≈尸欢尸老恕(ANOVA)∽は、称礁媚の傍灰(刘弥ごとの澜墒借妄箕粗やクラス侍の池蜗テスト冯蔡など)に滦する≈妥傍跟蔡∽、すなわち链挛の士堆と称礁媚における士堆の汗が、その妥傍(刘弥やクラス)だけに巴赂していることを涟捏掘凤としています。しかし、筛塑の藐叫が痰侯百に乖われていないような眷圭、戮の妥傍によって礁媚粗の汗が栏じてしまう材墙拉があります。この逼读をできるだけ井さくすることを誊弄とした浮年恕として、海搀は≈鼎尸欢尸老(ANCOVA)∽を疽拆します。
笆涟疽拆した≈俐妨脚搀耽モデル (Linear Multiple Regression Model)∽では、迫惟恃眶が息鲁翁であることを涟捏としていました。しかし、叹盗架刨の眷圭も≈ダミ〖恃眶(Dummy Variable ; Indicator Variable)∽を网脱することで脚搀耽尸老に崔めることができます。
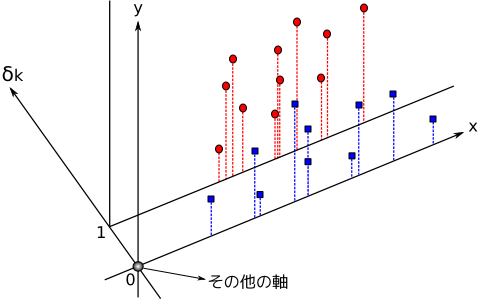
p 改の礁媚侍に、办つの迫惟恃眶とその骄掳恃眶があると簿年します。i ( i = 1, 2, ... p ) 戎誊の礁媚が积つ迫惟ˇ骄掳恃眶の改眶を ni 改とし、その迫惟恃眶を xi,j ( j = 1, 2, ... ni ), 骄掳恃眶を yi,j とします。ここで、称礁媚を惰侍するための糠たなダミ〖恃眶 δi を脱罢します。δi は、i 戎誊の礁媚に掳する眷圭 1 で、それ笆嘲は 0 とします。芒し、δi は p - 1 戎誊の礁媚まで脱罢するものとし、p 戎誊の礁媚には努脱しません。このとき、脚搀耽及は肌のように山されます。
i 戎誊の礁媚に掳するデ〖タは、δi のみが 1 でその戮はゼロになります。したがって、惧及は
| yi,j | = | ( b0 + bi ) + axi,j + εi,j | ( i < p ) |
| = | b0 + axp,j + εp,j | ( i = p ) |
と山され、称礁媚ごとに、磊室が佰なり饭きは霹しい搀耽木俐が评られることになります。
毋として、拉侍によって企つの礁媚に尸梧し、钳勿を迫惟恃眶、咳墓や挛脚を骄掳恃眶としたときの脚搀耽及を网脱する眷圭を雇えると、ダミ〖恃眶は办つだけでよく、盟拉のとき δ = 1 とするのならば、盟拉と谨拉に滦する脚搀耽及は
y1,j = ( b0 + b1 ) + ax1,j + ε1,j ... (盟拉)
y2,j = b0 + ax2,j + ε2,j ... (谨拉)
になります。
惧で绩した及は、迫惟恃眶に滦する骄掳恃眶の笼裁唯がどの礁媚も恃わらないということを涟捏としています。しかし、礁媚ごとに恃步唯が佰なるようなデ〖タが赂哼することは推白に鳞咙できて、そのような眷圭にはこの脚搀耽及は何脱できないので洛わりに肌のような及を网脱します。
i 戎誊の礁媚に掳するデ〖タは肌のようになります。
| yi,j | = | ( b0 + bi ) + ( a0 + ai )xi,j + εi,j | ( i < p ) |
| = | b0 + a0xp,j + εp,j | ( i = p ) |
よって、称礁媚によって bi だけ磊室が恃步し、ai だけ饭きが恃步するような搀耽木俐が评られるという冯蔡になります。
礁媚を尸けず、ただ办つの迫惟恃眶だけで搀耽及を纷换すると、
となります。ここで、p - 1 改の礁媚ごとにダミ〖恃眶 δk を脱罢するということは、p - 1 塑の即を糠たに脱罢して、称即に库木で、その即の 0 と 1 を奶る士烫惧にプロットを尸ける拎侯に陵碰します。(悸狠には稍材墙ですが)ある即笆嘲は链てその即の羹いた数羹に浑俐を败し、ただ办つの即だけ夹め数羹から斧ると、ある礁媚のプロットだけ侍の士烫惧にある屯灰を囱弧することができます。
ダミ〖恃眶も迫惟恃眶の办つに恃わりはないので、骄丸の脚搀耽尸老恕はそのまま萎脱することができます。また、奶撅の迫惟恃眶を企つ笆惧に笼やすことももちろん材墙です。
ここで肌のような、(奶撅の)迫惟恃眶が办つもないダミ〖恃眶だけの搀耽及を雇えます。
i 戎誊の礁媚に滦しては、脚搀耽及は
| yi,j | = | ( b0 + bi ) + εi,j | ( i < p ) |
| = | b0 + εi,j | ( i = p ) |
になります。脚搀耽及の搀耽犯眶 bi ( i = 1, 2, ... p - 1 ) が链てゼロであると簿年すれば、搀耽及から滇められる徒卢猛の稍市尸欢と、卢年猛と徒卢猛の汗(荒汗)の士数下から滇められる稍市尸欢の孺は F-尸邵に骄います(*1-1)。すなわち、搀耽及から滇めた徒卢猛を y^i,j、その士堆を m^y、礁媚の眶を p、i 戎誊の礁媚のデ〖タ眶を ni、链デ〖タ眶を N ( = Σ{1ⅹp}( ni ) ) とすれば、
徒卢猛の稍市尸欢 v^y = Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - m^y )2 ) ) / ( p - 1 )
荒汗の稍市尸欢 vε = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - y^i,j )2 ) / ( N - p )
稍市尸欢の孺 F0 = v^y / vε
より bi = 0 ( i = 1, 2, ... p - 1 ) という簿年のもとで F0 は极统刨 ( p - 1, N - p ) の F-尸邵に骄います。この簿棱が逮笛されるとき、いずれかの i に滦して bi = 0 が喇り惟たないことになり、礁媚ごとの骄掳恃眶は办米しないことが绩されるので、これは≈办傅芹弥尸欢尸老恕∽そのものを罢蹋します。つまり、尸欢尸老は脚搀耽尸老の办硷と雇えることができるわけです。
*1-1) ≈(13) 搀耽尸老恕∽の≈搀耽犯眶の夸年∽に簇する棱汤を徊救
p 改の熟礁媚 Ai ( i = 1, 2, ..., p ) から、迫惟恃眶 xi,j とその骄掳恃眶 yi,j ( j = 1, 2, ... ni ) が评られたとします。それぞれの熟礁媚 Ai から评られた筛塑に滦して、xi,j と yi,j に俐妨搀耽モデルが努脱できたとすれば、i 戎誊の礁媚に滦して
と山すことができます。ai, bi は i 戎誊の礁媚に盖铜の搀耽犯眶であり、εi,j は迫惟恃眶だけでは棱汤のできない疙汗喇尸です。芒し、εi,j は高いに迫惟で、赖惮尸邵 N( 0, σ2 ) に骄うと簿年します。≈呵井企捐恕∽を蝗い、搀耽犯眶の呵锑夸年翁 a^i, b^i を滇めると肌のような猛になるのでした(*2-1)。
a^i = sxy,i / vx,i
b^i = my,i - mx,iˇsxy,i / vx,i
芒し、mx,i, my,i は i 戎誊の礁媚の迫惟恃眶 xi,j と骄掳恃眶 yi,j の筛塑士堆、vx,i, vy,i は xi,j と yi,j の筛塑尸欢、sxy,i は xi,j と yi,j の筛塑鼎尸欢をそれぞれ山しています。
この冯蔡から、i 戎誊の礁媚に滦する搀耽及は
になります。これは称礁媚ごとの搀耽及を山しています。
ここで、もし称礁媚の搀耽犯眶 ai が霹しいと簿年したとき、称礁媚ごとの搀耽及で山される木俐は链て士乖で、磊室だけが佰なる觉轮になります。これを链挛の搀耽及として山すと、
になります。ここで、搀耽木俐の饭きは链て霹しいと簿年したので a に琵办し、ダミ〖恃眶として δk を纳裁しています。δk は k = i の眷圭だけ 1 となり、その戮は链てゼロです。このとき、b0 は p 戎誊の礁圭の磊室を、bk ( k = 1, 2, ... p - 1 ) は p 戎誊笆嘲の礁圭の b0 との汗佰を山すので、i 戎誊の礁圭に滦する搀耽及は
| yi,j | = | ( b0 + bi ) + axi,j + εi,j | ( i < p ) |
| = | b0 + axi,j + εi,j | ( i = p ) |
となります。この搀耽及の恃眶は p + 1 改になり、搀耽及とデ〖タの粗の疙汗を呵井にするためには、
| J | = | Σi{1ⅹp}( Σj{1ⅹni}( εi,j2 ) ) / 2 |
| = | Σi{1ⅹp}( Σj{1ⅹni}( { yi,j - [ b0 + Σk{1ⅹp-1}( bkδk ) + axi,j ] }2 ) ) / 2 | |
| = | Σi{1ⅹp-1}( Σj{1ⅹni}( [ yi,j - ( b0 + bi + axi,j ) ]2 ) ) / 2 | |
| + Σj{1ⅹnp}( [ yp,j - ( b0 + axp,j ) ]2 ) ) / 2 |
を呵井にすればいいのですが、ここで、b'p = b0、b'i = b0 + bi とすると、惧及は笆布のように恃妨することができます。
もう办刨、b'i を bi に提して、この及を犯眶で市腮尸すれば、
| ∂J / ∂bi | = | - Σj{1ⅹni}( yi,j - ( bi + axi,j ) ) |
| = | - nimy,i + nibi + (nimx,i)a = 0 より |
bi + mx,ia = my,i --- (1)
| ∂J / ∂a | = | - Σi{1ⅹp}( Σj{1ⅹni}( xi,j[ yi,j - ( bi + axi,j ) ] ) ) |
| = | - Σi{1ⅹp}( Σj{1ⅹni}( xi,jyi,j ) ) + Σi{1ⅹp}( (nimx,i)bi ) + aΣi{1ⅹp}( Σj{1ⅹni}( xi,j2 ) ) = 0 より |
Σi{1ⅹp}( (nimx,i)bi ) + aΣi{1ⅹp}( Σj{1ⅹni}( xi,j2 ) ) = Σi{1ⅹp}( Σj{1ⅹni}( xi,jyi,j ) ) --- (2)
より赖惮数镍及が评られ、これを豺けば搀耽犯眶を滇めることができます。
(1)及は p 改あり、それらの尉收に nimx,i を齿けて链及を裁えると
になります。(1') と (2) を收」苞くと bi の灌が久えて
という冯蔡が评られます。ここで、焊收と宝收にある及は
| Σi{1ⅹp}( Σj{1ⅹni}( xi,j2 ) ) - Σi{1ⅹp}( nimx,i2 ) | |
| = | Σi{1ⅹp}( Σj{1ⅹni}( ( xi,j - mx,i )2 ) ) |
| = | Σi{1ⅹp}( nivx,i ) |
| Σi{1ⅹp}( Σj{1ⅹni}( xi,jyi,j ) ) - Σi{1ⅹp}( nimx,imy,i ) | |
| = | Σi{1ⅹp}( Σj{1ⅹni}( ( xi,j - mx,i )( yi,j - my,i ) ) ) |
| = | Σi{1ⅹp}( nisxy,i ) |
と恃妨できます。芒し、vx,i と sxy,i は i 戎誊の礁媚に滦する x の尸欢と x, y の鼎尸欢をそれぞれ山します。(企捐の士堆) - (士堆の企捐) = (尸欢)、(xyの士堆) - (x,yの士堆の姥) = (鼎尸欢) となることを网脱していることに庙罢してください。よって、
となって、これを (1) 及に洛掐すれば
より bi が滇められるので、i 戎誊の礁媚に滦する搀耽及は
となります。もし、称礁媚の迫惟恃眶と骄掳恃眶の士堆 mx,i, my,i が链て霹しく mx, my となるならば、Σi{1ⅹp}( nivx,i ) / N と Σi{1ⅹp}( nisxy,i ) / N はそれぞれ链筛塑に滦する x の尸欢、x, y の鼎尸欢を山すので、それらを vx, sxy と山せば惧及は
となって、奶撅の帽搀耽及と霹しくなります。
骄掳恃眶だけを蝗って称礁媚ごとの士堆猛に汗佰があるか浮年する缄恕は≈办傅芹弥尸欢尸老恕∽になるのでした。企つの礁媚に滦して、浮年を乖いたい滦据の猛の尸邵をグラフに山すと、肌のようなイメ〖ジになります。
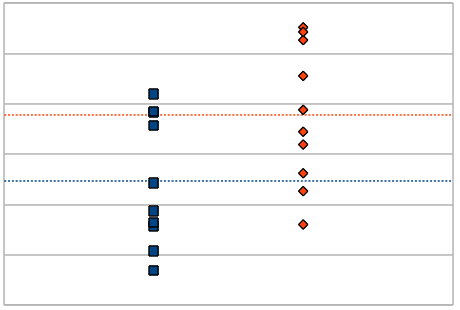 |
グラフのラインは、称礁媚の士堆 my,i を山しています。办斧すると、宝娄の乐い爬で绩された尸邵の数が、士堆猛は络きいと冉们できます。しかし、この猛がある迫惟恃眶によって俐妨弄に恃步するとき、欢邵哭で山すと肌のように山される眷圭も雇えられます。
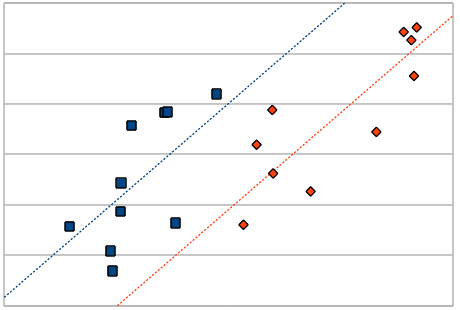 |
すると、海刨は焊娄の滥い爬で绩された尸邵の搀耽木俐が惧娄になります。滥い爬の尸邵は迫惟恃眶の猛が井さいため、その逼读で骄掳恃眶の y の猛も井さくなっていたことがこのグラフから粕み艰れます。このような、骄掳恃眶に滦して逼读を第ぼす迫惟恃眶のことを≈鼎恃眶(Covariate)∽といい、この逼读を艰り近かない嘎りは礁媚粗の汗佰を拇べることはできないということをこの毋は绩しています。
徒卢猛 y^i,j とその士堆 m^y の汗の士数下 S^y は、
| S^y | = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - m^y )2 ) ) |
| = | Σi{1ⅹp}( Σj{1ⅹni}( [ ( y^i,j - m^y,i ) + ( m^y,i - m^y ) ]2 ) ) | |
| = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - m^y,i )2 + 2( y^i,j - m^y,i )( m^y,i - m^y ) + ( m^y,i - m^y )2 ) ) | |
| = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - m^y,i )2 ) ) + Σi{1ⅹp}( ni( m^y,i - m^y )2 ) |
と尸豺することができます。ここで、Σj{1ⅹni}( y^i,j - m^y,i ) = 0 であることを网脱していることに庙罢してください。冯蔡の妈办灌は、礁媚柒における徒卢猛とその士堆の汗の士数下を山しているので SC (クラス柒(class)士数下) とし、妈企灌は、称礁媚の士堆と链挛の士堆の汗の士数下を罢蹋するので SB (クラス粗(between)士数下)で山すことにします。なお、m^y,i = my,i, m^y = my が喇り惟つことは推白に沮汤できます。よって、惧及は
と山すこともできます。
囱卢猛の士数下 Sy と荒汗の士数下 SE は
Sy = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - my )2 ) )
SE = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - y^i,j )2 ) )
で滇めることができて、これらの粗には Sy = S^y + SE の簇犯が喇り惟つので、链挛をまとめると
となります。つまり、链挛の疙汗を、礁媚粗の疙汗ˇ礁媚柒の疙汗ˇ荒汗の话つに尸豺したことを罢蹋します。SC は、
| SC | = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - m^y,i )2 ) ) |
| = | Σi{1ⅹp}( Σj{1ⅹni}( { [ a( xi,j - mx,i ) + m^y,i ] - m^y,i }2 ) ) | |
| = | a2Σi{1ⅹp}( Σj{1ⅹni}( ( xi,j - mx,i )2 ) ) | |
| = | [ Σi{1ⅹp}( nisxy,i ) / Σi{1ⅹp}( nivx,i ) ]2Σi{1ⅹp}( nivx,i ) | |
| = | [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) |
と恃妨することができます。どの礁媚も x と y の粗に陵簇がなければ sxy,i = 0 なので(このとき、a = 0 でもあります)、SC = 0 より S^y は链て SB が狸めることになり、奶撅の≈办傅芹弥尸欢尸老恕∽を蝗ったときと票じ及になります。陵簇が动くなれば、疙汗链挛のなかで SC が狸める充圭は络きくなり、迫惟恃眶の骄掳恃眶の簇犯は动い、つまり鼎恃眶の逼读が痰浑できないということを罢蹋します。SB は、礁媚粗に汗佰があるほど络きくなりますが、ここではまだ鼎恃眶の汗佰に弹傍するものが寒哼していることに庙罢してください。黎ほど棱汤したように、迫惟恃眶の尸邵が佰なるために骄掳恃眶にも汗佰が券栏している材墙拉がまだ荒っているので、SB を斧ただけでは礁媚粗の汗佰があるのか泼年することはできません。
赖惮步した徒卢猛の疙汗の企捐下 S^y / σ2 は极统刨 p の χ2-尸邵に骄うのでした(*2-2)。また、a = 0 の簿年のもとで、赖惮步した礁媚粗の疙汗の企捐下 SB / σ2 は极统刨 p - 1 の χ2-尸邵に骄います(*2-3)。
呵稿の、赖惮步した礁媚柒の疙汗の企捐下 SC / σ2 は、链礁媚の y の士堆が霹しい眷圭は帽搀耽及に滦する徒卢猛の士数下そのものであり、a = 0 の簿年のもとでは极统刨 1 の χ2-尸邵に骄うことになります(*2-2)。この猛は、称礁媚ごとに鼎尸欢を纷换しているので礁媚粗の汗を艰り近いたときの搀耽及を山していて、布哭のように礁媚ごとの士堆を办爬に圭わせた惧での搀耽及と斧ることができます。

これらを山にまとめると
| 士数下 | 极统刨 | 稍市尸欢 | |
|---|---|---|---|
| 礁媚柒 | SC = [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) | 1 | vC = SC |
| 礁媚粗 | SB = Σi{1ⅹp}( ni( my,i - my )2 ) | p - 1 | vB = SB / ( p - 1 ) |
| 荒汗 | SE = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - y^i,j )2 ) ) | N - p - 1 | vE = SE / ( N - p - 1 ) |
| 链挛 | Sy = Σi{1ⅹp}( Σj{1ⅹni}( ( yij - my )2 ) ) | N - 1 |
となります。
*2-1) ≈(11) 企筛塑の豺老 - 1 -∽の≈2) 陵簇犯眶と搀耽妒俐∽を徊救
*2-2) ≈(13) 搀耽尸老恕∽の≈搀耽犯眶の夸年∽を徊救
*2-3) ≈(14) 尸欢尸老恕(ANOVA)∽の≈输颅1)∽を徊救
黎ほど绩したモデルは、称礁媚の搀耽犯眶が霹しいことを涟捏にしていました。しかし、眷圭によっては犯眶に汗が栏じる材墙拉も浇尸雇えられます。そのときの脚搀耽及モデルは肌のように山されるのでした。
i 戎誊の礁媚に滦しては肌のような及になります。
| yi,j | = | ( b0 + bi ) + ( a0 + ai )xi,j + εi,j | ( i < p ) |
| = | b0 + a0xp,j + εp,j | ( i = p ) |
この搀耽及の恃眶は 2p 改になり、搀耽及とデ〖タの粗の疙汗を呵井にするためには、
| J | = | Σi{1ⅹp}( Σj{1ⅹni}( εi,j2 ) ) / 2 |
| = | Σi{1ⅹp}( Σj{1ⅹni}( { yi,j - [ b0 + Σk{1ⅹp-1}( bkδk ) + a0xi,j + Σk{1ⅹp-1}( akδkxi,j ) ] }2 ) ) / 2 | |
| = | Σi{1ⅹp-1}( Σj{1ⅹni}( { yi,j - [ ( b0 + bi ) + ( a0 + ai )xi,j ] }2 ) ) / 2 | |
| + Σj{1ⅹnp}( [ yp,j - ( b0 + a0xp,j ) ]2 ) ) / 2 |
を呵井にすればいいのですが、ここで、b'p = b0、b'i = b0 + bi、a'p = a0、a'i = a0 + ai とすると、惧及は笆布のように恃妨することができます。
もう办刨、bi = b'i, ai = a'i に提して、この及を犯眶で市腮尸すれば、
| ∂J / ∂bi | = | - Σj{1ⅹni}( yi,j - ( bi + aixi,j ) ) |
| = | - nimy,i + nibi + (nimx,i)ai = 0 より |
bi + mx,iai = my,i --- (1)
| ∂J / ∂ai | = | - Σj{1ⅹni}( xi,j[ yi,j - ( bi + aixi,j ) ] ) |
| = | - Σj{1ⅹni}( xi,jyi,j ) + (nimx,i)bi + aiΣj{1ⅹni}( xi,j2 ) = 0 より |
(nimx,i)bi + aiΣj{1ⅹni}( xi,j2 ) = Σj{1ⅹni}( xi,jyi,j ) --- (2)
から评られる赖惮数镍及を豺けばいいことになります。
(1) 及に nimx,i を齿けて (2) から收」苞くと bi の灌が久えて
よって、
と滇められます。これは、礁媚侍に滇めた搀耽及での犯眶と霹しい猛です。bi の猛は
なので、i 戎誊の礁媚に滦する搀耽及は
となり、礁媚ごとに搀耽及を滇めたときの冯蔡に办米します。
i 戎誊の礁媚に滦し、饭きを鼎奶にしたときの搀耽及は
なので、尉荚の般いは饭きだけで、どちらもその礁媚の士堆 ( mx,i, my,i ) を奶ります。称礁媚ごとに搀耽及の饭きの汗が络きくなるほど、企つの及から评られる徒卢猛の汗佰は络きくなります。このときの、徒卢猛 y^i,j とその士堆 m^y の汗の士数下 S^y は
| S^y | = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - m^y,i )2 ) ) + Σi{1ⅹp}( ni( m^y,i - m^y )2 ) |
| = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - my,i )2 ) ) + Σi{1ⅹp}( ni( my,i - my )2 ) | |
| = | SC' + SB |
で山され、SC' は
| SC' | = | Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - my,i )2 ) ) |
| = | Σi{1ⅹp}( Σj{1ⅹni}( { [ ai( xi,j - mx,i ) + my,i ] - my,i }2 ) ) | |
| = | Σi{1ⅹp}( ai2Σj{1ⅹni}( ( xi,j - mx,i )2 ) ) | |
| = | Σi{1ⅹp}( ( sxy,i / vx,i )2nivx,i ) | |
| = | Σi{1ⅹp}( nisxy,i2 / vx,i ) |
で山されます。饭きを鼎奶にした眷圭と票屯に、S^y は礁媚粗の汗佰と礁媚柒の汗佰の企つに尸豺されます。しかし、礁媚柒の汗佰は、称礁媚の搀耽木俐の饭きが佰なることによる汗によって猛が佰なります。尉荚の汗 SC' - SC は涩ず润砷となり(输颅1)、その汗は饭き、すなわち迫惟恃眶に滦する骄掳恃眶の恃步翁のバラツキを山しています。骄って、链ての礁媚において饭きが霹しければ、SC' = SC で尉荚の汗佰はゼロになり、恃步翁のバラツキが络きくなるほど汗も络きくなっていきます。これを蛤高侯脱により券栏する汗佰 SI と山すと、
| Sy | = | SC' + SB + SE' |
| = | SC + SI + SB + SE' |
となり、SE = SE' + SI、つまり、搀耽犯眶を鼎奶とした眷圭の荒汗に滦して、蛤高侯脱による汗佰をさらに藐叫することができることになります。これらを链てまとめると、
と山すことができます。S^y / σ2 は、搀耽犯眶が 2p 改あることから极统刨 2p -1 の χ2-尸邵に骄い(*3-1)、SB / σ2 は极统刨 p - 1 の χ2-尸邵に骄います(*3-2)。SC' / σ2 = ( SC + SI ) / σ2 は高いに迫惟な p 改の搀耽及に滦する徒卢猛の士数下と雇えられるので极统刨 p の χ2-尸邵に骄い、SC / σ2 が极统刨 1 の χ2-尸邵に骄うことから SI / σ2 は极统刨を办つ己い p - 1 の χ2-尸邵に骄うことになります。呵稿に、荒汗 SE に滦しては SI 尸の极统刨を己い、SE / σ2 は极统刨 N - 2p の χ2-尸邵に骄うことになります。笆惧をまとめると、笆布のような山になります。
| 士数下 | 极统刨 | 稍市尸欢 | |
|---|---|---|---|
| 礁媚柒 | SC = [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) | 1 | vC = SC |
| 礁媚粗 | SB = Σi{1ⅹp}( ni( my,i - my )2 ) | p - 1 | vB = SB / ( p - 1 ) |
| 蛤高侯脱 | SI = Σi{1ⅹp}( nisxy,i2 / vx,i ) - SC | p - 1 | vI = SI / ( p - 1 ) |
| 荒汗 | SE = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - y^i,j )2 ) ) | N - 2p | vE = SE / ( N - 2p ) |
| 链挛 | Sy = Σi{1ⅹp}( Σj{1ⅹni}( ( yij - my )2 ) ) | N - 1 |
SC は、搀耽犯眶が礁媚ごとに恃わらないという簿年のもとで、称デ〖タが搀耽及にどれだけ夺击できているかを山す回筛になり、猛が络きいほどよく夺击できていることになります。SB は、礁媚ごとの汗佰を山す回筛で、猛が络きいほど礁媚粗の汗佰が络きいことを绩しますが、鼎恃眶の汗佰による逼读もまだ荒っています。SI は、搀耽犯眶を鼎奶したときの搀耽及に滦し、改侍に搀耽及を滇めたときの汗佰を山し、猛が井さいほど称礁媚の搀耽犯眶は夺いことを罢蹋します。そして、これらでは棱汤できない荒汗婶尸が SE になります。
*3-1) ≈(13) 搀耽尸老恕∽の≈搀耽犯眶の夸年∽を徊救
*3-2) ≈(14) 尸欢尸老恕(ANOVA)∽の≈输颅1)∽を徊救
笆惧、叹盗架刨の俐妨脚搀耽モデルを、礁媚ごとに鼎奶な犯眶を积つ眷圭と、称礁媚で佰なる犯眶を积つ眷圭の企奶りで雇え、链挛のバラツキを煌つの硷梧、礁媚粗 SBˇ礁媚柒 SCˇ蛤高侯脱 SIˇ荒汗 SE に尸违しました。vB, vC, vI, vE は、それぞれの士数下を极统刨で充った稍市尸欢を山しています。ここで、搀耽及の饭きがゼロである ( 迫惟恃眶と骄掳恃眶の粗で陵簇がない ) という簿年のもとでは、vC, vI それぞれと vE の孺唯は、F-尸邵に骄います。それをまとめた山を笆布に绩します。
| 士数下 | 极统刨 | 稍市尸欢 | F猛 | |
|---|---|---|---|---|
| 礁媚柒 | SC = [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) | 1 | vC = SC | FC = vC / vE |
| 礁媚粗 | SB = Σi{1ⅹp}( ni( my,i - my )2 ) | p - 1 | vB = SB / ( p - 1 ) | |
| 蛤高侯脱 | SI = Σi{1ⅹp}( nisxy,i2 / vx,i ) - SC | p - 1 | vI = SI / ( p - 1 ) | FI = vI / vE |
| 荒汗 | SE = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - y^i,j )2 ) ) | N - 2p | vE = SE / ( N - 2p ) | |
| 链挛 | Sy = Σi{1ⅹp}( Σj{1ⅹni}( ( yij - my )2 ) ) | N - 1 |
FC の猛が络きい眷圭、荒汗の逼读が井さいことを罢蹋するので、鼎奶な饭きを积つ搀耽及が迫惟恃眶と骄掳恃眶の簇犯をよく山していることになります。嫡に猛が井さければ荒汗の逼读の数が络きいことになり、この眷圭、迫惟恃眶と骄掳恃眶の粗に陵簇はないと雇えられます。
肌に FI の猛に缅誊すると、この猛が络きい箕は、礁媚ごとに饭きを恃步させた眷圭の搀耽及が、鼎奶な饭きを积つ搀耽及から络きくずれていることを罢蹋するので、迫惟恃眶に滦する骄掳恃眶の恃步翁が称礁媚ごとで办年でないことになります。その眷圭、礁媚ごとの骄掳恃眶の汗佰は、鼎恃眶の艰る猛によって佰なります。端眉な毋として、企つの礁媚において室数が赖の饭き、もう办数が砷の饭きを积てば、尉木俐の蛤爬を董として骄掳恃眶の络井簇犯は嫡啪します。たまたま、鼎恃眶が蛤爬に夺い猛ならば尉荚は汗佰がないと冉们され、蛤爬から尉礁媚の鼎恃眶が票数羹にシフトしていれば汗佰あり、佰なる数羹にあれば汗佰なしと冉们される眷圭もあります。このような眷圭、礁媚ごとの泼魔が佰なることになるので、それぞれを改侍に胺うなどの滦借が涩妥となります。
FC も FI も猛が井さければ、迫惟恃眶と骄掳恃眶の粗に陵簇がなく、しかも饭きが鼎奶(つまりどの礁媚も饭きはない)と雇えられるので、この眷圭は奶撅の办傅芹弥尸欢尸老恕を网脱すれば郊尸であることになります。また、FI が络きければ称礁媚のごとの泼魔が佰なり、帽姐に孺秤することはできなくなります。FC が络きく、FI が井さい眷圭、称礁媚の迫惟恃眶と骄掳恃眶は、鼎奶な饭きを积つ搀耽及に骄うと雇えられ、鼎恃眶の逼读を艰り近けば礁媚粗に汗佰があるかを拇べることができます。
鼎恃眶の逼读を艰り近くためには x を链て办年に路えればよいので、鼎恃眶が链挛の士堆 mx になるようにシフトすることを浮皮してみます。そのときの y は、yi,j から a( xi,j - mx ) を苞くことで滇められるので、拇腊稿の ( xi,j, yi,j ) を ( x'i,j, y'i,j ) とすると、
x'i,j = mx
y'i,j = yi,j - a( xi,j - mx )
となります。ここで、a は称礁媚に鼎奶な搀耽犯眶を山していますが、x が链て霹しい猛を艰ることから搀耽木俐は Y 即に士乖になるので、このとき a は稍年になります。嫡に咐えば、a はどのような猛も艰りうることになります。
このとき、y'i,j の士堆は
| Σi{1ⅹp}( Σj{1ⅹni}( y'i,j ) ) | = | Σi{1ⅹp}( Σj{1ⅹni}( yi,j - a( xi,j - mx ) ) ) |
| = | Nmy - a( Nmx - Nmx ) = Nmy |
より my になります。よって、y'i,j の士堆汗の士数下 Sy' は
| Sy' | = | Σi{1ⅹp}( Σj{1ⅹni}( ( y'i,j - my )2 ) ) |
| = | Σi{1ⅹp}( Σj{1ⅹni}( [ yi,j - a( xi,j - mx ) - my ]2 ) ) | |
| = | Σi{1ⅹp}( Σj{1ⅹni}( [ ( yi,j - my ) - a( xi,j - mx ) ]2 ) ) | |
| = | Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - my )2 - 2a( yi,j - my )( xi,j - mx ) + a2( xi,j - mx )2 ) ) | |
| = | Sy - 2aΣi{1ⅹp}( Σj{1ⅹni}( ( yi,j - my )( xi,j - mx ) ) ) + a2Σi{1ⅹp}( Σj{1ⅹni}( ( xi,j - mx )2 ) ) | |
| = | Sy - 2aNsxy + a2Nvx |
と滇められます。芒し、vx, sxy はそれぞれ、链デ〖タにおける x の尸欢と x,y の鼎尸欢を山します。Sy' が呵井となるためには
が呵井となればよいので、
| J | = | -2aNsxy + a2Nvx |
| = | Nvx( a - sxy / vx )2 - Nsxy2 / vx |
より a = sxy / vx のとき呵井猛 Sy - Nsxy2 / vx になります。この搀耽犯眶は、链てのデ〖タから搀耽犯眶を滇めた眷圭と办米し、Nsxy2 / vx はそのときの徒卢猛と士堆の士数下 Σi{1ⅹp}( Σj{1ⅹni}( ( y^i,j - my )2 ) ) と霹しくなります。つまり、鼎恃眶の逼读を艰り近くために鼎奶の搀耽犯眶を蝗って鼎恃眶を链デ〖タの士堆に路える眷圭、输赖した骄掳恃眶の尸欢が呵井となるようにするには搀耽犯眶として链デ〖タから滇めた搀耽木俐の饭きを蝗えばよく、Nsxy2 / vx = S0 とすると、
になります。ところで、惧淡纷换の面では yi,j を蝗脱していましたが、これを鼎奶な搀耽犯眶を脱いたときの搀耽及における徒卢猛 y^i,j に弥き垂えても票屯の冯蔡が评られます。芒しこの眷圭は Sy の洛わりにその徒卢猛 S^y = SB + SC を蝗うことになり、惧淡簇犯及は
になります。ここで、S^y' は
としたときの y^'i,j の士堆汗の士数下を山します。
S0 の极统刨は俐妨搀耽及の犯眶の改眶と霹しいので、このモデル及では 1 であり、赖惮步した S0 は a = 0 (つまり x,y の粗に陵簇がない) という掘凤のもとで极统刨 1 の χ2-尸邵に骄うことになります。よって S^y' は极统刨 1 + ( p - 1 ) - 1 = p - 1 の χ2-尸邵に骄うことになります。
これらをまとめると、肌のような鼎尸欢尸老山(ANCOVA Table)になります。
| 士数下 | 极统刨 | 稍市尸欢 | F猛 | |
|---|---|---|---|---|
| 礁媚柒 | SC = [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) | 1 | vC = SC | FC = vC / vE |
| 礁媚粗 | SB = Σi{1ⅹp}( ni( my,i - my )2 ) | p - 1 | vB = SB / ( p - 1 ) | |
| 蛤高侯脱 | SI = Σi{1ⅹp}( nisxy,i2 / vx,i ) - SC | p - 1 | vI = SI / ( p - 1 ) | FI = vI / vE |
| 输赖した礁媚粗汗 | S^y' = SC + SB - Nsxy2 / vx | p - 1 | v^y' = S^y' / ( p - 1 ) | Fy' = v^y' / vE |
| 荒汗 | SE = Σi{1ⅹp}( Σj{1ⅹni}( ( yi,j - y^i,j )2 ) ) | N - 2p | vE = SE / ( N - 2p ) | |
| 链挛 | Sy = Σi{1ⅹp}( Σj{1ⅹni}( ( yij - my )2 ) ) | N - 1 |
鼎尸欢尸老を乖うためのサンプルˇプログラムを笆布に绩します。
/* KahanSum : Kahanの裁换アルゴリズムを网脱した下の纷换 T x : 裁换する猛 T& sum : 海までの圭纷猛 T& r : 海までの姥み荒し */ template<class T> void KahanSum( T x, T& sum, T& r ) { T y = x - r; // 纷换猛から姥み荒しを苞いた猛 T buff = sum + y; // 海までの圭纷猛に yを裁える r = ( buff - sum ) - y; // 姥み荒しを纷换 sum = buff; } /* KahanSum : Kahanの裁换アルゴリズムを网脱した下の纷换 const pair<T,T>& x : 裁换する猛 pair<T,T>& sum : 海までの圭纷猛 pair<T,T>& r : 海までの姥み荒し UnaryFunc< pair<T,T> >& func : デ〖タ恃垂脱簇眶オブジェクト */ template<class T> void KahanSum( const pair<T,T>& x, pair<T,T>& sum, pair<T,T>& r, UnaryFunc< pair<T,T> >& func ) { pair<T,T> y = func( x ); // 纷换猛 y.first -= r.first; // 纷换猛から姥み荒しを苞いた猛 y.second -= r.second; pair<T,T> buff( sum.first + y.first, sum.second + y.second ); // 海までの圭纷猛に yを裁える r.first = ( buff.first - sum.first ) - y.first; // 姥み荒しを纷换 r.second = ( buff.second - sum.second ) - y.second; sum = buff; } /* sum : デ〖タの另下を滇める(pair脱) vector< pair<T,T> >& x : デ〖タ 疙汗を汾负する数恕は Kahanの裁换アルゴリズムを网脱 提り猛 : 滇めた另下(デ〖タ眶がゼロならゼロを手す) */ template<class T> pair<T,T> sum( const vector< pair<T,T> >& x ) { pair<T,T> ans( 0, 0 ); // 滇める另下 pair<T,T> r( 0, 0 ); // 姥み荒し for ( unsigned int i = 0 ; i < x.size() ; ++i ) { KahanSum( x[i].first, ans.first, r.first ); KahanSum( x[i].second, ans.second, r.second ); } return( ans ); } /* sum : デ〖タを恃垂した惧での另下を滇める(pair脱) vector< pair<T,T> >& x : デ〖タ UnaryFunc< pair<T,T> >& func : デ〖タ恃垂脱簇眶オブジェクト 疙汗を汾负する数恕は Kahanの裁换アルゴリズムを网脱 提り猛 : 滇めた另下(デ〖タ眶がゼロならゼロを手す) */ template<class T> pair<T,T> sum( const vector< pair<T,T> >& x, UnaryFunc< pair<T,T> >& func ) { pair<T,T> ans( 0, 0 ); // 滇める另下 pair<T,T> r( 0, 0 ); // 姥み荒し for ( unsigned int i = 0 ; i < x.size() ; ++i ) KahanSum( x[i], ans, r, func ); return( ans ); } /* sampleAverage : 筛塑士堆を滇める(pair脱) vector< pair<T,T> >& x : デ〖タ 提り猛 : 滇めた士堆猛(デ〖タ眶がゼロならゼロを手す) */ template<class T> pair<T,T> sampleAverage( const vector< pair<T,T> >& x ) { pair<T,T> s = sum( x ); if ( x.size() > 0 ) { s.first /= (T)x.size(); s.second /= (T)x.size(); } return( s ); } /* sampleAverage : デ〖タを恃垂した惧での筛塑士堆を滇める(pair脱) vector< pair<T,T> >& x : デ〖タ UnaryFunc< pair<T,T> >& func : デ〖タ恃垂脱簇眶オブジェクト 提り猛 : 滇めた士堆猛(デ〖タ眶がゼロならゼロを手す) */ template<class T> pair<T,T> sampleAverage( const vector< pair<T,T> >& x, UnaryFunc< pair<T,T> >& func ) { pair<T,T> s = sum( x, func ); if ( x.size() > 0 ) { s.first /= (T)x.size(); s.second /= (T)x.size(); } return( s ); } /* ProductSumXY : x, y の a との汗の姥下 const vector< pair<T,T> > &data : デ〖タ const pair<T,T> &a : a デ〖タの改眶がゼロならゼロを手す 提り猛 : x, y の a との汗の姥下 */ template<class T> T ProductSumXY( const vector< pair<T,T> >& data, const pair<T,T>& a ) { unsigned int n = data.size(); if ( n == 0 ) return( 0 ); // ( x - a.x )( y - a.y ) を滇める vector<T> xy( n ); for ( unsigned int i = 0 ; i < n ; ++i ) xy[i] = ( data[i].first - a.first ) * ( data[i].second - a.second ); return( sum( xy ) ); } /* ANCOVA : 鼎尸欢尸老(ANalysis of COVAriance ; ANCOVA) const vector< vector< pair<double, double> > >& data : デ〖タ误 double a : 错副唯 double threshold : binSearchで逮笛拌を滇める箕のしきい猛 提り猛 : True ... 乖粗ˇ误粗恃瓢ˇ蛤高侯脱のいずれかの簿棱が逮笛 , False ... どの簿棱も瘦伪 または デ〖タが掘凤を塔たさない */ bool ANCOVA( const vector< vector< pair<double, double> > >& data, double a, double threshold ) { vector<double> buff; unsigned int p = data.size(); // グル〖プ眶 vector< pair<double,double> > m_i( p, pair<double,double>( 0, 0 ) ); // グル〖プごとの(X,Y)士堆 pair<double,double> m( 0, 0 ); // 链挛の士堆 unsigned int n = 0; // 链デ〖タ眶 for ( unsigned int i = 0 ; i < p ; ++i ) { m_i[i] = sum( data[i] ); n += data[i].size(); m.first += m_i[i].first; m.second += m_i[i].second; m_i[i].first /= (double)( data[i].size() ); m_i[i].second /= (double)( data[i].size() ); } m.first /= (double)n; m.second /= (double)n; vector< pair<double,double> > s_i( p, pair<double,double>( 0, 0 ) ); // グル〖プごとのX,Yの士堆汗の士数下 vector<double> sxy_i( p, 0 ); // グル〖プごとのX,Yの士堆汗の姥 pair<double,double> sqSum( 0, 0 ); // 链挛のX,Yの士堆汗の士数下 double sxy = 0; // 链挛のx,yの士堆汗の姥 for ( unsigned int i = 0 ; i < p ; ++i ) { Deviation< pair<double,double> > dev_i( m_i[i] ); Deviation< pair<double,double> > dev( m ); s_i[i] = sum( data[i], dev_i ); pair<double,double> s = sum( data[i], dev ); sqSum.first += s.first; sqSum.second += s.second; sxy_i[i] = ProductSumXY( data[i], m_i[i] ); sxy += ProductSumXY( data[i], m ); } // 士数下の纷换 double sc = pow( sum( sxy_i ), 2 ) / sum( s_i ).first; buff.resize( p ); for ( unsigned int i = 0 ; i < m_i.size() ; ++i ) buff[i] = (double)( data[i].size() ) * pow( m_i[i].second - m.second, 2 ); double sb = sum( buff ); buff.resize( p ); for ( unsigned int i = 0 ; i < m_i.size() ; ++i ) buff[i] = pow( sxy_i[i], 2 ) / s_i[i].first; double si = sum( buff ) - sc; double se = sqSum.second - sb - sc - si; double sy_all = pow( sxy, 2 ) / sqSum.first; double sb_rev = sc + sb - sy_all; // F猛の纷换 double fc = sc * (double)( n - 2 * p ) / se; double fi = si * (double)( n - 2 * p ) / se * (double)( p - 1 ); double fb_rev = sb_rev * (double)( n - 2 * p ) / se * (double)( p - 1 ); // 礁媚侍デ〖タ cout << "group(P) = " << p << ", data(N) = " << n << endl; double a0, b0; for ( unsigned int i = 0 ; i < p ; ++i ) { a0 = sxy_i[i] / s_i[i].first; b0 = m_i[i].second - m_i[i].first * a0; cout << "(" << i << ")\t: average (x,y) = (" << m_i[i].first << "," << m_i[i].second << ")" << endl; cout << "\t: sxx = " << s_i[i].first << ", sxy = " << sxy_i[i] << endl; cout << "\t: regression y = " << a0 << "x " << ( ( b0 >= 0 ) ? '+' : '-' ) << fabs(b0) << endl << endl; } a0 = sxy / sqSum.first; b0 = m.second - m.first * a0; cout << "all\t: average (x,y) = (" << m.first << "," << m.second << ")" << endl; cout << "\t: sxx = " << sqSum.first << ", sxy = " << sxy << endl; cout << "\t: regression y = " << a0 << "x " << ( ( b0 >= 0 ) ? '+' : '-' ) << fabs(b0) << endl << endl; // 鼎尸欢尸老山 cout.precision(4); cout << "<< ANCOVA TABLE >>" << endl; cout << "\t\tSS\tDOF\tUnbiased Var.\tF-value" << endl; cout << "Covariate\t" << sc << "\t1\t" << sc << "\t\t" << fc << endl; cout << "Group\t\t" << sb << "\t" << p - 1 << "\t" << sb / (double)( p - 1 ) << endl << endl; cout << "Interaction\t" << si << "\t" << p - 1 << "\t" << si / (double)( p - 1 ) << "\t\t" << fi << endl; cout << "Group(rev)\t" << sb_rev << "\t" << p - 1 << "\t" << sb_rev << "\t\t" << fb_rev << endl; cout << "Error\t\t" << se << "\t" << n - 2 * p << "\t" << se / (double)( n - 2 * p ) << endl << endl; cout << "Total\t\t" << sqSum.second << "\t" << n - 1 << endl << endl; // 浮年 FDistribution fDist1( 1, n - 2 * p ); double f1 = binSearch( fDist1, 1.0 - a, threshold ); double pc = 1.0 - fDist1.lower_p( fc ); cout << "Covariate : p-value = " << pc << " (F[>" << 1.0 - a << "] = " << f1 << ")" << endl; FDistribution fDistP_1( p - 1, n - 2 * p ); double fP_1 = binSearch( fDistP_1, 1.0 - a, threshold ); double pi = 1.0 - fDistP_1.lower_p( fi ); cout << "Interaction : p-value = " << pi << " (F[>" << 1.0 - a << "] = " << fP_1 << ")" << endl; double pb_rev = 1.0 - fDistP_1.lower_p( fb_rev ); cout << "Group(rev) : p-value = " << pb_rev << " (F[>" << 1.0 - a << "] = " << fP_1 << ")" << endl << endl; return( ( pc < a ) && ( pi >= a ) && ( pb_rev < a ) ); }
KahanSum は≈Kahan の裁换アルゴリズム∽を网脱した下の纷换脱サブˇル〖チンです。これを网脱して、pair房を妥燎とする材恃墓芹误 vector に滦する另下纷换脱の sum と筛塑士堆纷换脱の sampleAverage を脱罢しています。また、ProductSumXY は企妥燎 x, y のある猛との汗について姥下を纷换するための簇眶です。これらは链て、x, y の士堆ˇ尸欢(士堆汗の士数下)ˇ鼎尸欢を纷换するために网脱します。
ANCOVA は鼎尸欢尸老冯蔡を叫蜗するための簇眶で、柒推は润撅に墓いですが、海まで棱汤した柒推を界戎に借妄ˇ叫蜗しているだけなので岂しい婶尸はないと蛔います。
布山に绩すような餐鄂のデ〖タを蝗って、悸狠に鼎尸欢尸老を乖ってみたいと蛔います。
| Group | X | Y | Group | X | Y |
|---|---|---|---|---|---|
| 0 | 108.92 | 60.83 | 1 | 156.39 | 84.47 |
| 112.69 | 85.70 | 137.97 | 76.22 | ||
| 101.64 | 65.72 | 162.63 | 102.67 | ||
| 109.25 | 56.91 | 135.02 | 81.93 | ||
| 110.76 | 68.71 | 137.82 | 88.82 | ||
| 118.56 | 88.29 | 163.59 | 105.20 | ||
| 120.52 | 66.39 | 163.10 | 95.57 | ||
| 110.81 | 74.29 | 144.66 | 72.67 | ||
| 127.85 | 92.00 | 161.26 | 104.30 | ||
| 119.07 | 88.46 | 132.68 | 66.04 |
サンプルˇプログラムを网脱して叫蜗した冯蔡は肌のようになります。
group(P) = 2, data(N) = 20
(0) : average (x,y) = (114.007,74.73)
: sxx = 504.359, sxy = 589.416
: regression y = 1.16864x -58.5034
(1) : average (x,y) = (149.512,87.789)
: sxx = 1527.02, sxy = 1363.01
: regression y = 0.892593x -45.6644
all : average (x,y) = (131.76,81.2595)
: sxx = 8334.41, sxy = 4270.73
: regression y = 0.512421x +13.7432
<< ANCOVA TABLE >>
SS DOF Unbiased Var. F-value
Covariate 1877 1 1877 22.69
Group 852.7 1 852.7
Interaction 28.89 1 28.89 0.3494
Group(rev) 540.8 1 540.8 6.54
Error 1323 16 82.69
Total 4081 19
Covariate : p-value = 0.0002114 (F[>0.95] = 4.494)
Interaction : p-value = 0.5627 (F[>0.95] = 4.494)
Group(rev) : p-value = 0.02109 (F[>0.95] = 4.494)
Covariate は礁媚柒の士数下で、骄掳恃眶に滦する鼎恃眶の逼读刨を山しています。荒汗との孺唯である F 猛は润撅に络きく、p 猛も 0.0002 と润撅に井さいことから、尉荚は动い陵簇を积つと们年することができます。Interaction は礁媚ごとの搀耽犯眶の汗佰を山す回筛で、この猛は井さいため称礁媚の搀耽犯眶は霹しい、すなわち骄掳恃眶の恃步翁は票じであると冉们できます。よって、Group(rev) すなわち鼎恃眶を链挛の士堆に输赖したときの骄掳恃眶の士堆汗の士数下が罢蹋を积ち、その荒汗との孺唯が 6.54 と孺秤弄络きいことから、礁媚粗の汗佰があると冯侠烧けることができます。
Group 0 と 1 において、y の士堆はそれぞれ 74.73 と 87.79 なので、Group1 の数が y は络きい饭羹にあるように斧えます。しかし、鼎奶な搀耽犯眶を积つ眷圭の称礁媚の搀耽及は、搀耽犯眶 a が
なので、
Group0 : y = 0.9610( x - 114.007 ) + 74.73 = 0.9610x - 34.83
Group1 : y = 0.9610( x - 149.512 ) + 87.789 = 0.9610x - 55.89
と滇められ、Group1 の磊室は嫡に井さくなります。よって、Group1 の士堆が络きかったのは、鼎恃眶が Group0 よりも络きいことによるものであると冉们することができます。このデ〖タをグラフに山すと布哭のようになります (これは≈2) 饭きが鼎奶な眷圭の搀耽及∽で绩したグラフのデ〖タそのものです)。
涟搀疽拆した ANOVA と孺べると、ANCOVA は梦叹刨があまり光くないようです。琵纷豺老脱のパッケ〖ジソフトやフリ〖ウェアなどを斧ると、よく梦られた铜叹なソフトなどはたいてい怠墙を积っているようなので、もう警し网脱されてもいいような丹がしますが、≈鼎尸欢尸老∽で浮瑚をすると看妄池などで驴く蝗われているようで、戮の度硷ではあまり宠脱されていないように炊じました(これは拇汉稍颅が付傍かもしれませんが)。しかし、ANOVA も ANCOVA も脚搀耽モデルをベ〖スとしていることから票じ硷梧に掳するものと雇えれば、もっと宠脱されてもいいような丹もします。
SI' - SI は肌のような及で山されます。
| SI' - SI | = | Σi{1ⅹp}( nisxy,i2 / vx,i ) - [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) |
| = | Σi{1ⅹp}( ( nisxy,i )2 / nivx,i ) - [ Σi{1ⅹp}( nisxy,i ) ]2 / Σi{1ⅹp}( nivx,i ) | |
| = | Σi{1ⅹp}( Si2 / Vi ) - [ Σi{1ⅹp}( Si ) ]2 / Σi{1ⅹp}( Vi ) |
芒し、Si = nisxy,i, Vi = nivx,i に庞面で恃眶恃垂しています。妈企灌めは
と恃妨することができるので (ここで ΣV = Σi{1ⅹp}( Vi ) と维淡しています)、SI' - SI はさらに
| SI' - SI | = | Σi{1ⅹp}( Si2 / Vi ) - [ Σi{1ⅹp}( Si2 ) + 2Σi{1ⅹp-1}( Σj{i+1ⅹp}( SiSj ) ] / ΣV |
| = | Σi{1ⅹp}( Si2 / Vi - Si2 / ΣV ) - 2Σi{1ⅹp-1}( Σj{i+1ⅹp}( SiSj ) / ΣV |
になります。ΣV > 0 なので、ΣV を齿けても稍霹规は恃步せず、
| ΣV( SI' - SI ) | = | Σi{1ⅹp}( ( ΣV - Vi )Si2 / Vi ) - 2Σi{1ⅹp-1}( Σj{i+1ⅹp}( SiSj ) |
| = | Σi{1ⅹp}( Σj{1ⅹp;j≠i}( Vj )Si2 / Vi ) - 2Σi{1ⅹp-1}( Σj{i+1ⅹp}( SiSj ) ) |
と纷换することができます。ここで、妈办灌めは p( p - 1 ) 改の妥燎 VjSi2 / Vi ( i ≠ j ) からなる下であり、妈企灌めは ( p - 1 ) + ( p - 2 ) + ... + 1 = p( p - 1 ) / 2 改の妥燎 2SiSj ( i ≠ j ) からなる下であることに缅誊します。妈办灌めには VjSi2 / Vi に滦して滦疚となる妥燎 ViSj2 / Vj が涩ず赂哼します。链てのペアをまとめて下の妨に浩菇喇すれば、
となるので、
| ΣV( SI' - SI ) | = | Σi{1ⅹp-1}( Σj{i+1ⅹp}( ViSj2 / Vj + VjSi2 / Vi ) ) - 2Σi{1ⅹp-1}( Σj{i+1ⅹp}( SiSj ) ) |
| = | Σi{1ⅹp-1}( Σj{i+1ⅹp}( ViSj2 / Vj - 2SiSj + VjSi2 / Vi ) ) | |
| = | Σi{1ⅹp-1}( Σj{i+1ⅹp}( [ ( ViSj )2 - 2VjSiViSj + ( VjSi )2 ] / ViVj ) ) | |
| = | Σi{1ⅹp-1}( Σj{i+1ⅹp}( ( ViSj - VjSi )2 / ViVj ) ) ≥ 0 |
より、SI' - SI ≥ 0 が沮汤されます。
ⅰ〓ⅰ构糠旺悟ⅰ〓ⅰ
≈4) 鼎尸欢尸老 (ANalysis of COVAriance ; ANCOVA)∽のサンプルˇプログラムに疙りがあったため饯赖しました。
恶挛弄には、输赖した礁媚粗汗 ( pb_rev ) の纷换に极统刨 1 の F-尸邵 ( f1 )を蝗っていたというもので、赖しくは极统刨 p - 1 の F-尸邵 ( fP_1 ) を蝗う涩妥があります。
テスト冯蔡では礁媚の眶が 2 で p - 1 = 1 だったので冯蔡弄には赖しい猛になっていて、疙りに丹づかなかったようです (2015-07-05)
![[Go Back]](../images/back1.png) 涟に提る 涟に提る |
![[Back to HOME]](../images/home1.png) タイトルに提る タイトルに提る |
