図 2-1. '(a|b)*aa' の有限オートマトン
前回までは、固定文字列の照合アルゴリズムを紹介しましたが、この章では特定の「パターン」に合致する文字列を検索する処理、いわゆる「正規表現 (Regular Expression)」を取り上げたいと思います。正規表現は、grep, sed, awk, perl など、様々なツール、言語上でサポートされているので、利用したことのある方も多いのではないかと思います。
正規表現は、一つ以上の空白でない「枝 (Branch)」からなり、各「枝」は '|' で区切られます。正規表現は、「枝」の中のいずれかに一致した場合に「文字列が一致した」ことになるので、'|' は "論理和" の役割を持つといえます。
「枝」は一つ以上の「文節 (Piece)」が結合したものであり、それぞれの「文節」が並んだ順で一致した場合、その「枝」は「一致した」ことになります。
「文節」は一つ以上の「アトム (Atom)」からなります。アトムの種類には以下のようなものがあります。
| '.' | 空文字を除く任意の一文字と一致する |
| '^' | 文字列先頭の空文字と一致する |
| '$' | 文字列末尾の空文字と一致する |
| '(' と ')' に囲まれた正規表現 | その正規表現が一致した文字列に一致する |
| '()' | null文字と一致する |
| '[' と ']' に囲まれた文字のリスト | ブラケット表現(Bracket Expression)(後述) |
| '\' に任意の一文字を後置したもの | '\'を除いた文字と一致する |
| '^.[$()|*+?{\' 以外の一文字 | 文字そのものと一致する |
'^.[$()|*+?{\' は「メタ文字 (Metacharacter)」と呼ばれ、それぞれ特殊な意味を持つため、文字自体と一致させたい場合はその前に '\' をつけて、メタ文字としての機能を打ち消します。なお、'\' そのものと一致させたい場合は '\\' と記述します。
「ブラケット表現 (Bracket Expression)」では、'[' と ']' の間に存在する文字リストのいずれかに対象の文字が含まれていれば一致したと見なされます。逆に、文字リストが '^' で始まる場合は、文字リストに含まれていない場合に一致することになります。
文字リスト中の二文字が '-' で区切られている場合は文字範囲を表します。例えば '[A-Z]' は、'A' から 'Z' までのアルファベットのいずれか一文字と一致します。
文字リストに ']' を加えたい場合は、リストの先頭 (または先頭にある '^' の直後) に置きます。また、'-' を加えたい場合は、文字リストの先頭か末尾に置く必要があります。なお、全てのメタ文字は、ブラケット表現の内部では通常の文字として扱われます。
アトムの後には以下の文字列が続く場合があり、それぞれ以下のような意味を持ちます。
繰り返し指定 (Bound) は、繰り返しの個数を定義したい場合に用います。"{m,n}" ( m と n は正の十進数で、必ず m < n ) の形式で記述した場合、アトムを m 個以上 n 個以下だけ並べた文字列と一致します。',' と n は省略することが可能で、"{m,}" はアトムを m 個以上並べた文字列と、"{m}" はアトムをちょうど m 個並べた文字列とそれぞれ一致します。
なお、'{' はメタ文字ですが、その直後が数字以外の文字であれば通常の文字として扱われます。
正規表現が、与えられた文字列の中で複数の部分文字列に一致した場合は、最も先頭に近い位置にある部分文字列に一致したことになります。また、正規表現が一致したと判断できる範囲が複数ある場合は、最長の部分文字列に一致したことになります。
ある枝に対して文節の一部からなる文字列は「部分正規表現 (Subexpression)」と呼ばれます。部分正規表現も最長の部分文字列に一致することとしますが、正規表現全体の一致が最長になるという条件が優先されます。また、部分正規表現は先に現れたものが優先されますが、高位の部分正規表現は、それを構成する低位の部分正規表現より優先されることに注意する必要があります。例えば、正規表現 'x*x' と文字列 'xxxxx' を照合させる場合、先に現れた部分正規表現の 'x*' が文字列全体と一致してしまうと、残りの正規表現 'x' と一致する文字列がないので一致しないと見なされてしまいます。このときは、'x*' は 'xxxx' と一致すると考えなければなりません。
いくつか例を挙げてみます。
文字列を正規表現と照合する処理は、正規表現を認識する「有限オートマトン ( Finite State Automaton : 有限状態機械 )」を利用すると効率がいいようです。
有限オートマトンは、単純な仕組みだけで構成された仮想的な機械のことで、その機械は有限個の "状態" を取り、最初は "初期状態" にあります。この初期状態から入力を順に読み込んでは、その入力に応じて、ある状態から別の状態へと遷移していき、入力が尽きるか "最終状態" に達するまでそれを繰り返します。パターン照合の場合は、入力として文字をひとつずつ読み込んで、最終状態に達したらパターンに一致したと判断します。
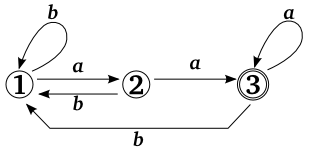
有限オートマトンは、一般的に流れ図の形で表されます。例えば正規表現 '(a|b)*aa' を認識する有限オートマトンは次のようになります。
図中、ラベル付きの矢印は「入力がラベルの文字と一致したら次の状態へ遷移する」ことを示します。また、各状態は番号で示され、受理状態は二重円(◎)で囲ってあります。
例に示した正規表現は a と b で構成され、末尾が "aa" であるような文字列
aa, aaa, baa, aaaa, abaa, baaa, bbaa, ...
などと一致します。上図の有限オートマトンに文字列 "aa" を与えてみると、文字列の第一文字目 'a' によって初期状態の 1 から状態 2 へ、さらに第二文字目の 'a' によって受理状態の 3 へ遷移するため照合は成功します。また、"bbaa" という文字列の場合は
| b | b | a | a | |||||
| 1 | → | 1 | → | 1 | → | 2 | → | 3 |
というルートで遷移します。
文字列 "aaa" の場合、
| a | a | a | ||||
| 1 | → | 2 | → | 3 | → | 3 |
というルートを通って受理されることになるのですが、途中 "aa" まで読み込んだ状態ですでに受理状態になっています。文字列を読み込んでから最初に受理状態に達した時点で処理を終了させるかどうかはその用途によって変わります。今回のように単なる文字列検索として使用する場合は、一度受理状態に達したら照合成功とみなして処理を中断してもいいのですが、文字列全体がパターンと一致するかどうかを調べる場合は、一度受理状態に達した後も入力が尽きるまで処理を続けなければなりません。前節で書いた通り、正規表現では可能な限り最長の文字列と一致させることになるので、一般的には受理状態になっても入力が尽きるか不一致が検出されるまで処理を継続することになります。
さて、上図の有限オートマトンは、ある入力文字による遷移先はただ一つです。このような有限オートマトンを「決定性有限オートマトン ( Deterministic Finite State Automaton ; DFA )」といいます。これに対して、入力文字に対して複数の遷移先を許す有限オートマトンを「非決定性有限オートマトン ( Non-deterministic Finite State Automaton ; NFA )」といいます。先ほどの流れ図を NFA で表すと以下のようになります。
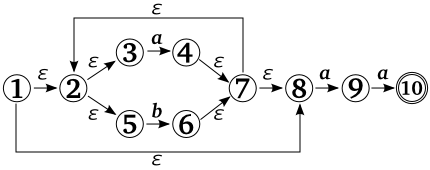
NFA では、二つの入力文字の間に空文字 (ε) があるものとして、空文字も読み込んで遷移していきます。このような遷移をする場合、次に取りうる状態は一意に決まらなくなるため、このオートマトンは非決定性を持つことになります。NFA は同時に複数の状態に分裂していき、それぞれの状態について並列に処理をして、いずれかが受理状態になったら照合成功と判断します。また、受理状態には到達できないことが判明した選択肢はふるい落とされ、取りうる状態がなくなった時点で照合失敗と見なされます。
DFA は NFA と比べて効率のよいパターン照合ルーチンが作成できますが、オートマトンの作成にやや複雑な処理が必要である、メモリを比較的大量に使う(最悪の場合、状態数が正規表現の文字・演算子数に指数的に増大する)、後方参照などの拡張正規表現や日本語などの多バイト文字と相性が悪いなど、いくつかの欠点も持ち合わせています。
NFA では複数の状態に遷移するため、それぞれの遷移先に対して照合できるかをチェックしていく必要があります。このための方法としてまず考えられるのが、枝分かれしたら一方の情報はスタックに積んで、片側を先に処理していくやり方です。処理した結果、受理状態に到達しないことが判明したら、スタックから情報を復元してそこから別ルートをたどり、もしスタックが空になれば照合は失敗したことになります。注意すべき点としては、空文字での遷移によるループ ( 上図での "7" から "2" への遷移 ) があった場合、そちらを優先して処理する必要があります。そうしないと、スタックに登録される状態を全て処理しない限り最長一致を検出することができなくなります ( a だけからなるテキストにパターン "a*a" との照合を行う場合、最長一致ならテキスト全体が検出されなければならないのですが、もしループが優先されなければ、検出されるのは "a" もしくは "aa" になってしまいます)。
もう一つのやり方として、複数の状態を並列で処理する方法も考えられます。二つのスタックを用意して、片側から状態を一つ取り出しては遷移できるかを調べ、可能だった場合は遷移後の状態をもう一方のスタックに積み込みます。このとき空文字による遷移があれば、その遷移先を読み込み側のスタックに再度積んで、テキストから次の文字を読み込む前に再度遷移させます。スタックが空になったらスタックの役割を入れ替えて同様の操作を繰り返し、入れ替え後に読み込むべき状態がスタックになければ照合失敗です。このとき、スタックに含まれる状態は全て、照合する対象文字列の同じ位置にある文字に対応することになります。
これら二種類の処理方法にはそれぞれ有利な部分と不利な部分がありますが、前者の方法では入力した文字の数だけ情報がスタックに積まれる可能性があり、その数が予想できないことから、どんなに大きくスタックを確保しても充分である保証はありません。入力文字数が予想できないほど大きくなるということは、最悪の場合の実行速度が非常に遅くなることも意味します。
例として、テキスト "aaaaa" とパターン "a*b" との照合を考えてみます。"a*b" の NFA は下図のようになります。
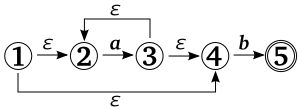
最長一致が前提の場合は状態 2 → 3 → 2 のループを優先して処理することになるので、
| ε | a | ε | a | ε | a | ε | a | ε | a | ε | ||||||||||||
| 1 | → | 2 | → | 3 | → | 2 | → | 3 | → | 2 | → | 3 | → | 2 | → | 3 | → | 2 | → | 3 | → | 2 |
と 'a' を末尾まで5回読み込んだところで一度照合失敗となります。この時点で空文字を通った回数は 6 回で、それぞれについて別のルートがスタックに積まれ、スタックから読み込んでは同じように操作を行うと、それぞれの操作でもまた空文字での分岐でスタックに情報を積み込むことを末尾まで繰り返すという最悪の状態になります。パターンが "a*a*b" になるとさらに多くのスタックが必要になり、実行速度も低下します。
後者の並列処理の場合は、状態の重複が起らないよう注意すれば一つのスタックが NFA の状態数と等しくなるので、スタックがあふれる心配をする必要はありません。また、スタックにすべての状態が詰まれていた場合、一文字の比較回数は状態数に等しくなるため、後戻りをしない並列処理では文字の比較回数が最大でも (テキストの文字数) X (状態数) を越えることはありません。よって、処理時間が爆発的に大きくなる心配はないわけです。
逆に、前者のやり方では運がよければ無駄な文字比較をすることなく最短時間で照合結果が得られる可能性もあります。後者ではすべての可能性を並行して行うため、無駄な文字比較がある程度は発生します。
正規表現から NFA への変換は、正規表現を構文上のパーツに分解し、個々の正規表現を認識する小さな NFA を作ってそれらを組み合わせることにより実現することができます。ここでは、基本パーツとして「論理和 "r|s"」「結合 "rs"」「繰り返し "r*"」の 3 パターンのみを使った正規表現について考えてみることにします。
各基本パーツは、以下のように表わすことができます。
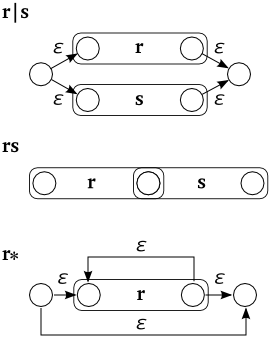
論理和は、二つの正規表現 ( r, s ) を空文字遷移によって並列につないだ NFA を形成することで実現できます。また結合は、r の受理状態と s の開始状態を重ねて直列に並べて表わします。
繰り返しパターンは、0 回の繰り返しとして開始状態から受理状態への空文字遷移によるバイパスを形成し、一回の繰り返しでは r を通って受理状態に達します。二回以上の繰り返しの場合、r の受理状態から開始状態へ空文字遷移によるループを形成して、必要な回数だけループしてから受理状態へ移動できるようにします。
次に、正規表現を構文単位に分解して適切に組み合わせるアルゴリズムの作成について考えます。正規表現の定義から、もっとも優先順位の高い演算子は論理和 "r|s" になるので、まずはこの論理和で「枝 (branch)」に分解するサブルーチンを用意します。次にそれぞれの「枝」を「アトム (atom)」に分解するサブルーチンを用意すれば、分解された「アトム」は任意の一文字かその繰り返し "r*"、あるいはカッコで括られた正規表現となります。
「アトム」をNFAに変換するルーチンは、単独の文字かその繰り返し、カッコで括られた正規表現について処理するだけなので、比較的簡単に実現できそうです(カッコで括られた部分は一つの正規表現であるため、構文解析ルーチンを再帰的に呼び出すことになります)。そしてこのルーチンを下請けに利用すれば、「枝」を NFA に変換するルーチンも各アトムを結合するだけの処理になるので容易に実現できます。この「枝」を論理和で処理するルーチンを用意すれば、優先順位をきちんと考慮した構文解析ルーチンができあがります。
NFA は、遷移するための条件(文字)と遷移先の組で表わすことができます。条件となる文字が一文字だけであるならその文字コードを入れておくだけで充分なのですが、ブラケット表現などにも対応できるようにするため、8 ビットで表現できる文字数分 ( 256 ビット ) のテーブルを用意して、対象の文字コードに対応するビットを ON にして表現します。また、遷移先は最大で二ヶ所になるので二つ分確保し、不必要な遷移先は無効値を入れておくことにします。
以上を考慮して、NFA の 遷移状態を表す NFAState クラスのサンプル・プログラムを以下に示します。
/* NFAState : 非決定性有限オートマトンの各要素 */ class NFAState { // 文字数の定義 static const size_t CHARA_SIZE = 256; // 文字パターン charaMask_ の要素数 static const size_t MASK_SIZE = CHARA_SIZE / CHAR_BIT + ( ( CHARA_SIZE % CHAR_BIT != 0 ) ? 1 : 0 ); // 遷移先への相対位置に対する型 typedef vector<NFAState>::difference_type difference_type; vector<unsigned char> charaMask_; // 遷移できる文字パターン public: /* 公開メンバ変数群 */ bool isEmpty; // 空文字か ? difference_type next0; // 一つ目の遷移先 difference_type next1; // 二つ目の遷移先 /* 公開メンバ関数群 */ // コンストラクタ NFAState() : charaMask_( MASK_SIZE, 0 ), isEmpty( true ), next0( 0 ), next1( 0 ) {} // clearMask : 文字パターンのビットクリア void clearMask() { for ( vector<unsigned char>::size_type i = 0 ; i < MASK_SIZE ; ++i ) charaMask_[i] = 0; } // fillMask : 文字パターンのビットフィル void fillMask() { for ( vector<unsigned char>::size_type i = 0 ; i < MASK_SIZE ; ++i ) charaMask_[i] = ~0; } // reverseMask : 文字パターンのビット反転 void reverseMask() { for ( vector<unsigned char>::size_type i = 0 ; i < MASK_SIZE ; ++i ) charaMask_[i] = ~( charaMask_[i] ); } // setMask : 文字コードに対応する文字パターンのビットを立てる void setMask( unsigned char c ) { size_t index = c / CHAR_BIT; unsigned int maskNum = c % CHAR_BIT; charaMask_[index] |= 1 << maskNum; } // checkChara : 文字照合ルーチン bool checkChara( unsigned char c ) const { size_t index = c / CHAR_BIT; unsigned int maskNum = c % CHAR_BIT; return( ( ( charaMask_[index] ) & ( 1 << maskNum ) ) != 0 ); } };
256 ビットのテーブル charaMask_ は、unsigned char 型の可変長配列 (std::vector) として確保しています。unsigned char 型は通常 8 ビットなので、その場合は 256 / 8 = 32 個の要素が確保されます。next0 と next1 は次の NFA への遷移先を表し、どちらも公開メンバ変数としています。遷移先は vector<NFAState>::difference_type 型であり、現在位置からの相対位置で遷移先を表すことを意味しています。また、今回の処理の中では自分自身に遷移することはないので、無効値はゼロで表現するものとします。
公開メンバ関数のほとんどは文字パターンの処理に使われます。clearMask は全パターンのビットのクリア、reverseMask はビットの反転に利用します。また、setMask は指定した文字コードに対するビットを 1 にし、checkChara は指定した文字コードに対するビットが 1 であるかどうかをチェックします。isEmpty はやはり公開メンバ変数であり、空文字かどうかをチェックするために利用されます。
NFAState クラスを連結することで NFA を表現することができます。今回は、先ほど示した三つの基本パーツ「論理和 "r|s"」「結合 "rs"」「繰り返し "r*"」を含む以下の機能が利用できる正規表現を作成してみます。
| 表現 | 内容 |
|---|---|
| . | 空文字と改行(\n)を除く任意の一文字と一致する |
| ^ | 文字列先頭の空文字と一致する |
| $ | 文字列末尾の空文字と一致する |
| [...] | ブラケット表現 |
| * | 前のアトムのゼロ回以上の繰り返しと一致する |
| + | 前のアトムの一回以上の繰り返しと一致する |
| ? | 前のアトムのゼロ回または一回の繰り返しと一致する |
| | | 論理和 |
ブラケット表現では、'-' を使った文字範囲指定や '^' を使った反転も利用できるようにします。また、繰り返し指定では、ゼロ回以上の繰り返しと一致する '*' の他に 一回以上の繰り返しと一致する '+' と ゼロ回または一回の繰り返しと一致する '?' が利用できるようにします。"{m,n}" で表現する Bound 指定は、繰り返し回数を表すカウンタを用意するなど実装がかなり複雑になるので、ここでは対応していません。。
エスケープ・シーケンスとしては、'\' を使った以下の表現が利用できるようにします。
| エスケープ シーケンス | ASCIIコード | 意味 |
|---|---|---|
| \a | 0x07 | アラーム(BEL) |
| \b | 0x08 | バック・スペース(BS) |
| \t | 0x09 | 水平タブ(HT) |
| \n | 0x0A | 改行(LF) |
| \v | 0x0B | 垂直タブ(VT) |
| \f | 0x0C | 書式送り(FF) |
| \r | 0x0D | 復帰(CR) |
さらに、'\' を使って以下のブラケット表現が利用できるようにします。
| 短縮形 | ブラケット表現 | 意味 |
|---|---|---|
| \d | [0-9] | 数値 |
| \D | [^0-9] | 数値以外 |
| \w | [a-zA-Z0-9] | 英数字 |
| \W | [^a-zA-Z0-9] | 英数字以外 |
| \s | [ \t\f\r\n] | 空白文字 |
| \S | [^ \t\f\r\n] | 空白文字以外 |
| \h | [ \t] | 水平空白文字 |
| \H | [^ \t] | 水平空白文字以外 |
| \v | [\n\v\f\r] | 垂直空白文字 |
| \V | [^\n\v\f\r] | 垂直空白文字以外 |
'\' の後に以上の文字コードがあった場合は、制御コードやブラケット表現と見なされることになります ( ブラケット表現の短縮形はおそらく Perl が最初ではないかと思いますが、正式な正規表現の定義ではありません )。それ以外は、メタ文字を含めて文字そのものを表すので、"\p" なら 'p' そのもの、"\*" もゼロ回以上の繰り返しではなく '*' そのものを表します。
まずは、正規表現を構文解析し、任意の文字列とパターン照合するためのクラス Regex を定義します。
/* ATOM : メタ文字の定義 */ namespace ATOM { static const char REPEAT0 = '*'; // 0 回以上の繰り返し static const char REPEAT1 = '+'; // 1 回以上の繰り返し static const char REPEAT01 = '\?'; // 0 または 1 回 static const char HEADOFPAT = '^'; // 行頭 static const char ENDOFPAT = '$'; // 行末 static const char CHARA_ANY = '.'; // 任意の一文字 static const char QUOTE = '\\'; // クォート(エスケープ・シーケンス) static const char GROUP_START = '('; // グループの開始 static const char GROUP_END = ')'; // グループの終了 static const char OR = '|'; // 論理和 static const char CLASS_START = '['; // ブラケット表現の開始 static const char CLASS_END = ']'; // ブラケット表現の終了 static const char CLASS_REVERSE = '^'; // ブラケット表現の反転 static const char CLASS_SEQUENCE = '-'; // ブラケット表現の文字範囲 }; /* Regex : 正規表現のコンパイルと検索 */ class Regex { // 型の定義 typedef string::const_iterator StrCit; typedef vector<NFAState>::iterator NFAIt; typedef vector<NFAState>::const_iterator NFACit; typedef vector<NFAState>::size_type size_type; typedef vector<NFAState>::difference_type difference_type; vector<NFAState> vecNFA_; // 非決定性オートマトン bool startFlg_; // 開始文字 (^) が先頭に指定されていたか bool endFlg_; // 終了文字 ($) が末尾に指定されていたか bool NFA_Quote( unsigned char c ); // エスケープ系列用 NFAState 作成 void NFA_Chara( unsigned char c ); // 文字コード用 NFAState 作成 bool NFA_Class( StrCit s, StrCit e ); // ブラケット表現用 NFAState 作成 bool NFA_LEOneRepeater( size_type headIdx ); // 0, 1 回の繰り返し用 NFAState 作成 bool NFA_GEOneRepeater( size_type headIdx ); // 1 回以上の繰り返し用 NFAState 作成 bool NFA_GEZeroRepeater( size_type headIdx ); // 0 回以上の繰り返し用 NFAState 作成 void NFA_Or( size_type idx0, size_type idx1 ); // 論理和用 NFAState 作成 bool compileBranch( StrCit s, StrCit e ); // 枝の構文解析 bool compile( StrCit s, StrCit e ); // 構文解析ルーチン string::const_iterator regexSub( StrCit s, StrCit e ) const; // 文字列検索(開始位置固定) bool regex( StrCit& s, StrCit& e ) const; // 文字列検索(開始位置を移動しながら regSub を呼び出す) static void addBuffer( vector<NFACit>& vecBuffer, NFACit nfa ); // バッファへの追加(regexSub用) public: // コンストラクタ Regex() : startFlg_( false ), endFlg_( false ) {} bool compile( const string& pattern ); // コンパイル処理 bool regex( const string& str, StrCit& s, StrCit& e ) const; // 文字列検索 };
Regex クラスのメンバ変数 vecNFA_ が、NFA を構築するために使われる、NFAState を要素とした可変長配列です。初期状態は必ず配列の先頭にあるものとし、最終状態は NFAState の文字パターンが全てクリアされ、next0 と next1 はどちらもゼロであるものとします ( また、必ず末尾の要素になります )。
他のメンバ変数 ( startFlg_, endFlg_ ) については後ほど説明したいと思います。今度は、正規表現の構文解析 ( NFA の作成 ) を行うための処理について順番に説明します。
/* Regex::compile : 構文解析ルーチン StrCit s : 構文の先頭 StrCit e : 構文の末尾の次 戻り値 : true ... 正常終了 false ... 各文節の処理に失敗 */ bool Regex::compile( StrCit s, StrCit e ) { size_type nfa0 = vecNFA_.size() - 1; // グループの先頭 size_type nfa1 = 0; // グループの先頭(論理和で利用) for ( StrCit p = s ; p != e ; ++p ) { switch ( *p ) { case ATOM::QUOTE: // 末尾が '\' の場合は false を返す if ( ++p == e ) { cerr << "\\ can't be the last character of regex pattern." << endl; return( false ); } break; case ATOM::OR: if ( ! compileBranch( s, p ) ) return( false ); if ( ( s = p + 1 ) >= e ) return( true ); // 末尾に'|'があった場合は無視 if ( nfa1 != 0 ) NFA_Or( nfa0, nfa1 ); nfa1 = vecNFA_.size() - 1; break; case ATOM::GROUP_START: // グループは compileBranch で処理するのでスキップ p = FindGroupEnd( p, e ); if ( p == e ) return( false ); } } if ( ! compileBranch( s, e ) ) return( false ); if ( nfa1 != 0 ) NFA_Or( nfa0, nfa1 ); vecNFA_.back().clearMask(); vecNFA_.back().next0 = 0; vecNFA_.back().next1 = 0; return( true ); } /* Regex::compile : 構文解析ルーチン const string& pattern : 正規表現 戻り値 : true ... 正常終了 false ... 各文節の処理に失敗 */ bool Regex::compile( const string& pattern ) { vecNFA_.clear(); vecNFA_.push_back( NFAState() ); StrCit s = pattern.begin(); // pattern の開始 StrCit e = pattern.end(); // pattern の末尾の次 // 先頭に ^ があれば startFlg_ = true にしてスキップ if ( *s == ATOM::HEADOFPAT ) { ++s; startFlg_ = true; } // 末尾に $ があれば endFlg_ = true にしてスキップ if ( *( e - 1 ) == ATOM::ENDOFPAT ) { --e; endFlg_ = true; } return( compile( s, e ) ); }
まず、照合したい文字列 pattern がサンプル・プログラムの下側にある Regex::compile に渡され処理がスタートします。最初に vecNFA_ を初期化し、次に pattern の先頭に '^' が、また末尾に '$' がそれぞれないかをチェックします。もし '^' があれば startFlg_ を、'$' があれば endFlg_ をそれぞれ true とし、これらのメタ文字は解析対象から除外します。この方法では、これらのメタ文字が必ず先頭・末尾にあることを原則としています。つまりパターンの中で見つかったメタ文字 '^', '$' は通常の文字として扱われることになります。本来なら枝の先頭・末尾でチェックをするべきですが ( "^ab|^ba" や "(^ab)|(ba)" などの正規表現に対応できるようになる )、コーディングが少々面倒になる上に代替手段があるので ( 例えば "^ab|^ba" なら "^(ab|ba)"、"(^ab)|(ba)" なら "^(ab|.*ba)" でもほぼ同意になる ) 簡略バージョンとしました。
メタ文字 '^', '$' のチェックをした後、パターン文字列の先頭と末尾の次の位置を示す反復子を引数として上側の Regex::compile が呼び出されます。ここではメタ文字 '|' があるかどうかをチェックし、もし見つかったら、前回までに構文解析が完了した位置からメタ文字 '|' の手前までを一つの枝として、後述する Regex::compileBranch を使って構文解析します。但し、"( )" で囲まれた領域は一つのグループとして処理する必要があるので、'(' が見つかったら末尾を示す ')' が見つかるまで '|' は無視してまとめて Regex::compileBranch で構文解析します。処理前に、vecNFA_ の末尾の反復子を nfa0 に保持し、'|' がパターン文字列内に見つかったらそれまでの部分文字列を Regex::compileBranch で処理します。すると、vecNFA_ に解析した結果が保持されるので、今度は末尾の反復子を nfa1 に保持します。これらは、論理和で結合する枝の先頭を表しており、再度 '|' が見つかったら、構文解析後に nfa0 と nfa1 を使って論理和で結合します。この処理は Regex::NFA_Or で行います。その後、nfa1 を vecNFA_ の末尾の反復子で新たに更新しておきます。
ループ内では、'|' が二回見つかったら ( つまり論理和で結合される枝が三つあったら ) 最初の二つを論理和で結合します。つまり、末尾の枝はループ内では結合されないので、ループを抜けた時にもう一度処理を行う必要があります。また、'|' が見つからない場合は論理和で結合する必要はなく、この時は nfa1 はゼロのままなので、nfa1 の値で処理をするかどうかを判定します。二つ以上の枝が論理和で結合される場合は、まず最初の二つを結合し、次にその結合した結果と三つ目の枝を結合するということを繰り返していきます。図で表すと以下のようになります。

プログラム言語用のコンパイラでは、論理和は前側の論理式から評価しますが、上記方法では評価する順番は不定となります。しかし、影響のある個所は処理時間以外にはないため、ここでは評価順に関しては無視しています。
'(' が見つかった場合、'(' と ')' で囲まれたアトムが存在すると見なして末尾の ')' まで処理を FindGroupEnd 関数を使ってスキップします。このアトムの処理は、後述する Regex::compileBranch の中で行われます。FindGroupEnd 関数の実装内容は後ほど紹介します。
次に、論理和を NFA に変換するためのメンバ関数 regex::NFA_Or を示します。
/* Regex::NFA_Or : 論理和用 NFAState 作成 size_type idx0, idx1 : 二つの枝の先頭 idx0 idx1 (grp0 ... ) (grp1 ...) (empty) v idx0 idx1 |--------v---------------------v |---v |---v <branch> (grp0 ...) <grp0_end> (grp1 ...) (grp1_end) <empty> |---^ |-------------------------^ */ void Regex::NFA_Or( size_type idx0, size_type idx1 ) { // grp1 の先頭に grp0 の末尾を追加 vecNFA_.insert( vecNFA_.begin() + idx1, 1, NFAState() ); // grp0 の先頭に空分岐のための NFAState を挿入 vecNFA_.insert( vecNFA_.begin() + idx0, 1, NFAState() ); size_type branch = idx0; // 先頭の空分岐 ++idx0; // idx0 の補正 idx1 += 2; // idx1 の補正 // 先頭の空分岐に分岐先を代入 vecNFA_[branch].clearMask(); vecNFA_[branch].next0 = 1; vecNFA_[branch].next1 = idx1 - branch; // 二つの枝の末尾の分岐先を最後の空分岐に vecNFA_[idx1 - 1].clearMask(); vecNFA_[idx1 - 1].next0 = vecNFA_.size() - ( idx1 - 1 ); vecNFA_[idx1 - 1].next1 = 0; vecNFA_[vecNFA_.size() - 1].clearMask(); vecNFA_[vecNFA_.size() - 1].next0 = 1; vecNFA_[vecNFA_.size() - 1].next1 = 0; // 次の要素を用意しておく vecNFA_.push_back( NFAState() ); return; }
引数として渡されるのは論理和で結合したい二つの枝の先頭の添字です。二つの枝を grp0, grp1 としたとき、それぞれの枝の先頭に空文字を挿入し、grp0 の前にある空文字は各枝の先頭へ遷移するようにし、grp1 の前にある空文字は grp0 の末尾と連結した上で、vecNFA_ の末尾に新たに作成した空文字に遷移するようにします。また、grp1 の末尾も vecNFA_ 末尾の空文字と連結します。
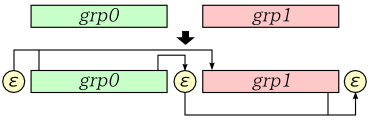
遷移先を表す next0 と next1 は相対位置であることから、前後に他の要素が挿入されたとしても補正をする必要はありません。これが遷移先を相対位置で表す理由になりますが、逆に実際の遷移先を求めるためには現在位置に next0 や next1 を加算する必要があります。
枝となる文字列の範囲が判明したら、それを引数に Regex::compileBranch で構文解析を行います。
/* FindGroupEnd : グループ化(...)の終端を見つける StrCit s : グループの開始 '(' がある個所 StrCit e : 探索範囲の終端の次 戻り値 : グループの終了 ')' が見つかった個所 見つからなかった場合は e が返される */ StrCit FindGroupEnd( StrCit s, StrCit e ) { int gCnt = 0; // グループが入れ子の場合、その数 StrCit p = s; // 終端を取り出すイテレータ for ( ; p != e ; ++p ) { if ( *p == ATOM::GROUP_END ) if ( --gCnt == 0 ) break; if ( *p == ATOM::GROUP_START ) ++gCnt; } // 終端まで ')' が見つからなかった if ( p == e ) cerr << "Unterminated group found." << endl; return( p ); } /* FindClassEnd : ブラケット表現[...]の終端を見つける StrCit s : ブラケット表現の開始 '[' がある個所 StrCit e : 探索範囲の終端の次 戻り値 : ブラケット表現の終了 ']' が見つかった個所 見つからなかった場合は e が返される */ StrCit FindClassEnd( StrCit s, StrCit e ) { StrCit p = s; // 終端を取り出すイテレータ while ( p != e && *p != ATOM::CLASS_END ) ++p; // 先頭に ']' ( または '^]' ) があった場合は再探索 if ( p != e ) { if ( p == s + 1 || // '[' の次に ']' ( ブラケットの先頭が ']' ) ( p == s + 2 && *( s + 1 ) == ATOM::CLASS_REVERSE ) // ブラケットの先頭が '^]' ) for ( ++p ; p != e && *p != ATOM::CLASS_END ; ++p ); } // 終端まで ']' が見つからなかった if ( p == e ) cerr << "Unterminated bracket found." << endl; return( p ); } /* Regex::compileBranch : 枝の構文解析 StrCit s : 枝の先頭 StrCit e : 枝の末尾の次 戻り値 : true ... 正常終了 false ... 各文節の処理に失敗, '\' が末尾にあった */ bool Regex::compileBranch( StrCit s, StrCit e ) { size_type headIdx = vecNFA_.size() - 1; // グループの先頭 StrCit p1; // 文字列探索用ポインタ const string anyChara = "^\n"; // 前キャラクタ (\nを除く) for ( StrCit p0 = s ; p0 != e ; ++p0 ) { switch ( *p0 ) { case ATOM::CHARA_ANY: headIdx = vecNFA_.size() - 1; if ( ! NFA_Class( anyChara.begin(), anyChara.end() ) ) return( false ); break; case ATOM::REPEAT0: if ( ! NFA_GEZeroRepeater( headIdx ) ) return( false ); headIdx = vecNFA_.size() - 1; break; case ATOM::REPEAT1: if ( ! NFA_GEOneRepeater( headIdx ) ) return( false ); headIdx = vecNFA_.size() - 1; break; case ATOM::REPEAT01: if ( ! NFA_LEOneRepeater( headIdx ) ) return( false ); headIdx = vecNFA_.size() - 1; break; case ATOM::GROUP_START: // グループの終端 ')' を探す p1 = FindGroupEnd( p0, e ); if ( p1 == e ) return( false ); headIdx = vecNFA_.size() - 1; if ( ! compile( p0 + 1, p1 ) ) return( false ); p0 = p1; break; case ATOM::CLASS_START: // ブラケット表現の終端 ']' を探す p1 = FindClassEnd( p0, e ); if ( p1 == e ) return( false ); headIdx = vecNFA_.size() - 1; if ( ! NFA_Class( p0 + 1, p1 ) ) return( false ); p0 = p1; break; case ATOM::QUOTE: // 末尾が '\' の場合は false を返す if ( ++p0 == e ) { cerr << "\\ can't be the last character of regex pattern." << endl; return( false ); } headIdx = vecNFA_.size() - 1; NFA_Quote( *p0 ); break; default: headIdx = vecNFA_.size() - 1; NFA_Chara( *p0 ); } } return( true ); }
Regex::compileBranch での処理は、パターン文字列から一文字ずつ読み込んでは文字の内容によって処理を振り分けるだけの単純なものです。対象の文字がメタ文字ならば、その内容に応じて呼び出す関数を切り替え、そうでなければ通常の文字と見なして処理します。NFA へ変換するための関数は、繰り返し表現を処理する Regex::NFA_GEZeroRepeater, Regex::NFA_NFA_GEOneRepeater, Regex::NFA_LEOneRepeater、ブラケット表現を処理する Regex::NFA_Class、エスケープ系列を処理する Regex::NFA_Quote、最後に通常の文字を処理する Regex::NFA_Chara があります。また、'(' が見つかったら ')' が見つかるまで走査して、() 内を正規表現としてもう一度 Regex::compile に処理させます。
'(', '[' が見つかったら、それぞれに対応する終端 ')', ']' を探します。個々の文字用に関数が分かれていますが ( FindGroupEnd, FindClassEnd )、一つにまとめることができないのは終端の判定方法や取得すべき内容がそれぞれ異なっているからです。
FindGroupEnd では () が入れ子になっている可能性があるため、終端探索の時に再度 '(' が見つかったらその数分だけ ')' を読み飛ばす必要があります。また FindClassEnd では、'[' のすぐ後に ']' が続く場合はそれを終端文字とはせずに次の ']' を探します。反転を表す '^' がある場合も同様なので、"[]" や "[^]" の後に ']' がなければ ']' が見つからないとみなされます。'^' の一致は "\^" で表現できるので、ここでは "[^]" は処理失敗と判定されるままにしています。
NFAState を作成する関数の中から、まずは繰り返し処理以外の NFA 変換用関数を以下に示します。
/* エスケープ・キャラクタの定義 */ struct ESCAPE_CHARA { char meta_chara; // メタキャラクタ string mask_chara; // 対象文字 } escape_chara[] = { { 'd', "0-9", }, // 数値 { 'D', "^0-9", }, // 数値以外 { 'w', "a-zA-Z0-9", }, // 英数字 { 'W', "^a-zA-Z0-9", }, // 英数字以外 { 's', " \t\f\r\n", }, // 空白文字 { 'S', "^ \t\f\r\n", }, // 空白文字以外 { 'h', " \t", }, // 水平空白文字 { 'H', "^ \t", }, // 水平空白文字以外 { 'v', "\n\v\f\r", }, // 垂直空白文字 { 'V', "^\n\v\f\r", }, // 垂直空白文字以外 { 'a', "\a", }, // アラーム(BEL=0x07) { 'b', "\b", }, // バック・スペース(BS=0x08) { 't', "\t", }, // 水平タブ(HT=0x09) { 'n', "\n", }, // 改行(LF=0x0A) { 'v', "\v", }, // 垂直タブ(VT=0x0B) { 'f', "\f", }, // 書式送り(FF=0x0C) { 'r', "\r", }, // 復帰(CR=0x0D) { 0, "", }, }; /* Regex::NFA_Quote : エスケープ系列用 NFAState 作成 unsigned char c : エスケープ・シーケンス内の文字 戻り値 : 常に true */ bool Regex::NFA_Quote( unsigned char c ) { // エスケープ系列に該当するか for ( struct ESCAPE_CHARA* esc = escape_chara ; esc->meta_chara != 0 ; ++esc ) if ( esc->meta_chara == c ) return( NFA_Class( ( esc->mask_chara ).begin(), ( esc->mask_chara ).end() ) ); // 該当なしの場合はキャラクタをそのまま処理 NFA_Chara( c ); return( true ); } /* Regex::NFA_Class : ブラケット表現用 NFAState 作成 StrCit s : ブラケット内部の開始 ( '[' の次 ) StrCit e : ブラケット終端 ( ']' のある個所 ) 戻り値 : true ... 正常終了 false ... 文字範囲の指定が不正 (empty) v |------v (back) <empty> ->set flag */ bool Regex::NFA_Class( StrCit s, StrCit e ) { // 末尾の要素を初期化 NFAState& back = vecNFA_.back(); back.clearMask(); // '^' が指定されているかチェック bool revFlg = false; if ( *s == ATOM::CLASS_REVERSE ) { revFlg = true; ++s; } for ( StrCit p = s ; p != e ; ++p ) { // 照合順序の処理 if ( p > s && ( p + 1 ) < e && *p == ATOM::CLASS_SEQUENCE ) { // 'x-y-z'のチェック if ( ( p + 3 ) < e && *( p + 2 ) == ATOM::CLASS_SEQUENCE ) { cerr << "Illegal range format in bracket (x-y-z)." << endl; return( false ); } // 順序が逆ならエラー if ( *( p - 1 ) > *( p + 1 ) ) { cerr << "Reverse sequence found in bracket (y-x)." << endl; return( false ); } for ( char c = *( p - 1 ) + 1 ; c <= *( p + 1 ) ; ++c ) back.setMask( c ); ++p; } else { back.setMask( *p ); } } if ( revFlg ) back.reverseMask(); // 左のみ次の要素に接続 back.next0 = 1; back.next1 = 0; back.isEmpty = false; // 次の要素を用意しておく vecNFA_.push_back( NFAState() ); return( true ); } /* Regex::NFA_Chara : 文字コード用 NFAState 作成 char c : 登録する文字コード (empty) v |------v (back) <empty> ->c */ void Regex::NFA_Chara( unsigned char c ) { NFAIt back = vecNFA_.end() - 1; back->setMask( c ); back->next0 = 1; back->next1 = 0; back->isEmpty = false; // 次の要素を用意しておく vecNFA_.push_back( NFAState() ); return; }
'\' が見つかったら、次はエスケープ文字であると見なして Regex::NFA_Quote を呼び出します。ESCAPE_CHARA 構造体の escape_chara 配列から該当するメタ文字があるかをチェックして、あれば該当するブラケット表現を抽出して後述する Regex::NFA_Class を呼び出し、該当しない場合は通常の文字と見なして Regex::NFA_Chara を使って処理します。
ブラケット表現に対しては、内部の文字列の範囲を引数として Regex::NFA_Class を使用します。文字列の内部にある文字を順番に呼び出して、NFAState インスタンスの文字パターンに対して該当する文字のビットを 1 にします。先頭や末尾以外の位置で '-' が見つかったら、その前後の文字の間は全て対象として処理を行います。'-' が先頭か末尾にあれば範囲指定と見なされないようにしているので、例えば "[-a-z]" や "[a-z-]" のような表現に対しては 'a' から 'z' までの文字列と '-' が対象になります。また、先頭に '^' がある場合は、処理後に文字パターンの全ビットを反転します。
通常の文字の処理は Regex::NFA_Chara を利用します。これは対象の文字コードに対応するビットを 1 にするだけの単純な関数です。
文字との照合を行う NFAState は Regex::NFA_Class と Regex::NFA_Chara の中でのみ作成されます。作成された NFAState は遷移先が必ず次の要素だけで、isEmpty は (たとえ照合する文字が存在しないとしても) false とします。今回は、文字パターンのビットがすべてゼロになるような場合は発生しないため、空文字かどうかを判定するために文字パターンを利用する方法もありますが、判定に文字パターン全てをチェックする必要があるためフラグだけで確認できるようにしています。
次に、繰り返し処理専用のメンバ関数を以下に示します。
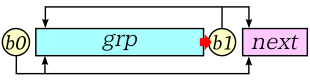
/* Regex::NFA_LEOneRepeater : 0,1 回の繰り返し用 NFAState 作成 size_type headIdx : 枝の先頭 戻り値 : true ... 正常終了 false ... 繰り返し対象がない headIdx (grp...) (empty) v headIdx +1 +n+1 |----v--------v <b0> (grp...) (empty) */ bool Regex::NFA_LEOneRepeater( size_type headIdx ) { // 繰り返し対象がない場合は false を返す if ( headIdx + 1 == vecNFA_.size() ) { cerr << "No group of repeat found." << endl; return( false ); } // 繰り返し対象の大きさ difference_type n = vecNFA_.size() - headIdx - 1; // 先頭に b0 を挿入 vecNFA_.insert( vecNFA_.begin() + headIdx, 1, NFAState() ); // b0 の初期化 NFAIt b0 = vecNFA_.begin() + headIdx; b0->clearMask(); b0->next0 = 1; b0->next1 = n + 1; return( true ); } /* Regex::NFA_GEOneRepeater : 1 回以上の繰り返し用 NFAState 作成 size_type headIdx : 枝の先頭 戻り値 : true ... 正常終了 false ... 繰り返し対象がない headIdx (grp...) (empty) v headIdx +n +n+1 v--------|----v (grp...) <b0> <empty> */ bool Regex::NFA_GEOneRepeater( size_type headIdx ) { // 繰り返し対象がない場合は false を返す if ( headIdx + 1 == vecNFA_.size() ) { cerr << "No group of repeat found." << endl; return( false ); } // 繰り返し対象の大きさ difference_type n = vecNFA_.size() - headIdx - 1; // b0 の初期化 NFAIt b0 = vecNFA_.end() - 1; b0->clearMask(); b0->next0 = -n; b0->next1 = 1; // 次の要素を用意しておく vecNFA_.push_back( NFAState() ); return( true ); } /* Regex::NFA_GEZeroRepeater : 0 回以上の繰り返し用 NFAState 作成 size_type headIdx : 枝の先頭 戻り値 : true ... 正常終了 false ... 繰り返し対象がない headIdx (grp...) (empty) v headIdx +1 +n+1 +n+2 |------v-------------v <b0> (grp...) (b1) <empty> ^--------|----^ */ bool Regex::NFA_GEZeroRepeater( size_type headIdx ) { // 繰り返し対象がない場合は false を返す if ( headIdx + 1 == vecNFA_.size() ) { cerr << "No group of repeat found." << endl; return( false ); } // 繰り返し対象の大きさ difference_type n = vecNFA_.size() - headIdx - 1; // 先頭に b0 を挿入 vecNFA_.insert( vecNFA_.begin() + headIdx, 1, NFAState() ); // b0 の初期化 NFAIt b0 = vecNFA_.begin() + headIdx; b0->clearMask(); b0->next0 = 1; b0->next1 = n + 2; // b1 の初期化 NFAIt b1 = vecNFA_.end() - 1; b1->clearMask(); b1->next0 = -n; b1->next1 = 1; // 次の要素を用意しておく vecNFA_.push_back( NFAState() ); return( true ); }
繰り返し処理のために、三つのメンバ関数 Regex::NFA_LEOneRepeater, Regex::NFA_GEOneRepeater, Regex::NFA_GEZeroRepeater が用意されています。Regex::NFA_LEOneRepeater は一回以下、つまりゼロ回か一回の繰り返し、Regex::NFA_GEOneRepeater は一回以上の、Regex::NFA_GEZeroRepeater はゼロ回以上の制限のない繰り返しに対応しています。
Regex::NFA_LEOneRepeater では、対象のアトムの前に空文字 b0 を挿入します。b0 の next0 に 対象のアトムの先頭への相対位置、next1 に対象のアトムの次の要素への相対位置を登録し、b0 に到達したら対象のアトムの先頭から照合する経路とスキップする経路の二つに分岐するようにします。

Regex::NFA_GEOneRepeater は一回以上の繰り返しなので、アトムの先頭では何もせずそのまま照合させ、末尾側に分岐用の空文字 b0 を用意します。b0 に遷移したところでアトムの先頭と次の要素に分岐するようにすれば、少なくとも一回の繰り返しが実現できます。

最後の Regex::NFA_GEZeroRepeater は前者二つの関数の組み合わせで実現することができます。アトムの先頭の前に b0、末尾の後に b1 と二つの空文字を用意して、どちらの空文字もアトムの先頭と b1 の次の要素に遷移するようにします。これで、ゼロ回以上の無制限の繰り返しを行うことができます。
サンプル・プログラムを使って正規表現をコンパイルした結果を以下に示します。表示するための関数は以下のようなものになります。
/* NFA_Print : NFAState マスクパターンの出力 (一文字出力) const vector<unsigned char>& charaMask : マスクパターン size_t index : ビット位置 const string& format : 出力フォーマット */ void NFA_Print( const vector<unsigned char>& charaMask, size_t index, const string& format ) { vector<unsigned char>::size_type vecIdx = index / CHAR_BIT; vector<unsigned char>::size_type maskIdx = index % CHAR_BIT; if ( ( ( charaMask[vecIdx] >> maskIdx ) & 1 ) != 0 ) printf( format.c_str(), index ); } /* NFA_Print : NFAState マスクパターンの出力 (範囲指定時の一文字出力) const vector<unsigned char>& charaMask : マスクパターン size_t index : ビット位置 const string& format : 出力フォーマット int bitOnIdx : 前にビットが立っていた位置 戻り値 : 更新した bitOnIdx */ int NFA_Print( const vector<unsigned char>& charaMask, size_t index, const string& format, int bitOnIdx ) { vector<unsigned char>::size_type vecIdx = index / CHAR_BIT; vector<unsigned char>::size_type maskIdx = index % CHAR_BIT; if ( ( ( charaMask[vecIdx] >> maskIdx ) & 1 ) != 0 ) { if ( bitOnIdx < 0 ) { printf( format.c_str(), index ); bitOnIdx = index; } return( bitOnIdx ); } else { if ( bitOnIdx >= 0 ) { if ( (size_t)( bitOnIdx + 1 ) < index ) printf( ( "-" + format + " " ).c_str(), index - 1 ); } return( -1 ); } } /* NFA_Print : NFAState マスクパターンの出力 (範囲出力) const vector<unsigned char>& charaMask : マスクパターン size_t s : 開始ビット位置 size_t e : 終了ビット位置の次 const string& format : 出力フォーマット */ void NFA_Print( const vector<unsigned char>& charaMask, size_t s, size_t e, const string& format ) { int bitOnIdx = -1; for ( size_t i = s ; i < e ; ++i ) bitOnIdx = NFA_Print( charaMask, i, format, bitOnIdx ); if ( bitOnIdx >= 0 && (size_t)( bitOnIdx + 1 ) < e ) printf( ( "-" + format ).c_str(), e - 1 ); } /* NFAState::print : NFAState のマスクパターンを表示する */ void NFAState::print() const { if ( isEmpty ) return; NFA_Print( charaMask_, 0, '\a', "0x%02X" ); // control code 0x00-0x08 NFA_Print( charaMask_, '\a', "\\a" ); // BEL NFA_Print( charaMask_, '\b', "\\b" ); // BS NFA_Print( charaMask_, '\t', "\\t" ); // HT NFA_Print( charaMask_, '\n', "\\n" ); // LF NFA_Print( charaMask_, '\v', "\\v" ); // VT NFA_Print( charaMask_, '\f', "\\f" ); // FF NFA_Print( charaMask_, '\r', "\\r" ); // CR NFA_Print( charaMask_, 0x0E, ' ', "0x%02X" ); // control code 0x0E-0x1F NFA_Print( charaMask_, ' ', "(SPACE)" ); // SPACE for ( unsigned char c = '!' ; c < '0' ; ++c ) NFA_Print( charaMask_, c, "%c" ); // 0x21-0x2F NFA_Print( charaMask_, '0', ':', "%c" ); // 数値 for ( unsigned char c = ':' ; c < 'A' ; ++c ) NFA_Print( charaMask_, c, "%c" ); // 0x3A-0x40 NFA_Print( charaMask_, 'A', '[', "%c" ); // 英大文字 for ( unsigned char c = '[' ; c < 'a' ; ++c ) NFA_Print( charaMask_, c, "%c" ); // 0x5B-0x60 NFA_Print( charaMask_, 'a', '{', "%c" ); // 英小文字 for ( unsigned char c = '{' ; c < 0x7F ; ++c ) NFA_Print( charaMask_, c, "%c" ); // 0x7B-0x7E NFA_Print( charaMask_, 0x7F, "(DEL)" ); // DEL NFA_Print( charaMask_, 0x80, 0x100, "0x%02X" ); // control code 0x80-0xFF } /* Regex::print : NFA の表示ルーチン */ void Regex::print() const { for ( size_type st = 0 ; st < vecNFA_.size() ; ++st ) { printf( "%.3u : mask=", (unsigned int)st ); vecNFA_[st].print(); cout << " next0="; if ( vecNFA_[st].next0 != 0 ) cout << st + vecNFA_[st].next0; else cout << "NULL"; cout << " next1="; if ( vecNFA_[st].next1 != 0 ) cout << st + vecNFA_[st].next1; else cout << "NULL"; cout << endl; } }
表示例: (abc)*|(def)* 000 : mask= next0=1 next1=7 001 : mask= next0=2 next1=6 002 : mask=a next0=3 next1=NULL 003 : mask=b next0=4 next1=NULL 004 : mask=c next0=5 next1=NULL 005 : mask= next0=2 next1=6 006 : mask= next0=13 next1=NULL 007 : mask= next0=8 next1=12 008 : mask=d next0=9 next1=NULL 009 : mask=e next0=10 next1=NULL 010 : mask=f next0=11 next1=NULL 011 : mask= next0=8 next1=12 012 : mask= next0=13 next1=NULL 013 : mask= next0=NULL next1=NULL (\w|\s)+ 000 : mask= next0=1 next1=3 001 : mask=0-9A-Za-z next0=2 next1=NULL 002 : mask= next0=5 next1=NULL 003 : mask=\t\n\f\r(SPACE) next0=4 next1=NULL 004 : mask= next0=5 next1=NULL 005 : mask= next0=0 next1=6 006 : mask= next0=NULL next1=NULL
表示用プログラムの中で、NFAState のメンバ関数 print に関連する処理が少し複雑に見えますが、ある範囲にある文字 ( 例えば 'A' から 'Z' までの英大文字 ) に対してビットが連続して 1 になっていた時に "A-Z" のような表現でまとめて表示したいため、前回ビットが 1 になった場所を記憶して、連続した個所がチェックできるようにしてあります。しかし、一文字ずつ表現したい個所もあったので、一文字専用のプログラムも用意し、出力する文字コードに応じて切り替えています。そのためメイン・ルーチンの NFAState::print が冗長に見えますが、内容としてはそれほど複雑なことはしていません。
NFA への変換が終わったら、あとはそれを使って文字列との照合を行うだけです。まずは照合処理のサンプル・プログラムを以下に示します。
/* Regex::addBuffer : バッファへの登録(重複チェック付き) vector<NFACit>& vecBuffer : 対象のバッファ NFACit nfa : 登録対象の NFACit */ void Regex::addBuffer( vector<NFACit>& vecBuffer, NFACit nfa ) { for ( vector<NFACit>::iterator it = vecBuffer.begin() ; it != vecBuffer.end() ; ++it ) if ( *it == nfa ) return; vecBuffer.push_back( nfa ); } /* Regex::regexSub : 正規表現によるパターン照合(メイン・ルーチン) StrCit s : 照合開始位置 StrCit e : 照合終了位置の次 戻り値 : 一致範囲の次の位置 */ StrCit Regex::regexSub( StrCit s, StrCit e ) const { vector<NFACit> buffer[2]; // バッファ(切り替えのため二つ準備) StrCit matched = s; // 一致範囲の次の位置 int sw = 0; // buffer の切り替えフラグ buffer[sw].push_back( vecNFA_.begin() ); for ( ; s <= e ; ++s ) { for ( vector<NFACit>::size_type i = 0 ; i < buffer[sw].size() ; ++i ) { NFACit nfa = buffer[sw][i]; // 終点に達したら一致範囲末尾の次のポインタを登録 if ( nfa->next0 == 0 && nfa->next1 == 0 ) { matched = s; // 空文字遷移の場合は同じバッファに登録する } else if ( nfa->isEmpty ) { if ( nfa->next0 != 0 ) addBuffer( buffer[sw], nfa + nfa->next0 ); if ( nfa->next1 != 0 ) addBuffer( buffer[sw], nfa + nfa->next1 ); // 文字パターンがマッチしたら,もう一方のバッファに次の状態を登録 } else if ( s < e && nfa->checkChara( *s ) ) { addBuffer( buffer[sw^1], nfa + nfa->next0 ); } } buffer[sw].clear(); sw ^= 1; // バッファの切り替え if ( buffer[sw].empty() ) break; // 次のバッファが空なら終了 } return( matched ); } /* Regex::regex : 文字列の先頭ポインタを後ろにずらしながら パターン照合ルーチンを呼び出す StrCit& s : 照合開始位置 StrCit& e : 照合終了位置の次 戻り値 : 一致したか (一致文字列が NULL の場合は false となる) */ bool Regex::regex( StrCit& s, StrCit& e ) const { for ( ; s < e ; ++s ) { StrCit matched = regexSub( s, e ); if ( matched != s ) { // 行末で終わっているか? if ( ( ! endFlg_ ) || matched == e ) { e = matched; return( true ); } } // 行頭を示すメタキャラクタがあった場合は一度だけ処理 if ( startFlg_ ) return( false ); } return( false ); } /* Regex::regex : パターン照合ルーチン const string& str : 照合する文字列 StrCit& s, e : 一致範囲 ( e は末尾の次の位置 ) 戻り値 : 一致したか (一致文字列が NULL の場合は false となる) */ bool Regex::regex( const string& str, StrCit& s, StrCit& e ) const { if ( str.size() == 0 ) return( false ); s = str.begin(); e = str.end(); return( regex( s, e ) ); }
公開メンバ関数は一番最後にある Regex::regex で、照合する文字列 str と、一致した文字列の範囲を string 用反復子の型で取得するための s, e を引数としています。空文字ならばここですぐに false を返し、そうでなければ文字列の先頭と末尾の次の反復子を s, e にそれぞれセットして次のサブ・ルーチンを呼び出します。
呼び出されたサブ・ルーチンの名前も Regex::regex ですが、引数は文字列の先頭と末尾の次の反復子を表す s, e の二つです。ここでは、s の位置を先頭から末尾側に一つずつシフトさせながら次のサブ・ルーチン Regex::regexSub を呼び出し、一致したと判定されたら true を返します。s と e は参照渡しなので、一致文字列の範囲はそのまま返されるようになっています。正規表現に行頭を表す '^' と行末を表す '$' が付加されていた場合、コンパイル処理の中で startFlg_ と endFlg_ がそれぞれセットされます。startFlg_ が true のとき、照合処理は s が文字列の先頭を示しているときだけ行えばよいので、最初の処理が終わったらすぐにループを抜けます。また、endFlg_ が true のときは、照合個所の末尾 ( これは Regex::regexSub によって返され、変数 matched に代入されています ) が文字列末尾の次の反復子 e と等しい場合だけ照合成功と見なすようにしています。
Regex::regexSub がパターン照合処理を実際に行う個所になります。各状態に対して並列処理を行うため、照合したと見なされた状態を保持するためのバッファ buffer を二本用意して、空文字による遷移では今使用しているバッファに、文字パターンによる遷移ではもう片方のバッファにそれぞれ次の移動先を追加しながら照合を進めていき、空になった時点でバッファを交換します。次に使用するバッファが空の場合はこれ以上処理しても無意味なのでループを抜けます。ループの中で vecNFA_ の終点まで到達したら、その時の文字位置を変数に代入しています。ここでループを抜けるようにすれば、最短の照合パターンを得ることができるようになりますが、サンプルではそのまま処理を続けているため、最長一致文字が抽出できるようになっています。
いくつかの文字列に対して照合を行った結果を以下に示します。NFA のコンパイル結果の後に、照合する対象文字列の中で一致が検出されたものだけが一致した範囲とともに出力されます。一致範囲は対象文字列の下側に '^' を使って示されています ( 一文字だけ一致した場合はその位置が一つの '^' で示されます )。
■ 照合する対象文字列
0123456789 abcdefghijklmnopqrstuvwxyz 0 1 2 3 Perl = Pathologically Eclectic Rubbish Lister 正規表現
■ 照合結果
000 : mask=0-9 next0=1 next1=NULL
001 : mask= next0=0 next1=2
002 : mask= next0=NULL next1=NULL
0123456789
^ ^
0 1 2 3
^
000 : mask=a-z next0=1 next1=NULL 001 : mask= next0=0 next1=2 002 : mask= next0=NULL next1=NULL abcdefghijklmnopqrstuvwxyz ^ ^ Perl = Pathologically Eclectic Rubbish Lister ^ ^
000 : mask=a-z next0=1 next1=NULL 001 : mask= next0=0 next1=2 002 : mask= next0=NULL next1=NULL abcdefghijklmnopqrstuvwxyz ^ ^
000 : mask=0xE6 next0=1 next1=NULL 001 : mask=0xAD next0=2 next1=NULL 002 : mask=0xA3 next0=3 next1=NULL 003 : mask=0xE8 next0=4 next1=NULL 004 : mask=0xA6 next0=5 next1=NULL 005 : mask=0x8F next0=6 next1=NULL 006 : mask=0xE8 next0=7 next1=NULL 007 : mask=0xA1 next0=8 next1=NULL 008 : mask=0xA8 next0=9 next1=NULL 009 : mask=0xE7 next0=10 next1=NULL 010 : mask=0x8F next0=11 next1=NULL 011 : mask=0xBE next0=12 next1=NULL 012 : mask= next0=NULL next1=NULL 正規表現 ^ ^
最後に "正規表現" というパターンを正規表現として出力し、対象文字列の中で同じ文字列がヒットしていますが、その一致した範囲はうまく表現できていません。文字コードとして UTF-8 を利用したため文字は 3 バイトであり、コンパイル結果は 3 bytes x 4 文字 + 終端 = 13 個の NFAState で表現されています。そのため、一致範囲は 12 バイト分とみなされズレてしまっているわけです。UTF-8 の場合はある文字に対応する文字コードが他の文字のコード内に含まれることがないように設計されているため、誤った照合がされる場合はないのですが、他の文字コードではそのような問題が発生する場合もあります。多バイト文字の扱いについては「検索アルゴリズム (4) 文字列の検索 - 2 -」の「3) 多バイトコードの扱い」でも紹介しています。
今回は、有限オートマトンを使った正規表現による文字列照合処理を紹介しました。今回紹介したプログラムに Bound 指定の "{m,n}" が実装されれば実用レベルにはなると思いますが、Linux や FreeBSD 等の UNIX ライクな OS なら正規表現用のライブラリは標準で用意されていますし、Windows なら Java や .Net Framework などでライブラリがあるので、あくまでもサンプル・プログラムとして見ていただければと思います。
処理方法を理解することは、正規表現を使う上でも非常に役立つと思います。正規表現の使い方がいまいちよくわからないという方は、ぜひ参考にしてみて下さい。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |