &value == 0 ) return( false ); size_t h = hashFunc_( key ) % size(); // ハッシュ値 size_t st = h; do { if ( ! table_[st].second ) return( false ); if ( eqFunc_( table_[st].first.key_, key ) ) { value = table_[st].first.value_; return( true ); } st = ( st + addressFunc_() ) % size(); } while ( st != h ); return( false ); }
クラス HashTable_OpenAddressing は、キーの型を K、値の型を T とし、さらにハッシュ関数は H、探索用関数は A、等値判定関数は EQ で表したテンプレートを利用しています。関数のデフォルトは H = HashFunc<K>、A = LinearProbe、EQ = std::equal_to<K> で、std::equal_to<K> は STL の中にある叙述関数オブジェクトです ( HashFunc<K> と LinearProbe の実装例は後ほど示します )。EQ は、ハッシュ値の等しい複数の要素からキーが同値であるものを探索するときに利用します。
コンストラクタでは、ハッシュ・テーブルのサイズとハッシュ関数、探索用関数、等値判定関数を引数として渡します。各関数はそれぞれメンバ変数 hashFunc_、addressFunc_、eqFunc_ にコピーされ、要素を登録するための配列 table_ が引数のサイズで初期化されます。なお、table_ は構造体 KeyValue と bool 値から成る pair 型が要素で、KeyValue にはキーと要素が登録されます。bool 値は要素が登録されているかを表す変数で、初期化時には全て false 値としています。
メンバ関数の中で重要なものは、要素を追加するための add と、要素を探索するための find の二種類です。どちらの関数も、まずは与えられたキーを元に hashFunc_ を使ってハッシュ値を求め、table_ のサイズで割った剰余を添字の初期値とします。求めた添字の位置にすでに登録されていれば、追加・探索しようとしている要素とキーを比較して、add の場合はすでに登録済みなので true を返して終了し、find の場合は目的の要素が見つかったので、値を取得してやはり処理を終了します。もしキーが異なれば、addressFunc_ を使って次の添字を求め、同様の処理を繰り返します。添字を更新した結果が最初の添字と一致してしまえば、これ以上処理を続けても要素を追加・探索することができないので false を返して終了します。また、登録されていない位置が見つかったら、add の場合は新たに追加を行なって true を返し、find の場合は要素が見つからなかったため false を返します。
次は、直接連鎖法を利用したサンプル・プログラムです。
// ハッシュ・テーブル(Closed Addressing方式) template<class K, class T, class H = HashFunc<K>, class EQ = std::equal_to<K> > class HashTable_ClosedAddressing { vector< vector<KeyValue> > data_; // 要素を登録する配列 H hashFunc_; // ハッシュ関数 EQ eqFunc_; // キー比較(等号)関数 public: // コンストラクタ HashTable_ClosedAddressing( size_t n = 101, const H& h = H(), const EQ& eq = EQ() ) : data_( n ), hashFunc_( h ), eqFunc_( eq ) {} // ハッシュ・テーブルのサイズを返す // * 実データのサイズではないことに注意 virtual size_t size() const { return( data_.size() ); } // ハッシュ・テーブルの初期化 virtual void clear() { size_t n = size(); data_.assign( n, vector<KeyValue>() ); } // 要素の追加 virtual bool add( const K& key, const T& value ); // 要素の探索 virtual bool find( const K& key, T& value ) const; }; /* HashTable_ClosedAddressing<K,T,H,A,EQ>::add : 要素の追加 const K& key : キー const T& value : 値 戻り値 : true ... 追加成功またはすでに同じキー要素が見つかった : false ... 登録する位置が見つからなかった */ template<class K, class T, class H, class EQ > bool HashTable_ClosedAddressing<K,T,H,EQ>::add( const K& key, const T& value ) { if ( &key == 0 || &value == 0 ) return( false ); vector<KeyValue>& vec = data_[hashFunc_( key ) % size()]; // 要素を追加する対象vector for ( size_t i = 0 ; i < vec.size() ; ++i ) if ( eqFunc_( vec[i].key_, key ) ) return( true ); vec.push_back( KeyValue( key, value ) ); return( true ); } /* HashTable_ClosedAddressing<K,T,H,A,EQ>::find : 要素の探索 const K& key : キー T& value : 取得した値(見つからなかった場合は変化しない) 戻り値 : true ... 要素が見つかった : false ... 要素が見つからなかった */ template<class K, class T, class H, class EQ > bool HashTable_ClosedAddressing<K,T,H,EQ>::find( const K& key, T& value ) const { if ( &key == 0 || &value == 0 ) return( false ); size_t h = hashFunc_( key ) % size(); // ハッシュ値 const vector<KeyValue>& vec = data_[h]; for ( typename vector<KeyValue>::const_iterator it = vec.begin() ; it != vec.end() ; ++it ) { if ( eqFunc_( it->key_, key ) ) { value = it->value_; return( true ); } } return( false ); }
HashTable_OpenAddressing と比べると、クラス HashTable_ClosedAddressing は多少シンプルな構成になっています。テンプレート引数は探索用関数の A が不要になる以外は HashTable_OpenAddressing と同じです。データを格納する配列 data_ の要素は構造体 KeyValue の配列であり、ハッシュ値が衝突した場合は複数の要素が一つの配列に登録されるようになっています。従って HashTable_OpenAddressing とは異なり、登録できる要素は理論上制限がありません。
メンバ関数として、HashTable_OpenAddressing と同様に add と find が用意されています。異なる点はハッシュ値が衝突した場合の処理で、同一のキーが存在しないかをチェックした上で、もし存在すれば、add の場合 true を返して終了し、find の場合は値を取得してやはり処理を終了します。存在しなければ、add の場合は ( data_ の要素としての ) 配列の末尾に新たに追加を行なって true を返し、find の場合は要素が見つからなかったため false を返します。
最後に、ハッシュ関数と探索用関数のサンプル・プログラムを示します。
// ハッシュ関数(汎用) template<class K> struct HashFunc : std::unary_function<K,size_t> { /* operator() : ハッシュ関数 key をバイト列(char型のデータ列)とみなして、各要素に対し XOR をとる操作を繰り返す。 XOR を取る前に、前のハッシュ値は 3 だけ左にビットする const K& key : 入力要素 戻り値 : ハッシュ値 */ size_t operator()( const K& key ) const { if ( &key == 0 ) return( 0 ); size_t h = 0; // 求めるハッシュ値 size_t len = sizeof( K ); // データ長 // key を示すポインタ(key はバイト列とみなす) const char* cp = reinterpret_cast<const char*>( &key ); while ( len-- ) h = ( h << 3 ) ^ ( *cp++ ); return( h ); } }; // ハッシュ関数(文字列用) template<> struct HashFunc<char*> : std::unary_function<char*,size_t> { /* operator() : 文字列(char型配列)専用ハッシュ関数 const char* key : 入力要素へのポインタ 戻り値 : ハッシュ値 */ size_t operator()( const char* key ) const { if ( key == 0 ) return( 0 ); size_t h = 0; // 求めるハッシュ値 while ( *key ) h = ( h << 3 ) ^ ( *key++ ); return( h ); } }; // ハッシュ関数(string用) template<> struct HashFunc< std::string > : std::unary_function<std::string,size_t> { /* operator() : string型専用ハッシュ関数 const std::string& key : 入力要素 戻り値 : ハッシュ値 */ size_t operator()( const std::string& key ) const { if ( &key == 0 ) return( 0 ); size_t h = 0; // 求めるハッシュ値 // 文字列の先頭(反復子) std::string::const_iterator ci = key.begin(); while ( ci != key.end() ) h = ( h << 3 ) ^ ( *ci++ ); return( h ); } }; // 線形探索関数オブジェクト struct LinearProbe { size_t inc_; LinearProbe( size_t st = 1 ) : inc_( ( st > 0 ) ? st : 1 ) {} size_t operator()() const { return( inc_ ); } };
ハッシュ関数は、キーをバイト列 ( char 型のデータ列 ) とみなし、各バイト値を使って排他的論理和 ( XOR ) を求める処理を繰り返すことでハッシュ値を求めています。ハッシュ値の初期値はゼロとし、処理前に左へ 3 だけビットシフトした上で、バイト値との XOR を計算します。単純な処理でそれなりの結果が得られる例として一般的に使われる手法です。キーとしてどのような型でも使うことができるように、テンプレート引数として任意の型が利用できるようにしてありますが、文字列に対しては特別バージョンを用意しています。
探索関数オブジェクトとして、線形探索法を使った LinearProbe を用意しています。処理は非常にシンプルで、増分を保持しておいてそれを返すだけです。
サンプル・プログラムを使って、処理時間を計測した結果を以下に示します。
|
| ||||||||||||||||||||||||||||||||||||||||
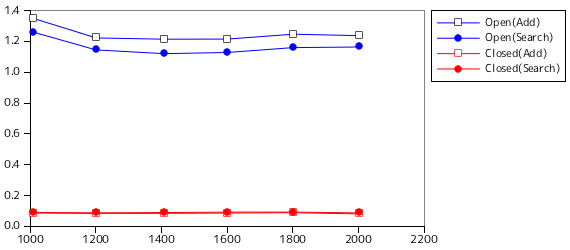
上に示した図表は、三桁の数字からなる文字列 ( 000 〜 999 ) をハッシュ・テーブルに登録し、その中から任意の値を一つだけ取得した時の時間を示しています。Table Size はハッシュ・テーブルの大きさを表し、1009 から 2003 まで 200 程度の間隔で徐々に大きくしながら六通りのテストをしています。大きさが中途半端な数になっているのは、衝突を避けるため素数を利用してるからです。Method はハッシュ値が衝突した時の処理方法で、Open が「開放番地方式」、Closed が「内部番地方式」を表します。「開放番地方式」ではハッシュ値が衝突した時の位置の探索に「線形探索法」を使い、増分はデフォルトの 1 のままとしています。登録と探索はどちらも 50 万回行い、その合計時間を秒単位で示しています。また、テストは各条件に対し 10 回繰り返し、その平均を利用しました。
三桁の数字として表される文字列の種類は 1000 種類あるので、どの Table Size についても全ての要素を登録することが可能です。「開放番地方式」の Table Size = 1009 の条件が、全条件の中では最も処理時間が長いという結果になっています。それを除けば、「開放番地方式」「内部番地方式」のいずれも、登録・探索はハッシュ・テーブルのサイズに関係なくほぼ一定の時間で処理できることがこの結果からわかります。
「開放番地方式」と「内部番地方式」では、「内部番地方式」の方が圧倒的に速く処理できます。「開放番地方式」においてハッシュ値の衝突があった場合、例えばハッシュ値が 100 の位置が登録済みで、代わりに 101 番目に登録したとすると、ハッシュ値が 101 の要素をその後に登録しようとしても 101 番目はすでに使われているので更に次の位置に登録するというように、他の位置にデータを登録するという流れが連鎖的に発生して処理時間が長くなる傾向にあると考えられます。「開放番地方式」の Table Size = 1009 の条件は全条件の中で最も処理時間が長いという結果になっていますが、これは、ほぼすべての位置が要素の登録に使われ、空きスペースがほとんどない状態で無理にデータを登録していることが主な理由でしょう。
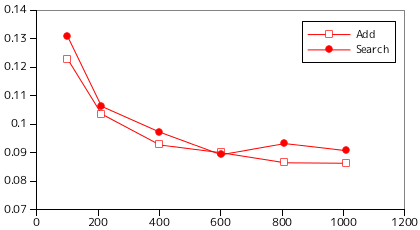
「開放番地方式」はハッシュ・テーブルのサイズ以上のデータを登録することはできませんが、「内部番地方式」であればそれは可能です。このとき、ハッシュ値の重複はサイズが小さいほど多く発生するようになり、処理時間へも影響することが予想されます。「内部番地方式」について、ハッシュ・テーブルのサイズが小さな場合の処理時間を計測した結果を以下に示します。ハッシュ・テーブルのサイズ以外の条件は先ほどと全て同じです。
|
|
予想通り、ハッシュ・テーブルのサイズが極端に小さい場合は処理性能も落ちる傾向が見られます。今回の例では、登録可能なデータ数の 80% 程度で一定な時間になるという結果になりました。
三桁の数値は 1000 通りの表し方があるのに対して登録回数が 50 万回であるということは、重複したデータが多数存在した場合の処理時間を表していることになります。これに対し、10 桁の数値を登録・探索したときの処理時間は次のような結果になりました。
|
|
このテストでは、探索結果が得られる回数は極端に少なくなって、50 万回中 100 回を超えることはありませんでした。この場合、テーブルのサイズが小さいと極端に性能が落ちてしまいます。任意の長さの文字列など、データの取りうる値は通常は有限でないと考えられるので、これが本来の性能であると考える方がいいでしょう。ちなみに「開放番地方式」を使って同じ条件で処理すると、処理時間が極端に長くなってしまったので断念しました。
最後に、ハッシュ・テーブルのサイズが 2 のべき乗 ( 131072 = 217 ) と素数 ( 131009 ) の場合での、「内部番地方式」を使った登録・探索時間の差を計測した結果を以下に示します。データの登録・探索回数は 50 万回、データの桁数は 10 桁で、今までと同様、10 回のテストの平均を示しています。
| Table Size | 登録 | 探索 |
|---|---|---|
| 131072 | 0.379 | 0.465 |
| 131009 | 0.338 | 0.375 |
| 差分 | 0.041 | 0.090 |
ほぼ等しいサイズであるにも関わらず、特に探索処理において大きな差が見られます。サイズについてはできるだけ素数を使うほうがよいということがこの結果からもわかります。
ハッシュ・テーブルは、複数のオブジェクトを保持するための「コンテナ(Container)」や「コレクション(Collection)」に位置付けされます。今回作成したサンプル・プログラムは要素の追加と探索しかできないので、実用できるレベルまでは実装されていません。STL では標準で unordered_(multi)map と unordered_(multi)set が用意されています。但し、これらが標準化されたのは「ISO/IEC 14882:2011 (C++11)」からになります。C++11 は 2011 年 8 月に承認された新しい ISO 標準なので、古いライブラリにはまだ実装されていない場合もあります。
template< class Key, // unordered_map::key_type class T, // unordered_map::mapped_type class Hash = hash<Key>, // unordered_map::hasher class Pred = equal_to<Key>, // unordered_map::key_equal class Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type > class unordered_map; template< class Key, // unordered_multimap::key_type class T, // unordered_multimap::mapped_type class Hash = hash<Key>, // unordered_multimap::hasher class Pred = equal_to<Key>, // unordered_multimap::key_equal class Alloc = allocator< pair<const Key,T> > // unordered_multimap::allocator_type > class unordered_multimap; template< class Key, // unordered_set::key_type/value_type class Hash = hash<Key>, // unordered_set::hasher class Pred = equal_to<Key>, // unordered_set::key_equal class Alloc = allocator<Key> // unordered_set::allocator_type > class unordered_set; template< class Key, // unordered_multiset::key_type/value_type class Hash = hash<Key>, // unordered_multiset::hasher class Pred = equal_to<Key>, // unordered_multiset::key_equal class Alloc = allocator< pair<const Key,T> > // unordered_multiset::allocator_type > class unordered_multiset;
このクラスには、map などと同じように、登録と探索を一つにまとめた演算子の多重定義関数 operator[] や、要素削除用の関数 erase などを持っています。また、サンプル・プログラムではハッシュ・テーブルのサイズが変更できないのに対して、データ量に応じてサイズを自動的に最適な状態としてくれます。参考文献 2 には、直接連鎖法を使った、より実用的なサンプルがあります。その中では、要素そのものを vector に登録し、そのポインタを、ハッシュ・テーブルとなる他の vector に保持するという手法を取っています。vector は要素が増えると自動的に再配置を行うため、各要素のポインタが常に同じ値となる保証はありません。そこで、メンバ関数の reserve を使ってサイズをあらかじめ予約することで再配置が発生しないような処置を行なっています。ハッシュ・テーブルのサイズが増えれば再配置の可能性がありますが、ハッシュ・テーブルのサイズが変化すれば添字の再計算も必要となるので要素の再登録は必須になります。STL のクラスも同様ですが、サイズの拡張は全要素に対して再配置を行うことになるので効率を落とす原因となります。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |