| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
今まで、「速いソート・ルーチン」としてシェル・ソートやコム・ソート、ヒープ・ソートを紹介してきました。今回は最後に残された「速いソート・ルーチン」として「クイック・ソート」を紹介します。クイック・ソートは、その名が示す通り現時点で最高速を誇るアルゴリズムとして知られ(補足1)、初期化の手間が要らず、細部の処理も簡潔であることからヒープ・ソートよりもさらに処理は速くなります。
「クイック・ソート(Quick Sort)」のアルゴリズムは、上にも書いたようにいたってシンプルです。
配列を分割する処理は
となります。
x として全くでたらめな数値を使用してもアルゴリズムは正常に動きますが、配列中の値を使用するとその位置で必ず走査が停止するため「番人」の役割を持たせることになり、走査位置が配列の先頭(または末尾)に達したかをチェックする必要がなくなって処理を簡略化することができます。配列を分割する処理で x 以上(または x 以下)の値を探すようにしているのは、x が「番人」として働くようにするためです。
配列を分割する処理の例を下図に示します。
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
例を見れば分かるように、L と R がすれ違った時点で L は必ず x 以上の要素を持つ配列の先頭を、また R は x 以下の要素を持つ配列の末尾をそれぞれ示すことになります(但し、両者が「番人」と等しい同じ位置の要素を示す場合もあります)。
クイック・ソートのサンプル・プログラムを以下に示します。
/* QuickSort : クイック・ソートによるソート・ルーチン Ran first, last : ランダム・アクセス反復子(ソート開始と終了) Less less : 要素比較用関数オブジェクト(boolを返す二項叙述関数) */ template<class Ran, class Less> void QuickSort( Ran first, Ran last, Less less ) { // 反復子の要素の型 typedef typename Ran::value_type value_type; if ( last - first <= 1 ) return; value_type x = first[( last - first ) / 2]; // ピボット Ran l = first; Ran r = last - 1; for (;;) { while ( less( *l, x ) ) ++l; while ( less( x, *r ) ) --r; if ( l >= r ) break; swap( l, r ); ++l; --r; } QuickSort( first, l, less ); QuickSort( l, last, less ); }
クイック・ソートのアルゴリズムは再帰的であり、コーディングも再起呼び出しを使用することですっきりとした形で記述できます。サンプル・プログラムの中では、分割したそれぞれの配列を処理するため最後の二行で自分自身を呼び出しています。
L は x 以上の要素を持つ配列の先頭を示すと同時に、x 以下の要素を持つ配列の末尾の次の要素を示すことにもなります。したがって再起呼び出し時には L のみを用いれば充分です。
一般に、高速化のために処理を複雑にしたソート・アルゴリズムの場合、要素数が少ない場合は単純なソート・アルゴリズムよりも遅くなる傾向にあります。クイック・ソートも例外ではなく、要素数が充分少ないときにはクイック・ソートではなくもっと単純なソート・ルーチン(例えば挿入ソート)を使用した方が処理は速くなります。
クイック・ソートは再帰的なアルゴリズムであるため、配列が細かく分割するにつれてその数も多くなり、処理速度が極端に下がってしまいます。そこで、処理を行う前に要素数をチェックして、充分小さい場合は単純なソート・アルゴリズムに切り替えることにより、処理は高速になります。
高速化を施したコーディング例を以下に示します。
/* CombinedQuickSort : クイック・ソートによるソート・ルーチン(途中で他のソート法に切り替える) Ran first, last : ランダム・アクセス反復子(ソート開始と終了) Less less : 要素比較用関数オブジェクト(boolを返す二項叙述関数) void (*func)( Ran, Ran, Less ) : 切り替え用ソート・ルーチン typename Ran::difference_type min : 切り替えを行うデータ数最小値 */ template<class Ran, class Less> void CombinedQuickSort( Ran first, Ran last, Less less, void (*func)( Ran, Ran, Less ), typename Ran::difference_type min ) { // 反復子の要素の型 typedef typename Ran::value_type value_type; if ( last - first <= min ) { func( first, last, less ); return; } value_type x = first[( last - first ) / 2]; // ピボット Ran l = first; Ran r = last - 1; for (;;) { while ( less( *l, x ) ) ++l; while ( less( x, *r ) ) --r; if ( l >= r ) break; swap( l, r ); ++l; --r; } CombinedQuickSort( first, l, less, func, min ); CombinedQuickSort( l, last, less, func, min ); }
この例では、データ数が min 以下になったら単純ソート・アルゴリズムでソートするように切り替えています。対象のソート・ルーチンは func で渡すようにして、任意のアルゴリズムに切り替えることができるようにしています。
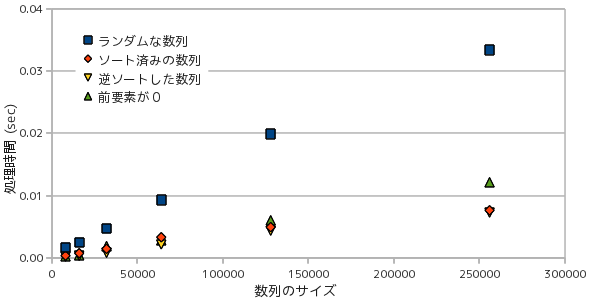
まずは、データ数に対する処理時間の計測結果を以下に示します。テスト回数は 20 回で、その平均値を示しています。
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ランダムな数列に対しては、前回の「ヒープ・ソート」とほぼ同程度の速度という結果になりました。比較用のソート法として、Standard Template Library(STL) にある sort と stable_sort (補足2) の両関数に対して処理したときの時間もあわせて示してありますが、こちらはさらに短い時間で処理することができます。
クイック・ソートの処理時間は、ヒープ・ソートの場合と同様に、平均的にはデータ数 N に対して N・log2N にほぼ比例します。したがって、グラフはほぼ直線を描いています。ソート済みの配列は交換作業がほとんどなくなり、逆ソートされた配列ははじめのパスでソート済み配列になるので、どちらもランダムな数列に比べて処理時間が短くなっています。
クイック・ソートを使用する場合、データ列の並び方によっては処理時間が N2 にまで落ち込むことも考えられます。これはピボット x の取り方に大きく依存し、もし一回のパスでデータ列の最小値(または最大値)を選んでしまった場合、最小値(または最大値)だけからなるデータ列と、残り全ての要素を持つデータ列に分割されます。これが全てのパスで繰り返されると 1 パスごとに最小値(または最大値)を選ぶことになり、「バブル・ソート」などの遅いソート処理と変わらなくなってしまい、処理時間は N2 のオーダーとなります。このようなことは滅多に起こることはありませんが、クイック・ソートにはこのような「最悪のケース」もあることを知っておく必要があります。このような現象を避けるために、ランダムに要素を選択した上でそのメディアン値(中央値)をピボットとして採用するなどの手法が考えられています。
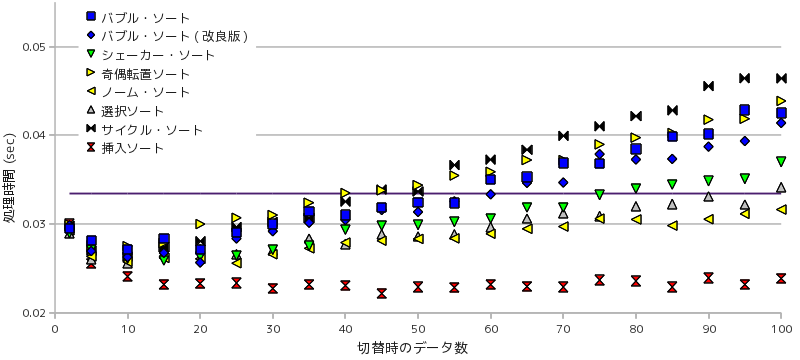
途中で他のソート・ルーチンに切り替えた場合の計測結果を以下に示します。いずれも、データは乱数列でそのサイズは 256000、テスト回数は 20 回としています。
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
上側のグラフ 3-3 は、単純なソート法へ切り替えるときのデータ数を最大 100 まで変化させた場合の処理時間を示しています。0.033 付近にあるラインは通常の(切替を行わない)クイック・ソートによる処理時間になります。どのソート法を利用しても、データ数が 40 程度になるまでに切り替えれば、通常のクイック・ソートよりも速くなるという結果が得られました。特に効果が高いのが挿入ソートを使った場合で、切替時のデータ数が 15 から 100 になるまでの間、処理時間が変化しないという特有の現象も見られます。その処理速度は、STL の場合とほぼ同等なレベルとなっています。
下側のグラフ 3-4 は、切替時のデータ数をさらに大きくした場合の処理時間の推移を示しています。データ数が大きくなるに従い、単純なソート法の処理時間がデータ数の二乗のオーダーで増加することから急激に遅くなる傾向が見られ、たとえ挿入ソートを利用しても逆効果となります。以上から、切替時のソート法には挿入ソートを使い、データ数 50 程度を目安に切り替えるのが最も効率のよい手法であるという結果となりました。
今まで紹介したソート・ルーチンは「真面目に」処理を行うアルゴリズムばかりでしたが、対象とする要素に制限を加えれば、今まで紹介したアルゴリズムより処理速度の速いものも存在します。
ソート・ルーチンのアルゴリズムは、どれも「データの比較」と「データの交換」を行うことで並べ替えを実現していましたが、ここで紹介するアルゴリズムでは「データを数える」ことでソートを行います。例えば、要素の範囲が 0 から 255 であるデータ列をソートする場合、
とすることでソートはできてしまいます。このようなアルゴリズムを「バケット・ソート(Bucket Sort)」または「分布数えソート(Distribution Counting Sort)」といい、このように比較を必要としない(データの分布を利用してソートする)手法を「分布ソート(Distribution Sort)」というようです。アルゴリズムを見ればわかるように、この方法では要素の種類があらかじめ分かっているデータのソートしかできませんし、確保しなければならないカウンタ配列の大きさは要素の種類の数に依存することになります。しかし、取りうる要素を限定すれば(例えば文字列中に含まれる文字のソートを行うなど)、処理が単純でしかも処理速度がデータ数 N に比例するため圧倒的に早い処理が可能になります。
バケット・ソートのサンプル・プログラムを以下に示します。
/* BucketSort : バケット・ソートによるソート・ルーチン Ran first, last : ランダム・アクセス反復子(ソート開始と終了) */ template<class Ran> void BucketSort( Ran first, Ran last ) { // 反復子の要素の型 typedef typename Ran::value_type value_type; vector<unsigned int> cnt( std::numeric_limits<value_type>::max(), 0 ); for ( Ran r = first ; r < last ; ++r ) ++cnt[*r]; for ( unsigned int i = 0 ; i < cnt.size() ; ++i ) { for ( unsigned int j = 0 ; j < cnt[i] ; ++j ) { if ( first == last ) return; *first++ = i; } } }
テンプレートを利用して任意の型のデータ列を処理可能としていますが、実際には符号なしの整数値で範囲の小さいもの、例えば unsigned char や unsigned short int 程度にしか利用できません。しかし、処理も単純なため処理速度は非常に速く、unsigned char 型の 256000 個のデータ列を処理する時間はクイック・ソートの 1 / 10 以下になります。
ソート処理の中で行われる比較処理において「等しい」と判断される要素が複数あったとき、元のデータ列の中での順序を保持する場合とそうでない場合があります。前者の場合は「安定なソート(Stable Sort)」といいます。したがって、後者は「安定でないソート」ということになります。安定なソートになるためには、等しい要素の前後関係が処理中に逆転しないことが必要になります。
単純なソートは全て安定なソートにすることができますが、安定なソートになるかどうかは比較方法に依存します。バブル・ソートをはじめとする交換ソートは、要素の配置を大小関係で判断して入れ替えることで並べ替えを行っているので、等しい場合も並べかえをしてしまえば安定なソートにはなりません。また、選択ソートの場合は、配列の末尾(または先頭)にあたる要素を探してから末尾(または先頭)と交換する処理を繰り返すので、末尾(または先頭)側に近い要素を優先して採用しないと安定なソートにはなりません。挿入ソートの場合、先頭から順にソートするのであれば、等しい要素が見つかった場合にその直後に挿入すれば安定なソートになります。
しかし、サイクル・ソートの場合だけは例外で、交換処理によって前後関係が逆転する可能性があるため安定なソートにすることはできません。例えば、交換処理によって未ソートな列の先頭に移動した要素が、未ソート列の中の最小値(昇順に並べていると仮定して)であった場合、それ以上移動することはありません。このとき、交換した要素の間にも最小値があれば、前後関係が逆転したままソートが完了することになります。
「(1) 遅いソート・ルーチン」で紹介したソート法で示したサンプル・プログラムの中では、選択ソートとサイクル・ソート以外は全て「安定なソート」になっています。
「シェル・ソート」「コム・ソート」「ヒープ・ソート」「クイック・ソート」といった速い部類のソートは通常全て「安定でないソート」になります。「シェル・ソート」や「コム・ソート」は適当な飛び幅を決めてソートしていることから前後関係は逆転する可能性があり「安定なソート」にはなりません。また「ヒープ・ソート」も要素をふるい落とす時や末尾と根を交換する時に順序が逆転することを避けることができません。「クイック・ソート」の場合、前後にあるデータを入れ替えるときに順序が変わってしまいます。
「クイック・ソート」の場合、前方と後方の要素を交換するのではなく他のバッファに登録して(このとき、空になった位置は除外する必要があります)、走査位置がすれ違ったらその位置に空き領域を作って、その中に元の並び順を保った状態で挿入すれば前後関係は保つことができます。しかし、処理速度を犠牲にすることは避けられなくなります。
安定なソートでなければならない場面はそれほど発生することはありません。すでにある規則にしたがってソートされていたとして、等しい要素の順序はそのままに別の方法でソートする場合に利用することになりますが、そのときは前の規則も含めて比較処理を行えば済みます。比較処理時間が極端に長くなる場合や、比較処理自体に制限がある場合に安定なソートが必要となる可能性があります。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |