| 年齢層 | 喫煙者 | 非喫煙者 | ||
|---|---|---|---|---|
| 死亡者数 | 総数 | 死亡者数 | 総数 | |
| 35〜44 | 32 | 52407 | 2 | 18790 |
| 45〜54 | 104 | 43248 | 12 | 10673 |
| 55〜64 | 206 | 28612 | 28 | 5710 |
| 65〜74 | 186 | 12663 | 28 | 2585 |
| 75〜84 | 102 | 5317 | 31 | 1462 |
ある事象が発生した回数を記録したデータは非常に多く見かけられ、活用されています。例えば、台風や大雨、地震といった災害の年間発生回数や、店舗にてある商品が一日に売れる個数、ガンなどの病気による年間死亡者数などがそれに該当します。このようなデータは「計数データ (Count Data)」または「度数データ (Frequency Data)」と呼ばれ、季節や月単位といった期間や、商品別・性別・喫煙の有無等の事象によってヒストグラムなどのグラフを使って傾向を観察することはよく行われる推定方法です。一般化線形モデルで計数データを扱う場合は、「ポアソン回帰 (Poisson Regression)」や「対数線形モデル (Log-linear Model)」がよく利用されます。この章では、これらのモデルを「分散分析」と比較しながら紹介したいと思います。
「一元配置分散分析法 (One-way ANalysis Of VAriance ; One-way ANOVA)」は、各事象を表す「ダミー変数 (Dummy Variable ; Indicator Variable)」を独立変数とした「線形重回帰モデル式 (Linear Multiple Regression Model)」として表せることを以前紹介しました (*1-1)。また、線形重回帰モデルは「一般化線形モデル (Generalized Linear Model)」に対して正規分布を「指数型分布族 (Exponential Family of Distributions)」とした場合に相当するので、分散分析法も一般化線形モデルの一つであるということになります。ここで、分散分析法と一般化線形モデルの関係について整理しておきます。
以前は、一元配置分散分析法を表す線形重回帰式として以下のものを示しました。
ここで、j は事象に対する番号で、その総数は p になります。また、i は各事象が持つ従属変数に対する番号であり、ここではその数を nj で表します。αj は回帰係数、δj は各事象に対応したダミー変数で、j 番目の事象に属する場合だけ 1 で、その他は 0 になります。よって yi,J に対応する ( j = J のときの ) 式は
となります。但し、j = p の場合は該当するダミー変数がないことから、回帰式は
になります。これは、α0 が基準となって、1 から p - 1 までの事象との差異が αj で表されると考えると理解しやすいと思います。
最後に、yi,j が従属変数、εi,j が誤差成分で、εi,j は正規分布 N( 0, σ2 ) に従うと仮定します。この誤差成分は、事象によらずバラツキが一定であると考えるわけです。
この式は、各事象に対して nj 個存在するので、全事象での式の総数を N とすると、この値は
で求められます。この式を、事象ごとの式がまとめるように順に並べてみると
| y1,1 | = | α0 | + | α1 | + | ε1,1 | ||||||
| y2,1 | = | α0 | + | α1 | + | ε2,1 | ||||||
| : | ||||||||||||
| yn1,1 | = | α0 | + | α1 | + | εn1,1 | ||||||
| y1,2 | = | α0 | + | α2 | + | ε1,2 | ||||||
| : | ||||||||||||
| yi,j | = | α0 | + | αj | + | εi,j | ||||||
| : | ||||||||||||
| ynp-1,p-1 | = | α0 | + | αp-1 | + | εnp-1,p-1 | ||||||
| : | ||||||||||||
| ynp,p | = | α0 | + | εnp,p | ||||||||
となります。ここで、全成分が 1 からなる n 次元ベクトルを 1n、全成分が 0 からなる n 次元ベクトルを 0n で表して
| X | = | | | 1n1, | 1n1, | 0n1, | ... | 0n1 | | |
| | | 1n2, | 0n2, | 1n2, | ... | 0n2 | | | ||
| | | : | : | : | ... | : | | | ||
| | | 1np-1, | 0np-1, | 0np-1, | ... | 1np-1 | | | ||
| | | 1np, | 0np, | 0np, | ... | 0np | | | ||
| α | = | | | α0 | | |
| | | α1 | | | ||
| | | : | | | ||
| | | αp-1 | | | ||
とし、y を、左辺を並べた N 次元ベクトル、ε を、誤差成分を並べた N 次元ベクトルとすれば、先ほど示した式は
となります。これが一元配置分散分析法における線形重回帰モデル式で、X は「デザイン行列 (Design Matrix)」を意味します。a を α の最尤推定量としたとき、線形重回帰モデル式の正規方程式は
となるのでした (*1-2)。XTX は
| XTX | = | | | 1n1T, | 1n2T, | ... | 1np-1T, | 1npT | || | 1n1, | 1n1, | 0n1, | ... | 0n1 | | |
| | | 1n1T, | 0n2T, | ... | 0np-1T, | 0npT | || | 1n2, | 0n2, | 1n2, | ... | 0n2 | | | ||
| | | 0n1T, | 1n2T, | ... | 0np-1T, | 0npT | || | : | : | : | ... | : | | | ||
| | | : | : | ... | : | : | || | 1np-1, | 0np-1, | 0np-1, | ... | 1np-1 | | | ||
| | | 0n1T, | 0n2T, | ... | 1np-1T, | 0npT | || | 1np, | 0np, | 0np, | ... | 0np | | | ||
| = | | | N, | n1, | n2, | ... | np-1 | | | |||||||
| | | n1, | n1, | 0, | ... | 0 | | | ||||||||
| | | n2, | 0, | n2, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | | | ||||||||
| | | np-2, | 0, | 0, | ... | 0 | | | ||||||||
| | | np-1, | 0, | 0, | ... | np-1 | | | ||||||||
で、XTy は yj = ( y1,j, y2,j ... ynj,j )T としたとき
| XTy | = | | | 1n1T, | 1n2T, | ... | 1np-1T, | 1npT | || | y1 | | |
| | | 1n1T, | 0n2T, | ... | 0np-1T, | 0npT | || | y2 | | | ||
| | | 0n1T, | 1n2T, | ... | 0np-1T, | 0npT | || | : | | | ||
| | | : | : | ... | : | : | || | yp-1 | | | ||
| | | 0n1T, | 0n2T, | ... | 1np-1T, | 0npT | || | yp | | | ||
| = | | | Sy | | | |||||||
| | | S1 | | | ||||||||
| | | S2 | | | ||||||||
| | | : | | | ||||||||
| | | Sp-1 | | | ||||||||
となります。但し Sj は事象 j に対する従属変数の和 Σi{1→nj}( yi,j )、Sy は全従属変数の和 Σj{1→p}( Sj ) をそれぞれ表します。簡単な考察から、XTX の逆行列 ( XTX )-1 は
| ( XTX )-1 | = | | | 1 / np, | -1 / np, | -1 / np, | ... | -1 / np | | |
| | | -1 / np, | ( n1 + np ) / n1np, | 1 / np, | ... | 1 / np | | | ||
| | | : | : | : | ... | : | | | ||
| | | -1 / np, | 1 / np, | 1 / np, | ... | ( np-1 + np ) / np-1np | | | ||
と求められるので (補足 1)、a は
| a = | ( XTX )-1XTy | ||||||||||||||||||||||||||||||||||||
| = |
| ||||||||||||||||||||||||||||||||||||
| = |
| ||||||||||||||||||||||||||||||||||||
| = |
|
となります。但し、mj は事象 j に対する従属変数の平均を表します。
線形重回帰モデルにおける飽和モデルとの対数尤度統計量 D は
となることから (*1-3)、一元配置分散分析の場合は
| D | = | { Σj{1→p-1}( Σi{1→nj}( [ yi,j - ( a0 + aj ) ]2 ) ) + Σi{1→np}( ( yi,p - a0 )2 ) } / σ2 |
| = | { Σj{1→p-1}( Σi{1→nj}( [ yi,j - ( mp + mj - mp ) ]2 ) ) + Σi{1→np}( ( yi,p - mp )2 ) } / σ2 | |
| = | Σj{1→p}( Σi{1→nj}( ( yi,j - mj )2 ) ) / σ2 |
という結果が得られます。これは、一元配置分散分析において集団内の平方和 SE を求める式に相当し、自由度 N - p の χ2-分布に「正確に」従います。
回帰係数を一つとし、yi,j = α0 + εi,j である場合を考えると、線形重回帰モデルの場合における飽和モデルとの対数尤度統計量 D0 は
となるのでした (*1-3)。但し、my は全従属変数の平均 Sy / N を表します。一元配置分散分析の場合、これが全体の平方和 ST を意味し、D0 - D が集団間の平方和 SC になります。D0 は自由度 N - 1 の χ2-分布に従うので、D0 - D は自由度 p - 1 の χ2-分布に従うことになり、
は自由度 ( p - 1, N - p ) の F-分布に従うことになります。この値 F を使って検定を行うのが一元配置分散分析でした (*1-4)。
一元配置分散分析における重回帰線形モデル式は、以下のモデル式
において αp = 0 とした場合に相当します。上記の式をそのまま y = Xα + ε の形にすると、
| X | = | | | 1n1, | 1n1, | 0n1, | ... | 0n1, | 0n1 | | |
| | | 1n2, | 0n2, | 1n2, | ... | 0n2, | 0n2 | | | ||
| | | : | : | : | ... | : | : | | | ||
| | | 1np-1, | 0np-1, | 0np-1, | ... | 1np-1, | 0np-1 | | | ||
| | | 1np, | 0np, | 0np, | ... | 0np | 1np | | | ||
| α | = | | | α0 | | |
| | | α1 | | | ||
| | | : | | | ||
| | | αp-1 | | | ||
| | | αp | | | ||
となって、X の列数と α の次元数は p + 1 となります。XTX は
| XTX | = | | | N, | n1, | n2, | ... | np | | |
| | | n1, | n1, | 0, | ... | 0 | | | ||
| | | n2, | 0, | n2, | ... | 0 | | | ||
| | | : | : | : | ... | : | | | ||
| | | np-1, | 0, | 0, | ... | 0 | | | ||
| | | np, | 0, | 0, | ... | np | | | ||
と計算できますが、第一列 ( または第一行 ) は他の列(行)の和に等しいことから線形従属な列(行)ベクトルが存在することになって、XTX は特異行列であることになります。このままでは正規方程式 XTXa = XTy の解が一意に決まりません。そのため、αp = 0 として ( α0 の中に含めることで ) 非特異な行列になるようにしていたわけです。これは「端点制約 (Corner-point Constraint)」と呼ばれます。
XTXa = XTyを連立方程式の形で書き直すと以下のようになります。
| Na0 + n1a1 + n2a2 + ... + npap | = | Sy |
| n1a0 + n1a1 | = | S1 |
| n2a0 + n2a2 | = | S2 |
| : | : | |
| npa0 + npap | = | Sp |
このままでは解は一意に決まらないので、n1a1 + n2a2 + ... + npap = Σj{1→p}( njaj ) = Sy - Nt とすれば、一番目の式から
Na0 + Sy - Nt = Sy より
a0 = t
となるので、
となり、a0 = t = Sy / N = my のとき、最初に仮定した式から Σj{1→p}( njaj ) = Sy - Nt = 0 で
という結果が得られます。この結果を使って飽和モデルとの対数尤度統計量 D を求めると
| D | = | Σi{1→N}( ( yi - xiTa )2 ) / σ2 |
| = | Σj{1→p}( Σi{1→nj}( [ yi,j - ( a0 + aj ) ]2 ) ) / σ2 | |
| = | Σj{1→p}( Σi{1→nj}( ( yi,j - mj )2 ) ) / σ2 |
となって、端点制約を用いた結果と等しくなります。これは「零和制約 (Sum-to-zero Constraint)」と呼ばれる手法になります。
次に、以下のような線形重回帰モデル式について検討してみます。
μ は従属変数全体の基準値で、αj はある事象 (これを A とします) ごとの基準との差異を、また βk は他の事象 (これを B とします) ごとの基準との差異をそれぞれ表し、最後の γj,k は事象 A, B の組み合わせによって生じる差異を表します。αj, βk は事象 A, B それぞれの「主効果 (Main Effect)」、γj,k は事象 A, B の「交互作用効果 (Interaction Effect)」と呼ばれます。添字の i は、事象 ( A, B ) の組み合わせごとの変数に付けられる連番であり、各変数の個数は全て等しく n であるとします。事象 A, B の数をそれぞれ p, q としたとき、連立方程式は
| y1,1,1 | = | μ | + | α1 | + | β1 | + | γ1,1 |
| y2,1,1 | = | μ | + | α1 | + | β1 | + | γ1,1 |
| : | ||||||||
| yn,1,1 | = | μ | + | α1 | + | β1 | + | γ1,1 |
| y1,2,1 | = | μ | + | α2 | + | β1 | + | γ2,1 |
| : | ||||||||
| yn,p,1 | = | μ | + | αp | + | β1 | + | γp,1 |
| y1,1,2 | = | μ | + | α1 | + | β2 | + | γ1,2 |
| : | ||||||||
| yi,j,k | = | μ | + | αj | + | βk | + | γj,k |
| : | ||||||||
| yn,p,q | = | μ | + | αp | + | βq | + | γp,q |
となって、全部で npq 個の式が得られます。しかし、事象 A, B の組み合わせが等しい従属変数に対する式は等しく、独立した式は高々 pq 個しかありません。それに対して求めるべき未知数は、μ と、αj が p 個、βk が q 個、γj,k が pq 個で合わせて pq + p + q + 1 = ( p + 1 )( q + 1 ) 個あるので、ここでも零和制約や端点制約を使って一意の解にする必要があります。
まず、連立方程式を y = Xα で表すと
| <μ> | < | αj (p列) | > | < | βk (q列) | > | < | γj,1 (p列) | > | < | γj,2 (p列) | > | ... | < | γj,q (p列) | > | | | |||||||||
| X | = | | | 1n, | 1n, | 0n, | ... | 0n, | 1n, | 0n, | ... | 0n, | 1n, | 0n, | ... | 0n, | 0n, | 0n, | ... | 0n, | ... | 0n, | 0n, | ... | 0n | | | ^ |
| | | 1n, | 0n, | 1n, | ... | 0n, | 1n, | 0n, | ... | 0n, | 0n, | 1n, | ... | 0n, | 0n, | 0n, | ... | 0n, | ... | 0n, | 0n, | ... | 0n | | | ( np 行 ) | ||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | |||
| | | 1n, | 0n, | 0n, | ... | 1n, | 1n, | 0n, | ... | 0n, | 0n, | 0n, | ... | 1n, | 0n, | 0n, | ... | 0n, | ... | 0n, | 0n, | ... | 0n | | | v | ||
| | | 1n, | 1n, | 0n, | ... | 0n, | 0n, | 1n, | ... | 0n, | 0n, | 0n, | ... | 0n, | 1n, | 0n, | ... | 0n, | ... | 0n, | 0n, | ... | 0n | | | |||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | |||
| | | 1n, | 0n, | 0n, | ... | 1n, | 0n, | 0n, | ... | 1n, | 0n, | 0n, | ... | 0n, | 0n, | 0n, | ... | 0n, | ... | 0n, | 0n, | ... | 1n | | | |||
| α | = | | | μ | | |
| | | α1 | | | ||
| | | : | | | ||
| | | αp | | | ||
| | | β1 | | | ||
| | | : | | | ||
| | | βq | | | ||
| | | γ1,1 | | | ||
| | | : | | | ||
| | | γp,q | | | ||
となって、X は npq 行 ( p + 1 )( q + 1 ) 列の行列、α は ( p + 1 )( q + 1 ) 次元のベクトルになります。X の内容がわかりづらいので、次の部分行列(ブロック)
| D | = | | | 1n, | 0n, | ... | 0n | | |
| | | 0n, | 1n, | ... | 0n | | | ||
| | | : | : | ... | : | | | ||
| | | 0n, | 0n, | ... | 1n | | | ||
| k 列目 | ||||||||
| Fk | = | | | 0n, | ... | 1n, | ... | 0n | | |
| | | 0n, | ... | 1n, | ... | 0n | | | ||
| | | : | ... | : | ... | : | | | ||
| | | 0n, | ... | 1n, | ... | 0n | | | ||
を使って X を表します。ここで、D は np 行 p 列の行列、Fk は np 行 q 列の行列とします。また、0np,p を np 行 p 列の零行列とすれば、X は
| X | = | | | 1np, | D, | F1, | D, | 0np,p, | ... | 0np,p | | |
| | | 1np, | D, | F2, | 0np,p, | D, | ... | 0np,p | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | 1np, | D, | Fq, | 0np,p, | 0np,p, | ... | D | | | ||
となります。しかし、D を列とする部分行列の各列 ( αj に対する独立変数成分 ) の和は最左端にある 1np が並ぶ列に等しくなり、Fk を列とする部分行列の各列 ( βk に対する独立変数成分 ) の和も同じく 1np が並ぶ列に等しくなります。そこで、それぞれの最後の列を除き、D を np 行 p - 1 列の、Fk を np 行 q - 1 列の行列とします。このとき、Fq は全ての要素がゼロになります。これは、未知数 αp, βq を除外する操作と同じ意味を持ちます。また、この操作によって、D と Fk の全ての列も互いに独立になります。
次に、D が対角上に並んだ後半部の行列 ( γj,k に対する独立変数成分 ) の各列を任意の組み合わせで加算することで、その左側に並ぶ 1np, D, Fk が並ぶ列と等しくすることができるので、D が並ぶ列と独立になるように対角上の最後の D を除外し、Fk が並ぶ列と独立になるように各対角上の D から最後の p 列目を除きます。これらの操作は、γj,q ( 1 ≤ j ≤ p ) と γp,k ( 1 ≤ k ≤ q - 1 ) を取り除いたことに等しくなります。これでようやく互いの列が独立になります。
除外した列の数は、αp, βq の 2 個と γj,q の p 個、それに γp,k が q - 1 個なので、全部で p + q + 1 個になります。従って未知数の数は pq 個で式の数と等しくなり、解が一意に決まります。具体的に n = 1, p = 3, q = 3 の時の X を例に今までの操作を行うと次のようになります。
| X | = | | | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | |||||
| | | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | |||||||
| | | 1, | 0, | 0, | 1, | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0 | | | |||||||
| | | 1, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0 | | | |||||||
| | | 1, | 0, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0 | | | |||||||
| | | 1, | 0, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0 | | | |||||||
| | | 1, | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0 | | | |||||||
| | | 1, | 0, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0 | | | |||||||
| | | 1, | 0, | 0, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1 | | | |||||||
| → | | | 1, | 1, | 0, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | |||||
| | | 1, | 0, | 1, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0 | | | ||||||
| | | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1 | | |
| → | | | 1, | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | |||||
| | | 1, | 0, | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0 | | | ||||||
| | | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1 | | |
| → | | | 1, | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0 | | | |||||
| | | 1, | 0, | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 1, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 1, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 1 | | | ||||||
| | | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | |
| → | | | 1, | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0 | | | |||||
| | | 1, | 0, | 1, | 1, | 0, | 0, | 1, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 1, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 1, | 0, | 0, | 1, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 1, | 0, | 0, | 0, | 1 | | | ||||||
| | | 1, | 0, | 0, | 0, | 1, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 1, | 0, | 0, | 0, | 0, | 0, | 0 | | | ||||||
| | | 1, | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | | |
この操作によって X は次のような形に変化します。
| X | = | | | 1np, | D, | F1, | D, | 0np,p-1, | ... | 0np,p-1 | | |
| | | 1np, | D, | F2, | 0np,p-1, | D, | ... | 0np,p-1 | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | 1np, | D, | Fq-1, | 0np,p-1, | 0np,p-1, | ... | D | | | ||
| | | 1np, | D, | 0np,q-1, | 0np,p-1, | 0np,p-1, | ... | 0np,p-1 | | | ||
但し、D は p 列目が除外された np 行 p - 1 列の行列であり、Fk も q 列目が除外された np 行 q - 1 列の行列です。XTX は
| XTX | = | | | q1npT1np, | q1npTD, | Σk{1→q-1}( 1npTFk ), | 1npTD, | 1npTD, | ... | 1npTD | | |
| | | qDT1np, | qDTD, | Σk{1→q-1}( DTFk ), | DTD, | DTD, | ... | DTD | | | ||
| | | Σk{1→q-1}( FkT1np ), | Σk{1→q-1}( FkTD ), | Σk{1→q-1}( FkTFk ), | F1TD, | F2TD, | ... | 0q-1,p-1 | | | ||
| | | DT1np, | DTD, | DTF1, | DTD, | 0q-1,p-1, | ... | 0q-1,p-1 | | | ||
| | | DT1np, | DTD, | DTF2, | 0q-1,p-1, | DTD, | ... | 0q-1,p-1 | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | DT1np, | DTD, | 0q-1,p-1, | 0q-1,p-1, | 0q-1,p-1, | ... | DTD | | | ||
となります。個々の部分行列を計算すると
q1npT1np = npq
1npTD = n1p-1T
1npTFk = ( 0, ... np, ... 0 ) ( k 番目の要素を np、その他を 0 とする q - 1 次元のベクトル ) より
Σk{1→q-1}( 1npTFk ) = np1q-1T
| DTD | = | | | 1nT1n, | 0, | ... | 0 | | |
| | | 0, | 1nT1n, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | 1nT1n | | | ||
| = | | | n, | 0, | ... | 0 | | = nEp-1 ( p - 1 の大きさの単位行列 x n ) | |
| | | 0, | n, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | n | | | ||
| k 列目 | ||||||||
| DTFk | = | | | 0, | ... | 1nT1n, | ... | 0 | | |
| | | 0, | ... | 1nT1n, | ... | 0 | | | ||
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | 1nT1n, | ... | 0 | | | ||
| = | | | 0, | ... | n, | ... | 0 | | | |
| | | 0, | ... | n, | ... | 0 | | | ||
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | n, | ... | 0 | | より | ||
| Σk{1→q-1}( DTFk ) | = | | | n, | n, | ... | n | | |
| | | n, | n, | ... | n | | | ||
| | | : | : | ... | : | | | ||
| | | n, | n, | ... | n | | | ||
| k 列目 | ||||||||
| FkTFk | = | | | 0, | ... | 0, | ... | 0 | | |
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | p1nT1n, | ... | 0 | | k 行目 | ||
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | 0, | ... | 0 | | | ||
| = | | | 0, | ... | 0, | ... | 0 | | | |
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | np, | ... | 0 | | k 行目 | ||
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | 0, | ... | 0 | | より | ||
| Σk{1→q-1}( FkTFk ) | = | | | np, | 0, | ... | 0 | | = npEq-1 ( q - 1 の大きさの単位行列 x np ) |
| | | 0, | np, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | np | | | ||
となるので、XTX は pq の大きさの正方行列で
| XTX | = n | | | pq, | q1p-1T, | p1q-1T | 1p-1T, | 1p-1T, | ... | 1p-1T | | |
| | | q1p-1, | qEp-1, | NT | Ep-1, | Ep-1, | ... | Ep-1 | | | ||
| | | p1q-1, | N, | pEq-1 | F1T, | F2T, | ... | Fq-1T | | | ||
| | | 1p-1, | Ep-1, | F1 | Ep-1, | 0p-1, | ... | 0p-1 | | | ||
| | | 1p-1, | Ep-1, | F2 | 0p-1, | Ep-1, | ... | 0p-1 | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | 1p-1, | Ep-1, | Fq-1 | 0p-1, | 0p-1, | ... | Ep-1 | | | ||
| < | ( p - 1 )( q - 1 ) 列 | > | |||||||||||||||||||||||||||||
| <1 列> | < | p-1 列 | > | < | q-1 列 | > | < | p-1 列 | > | < | p-1 列 | > | < | p-1 列 | > | ||||||||||||||||
| = n | | | pq, | q, | q, | ... | q, | p, | p, | ... | p, | 1, | 1, | ... | 1, | 1, | 1, | ... | 1, | ... | 1, | 1, | ... | 1 | | | 1 行 | ||||||
| | | q, | q, | 0, | ... | 0, | 1, | 1, | ... | 1, | 1, | 0, | ... | 0, | 1, | 0, | ... | 0, | ... | 1, | 0, | ... | 0 | | | p-1 行 | |||||||
| | | q, | 0, | q, | ... | 0, | 1, | 1, | ... | 1, | 0, | 1, | ... | 0, | 0, | 1, | ... | 0, | ... | 0, | 1, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | q, | 0, | 0, | ... | q, | 1, | 1, | ... | 1, | 0, | 0, | ... | 1, | 0, | 0, | ... | 1, | ... | 0, | 0, | ... | 1 | | | ||||||||
| | | p, | 1, | 1, | ... | 1, | p, | 0, | ... | 0, | 1, | 1, | ... | 1, | 0, | 0, | ... | 0, | ... | 0, | 0, | ... | 0 | | | q-1 行 | |||||||
| | | p, | 1, | 1, | ... | 1, | 0, | p, | ... | 0, | 0, | 0, | ... | 0, | 1, | 1, | ... | 1, | ... | 0, | 0, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | p, | 1, | 1, | ... | 1, | 0, | 0, | ... | p, | 0, | 0, | ... | 0, | 0, | 0, | ... | 0, | ... | 1, | 1, | ... | 1 | | | ||||||||
| | | 1, | 1, | 0, | ... | 0, | 1, | 0, | ... | 0, | 1, | 0, | ... | 0, | 0, | 0, | ... | 0, | ... | 0, | 0, | ... | 0 | | | p-1 行 | |||||||
| | | 1, | 0, | 1, | ... | 0, | 1, | 0, | ... | 0, | 0, | 1, | ... | 0, | 0, | 0, | ... | 0, | ... | 0, | 0, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | 0, | 0, | ... | 1, | 1, | 0, | ... | 0, | 0, | 0, | ... | 1, | 0, | 0, | ... | 0, | ... | 0, | 0, | ... | 0 | | | ||||||||
| | | 1, | 1, | 0, | ... | 0, | 0, | 1, | ... | 0, | 0, | 0, | ... | 0, | 1, | 0, | ... | 0, | ... | 0, | 0, | ... | 0 | | | p-1 行 | |||||||
| | | 1, | 0, | 1, | ... | 0, | 0, | 1, | ... | 0, | 0, | 0, | ... | 0, | 0, | 1, | ... | 0, | ... | 0, | 0, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | 0, | 0, | ... | 1, | 0, | 1, | ... | 0, | 0, | 0, | ... | 0, | 0, | 0, | ... | 1, | ... | 0, | 0, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | 1, | 0, | ... | 0, | 0, | 0, | ... | 1, | 0, | 0, | ... | 0, | 0, | 0, | ... | 0, | ... | 1, | 0, | ... | 0 | | | p-1 行 | |||||||
| | | 1, | 0, | 1, | ... | 0, | 0, | 0, | ... | 1, | 0, | 0, | ... | 0, | 0, | 0, | ... | 0, | ... | 0, | 1, | ... | 0 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | 0, | 0, | ... | 1, | 0, | 0, | ... | 1, | 0, | 0, | ... | 0, | 0, | 0, | ... | 0, | ... | 0, | 0, | ... | 1 | | | ||||||||
と求められます。但し、N は全要素が 1 の q - 1 行 p - 1 列行列とします。XTX の逆行列 ( XTX )-1 は以下のような結果になります (補足 2)。
| ( XTX )-1 | = (1/n) | | | 1, | -1p-1T, | -1q-1T, | 1p-1T, | 1p-1T, | ... | 1p-1T | | |
| | | -1p-1, | Np-1 + Ep-1, | NT, | -( Np-1 + Ep-1 ), | -( Np-1 + Ep-1 ), | ... | -( Np-1 + Ep-1 ) | | | ||
| | | -1q-1, | N, | Nq-1 + Eq-1, | -( N + F1T ), | -( N + F2T ), | ... | -( N + Fq-1T ) | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + F1 ) | 2( Np-1 + Ep-1 ), | Np-1 + Ep-1, | ... | Np-1 + Ep-1 | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + F2 ) | Np-1 + Ep-1, | 2( Np-1 + Ep-1 ), | ... | Np-1 + Ep-1 | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + Fq-1 ) | Np-1 + Ep-1, | Np-1 + Ep-1, | ... | 2( Np-1 + Ep-1 ) | | | ||
| < | ( p - 1 )( q - 1 ) 列 | > | |||||||||||||||||||||||||||||
| <1 列> | < | p-1 列 | > | < | q-1 列 | > | < | p-1 列 | > | < | p-1 列 | > | < | p-1 列 | > | ||||||||||||||||
| = (1/n) | | | 1, | -1, | -1, | ... | -1, | -1, | -1, | ... | -1, | 1, | 1, | ... | 1, | 1, | 1, | ... | 1, | ... | 1, | 1, | ... | 1 | | | 1 行 | ||||||
| | | -1, | 2, | 1, | ... | 1, | 1, | 1, | ... | 1, | -2, | -1, | ... | -1, | -2, | -1, | ... | -1, | ... | -2, | -1, | ... | -1 | | | p-1 行 | |||||||
| | | -1, | 1, | 2, | ... | 1, | 1, | 1, | ... | 1, | -1, | -2, | ... | -1, | -1, | -2, | ... | -1, | ... | -1, | -2, | ... | -1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | -1, | 1, | 1, | ... | 2, | 1, | 1, | ... | 1, | -1, | -1, | ... | -2, | -1, | -1, | ... | -2, | ... | -1, | -1, | ... | -2 | | | ||||||||
| | | -1, | 1, | 1, | ... | 1, | 2, | 1, | ... | 1, | -2, | -2, | ... | -2, | -1, | -1, | ... | -1, | ... | -1, | -1, | ... | -1 | | | q-1 行 | |||||||
| | | -1, | 1, | 1, | ... | 1, | 1, | 2, | ... | 1, | -1, | -1, | ... | -1, | -2, | -2, | ... | -2, | ... | -1, | -1, | ... | -1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | -1, | 1, | 1, | ... | 1, | 1, | 1, | ... | 2, | -1, | -1, | ... | -1, | -1, | -1, | ... | -1, | ... | -2, | -2, | ... | -2 | | | ||||||||
| | | 1, | -2, | -1, | ... | -1, | -2, | -1, | ... | -1, | 4, | 2, | ... | 2, | 2, | 1, | ... | 1, | ... | 2, | 1, | ... | 1 | | | p-1 行 | |||||||
| | | 1, | -1, | -2, | ... | -1, | -2, | -1, | ... | -1, | 2, | 4, | ... | 2, | 1, | 2, | ... | 1, | ... | 1, | 2, | ... | 1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -1, | -1, | ... | -2, | -2, | -1, | ... | -1, | 2, | 2, | ... | 4, | 1, | 1, | ... | 2, | ... | 1, | 1, | ... | 2 | | | ||||||||
| | | 1, | -2, | -1, | ... | -1, | -1, | -2, | ... | -1, | 2, | 1, | ... | 1, | 4, | 2, | ... | 2, | ... | 2, | 1, | ... | 1 | | | p-1 行 | |||||||
| | | 1, | -1, | -2, | ... | -1, | -1, | -2, | ... | -1, | 1, | 2, | ... | 1, | 2, | 4, | ... | 2, | ... | 1, | 2, | ... | 1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -1, | -1, | ... | -2, | -1, | -2, | ... | -1, | 1, | 1, | ... | 2, | 2, | 2, | ... | 4, | ... | 1, | 1, | ... | 2 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -2, | -1, | ... | -1, | -1, | -1, | ... | -2, | 2, | 1, | ... | 1, | 2, | 1, | ... | 1, | ... | 4, | 2, | ... | 2 | | | p-1 行 | |||||||
| | | 1, | -1, | -2, | ... | -1, | -1, | -1, | ... | -2, | 1, | 2, | ... | 1, | 1, | 2, | ... | 1, | ... | 2, | 4, | ... | 2 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -1, | -1, | ... | -2, | -1, | -1, | ... | -2, | 1, | 1, | ... | 2, | 1, | 1, | ... | 2, | ... | 2, | 2, | ... | 4 | | | ||||||||
また XTyは
| XTy | = | | | 1npT, | 1npT, | ... | 1npT, | 1npT | || | y1 | | |
| | | DT, | DT, | ... | DT | DT | || | y2 | | | ||
| | | F1T, | F2T, | ... | Fq-1T | 0q-1,np | || | : | | | ||
| | | DT, | 0p-1,np, | ... | 0p-1,np | 0p-1,np | || | yq-1 | | | ||
| | | 0p-1,np, | DT, | ... | 0p-1,np | 0p-1,np | || | yq | | | ||
| | | : | : | ... | : | : | | | ||||
| | | 0p-1,np, | 0p-1,np, | ... | DT | 0p-1,np | | | ||||
から求めることができます。但し、yk は事象 B の添字が k である np 個の要素からなるベクトル ( y1,1,k, y2,1,k, ... yn,1,k, y1,2,k, ... yn,p,k )T を表します。XT の個々の行ブロックに対する計算結果は
Σk{1→q}( 1npTyk ) = Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k ) ) ) ≡ Sy
| Σk{1→q}( DTyk ) | = | ( Σk{1→q}( Σi{1→n}( yi,1,k ) ), Σk{1→q}( Σi{1→n}( yi,2,k ) ), ... Σk{1→q}( Σi{1→n}( yi,p-1,k ) ) )T |
| ≡ | ( SA,1, SA,2, ... SA,p-1 )T ≡ SA |
| Σk{1→q}( FkTyk ) | = | ( Σj{1→p}( Σi{1→n}( yi,j,1 ) ), Σj{1→p}( Σi{1→n}( yi,j,2 ) ), ... Σj{1→p}( Σi{1→n}( yi,j,q-1 ) ) )T |
| ≡ | ( SB,1, SB,2, ... SB,q-1 )T ≡ SB |
| DTyk | = | ( Σi{1→n}( yi,1,k ), Σi{1→n}( yi,2,k ), ... Σi{1→n}( yi,p-1,k ) )T |
| ≡ | ( s1,k, s2,k, ... sp-1,k )T ≡ sk |
となるので、
| a = ( XTX )-1XTy | = (1/n) | | | 1, | -1p-1T, | -1q-1T, | 1p-1T, | 1p-1T, | ... | 1p-1T | || | Sy | | |
| | | -1p-1, | Np-1 + Ep-1, | NT, | -( Np-1 + Ep-1 ), | -( Np-1 + Ep-1 ), | ... | -( Np-1 + Ep-1 ) | || | SA | | | ||
| | | -1q-1, | N, | Nq-1 + Eq-1, | -( N + F1T ), | -( N + F2T ), | ... | -( N + Fq-1T ) | || | SB | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + F1 ), | 2( Np-1 + Ep-1 ), | Np-1 + Ep-1, | ... | Np-1 + Ep-1 | || | s1 | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + F2 ), | Np-1 + Ep-1, | 2( Np-1 + Ep-1 ), | ... | Np-1 + Ep-1 | || | s2 | | | ||
| | | : | : | : | : | : | ... | : | || | : | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + Fq-1 ), | Np-1 + Ep-1, | Np-1 + Ep-1, | ... | 2( Np-1 + Ep-1 ) | || | sq-1 | | | ||
から回帰係数の最尤推定量 a を得ることができます。ここで、
| Sy | = | Σj{1→p-1}( SA,j ) + SA,p |
| = | Σk{1→q-1}( SB,k ) + SB,q | |
| = | Σk{1→q-1}( Σj{1→p-1}( sj,k ) ) + SA,p + SB,q - sp,q |
が成り立つことを利用して一行めのブロック単位で計算すると
| ( 1, -1p-1T, -1q-1T, 1p-1T, 1p-1T, ... 1p-1T )( Sy, SAT, SBT, s1T, s2T, ... sq-1T )T / n | |
| = | [ Sy - 1p-1TSA - 1q-1TSB + Σk{1→q-1}( 1p-1Tsk ) ] / n |
| = | [ Sy - Σj{1→p-1}( SA,j ) - Σk{1→q-1}( SB,k ) + Σk{1→q-1}( Σj{1→p-1}( sj,k ) ) ] / n |
| = | [ Sy - ( Sy - SA,p ) - ( Sy - SB,q ) + ( Sy - SA,p - SB,q + sp,q ) ] / n |
| = | sp,q / n ≡ mp,q |
となり、これは、事象 ( A, B ) が ( p, q ) に属する従属変数の平均を意味します。二行目は
| ( -1p-1, Np-1 + Ep-1, NT, -( Np-1 + Ep-1 ), -( Np-1 + Ep-1 ), ... -( Np-1 + Ep-1 ) )( Sy, SAT, SBT, s1T, s2T, ... sq-1T )T / n | |
| = | ( [ -Sy1p-1 + ( Np-1 + Ep-1 )SA + NTSB - Σk{1→q-1}( ( Np-1 + Ep-1 )sk ) ] / n ) |
で計算することができて、この結果もベクトルになります。その r 行目 ( 1 ≤ r ≤ p - 1 ) は
| [ -Sy + Σj{1→p-1}( SA,j ) + SA,r + Σk{1→q-1}( SB,k ) - Σk{1→q-1}( sr,k + Σj{1→p-1}( sj,k ) ) ] / n | |
| = | { -Sy + ( Sy - SA,p ) + SA,r + ( Sy - SB,q ) - [ ( SA,r - sr,q ) + ( Sy - SA,p - SB,q + sp,q ) ] } / n |
| = | ( sr,q - sp,q ) / n ≡ mr,q - mp,q |
なので、これは事象 B を q に固定したときの、事象 A に対して r 番目と p 番目の平均差になります。次の三行目は
| ( -1q-1, N, Nq-1 + Eq-1, -( N + F1T ), -( N + F2T ), ... -( N + Fq-1T ) )( Sy, SAT, SBT, s1T, s2T, ... sq-1T )T / n | |
| = | [ -Sy1q-1 + NSA + ( Nq-1 + Eq-1 )SB - Σk{1→q-1}( ( N + FkT )sk ) ] / n |
で、これもベクトルです。その r 行目 ( 1 ≤ r ≤ q - 1 ) は
| = | [ -Sy + Σj{1→p-1}( SA,j ) + Σk{1→q-1}( SB,k ) + SB,r - Σk{1→q-1}( Σj{1→p-1}( sj,k ) ) - Σj{1→p-1}( sj,r ) ] / n |
| = | [ -Sy + ( Sy - SA,p ) + ( Sy - SB,q ) + SB,r - ( Sy - SA,p - SB,q + sp,q ) - ( SB,r - sp,r ) ] / n ) |
| = | ( sp,r - sp,q ) / n ≡ mp,r - mp,q |
となって、事象 A を p に固定したときの、事象 B に対して r 番目と q 番目の平均差になります。四行目以降は q - 1 行のブロックに分かれているので、その R 行目について計算すると、
| 1 番目 | ... | R 番目 | ... | q-1 番目 | |||
| ( 1p-1, -( Np-1 + Ep-1 ), -( NT + FR ), | Np-1 + Ep-1, | ... | 2( Np-1 + Ep-1 ), | ... | Np-1 + Ep-1 | )( Sy, SAT, SBT, s1T, ... sRT, ... sq-1T )T / n | |
| = | [ Sy1p-1 - ( Np-1 + Ep-1 )SA - ( NT + FR )SB + ( Np-1 + Ep-1 )s1 + ... + 2( Np-1 + Ep-1 )sR + ... + ( Np-1 + Ep-1 )sq-1 ] / n | ||||||
| = | [ Sy1p-1 - ( Np-1 + Ep-1 )SA - ( NT + FR )SB + Σk{1→q-1}( ( Np-1 + Ep-1 )sk ) + ( Np-1 + Ep-1 )sR ] / n | ||||||
となり、さらにその r 行目は
| [ Sy - Σj{1→p-1}( SA,j ) - SA,r - Σk{1→q-1}( SB,k ) - SB,R + Σk{1→q-1}( Σj{1→p-1}( sj,k ) + sr,k ) + Σj{1→p-1}( sj,R ) + sr,R ] / n | |
| = | [ Sy - ( Sy - SA,p ) - SA,r - ( Sy - SB,q ) - SB,R + ( Sy - SA,p - SB,q + sp,q ) + ( SA,r - sr,q ) + ( SB,R - sp,R ) + sr,R ] / n |
| = | [ ( sr,R - sp,R ) - ( sr,q - sp,q ) ] / n |
| = | ( mr,R - mp,R ) - ( mr,q - mp,q ) |
となります。mr,R - mp,R は事象 B を R に固定したときの、mr,q - mp,q は事象 B を q に固定したときの、事象 A が r 番目と p 番目の場合の平均差です。事象 A の中のある二つの要素で平均差を求めた時、それが事象 B の選び方でどの程度変化するのかをこの値で見ることができます。
以上の結果から、a = ( m, a1, ... ap, b1, ... bq, g1,1, g2,1, ... gp,1, g1,2, ... gp,q )T の各係数は以下のように表されることになります。
m = mp,q
aj = mj,q - mp,q
bk = mp,k - mp,q
gj,k = ( mj,k - mp,k ) - ( mj,q - mp,q )
| m + aj + bk + gj,k | = | mp,q + ( mj,q - mp,q ) + ( mp,k - mp,q ) + [ ( mj,k - mp,k ) - ( mj,q - mp,q ) ] |
| = | mj,k |
対数尤度統計量 DE は
| DE | = | Σk{1→q}( Σj{1→p}( Σi{1→n}( ( yi,j,k - xnp(k-1)+n(j-1)+iTa )2 ) ) ) / σ2 |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( [ yi,j,k - ( m + aj + bk + gj,k ) ]2 ) ) ) / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( ( yi,j,k - mj,k )2 ) ) ) / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 - 2yi,j,kmj,k + mj,k2 ) ) ) / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) - 2mj,kΣi{1→n}( yi,j,k ) + nmj,k2 ) ) / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) - nmj,k2 ) ) / σ2 |
となり、これは「反復のある二元配置分散分析法」での「誤差変動 SE」に相当します (*1-5)。
次に、「交互作用効果 (Interaction Effect)」γj,k を無視した以下のような縮小モデルを考えます。
このときのデザイン行列 X は、交互作用効果を含んだモデルに対してその係数に対する変数部分を除外したものに等しくなります。すなわち、
| X | = | | | 1np, | D, | F1 | | |
| | | 1np, | D, | F2 | | | ||
| | | : | : | : | | | ||
| | | 1np, | D, | Fq-1 | | | ||
| | | 1np, | D, | 0np,q-1 | | | ||
であり、XTX とその逆行列 ( XTX )-1 は
| XTX | = n | | | pq, | q1p-1T, | p1q-1T | | |
| | | q1p-1, | qEp-1, | NT | | | ||
| | | p1q-1, | N, | pEq-1 | | | ||
| ( XTX )-1 | = (1/n) | | | ( p + q - 1 ) / pq, | -1p-1T / q, | -1q-1T / p | | |
| | | -1p-1 / q, | ( 1 / q )( Np-1 + Ep-1 ), | 0p-1,q-1 | | | ||
| | | -1q-1 / p, | 0q-1,p-1, | ( 1 / p )( Nq-1 + Eq-1 ) | | | ||
です (補足 3)。α = ( μ, α1, ... αp, β1, ... βq )T の最尤推定量 a = ( m, a1, ... ap, b1, ... bq )T は次の式を解くことで求められます。
| a = ( XTX )-1XTy | = (1/n) | | | ( p + q - 1 ) / pq, | -1p-1T / q, | -1q-1T / p | || | Sy | | |
| | | -1p-1 / q, | ( 1 / q )( Np-1 + Ep-1 ), | 0p-1,q-1 | || | SA | | | ||
| | | -1q-1 / p, | 0q-1,p-1, | ( 1 / p )( Nq-1 + Eq-1 ) | || | SB | | | ||
一行目のブロックは
| ( ( p + q - 1 ) / pq, -1p-1T / q, -1q-1T / p )( Sy, SAT, SBT )T / n | |
| = | ( [ ( p + q - 1 ) / pq ]Sy - 1p-1TSA / q - 1q-1TSB / p ) / n |
| = | [ ( 1 / q + 1 / p - 1 / pq )Sy - Σj{1→p-1}( SA,j ) / q - Σk{1→q-1}( SB,k ) / p ] / n |
| = | [ ( 1 / q + 1 / p - 1 / pq )Sy - ( Sy - SA,p ) / q - ( Sy - SB,q ) / p ] / n |
| = | SA,p / nq + SB,q / np - Sy / npq |
| ≡ | mA,p + mB,q - my |
となります。ここで mA,p, mB,q, my はそれぞれ、p 番目の事象 A、q 番目の事象 B、全従属変数の平均を意味します。二行目のブロックは
| ( -1p-1 / q, ( Np-1 + Ep-1 ) / q, 0p-1,q-1 )( Sy, SAT, SBT )T / n | |
| = | [ -Sy1p-1 + ( Np-1 + Ep-1 )SA ] / nq |
より、その r 行目 ( 1 ≤ r ≤ p - 1 ) は
| [ -Sy + Σj{1→p-1}( SA,j ) + SA,r ] / nq | |
| = | [ -Sy + ( Sy - SA,p ) + SA,r ] / nq |
| = | mA,r - mA,p |
次の三行目は
| ( -1q-1 / p, 0q-1,p-1, ( Nq-1 + Eq-1 ) / p )( Sy, SAT, SBT )T / n | |
| = | [ -Sy1q-1 + ( Nq-1 + Eq-1 )SB ] / np |
より、その r 行目 ( 1 ≤ r ≤ q - 1 ) は
| = | [ -Sy + Σk{1→q-1}( SB,k ) + SB,r ] / np |
| = | [ -Sy + ( Sy - SB,q ) + SB,r ] / np |
| = | mB,r - mB,q |
となります。従って、
m = mA,p + mB,q - my
aj = mA,j - mA,p
bk = mB,k - mB,q
m + aj + bk = mA,j + mB,k - my
より対数尤度統計量 DAB は
| DAB | = | Σk{1→q}( Σj{1→p}( Σi{1→n}( [ yi,j,k - ( m + aj + bk ) ]2 ) ) ) / σ2 |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( [ yi,j,k - ( mA,j + mB,k - my ) ]2 ) ) ) / σ2 |
となります。交互作用効果を含んだモデルとの対数尤度比 DAB - DE は
| DAB - DE | = | Σk{1→q}( Σj{1→p}( Σi{1→n}( [ yi,j,k - ( mA,j + mB,k - my ) ]2 ) - [ Σi{1→n}( yi,j,k2 ) - nmj,k2 ] ) ) / σ2 |
| = | Σk{1→q}( Σj{1→p}( -2( mA,j + mB,k - my )Σi{1→n}( yi,j,k ) + n( mA,j + mB,k - my )2 + nmj,k2 ) ) / σ2 | |
| = | nΣk{1→q}( Σj{1→p}( mj,k2 - 2( mA,j + mB,k - my )mj,k + ( mA,j + mB,k - my )2 ) ) / σ2 | |
| = | nΣk{1→q}( Σj{1→p}( ( mj,k - mA,j - mB,k + my )2 ) ) / σ2 |
となって、これは二元配置分散分析における「交互作用 SRC」に該当します (*1-5)。
さらに事象 B に関する変動分 βk まで除外したモデル式とデザイン行列は
yi,j,k = μ + αj + εi,j,k
| X | = | | | 1np, | D | | |
| | | 1np, | D | | | ||
| | | : | : | | | ||
| | | 1np, | D | | | ||
であり、XTX とその逆行列 ( XTX )-1 は
| XTX | = n | | | pq, | q1p-1T | | |
| | | q1p-1, | qEp-1 | | | ||
| ( XTX )-1 | = (1/nq) | | | 1, | -1p-1T | | |
| | | -1p-1, | Np-1 + Ep-1 | | | ||
です。α = ( μ, α1, ... αp )T の最尤推定量 a = ( m, a1, ... ap )T は
| a = ( XTX )-1XTy | = (1/nq) | | | 1, | -1p-1T | || | Sy | | |
| | | -1p-1, | Np-1 + Ep-1 | || | SA | | | ||
より
m = [ Sy - Σj{1→p-1}( SA,j ) ] / nq
ar = [ -Sy + Σj{1→p-1}( SA,j ) + SA,r ] / nq ( 2 ≤ r ≤ p )
m + aj = SA,j / nq = mA,j ( 2 ≤ j ≤ p )
となって、対数尤度統計量 DA は
| DA | = | Σk{1→q}( Σj{1→p}( Σi{1→n}( [ yi,j,k - ( m + aj ) ]2 ) ) ) / σ2 |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( ( yi,j,k - mA,j )2 ) ) ) / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 - 2yi,j,kmA,j + mA,j2 ) ) ) / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) - 2mA,jΣi{1→n}( yi,j,k ) + nmA,j2 ) ) / σ2 | |
| = | [ Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) ) ) - 2Σj{1→p}( mA,jΣk{1→q}( sj,k ) ) + nqΣj{1→p}( mA,j2 ) ] / σ2 | |
| = | [ Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) ) ) - 2Σj{1→p}( mA,jSA,j ) ) + nqΣj{1→p}( mA,j2 ) ] / σ2 | |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) - nmA,j2 ) ) / σ2 |
となります。最小モデルに対する対数尤度統計量を DT とすると、
| DT | = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k - my )2 ) ) ) / σ2 |
| = | Σk{1→q}( Σj{1→p}( Σi{1→n}( yi,j,k2 ) - nmy2 ) ) / σ2 |
となるのでした。対数尤度比 DT - DA は
| DT - DA | = | Σk{1→q}( Σj{1→p}( [ Σi{1→n}( yi,j,k2 ) - nmy2 ] - [ Σi{1→n}( yi,j,k2 ) - nmA,j2 ] ) ) / σ2 |
| = | nΣk{1→q}( Σj{1→p}( mA,j2 - my2 ) ) / σ2 | |
| = | nqΣj{1→p}( mA,j2 - my2 ) ) / σ2 |
となり、これは事象 A での ( 事象 B の差異を考慮しない ) 変動を表します。同様に、事象 B での ( 事象 A の差異を考慮しない ) 変動は
であり、これらは二元配置分散分析における「列間・行間変動 SR, SC」を意味します。
分散分析は、一般化線形モデルにおける尤度比を使った検定と同等であることが、これらの結果からわかります。その内容についても比較的理解がしやすく、それが広く利用されている理由の一つなのではないかと思います。但し、連結関数は恒等関数であり、利用する確率分布も正規分布であることから、それ以外のモデルを考慮しなければならない場合は分散分析をそのまま利用することはできません。
*1-1) 「確率・統計 (15) 共分散分析 (ANCOVA)」の「名義尺度の線形重回帰モデル」に関する説明を参照
*1-2) 「確率・統計 (18) 一般化線形モデル (Generalized Linear Model)」の「スコア統計量 (Score Statistic)」に関する説明を参照
*1-3) 「確率・統計 (18) 一般化線形モデル (Generalized Linear Model)」の「尤度比 (Likelihood-ratio)」に関する説明を参照
*1-4) 「確率・統計 (14) 分散分析法 (ANOVA)」の「一元配置分散分析法(One-way ANalysis Of VAriance ; One-way ANOVA)」に関する説明を参照
*1-5) 「確率・統計 (14) 分散分析法 (ANOVA)」の「反復のある二元配置分散分析法(Two-way Repeated-Measures ANOVA)」に関する説明を参照
分散分析の場合、独立変数が事象をダミー変数で表したものであるのに対し従属変数は連続値になるのが通常で、モデル式との誤差が平均ゼロの正規分布に従うと仮定した上で検定を行います。また、正規分布の分散は、どの従属変数に対しても一定であるとみなします。しかし、従属変数が「計数データ (Count Data)」または「度数データ (Frequency Data)」と呼ばれる、ある事象の発生回数であった場合、正規分布よりも「ポアソン分布 (Poisson Distribution)」がよく用いられます (*2-1)。ポアソン分布は、
で表される離散確率密度関数で、一母数指数型分布族なので一般化線形モデルを適用することができます。確率変数の y は事象の発生した回数を表し、その平均発生回数が μ になります。すなわち、E[y] = μ です。また、ポアソン分布は分散が平均と等しいという特徴があります。よって、V[y] = μ ということになります。μ は割合や比率で表されます。例えば、一定時間内に発生する事象の平均回数や、一定の試行回数あたりで発生する事象の平均回数などで表現されます。特に後者の場合、試行回数を n で表せば μ = nθ とすることができて、さらに
とすれば
μ = nexα より
log μ = log n + xα
となって、連結関数は対数関数になります。なお、θ を指数関数にすることで、任意の x に対して μ は正の数であることが保証されます。
ある独立変数 xi に対してその従属変数 yi の期待値が E[yi] = μi = niθi であるとします。これらを上式にあてはめると
より
であり、また V[yi] = μi なので、1 / V[yi]g'(μi)2 = μi となって、これがフィッシャー情報行列 Φ = XTWX における対角行列 W の対角成分となります。すでにポアソン分布用のクラス ExpFamily_Poisson と対数関数を連結関数とした LogFunc クラスは「確率・統計 (18) 一般化線形モデル」において用意されているので、これらを使ってスコア法 ScoringMethod 関数を呼び出せば処理をすることができます。
ポアソン分布を利用した場合、対数尤度関数は
| l( μ | y ) | = | log( Πi{1→N}( μiyie-μi / yi! ) ) |
| = | Σi{1→N}( yilog μi - μi - log yi! ) |
となります。ここで、N は独立変数・従属変数の数を表します。飽和モデルの場合は μ を使ったモデル式を考えればよいので
より μi = yi、すなわち推定量は実測値と等しくなります。あるモデル式から得られた当てはめ値を mi とすれば、
なので、飽和モデルの対数尤度関数の最大値を l( y | y ) で表した時、飽和モデルとの対数尤度統計量 D は
| D = 2[ l( y | y ) - l( m | y ) ] | = | 2[ Σi{1→N}( yilog yi - yi - log yi! ) - Σi{1→N}( yilog mi - mi - log yi! ) ] |
| = | 2Σi{1→N}( yilog( yi / mi ) - ( yi - mi ) ) |
となります。ところが、スコア統計量 uj は
で表され、指数型分布属をポアソン分布、連結関数を対数関数とした場合、
V[yi] = μi
g'(μi) = 1 / μi
なので、分母は打ち消されて
となるので、特に定数項に対するスコア統計量は Σi{1→N}( yi - μi ) です。スコア統計量がゼロになるときの各係数が最尤推定量になることから、特に定数項に対しては
が成り立ちます。従って、(モデル式が定数項を含むなら) 対数尤度統計量 D は
と単純化することができます。なお、ロジスティック回帰の時と同様に「逸脱度残差」を定義すると、
となります。但し、SIGN は yi - mi の符号を意味します ( 補足 5 )。
最小モデルに対する対数尤度関数は、θi が全て共通の値 θ であると考えて
より ∂l / ∂θ = 0 のとき
Σi{1→N}( yi / θ - ni ) = 0 より
θ = Σi{1→N}( yi ) / Σi{1→N}( ni )
となるので、θ の最尤推定量は yi の和と ni の和の比率となります。これを t として、最小モデルの対数尤度関数の最大値を l( t | y ) で表した時、最小モデルとの対数尤度統計量 ( = 「尤度比カイ二乗統計量 C」 ) は、
| C = 2[ l( m | y ) - l( t | y ) ] | = | 2Σi{1→N}( yilog mi - mi - log yi! ) - 2Σi{1→N}( yilog nit - nit - log yi! ) |
| = | 2Σi{1→N}( yilog( mi / nit ) - ( mi - nit ) ) |
となります。ここで、
| Σi{1→N}( mi - nit ) | = | Σi{1→N}( mi ) - Σi{1→N}( ni )Σi{1→N}( yi ) / Σi{1→N}( ni ) |
| = | Σi{1→N}( mi - yi ) |
より、モデル式に定数項が含まれることを前提として、C は
と単純化することができます。また、「(マクファデンの) 擬似 R2 値」は [ l( t | y ) - l( m | y ) ] / l( t | y ) で求められるので、
から得ることができます。
線形重回帰分析において、観測した従属変数 yi の予測値を y^i とし、観測値 yi と予測値 y^i の平均をそれぞれ my, m^y としたとき、
とすれば、S^y が自由度 p - 1 の、Sε が自由度 N - p の、Sy が自由度 N - 1 のカイ二乗分布にそれぞれ従います。また、S^y = Sy - Sε が成り立つことから、S^y は自由度 p - 1 のカイ二乗分布に従うことになります。しかし、正規分布には「局外パラメータ」として標準偏差 σ があり、そのままでは検定をすることができないので、v^y ≡ S^y / ( p - 1 ) と vT = ST / ( N - p ) の比率 F0 が自由度 ( p - 1, N - p ) の F-分布に従うことを利用して検定を行います。重回帰分析が、誤差項が従う確率分布として利用する正規分布の分散を全て等しいと仮定しているのはそのためです。また、( Sy - Sε ) / Sy = S^y / Sy は「決定係数」または「寄与率」を表し、これは予測値がどの程度モデル式を反映しているかを見るための指標となるのでした。これらの結果は通常、分散分析表で表されます (*2-2)。
一般化線形モデルでは、Sε が飽和モデルと線形モデルの間の対数尤度統計量 D と等しく、Sy が飽和モデルと最小モデルの間の対数尤度統計量 D0 と等しいのでした。また、寄与率は ( D0 - D ) / D0 となり、これは線形モデルが飽和モデルと最小モデルの対数尤度差を指標としてどの程度の割合でモデル式を表せているのかを表していると考えることができます (*2-3)。
ポアソン回帰を行うためのサンプル・プログラムを示します。
/* LogFunc_Poisson : 対数連結関数(ポアソン回帰用) 定数項として試行回数を加える。試行回数は各試行に応じて切り替える */ class LogFunc_Poisson : public LinkFunction_IF { const vector<double>& ni_; // 試行回数 // 各関数の利用回数(n_.size()の剰余) mutable unsigned int opCnt_; // operator()() mutable unsigned int invfCnt_; // invf() public: // コンストラクタ LogFunc_Poisson( const vector<double>& ni ) : ni_( ni ), opCnt_( 0 ), invfCnt_( 0 ) {} // 連結関数 g(x) virtual double operator()( double x ) const { double d = log( x ) - log( ni_[opCnt_] ); opCnt_ = ( opCnt_ + 1 ) % ni_.size(); return( d ); } // 導関数 g'(x) virtual double df( double x ) const { return( 1 / x ); } // 逆関数 g^-1(y) virtual double invf( double y ) const { double d = ni_[invfCnt_] * exp( y ); invfCnt_ = ( invfCnt_ + 1 ) % ni_.size(); return( d ); } // 属性を表す文字列 virtual string ident() const { return( "Logarithm Function ( for Poisson Regression )" ); } }; /* PoissonRegression : ポアソン回帰 const vector<double>& y : 発生回数(従属変数) const vector<double>& ni : 試行回数 const vector< vector<double> >& x : 独立変数 vector<double>& a : 求めた係数 bool verbose : 冗長モード(ON/OFF) unsigned int maxCount : 反復処理の最大回数 double threshold : 収束条件(全係数が threshold 以下なら処理終了) 戻り値 : 係数が得られた ... true ; データ異常・反復処理回数が最大値を超えた ... false */ bool PoissonRegression( const vector<double>& y, const vector<double>& ni, const vector< vector<double> >& x, vector<double>& a, bool verbose, unsigned int maxCount, double threshold ) { cout << "*** Poisson Regression ***" << endl << endl; // NULL のチェック ( x, y, a は ScoringMethod で行われるので省略 if ( ! NullCheck( ni, "Total Count ni" ) ) return( false ); // x と ni のサイズ比較 if ( ! SizeCheck( ni, "Total Count ni", x.size(), "Independent Variable x" ) ) return( false ); if ( verbose ) { PrintVector( "ni = ", ni ); cout << endl; } // 連結関数の作成 LogFunc_Poisson g( ni ); // 指数型分布族(ポアソン分布) ExpFamily_Poisson pdf; return( ScoringMethod( x, y, a, pdf, g, verbose, maxCount, threshold ) ); }
総試行回数は各試行によって変わるので、連結関数に含まれる定数項 log ni も切り替える必要があります。そこで、以前「(19) ロジスティック回帰 (Logistic Regression Model)」の章で紹介した、二項分布を利用したスコア法のサンプル・プログラムと同様の手法を使い、各メンバ関数が呼び出された時にカウンタを 1 ずつ増加させることで定数項が切り替わるようにします。スコア法の関数 ScoringMethod は、計算に必要な LinkFunction_IF のメンバ関数 operator(), df, invf をそれぞれ 1 ループに一度しか呼び出さないのでこのような手法が可能になりますが、前にも書いた通り実装に依存した方法なのであまりいいやり方とは言えません。内容は対数関数用の連結関数とほとんど変わりませんが、定数項を使うため以下のような式になります。
ξi = g( μi ) = log μi - log ni
dξi / dμi = g'( μi ) = 1 / μi
μi = g-1( ξi ) = nieξi
定数項を計算するための試行回数 ni はインスタンス化をするときに配列のまま渡すようにしています。カウンタは opCnt_ と invfCnt_ で、それぞれ operator(), invf 用に利用します。df の計算には ni は含まれないので専用のカウンタは不要です。これらのメンバ関数が呼び出されたら、計算後にカウンタを 1 増加させます。カウンタが ni の個数以上にならないように、個数との剰余をカウンタに代入するようにしています。これによって、カウンタが循環するような形になります。
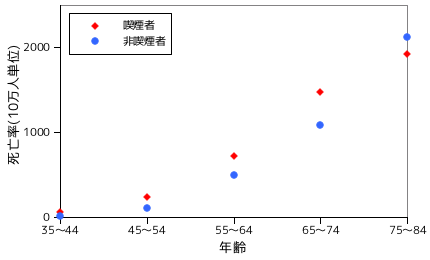
サンプル・プログラムを使って、参考文献にあるデータをポアソン回帰で解析してみたいと思います。下表は、イギリスの男性医師の冠動脈心疾患による死亡者数を 1951 年から 10 年間調査し、喫煙の有無と年齢ごとに分類した結果です。総数はその事象の調査対象者の人数を示しています。
|
|
||||||||||||||||||||||||||||||||||
グラフの死亡者数は、10 万人を総数とした時の比率で表されています。グラフから、死亡者数は年齢に対して二次のオーダーで増加しているように見えます。また、喫煙者と非喫煙者の間でわずかな差異が見られます。喫煙・非喫煙の有無を xi1 = 1 (喫煙) または 0 (非喫煙)、年齢を xi2 として 35〜44 から 75〜84 まで順に 1 から 5 まで連番で表します。また、死亡者数が年齢に対して二次のオーダーで増加していることを表すため、xi3 = xi22 として二次項を追加します。最後に、年齢と喫煙・非喫煙の相関を表す項として xi4、定数項を xi0 とします。xi = ( xi0, xi1, xi2, xi3, xi4 )T は 5 次元のベクトルで、X = ( x1, x2, ... x10 ) はデザイン行列です。X の具体的な値は
| X | = | | | 1, | 1, | 1, | 1, | 1 | | |
| | | 1, | 1, | 2, | 4, | 2 | | | ||
| | | 1, | 1, | 3, | 9, | 3 | | | ||
| | | 1, | 1, | 4, | 16, | 4 | | | ||
| | | 1, | 1, | 5, | 25, | 5 | | | ||
| | | 1, | 0, | 1, | 1, | 0 | | | ||
| | | 1, | 0, | 2, | 4, | 0 | | | ||
| | | 1, | 0, | 3, | 9, | 0 | | | ||
| | | 1, | 0, | 4, | 16, | 0 | | | ||
| | | 1, | 0, | 5, | 25, | 0 | | | ||
であり、W の対角行列は μi なので、これらからフィッシャー情報行列 Φ を得ることができます。
これらを使ってスコア法により係数の最尤推定量を計算すると以下の結果が得られます ( verbose = true にして冗長モードで出力しています )。
*** Poisson Regression ***
ni = ( 52407, 43248, 28612, 12663, 5317, 18790, 10673, 5710, 2585, 1462 )
*** Scoring Method ***
Exponential Family of Distribution : Poisson Distribution
Link Function : Logarithm Function ( for Poisson Regression )
N = 10; p = 5
x = ( 1, 1, 1, 1, 1 )
( 1, 1, 2, 4, 2 )
( 1, 1, 3, 9, 3 )
( 1, 1, 4, 16, 4 )
( 1, 1, 5, 25, 5 )
( 1, 0, 1, 1, 0 )
( 1, 0, 2, 4, 0 )
( 1, 0, 3, 9, 0 )
( 1, 0, 4, 16, 0 )
( 1, 0, 5, 25, 0 )
y = ( 32, 104, 206, 186, 102, 2, 12, 28, 28, 31 )
----- cnt = 0 -----
mu = ( 32, 104, 206, 186, 102, 2, 12, 28, 28, 31 )
g'(mu) = ( 0.03125, 0.00961538, 0.00485437, 0.00537634, 0.00980392, 0.5, 0.0833333, 0.0357143, 0.0357143, 0.0322581 )
w = ( 0.03125, 0.00961538, 0.00485437, 0.00537634, 0.00980392, 0.5, 0.0833333, 0.0357143, 0.0357143, 0.0322581 )
Equation System :
(731)x0 + (630)x1 + (2489)x2 + (9353)x3 + (2112)x4 = -3563.5
(630)x0 + (630)x1 + (2112)x2 + (7828)x3 + (2112)x4 = -3068.66
(2489)x0 + (2112)x1 + (9353)x2 + (37601)x3 + (7828)x4 = -11428.8
(9353)x0 + (7828)x1 + (37601)x2 + (158753)x3 + (31080)x4 = -41233.4
(2112)x0 + (2112)x1 + (7828)x2 + (31080)x3 + (7828)x4 = -9696.75
Regression equation : y = -10.7355x0 + 1.39899x1 + 2.35751x2 + -0.19629x3 + -0.297892x4
----- cnt = 1 -----
mu = ( 29.7732, 106.94, 207.951, 182.681, 102.819, 3.54945, 11.8203, 25.0376, 30.3064, 30.9487 )
g'(mu) = ( 0.0335872, 0.00935107, 0.00480882, 0.00547401, 0.00972583, 0.281734, 0.0846, 0.03994, 0.0329964, 0.0323116 )
w = ( 0.0335872, 0.00935107, 0.00480882, 0.00547401, 0.00972583, 0.281734, 0.0846, 0.03994, 0.0329964, 0.0323116 )
Equation System :
(731.827)x0 + (630.164)x1 + (2490.6)x2 + (9357.26)x3 + (2112.33)x4 = -3570.14
(630.164)x0 + (630.164)x1 + (2112.33)x2 + (7822.47)x3 + (2112.33)x4 = -3068.6
(2490.6)x0 + (2112.33)x1 + (9357.26)x2 + (37626.3)x3 + (7822.47)x4 = -11440.4
(9357.26)x0 + (7822.47)x1 + (37626.3)x2 + (158935)x3 + (31044)x4 = -41256.5
(2112.33)x0 + (2112.33)x1 + (7822.47)x2 + (31044)x3 + (7822.47)x4 = -9704.44
Regression equation : y = -10.7912x0 + 1.44048x1 + 2.37629x2 + -0.197665x3 + -0.307437x4
----- cnt = 2 -----
mu = ( 29.5862, 106.813, 208.197, 182.827, 102.579, 3.41625, 11.5448, 24.7469, 30.2303, 31.0696 )
g'(mu) = ( 0.0337996, 0.00936217, 0.00480315, 0.00546966, 0.0097486, 0.292718, 0.0866192, 0.040409, 0.0330794, 0.0321858 )
w = ( 0.0337996, 0.00936217, 0.00480315, 0.00546966, 0.0097486, 0.292718, 0.0866192, 0.040409, 0.0330794, 0.0321858 )
Equation System :
(731.009)x0 + (630.001)x1 + (2489.02)x2 + (9353.05)x3 + (2112)x4 = -3564.38
(630.001)x0 + (630.001)x1 + (2112)x2 + (7820.31)x3 + (2112)x4 = -3067.31
(2489.02)x0 + (2112)x1 + (9353.05)x2 + (37611)x3 + (7820.31)x4 = -11430.2
(9353.05)x0 + (7820.31)x1 + (37611)x2 + (158868)x3 + (31028.7)x4 = -41232.5
(2112)x0 + (2112)x1 + (7820.31)x2 + (31028.7)x3 + (7820.31)x4 = -9702.87
Regression equation : y = -10.7918x0 + 1.44097x1 + 2.37648x2 + -0.197677x3 + -0.307548x4
Estimated regression equation : y = -10.7918x0 + 1.44097x1 + 2.37648x2 + -0.197677x3 + -0.307548x4
variance of a = ( 0.202529, 0.138504, 0.043238, 0.000748941, 0.0094156 )
この結果を表にまとめると以下のようになります。
| 喫煙の有無 (xi1) | 年齢 (xi2) | 年齢2 (xi3) | 年齢 x 喫煙の有無 (xi4) | |
|---|---|---|---|---|
| 係数の最尤推定量 a | 1.441 | 2.376 | -0.198 | -0.308 |
| a の分散 | 0.139 | 0.0432 | 7.49E-4 | 9.42E-3 |
| a の標準偏差 | 0.372 | 0.208 | 0.0274 | 0.0970 |
独立変数の一つ xj に対して、j 以外の事象が全て同一なときの、xj = 1 での期待値と xj = 0 での期待値の比率は「率比 (Rate Ratio)」と呼ばれ、それを RR で表すと
となります。eαj は θ に対して乗法的に作用するので、αj ではなく率比で表した方が意味を解釈しやすくなります。率比を計算した結果は以下のようになります。
| 喫煙の有無 (xi1) | 年齢 (xi2) | 年齢2 (xi3) | 年齢 x 喫煙の有無 (xi4) | |
|---|---|---|---|---|
| 率比 RR | 4.22 | 10.8 | 0.821 | 0.735 |
年齢による差異を調整したときの喫煙の有無に対する死亡率は、率比から 4.22 倍と推定することができます。但し、xi4 に対する率比が 1 より小さく、係数も負数であることから、その差は年齢とともに小さくなっていくことになります。
求めた係数から得られる期待値と残差を求めた結果は以下のようになります。
| 年齢 | 喫煙 | 実測値 | 期待値 | Χi | di | Ci |
|---|---|---|---|---|---|---|
| 35〜44 | 有 | 32 | 29.58 | 0.444 | 0.438 | 237.28 |
| 45〜54 | 104 | 106.81 | -0.272 | -0.273 | 33.05 | |
| 55〜64 | 206 | 208.19 | -0.152 | -0.152 | 57.74 | |
| 65〜74 | 186 | 182.82 | 0.235 | 0.234 | 211.23 | |
| 75〜84 | 102 | 102.57 | -0.0565 | -0.0566 | 157.22 | |
| 35〜44 | 無 | 2 | 3.41 | -0.766 | -0.830 | 132.16 |
| 45〜54 | 12 | 11.54 | 0.135 | 0.134 | 31.34 | |
| 55〜64 | 28 | 24.74 | 0.655 | 0.641 | 0.6039 | |
| 65〜74 | 28 | 30.23 | -0.405 | -0.410 | 20.05 | |
| 75〜84 | 31 | 31.07 | -0.0125 | -0.0125 | 52.75 | |
| Χ2 | D | C | ||||
| 1.550 | 1.635 | 933.43 | ||||
表の中で、Χi はピアソン残差、di は逸脱度残差、Ci は尤比度カイ二乗統計量の和の成分をそれぞれ表し、Χ2 = Σi( Χi2 ) がピアソン・カイ二乗統計量、D = Σi( di2 ) が飽和モデルとの対数尤度統計量、C = Σi( Ci ) が尤比度カイ二乗統計量をそれぞれ表します。
Χ2 も D も小さな値を示していることから、このモデル式への当てはめは非常によいことになります。飽和モデルのパラメータ数は 10 であり、仮定したモデル式のパラメータ数は 5 なので、Χ2 と D は自由度 5 のカイ二乗分布に近似的に従うことになり、その上側 5% 点は 11.07 であることからはるかに小さな値を示しています。C はかなり大きな値であり、自由度 5 - 1 = 4 のカイ二乗分布に従うことから p 値を計算すると極端に小さな値となるので、定数項以外の係数がゼロであるという仮定は成り立ちません。擬似 R2 値は 0.943 であり、このことからもモデル式の当てはめが非常によいと判断できます。
*2-1) 「確率・統計 (3) 離散確率分布」の「2) ポアソン分布(Poisson Distribution)」を参照
*2-2) 「確率・統計 (13) 回帰分析法」の「2) 重相関係数(Multiple Correlation Coefficient)」を参照
*2-3) 「確率・統計 (18) 一般化線形モデル (Generalized Linear Model)」の「5) 尤度比 (Likelihood-ratio)」を参照
ポアソン回帰では、各独立変数に対応する従属変数が従う確率分布のパラメータ μi が互いに制約を受けないことを前提としていました。しかし、全体の母数や各条件の母数にあらかじめ制約があるなどの理由でポアソン回帰をそのまま利用することができない場合があります。例えば、総試行回数が N 回で、その中である条件 Ai ( 1 ≤ i ≤ m ) に当てはまる回数が yi 回であったと仮定します。これは、N 回の試行の中で Ai が yi 回発生した時の確率密度を意味するので、Ai の発生確率を θi としたとき、多項分布
で表すことができます。ここで、μi = Nθi として各試行がポアソン分布
に従うと仮定すると、その同時確率は
となりますが、総試行回数 Σi{1→m}( yi ) が N となる確率分布はやはりポアソン分布に従い (補足 4)、
と表すことができます。但し、μ = Σi{1→m}( μi ) です。従って、総試行回数が N という条件下での条件付き確率 P( y | N ) は
| P( y | N ) | = | Πi{1→m}( Pμi( yi ) ) / Pμ( N ) |
| = | [ e-μΠi{1→m}( μiyi / yi! ) ] / ( μNe-μ / N! ) | |
| = | N!Πi{1→m}( μiyi / μyiyi! ) | |
| = | N!Πi{1→m}( ( μi / μ )yi / yi! ) |
となって、μi / μ = θi とすれば多項分布と一致します。このとき、μ = Σi{1→m}( μi ) より Σi{1→m}( θi ) = 1 が成り立ちます。yi の期待値 E[yi] は
なので、ポアソン回帰のときと同様に
とすれば、連結関数として
が成り立ち、これはポアソン回帰での連結関数において ni = N とした場合に相当します。
ポアソン回帰では ni も θi も未知数であり、これらを決定するのは連結関数です。ポアソン回帰の場合、連結関数は
であるのに対し、多項分布の場合は
となります。両者の差異は定数項のみであり、前者は各事象に対して定数項を決めた上で方程式を解くのに対し、後者は定数項を全て等しく、つまり連結関数は共通であるとした上で方程式を解いています。
 |
ポアソン分布 |
| 多項分布 |
デザイン行列 X を次のような形で表します。各行は一つの事象を表すので行数は m になります。また、端点制約により最後の m 番目の係数は定数項の係数の中に含めてしまい、列数は定数項を含め m 個となります。
| X | = | | | 1, | 1, | 0, | ... | 0 | | |
| | | 1, | 0, | 1, | ... | 0 | | | ||
| | | : | : | : | ... | : | | | ||
| | | 1, | 0, | 0, | ... | 1 | | | ||
| | | 1, | 0, | 0, | ... | 0 | | | ||
これは、一元配置分散分析において yi = 1 にした場合に相当します。回帰係数の最尤推定量を a = ( a0, a1, ... am-1 ) としたとき、i 行目の式は
となるので、連結関数と見比べると、
が成り立ち、率比 RR = eai がそのまま μi の基準カテゴリ ( この場合 i = m ) との比率を表し、Neaiea0 が μi の推定量となります。
W は対角成分を μi とした対角行列で表すことができるので、スコア法における漸化式の左辺の係数行列 XTWX は、
| XTWX |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
となります。また、右辺の XTWz において
zi = g(μi) + ( yi - μi )g'(μi)
z = ( z1, z2, ... zm )T
とすれば、
であり、右辺は
| XTWz |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
|
なので、回帰係数の最尤推定量を a = ( a0, a1, ... am-1 )T とすれば
| a0Σi{1→m}( μi ) + Σi{1→m-1}( aiμi ) | |
| = | a0μm + Σi{1→m-1}( ( a0 + ai )μi ) |
| = | Σi{1→m}( μizi ) |
a0μi + aiμi = ( a0 + ai )μi = μizi より a0 + ai = zi
となります。a0 + ai = zi を上側の式に代入すれば
a0μm + Σi{1→m-1}( μizi ) = Σi{1→m}( μizi ) より
a0 = zm
であり、
a0 + ai = zi より
ai = zi - zm
という結果が得られますが、一元配置分散分析での回帰係数が、ni = 1 ならば
a0 = ym
ai = yi - ym
となることと比較すると非常によく似た式になります。
多項分布を仮定した方式では、事象を複数としても成り立ちます。例えば、二つの事象 A, B の組み合わせに対して発生回数 yj,k の同時確率が多項分布に従うと仮定することができます。さらに、それぞれの事象の発生回数に制約を設ける考え方もあります。事象 A がカテゴリ Aj ( 1 ≤ j ≤ p ) に分類できたとして、その発生回数の総計がそれぞれ nj に固定されている場合、カテゴリ Aj の同時確率が多項分布
に従うと仮定します。q は事象 B の分類数を表し、Σk{1→q}( θj,k ) = 1、Σk{1→q}( yj,k ) = nj です。このとき、全事象に対する同時確率は
となります。これは「積多項分布 (Product Multinomial Distribution)」と呼ばれます。この場合の連結関数は、μj,k = njθj,k より
となります。
二つの事象 A, B の組み合わせに対して多項分布を仮定したとき、事象 A, B の中であるカテゴリが発生する確率が互いに独立ならば、事象 A のカテゴリ Aj が発生する確率を θA,j、事象 B のカテゴリ Bk が発生する確率を θB,k としたとき、
θj,k = θA,jθB,k
μj,k = NθA,j・NθB,k / N ≡ μA,jμB,k / N
であることから、連結関数は
となります。飽和モデルは
なので、この両者を比較することで独立性の推定・検定を行うことができます。これはよく利用される手法です。
二元配置分散分析において n = 1 とした時のデザイン行列は
| X | = | | | 1p, | D, | F1, | D, | 0p,p-1, | ... | 0p,p-1 | | |
| | | 1p, | D, | F2, | 0p,p-1, | D, | ... | 0p,p-1 | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | 1p, | D, | Fq-1, | 0p,p-1, | 0p,p-1, | ... | D | | | ||
| | | 1p, | D, | 0p,q-1, | 0p,p-1, | 0p,p-1, | ... | 0p,p-1 | | | ||
となります。ここで、D は行列数が p の単位行列 Ep から第 p 列を除外した p 行 p - 1 列の行列、Fk は k 列目の全要素が全て 1 で、残りは 0 の p 行 q - 1 列行列になります。回帰係数の最尤推定量を a = ( a0, a1, ... ap-1, b1, ... aq-1, g1,1, ... gp-1,1, g1,2, ... gp-1,q-1 )T とした時、j 行目のブロックの k 行目の要素にあたる式は
となり、連結関数と比較すると
が成り立ちます。
W は、μj,k を対角成分 ( 但し、μ1,1, μ2,1, ... μp,1, μ1,2 ... の順に並べます ) とした行列数 pq の対角行列になるので、μ1,k から μp,k までを対角成分とする行列数 p の対角行列を Μk とすれば、
| XTWX |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
と計算することができます。各ブロックは
1pTΜk = ( μ1,k, μ2,k, ... μp,k ) より
1pTΜk1p = Σj{1→p}( μj,k ) ≡ μB,k
Σk{1→q}( 1pTΜk1p ) = Σk{1→q}( μB,k ) ≡ μ ( = N )
| Σk{1→q}( 1pTΜkD ) | = | ( Σk{1→q}( μ1,k ), Σk{1→q}( μ2,k ), ... Σk{1→q}( μp-1,k ) ) |
| ≡ | ( μA,1, μA,2, ... μA,p-1 ) |
1pTΜkFk = ( 0, 0, ... μB,k, ... 0 ) ( k 列のみ要素を持つ行ベクトル )
Σk{1→q-1}( 1pTΜkFk ) = ( μB,1, μB,2, ... μB,q-1 )
| DTΜk | = | | | μ1,k, | 0, | ... | 0, | 0 | | |
| | | 0, | μ2,k, | ... | 0, | 0 | | | ||
| | | : | : | ... | : | : | | | ||
| | | 0, | 0, | ... | μp-1,k, | 0 | | より | ||
DTΜk1p = ( μ1,k, μ2,k, ... μp-1,k )T
Σk{1→q}( DTΜk1p ) = ( μA,1, μA,2., ... μA,p-1 )T
| DTΜkD | = | | | μ1,k, | 0, | ... | 0 | | |
| | | 0, | μ2,k, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | μp-1,k | | | ||
| Σk{1→q}( DTΜkD ) | = | | | μA,1, | 0, | ... | 0 | | |
| | | 0, | μA,2, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | μA,p-1 | | | ||
| DTΜkFk | = | | | 0, | 0, | ... | μ1,k, | ... | 0 | | |
| | | 0, | 0, | ... | μ2,k, | ... | 0 | | | ||
| | | : | : | ... | : | ... | : | | | ||
| | | 0, | 0, | ... | μp-1,k, | ... | 0 | | ( k 列のみ要素を持つ行列 ) | ||
| Σk{1→q-1}( DTΜkFk ) | = | | | μ1,1, | μ1,2, | ... | μ1,q-1 | | |
| | | μ2,1, | μ2,2, | ... | μ2,q-1 | | | ||
| | | : | : | ... | : | | | ||
| | | μp-1,1, | μp-1,2, | ... | μp-1,q-1 | | | ||
| FkTΜk | = | | | 0, | 0, | ... | 0 | | |
| | | 0, | 0, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | μ1,k, | μ2,k, | ... | μp,k | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | 0 | | より | ||
FkTΜk1p = ( 0, 0, ... μB,k, ... 0 )T ( k 行のみ要素を持つ列ベクトル )
Σk{1→q-1}( FkTΜk1p ) = ( μB,1, μB,2, ... μB,q-1 )T
| FkTΜkD | = | | | 0, | 0, | ... | 0 | | |
| | | 0, | 0, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | μ1,k, | μ2,k, | ... | μp-1,k | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | 0 | | | ||
| Σk{1→q-1}( FkTΜkD ) | = | | | μ1,1, | μ2,1, | ... | μp-1,1 | | |
| | | μ1,2, | μ2,2, | ... | μp-1,2 | | | ||
| | | : | : | ... | : | | | ||
| | | μ1,q-1, | μ2,q-1, | ... | μp-1,q-1 | | | ||
| FkTΜkFk | = | | | 0, | ... | 0, | ... | 0 | | |
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | μB,k, | ... | 0 | | | ||
| | | : | ... | : | ... | : | | | ||
| | | 0, | ... | 0, | ... | 0 | | ( k 行 k 列のみ要素を持つ行列 ) | ||
| Σk{1→q-1}( FkTΜkFk ) | = | | | μB,1, | 0, | ... | 0 | | |
| | | 0, | μB,2, | ... | 0 | | | ||
| | | : | : | ... | : | | | ||
| | | 0, | 0, | ... | μB,q-1 | | | ||
となるので、
| XTWX = | | | μ, | μA,1, | μA,2, | ... | μA,p-1, | μB,1, | μB,2, | ... | μB,q-1, | μ1,1, | μ2,1, | ... | μp-1,1, | μ1,2, | ... | μp-1,q-1 | | | |||
| | | μA,1, | μA,1, | 0, | ... | 0, | μ1,1, | μ1,2, | ... | μ1,q-1, | μ1,1, | 0, | ... | 0, | μ1,2, | ... | 0 | | | ||||
| | | μA,2, | 0, | μA,2, | ... | 0, | μ2,1, | μ2,2, | ... | μ2,q-1, | 0, | μ2,1, | ... | 0, | 0, | ... | 0 | | | ||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | ... | : | | | ||||
| | | μA,p-1, | 0, | 0, | ... | μA,p-1, | μp-1,1, | μp-1,2, | ... | μp-1,q-1, | 0, | 0, | ... | μp-1,1, | 0, | ... | μp-1,q-1 | | | ||||
| | | μB,1, | μ1,1, | μ2,1, | ... | μp-1,1, | μB,1, | 0, | ... | 0, | μ1,1, | μ2,1, | ... | μp-1,1, | 0, | ... | 0 | | | ||||
| | | μB,2, | μ1,2, | μ2,2, | ... | μp-1,2, | 0, | μB,2, | ... | 0, | 0, | 0, | ... | 0, | μ1,2, | ... | 0 | | | ||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | ... | : | | | ||||
| | | μB,q-1, | μ1,q-1, | μ2,q-1, | ... | μp-1,q-1, | 0, | 0, | ... | μB,q-1, | 0, | 0, | ... | 0, | 0, | ... | μp-1,q-1 | | | ||||
| | | μ1,1, | μ1,1, | 0, | ... | 0, | μ1,1, | 0, | ... | 0, | μ1,1, | 0, | ... | 0, | 0, | ... | 0 | | | ||||
| | | μ2,1, | 0, | μ2,1, | ... | 0, | μ2,1, | 0, | ... | 0, | 0, | μ2,1, | ... | 0, | 0, | ... | 0 | | | ||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | ... | : | | | ||||
| | | μp-1,1, | 0, | 0, | ... | μp-1,1, | μp-1,1, | 0, | ... | 0, | 0, | 0, | ... | μp-1,1, | 0, | ... | 0 | | | ||||
| | | μ1,2, | μ1,2, | 0, | ... | 0, | 0, | μ1,2, | ... | 0, | 0, | 0, | ... | 0, | μ1,2, | ... | 0 | | | ||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | ... | : | | | ||||
| | | μp-1,q-1, | 0, | 0, | ... | μp-1,q-1, | 0, | 0, | ... | μp-1,q-1, | 0, | 0, | ... | 0, | 0, | ... | μp-1,q-1 | | |
という結果が得られます。μj,k = 1 とすれば、これは ( n = 1 のときの ) 二元配置分散分析での左辺の係数行列 XTX と等しくなります。各行の式は、1 行目、2 行目からの p - 1 行分、その次の q - 1 行分、残りの行と分けた時、
となります。右辺の XTWz は
| zj,k | = | g(μj,k) + ( yj,k - μj,k )g'(μj,k) |
| = | log( μj,k / N ) + ( yj,k - μj,k ) / μj,k |
zk = ( z1,k, z2,k, ... zp,k )T
z = ( z1, z2, ... zq )T
とすれば、
| XTWz | = | | | 1pTΜ1, | 1pTΜ2, | ... | 1pTΜq-1, | 1pTΜq | || | z1 | | |
| | | DTΜ1, | DTΜ2, | ... | DTΜq-1, | DTΜq | || | z2 | | | ||
| | | F1TΜ1, | F2TΜ2, | ... | Fq-1TΜq-1, | 0q-1,p | || | : | | | ||
| | | DTΜ1, | 0p-1,p, | ... | 0p-1,p, | 0p-1,p | || | zq-1 | | | ||
| | | 0p-1,p, | DTΜ2, | ... | 0p-1,p, | 0p-1,p | || | zq | | | ||
| | | : | : | ... | : | : | | | ||||
| | | 0p-1,p, | 0p-1,p, | ... | DTΜq-1, | 0p-1,p | | | ||||
と表すことができて、
| Σk{1→q}( 1pTΜkzk ) | = | Σk{1→q}( Σj{1→p}( μj,kzj,k ) ) |
| ≡ | Sz | |
| Σk{1→q}( DTΜkzk ) | = | ( Σk{1→q}( μ1,kz1,k ), Σk{1→q}( μ2,kz2,k ), ... Σk{1→q}( μp-1,kzp-1,k ) )T |
| ≡ | ( SA,1, SA,2, ... SA,p-1 ) ≡ SA | |
| Σk{1→q-1}( FkTΜkzk ) | = | ( Σj{1→p}( μj,1zj,1 ), Σj{1→p}( μj,2zj,2 ), ... Σj{1→p}( μj,q-1zj,q-1 ) )T |
| ≡ | ( SB,1, SB,2, ... SB,q-1 ) ≡ SB | |
| DTΜkzk | = | ( μ1,kz1,k, μ2,kz2,k, ... μp,kzp-1,k )T [ 1 ≤ k ≤ q - 1 ] |
という結果が得られます。μj,k = 1 かつ zj,k = yj,k ならば、これも二元配置分散分析と全く同じ式になります。それぞれの正規方程式は
となり、(2), (3) の左辺は
| μA,ja0 + μA,jaj + Σk{1→q-1}( μj,kbk ) + Σk{1→q-1}( μj,kgj,k ) | |
| = | Σk{1→q-1}( μj,k( a0 + aj ) ) + μj,q( a0 + aj ) + Σk{1→q-1}( μj,kbk ) + Σk{1→q-1}( μj,kgj,k ) |
| = | Σk{1→q-1}( μj,k( a0 + aj + bk + gj,k ) ) + μj,q( a0 + aj ) |
| = | Σk{1→q-1}( μj,kzj,k ) + μj,q( a0 + aj ) |
| μB,ka0 + Σj{1→p-1}( μj,kaj ) + μB,kbk + Σj{1→p-1}( μj,kgj,k ) | |
| = | Σj{1→p-1}( μj,kzj,k ) + μp,k( a0 + bk ) |
なので、(2) の左辺を j = 1 から p - 1 まで加算すると、
| Σj{1→p-1}( Σk{1→q-1}( μj,kzj,k ) + μj,q( a0 + aj ) ) | |
| = | Σj{1→p-1}( Σk{1→q-1}( μj,kzj,k ) ) + ( μB,q - μp,q )a0 + Σj{1→p-1}( μj,qaj ) |
(3) の左辺を k = 1 から q - 1 まで加算すると、
| Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) + μp,k( a0 + bk ) ) | |
| = | Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) + ( μA,p - μp,q )a0 + Σk{1→q-1}( μp,kbk ) |
であり、両者を加算すると
| 2Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) + ( μA,p + μB,q - 2μp,q )a0 |
| + Σj{1→p-1}( μj,qaj ) + Σk{1→q-1}( μp,kbk ) |
となります。(1) は
| ||||||||||||
|
より
| μa0 + Σj{1→p-1}( μA,jaj ) + Σk{1→q-1}( μB,kbk ) + Σk{1→q-1}( Σj{1→p-1}( μj,kgj,k ) ) | |
| = | Σk{1→q-1}( Σj{1→p-1}( μj,ka0 + μj,kaj + μj,kbk + μj,kgj,k ) ) |
| + ( μA,p + μB,q - μp,q )a0 + Σj{1→p-1}( μj,qaj ) + Σk{1→q-1}( μp,kbk ) | |
| = | Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) + ( μA,p + μB,q - μp,q )a0 |
| + Σj{1→p-1}( μj,qaj ) + Σk{1→q-1}( μp,kbk ) |
なので、(2), (3) の加算結果を減算すると
| Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) + ( μA,p + μB,q - μp,q )a0 | |
| + Σj{1→p-1}( μj,qaj ) + Σk{1→q-1}( μp,kbk ) | |
| - 2Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) - ( μA,p + μB,q - 2μp,q )a0 | |
| - Σj{1→p-1}( μj,qaj ) - Σk{1→q-1}( μp,kbk ) | |
| = | -Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) + μp,qa0 |
という結果が得られます。右辺は
| Sz - Σj{1→p-1}( SA,j ) - Σk{1→q-1}( SB,k ) | |
| = | Σk{1→q}( Σj{1→p}( μj,kzj,k ) ) - Σj{1→p-1}( Σk{1→q}( μj,kzj,k ) ) - Σk{1→q-1}( Σj{1→p}( μj,kzj,k ) ) |
| = | Σk{1→q}( μp,kzp,k ) - Σj{1→p}( Σk{1→q-1}( μj,kzj,k ) ) |
| = | -Σk{1→q-1}( Σj{1→p}( μj,kzj,k ) - μp,kzp,k ) + μp,qzp,q |
| = | -Σk{1→q-1}( Σj{1→p-1}( μj,kzj,k ) ) + μp,qzp,q |
なので
となり、これは二元配置分散分析において a0 = mp,q となることに対応します。これを (2), (3) に代入すれば
より
で、二元配置分散分析において aj = mj,q - mp,q、bk = mp,k - mp,q となることに対応し、(4) より
| gj,k | = | zj,k - a0 - aj - bk |
| = | zj,k - zp,q - ( zj,q - zp,q ) - ( zp,k - zp,q ) | |
| = | ( zj,k - zp,k ) - ( zj,q - zp,q ) |
となるので、二元配置分散分析において gj,k = ( mj,k - mp,k ) - ( mj,q - mp,q ) となることに対応します。これらの最尤推定量を使って求められる対数尤度統計量は、二元配置分散分析における誤差変動 DE に対応します。このように、計数データに多項分布や積多項分布と対数関数を組み合わせたモデルは分散分析と非常によく似た性質を持っていますが、右辺には μj,k が存在してこの中にも係数 α が (しかも線形式ではない状態で) 含まれているので、分散分析のときのように連立方程式を解く ことはできません。従って、スコア法を利用して係数を求める必要があります。これは、交互作用効果 gj,k を含む独立変数を除外した縮小モデル (加法モデル) でも同様です。
最小モデルは
となるので θj,k が全て等しいことになります。しかし、θj,k の総和は 1 なので、θj,k = 1 / pq ( α0 = -log pq ) であり、従って μj,k = N / pq になります。
ポアソン回帰を含め、今まで紹介したモデルはすべて連結関数に対数関数を用いてきました。計数データの場合、線形式の値に関係なく μ は正の数となるので、対数関数を用いることは非常に都合がいいことになります。特に、指数型分布族にポアソン分布を仮定すれば回帰方程式も比較的シンプルな形にすることができます。このような形式の一般化線形モデルは「対数線形モデル (Log-linear Model)」と呼ばれます。
前節で示したサンプル・プログラム PoissonRegression を使って、参考文献にあったデータを処理してみたいと思います。このデータは、悪性黒色腫と呼ばれる皮膚がんの患者数を、三つの部位 ( 頭頸部・体幹部・四肢 ) と四つの病型 ( ハッチンソン黒色斑・表在拡大型黒色腫・結節型黒色腫・不明 ) の組み合わせごとに分類した結果です。患者数は 400 名と固定されているので、各数は N = 400 とした多項分布に従うと解釈することができます。
| 病型 | 部位 | |||
|---|---|---|---|---|
| 頭頸部 | 体幹部 | 四肢 | 計 | |
| ハッチンソン黒色斑 | 22 | 2 | 10 | 34 |
| 表在拡大型黒色腫 | 16 | 54 | 115 | 185 |
| 結節型黒色腫 | 19 | 33 | 73 | 125 |
| 不明 | 11 | 17 | 28 | 56 |
| 計 | 68 | 106 | 226 | 400 |
まずは、このデータに飽和モデルを適用して係数の最尤推定量を計算してみます ( verbose = true にして冗長モードで出力しています )。
*** Poisson Regression ***
ni = ( 400, 400, 400, 400, 400, 400, 400, 400, 400, 400, 400, 400 )
*** Scoring Method ***
Exponential Family of Distribution : Poisson Distribution
Link Function : Logarithm Function ( for Poisson Regression )
N = 12; p = 12
x = ( 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0 )
( 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0 )
( 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0 )
( 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0 )
( 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0 )
( 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0 )
( 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0 )
( 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1 )
( 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0 )
( 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 )
( 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 )
( 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 )
y = ( 22, 2, 10, 16, 54, 115, 19, 33, 73, 11, 17, 28 )
----- cnt = 0 -----
mu = ( 22, 2, 10, 16, 54, 115, 19, 33, 73, 11, 17, 28 )
g'(mu) = ( 0.0454545, 0.5, 0.1, 0.0625, 0.0185185, 0.00869565, 0.0526316, 0.030303, 0.0136986, 0.0909091, 0.0588235, 0.0357143 )
w = ( 0.0454545, 0.5, 0.1, 0.0625, 0.0185185, 0.00869565, 0.0526316, 0.030303, 0.0136986, 0.0909091, 0.0588235, 0.0357143 )
Equation System :
(400)x0 + (68)x1 + (106)x2 + (34)x3 + (185)x4 + (125)x5 + (22)x6 + (2)x7 + (16)x8 + (54)x9 + (19)x10 + (33)x11 = -846.361
(68)x0 + (68)x1 + (0)x2 + (22)x3 + (16)x4 + (19)x5 + (22)x6 + (0)x7 + (16)x8 + (0)x9 + (19)x10 + (0)x11 = -212.734
(106)x0 + (0)x1 + (106)x2 + (2)x3 + (54)x4 + (33)x5 + (0)x6 + (2)x7 + (0)x8 + (54)x9 + (0)x10 + (33)x11 = -254.754
(34)x0 + (22)x1 + (2)x2 + (34)x3 + (0)x4 + (0)x5 + (22)x6 + (2)x7 + (0)x8 + (0)x9 + (0)x10 + (0)x11 = -111.295
(185)x0 + (16)x1 + (54)x2 + (0)x3 + (185)x4 + (0)x5 + (0)x6 + (0)x7 + (16)x8 + (54)x9 + (0)x10 + (0)x11 = -302.987
(125)x0 + (19)x1 + (33)x2 + (0)x3 + (0)x4 + (125)x5 + (0)x6 + (0)x7 + (0)x8 + (0)x9 + (19)x10 + (33)x11 = -264.4
(22)x0 + (22)x1 + (0)x2 + (22)x3 + (0)x4 + (0)x5 + (22)x6 + (0)x7 + (0)x8 + (0)x9 + (0)x10 + (0)x11 = -63.8093
(2)x0 + (0)x1 + (2)x2 + (2)x3 + (0)x4 + (0)x5 + (0)x6 + (2)x7 + (0)x8 + (0)x9 + (0)x10 + (0)x11 = -10.5966
(16)x0 + (16)x1 + (0)x2 + (0)x3 + (16)x4 + (0)x5 + (0)x6 + (0)x7 + (16)x8 + (0)x9 + (0)x10 + (0)x11 = -51.502
(54)x0 + (0)x1 + (54)x2 + (0)x3 + (54)x4 + (0)x5 + (0)x6 + (0)x7 + (0)x8 + (54)x9 + (0)x10 + (0)x11 = -108.134
(19)x0 + (19)x1 + (0)x2 + (0)x3 + (0)x4 + (19)x5 + (0)x6 + (0)x7 + (0)x8 + (0)x9 + (19)x10 + (0)x11 = -57.8935
(33)x0 + (0)x1 + (33)x2 + (0)x3 + (0)x4 + (33)x5 + (0)x6 + (0)x7 + (0)x8 + (0)x9 + (0)x10 + (33)x11 = -82.3336
Regression equation : y = -2.65926x0 + -0.934309x1 + -0.498991x2 + -1.02962x3 + 1.41273x4 + 0.958255x5 + 1.72277x6 + -1.11045x7 + -1.03803x8 + -0.256957x9 + -0.411711x10 + -0.294961x11
----- cnt = 1 -----
mu = ( 22, 2, 10, 16, 54, 115, 19, 33, 73, 11, 17, 28 )
g'(mu) = ( 0.0454545, 0.5, 0.1, 0.0625, 0.0185185, 0.00869565, 0.0526316, 0.030303, 0.0136986, 0.0909091, 0.0588235, 0.0357143 )
w = ( 0.0454545, 0.5, 0.1, 0.0625, 0.0185185, 0.00869565, 0.0526316, 0.030303, 0.0136986, 0.0909091, 0.0588235, 0.0357143 )
Equation System :
(400)x0 + (68)x1 + (106)x2 + (34)x3 + (185)x4 + (125)x5 + (22)x6 + (2)x7 + (16)x8 + (54)x9 + (19)x10 + (33)x11 = -846.361
(68)x0 + (68)x1 + (0)x2 + (22)x3 + (16)x4 + (19)x5 + (22)x6 + (0)x7 + (16)x8 + (0)x9 + (19)x10 + (0)x11 = -212.734
(106)x0 + (0)x1 + (106)x2 + (2)x3 + (54)x4 + (33)x5 + (0)x6 + (2)x7 + (0)x8 + (54)x9 + (0)x10 + (33)x11 = -254.754
(34)x0 + (22)x1 + (2)x2 + (34)x3 + (0)x4 + (0)x5 + (22)x6 + (2)x7 + (0)x8 + (0)x9 + (0)x10 + (0)x11 = -111.295
(185)x0 + (16)x1 + (54)x2 + (0)x3 + (185)x4 + (0)x5 + (0)x6 + (0)x7 + (16)x8 + (54)x9 + (0)x10 + (0)x11 = -302.987
(125)x0 + (19)x1 + (33)x2 + (0)x3 + (0)x4 + (125)x5 + (0)x6 + (0)x7 + (0)x8 + (0)x9 + (19)x10 + (33)x11 = -264.4
(22)x0 + (22)x1 + (0)x2 + (22)x3 + (0)x4 + (0)x5 + (22)x6 + (0)x7 + (0)x8 + (0)x9 + (0)x10 + (0)x11 = -63.8093
(2)x0 + (0)x1 + (2)x2 + (2)x3 + (0)x4 + (0)x5 + (0)x6 + (2)x7 + (0)x8 + (0)x9 + (0)x10 + (0)x11 = -10.5966
(16)x0 + (16)x1 + (0)x2 + (0)x3 + (16)x4 + (0)x5 + (0)x6 + (0)x7 + (16)x8 + (0)x9 + (0)x10 + (0)x11 = -51.502
(54)x0 + (0)x1 + (54)x2 + (0)x3 + (54)x4 + (0)x5 + (0)x6 + (0)x7 + (0)x8 + (54)x9 + (0)x10 + (0)x11 = -108.134
(19)x0 + (19)x1 + (0)x2 + (0)x3 + (0)x4 + (19)x5 + (0)x6 + (0)x7 + (0)x8 + (0)x9 + (19)x10 + (0)x11 = -57.8935
(33)x0 + (0)x1 + (33)x2 + (0)x3 + (0)x4 + (33)x5 + (0)x6 + (0)x7 + (0)x8 + (0)x9 + (0)x10 + (33)x11 = -82.3336
Regression equation : y = -2.65926x0 + -0.934309x1 + -0.498991x2 + -1.02962x3 + 1.41273x4 + 0.958255x5 + 1.72277x6 + -1.11045x7 + -1.03803x8 + -0.256957x9 + -0.411711x10 + -0.294961x11
Estimated regression equation : y = -2.65926x0 + -0.934309x1 + -0.498991x2 + -1.02962x3 + 1.41273x4 + 0.958255x5 + 1.72277x6 + -1.11045x7 + -1.03803x8 + -0.256957x9 + -0.411711x10 + -0.294961x11
variance of a = ( 0.0357143, 0.126623, 0.0945378, 0.135714, 0.0444099, 0.0494129, 0.272078, 0.694538, 0.197819, 0.121752, 0.192954, 0.138539 )
このデータは列 j が 3 個、行 k が 4 個で、基準となるカテゴリは ( j, k ) = ( 3, 4 ) としています。デザイン行列は 3 x 4 = 12 行、1 + ( 3 - 1 ) + ( 4 - 1 ) + ( 3 - 1 ) x ( 4 - 1 ) = 12 列で、実際の要素はサンプル・プログラムの出力結果で確認することができます。指数型分布族として使用するポアソン分布のパラメータ ni は全て 400 として計算しています。各独立変数 x0 から x11 はそれぞれ
を表します。回帰式を使って ( j, k ) = ( 3, 4 ) すなわち基準カテゴリ ( 部位 = 四肢 ; 病型 = 不明 ) の期待値を求めると
なので
となって観測値と一致します。( j, k ) = ( 1, 1 ) ( 部位 = 頭頸部 ; 病型 = ハッチンソン黒色斑 ) では
なので
であり、やはり観測値と一致します。このように、飽和モデルでは期待値が観測値と完全に一致します。飽和モデルの回帰係数は
なので、log( μj,k / N ) は
となって、全て zj,k と等しくなります。
より
なので、μj,k = yj,k が成り立ち、スコア法の結果と一致します。
次に、加法モデルを適用して係数の最尤推定量を計算すると以下の結果が得られます ( verbose = true にして冗長モードで出力しています )。
*** Poisson Regression ***
ni = ( 400, 400, 400, 400, 400, 400, 400, 400, 400, 400, 400, 400 )
*** Scoring Method ***
Exponential Family of Distribution : Poisson Distribution
Link Function : Logarithm Function ( for Poisson Regression )
N = 12; p = 6
x = ( 1, 1, 0, 1, 0, 0 )
( 1, 0, 1, 1, 0, 0 )
( 1, 0, 0, 1, 0, 0 )
( 1, 1, 0, 0, 1, 0 )
( 1, 0, 1, 0, 1, 0 )
( 1, 0, 0, 0, 1, 0 )
( 1, 1, 0, 0, 0, 1 )
( 1, 0, 1, 0, 0, 1 )
( 1, 0, 0, 0, 0, 1 )
( 1, 1, 0, 0, 0, 0 )
( 1, 0, 1, 0, 0, 0 )
( 1, 0, 0, 0, 0, 0 )
y = ( 22, 2, 10, 16, 54, 115, 19, 33, 73, 11, 17, 28 )
----- cnt = 0 -----
mu = ( 22, 2, 10, 16, 54, 115, 19, 33, 73, 11, 17, 28 )
g'(mu) = ( 0.0454545, 0.5, 0.1, 0.0625, 0.0185185, 0.00869565, 0.0526316, 0.030303, 0.0136986, 0.0909091, 0.0588235, 0.0357143 )
w = ( 0.0454545, 0.5, 0.1, 0.0625, 0.0185185, 0.00869565, 0.0526316, 0.030303, 0.0136986, 0.0909091, 0.0588235, 0.0357143 )
Equation System :
(400)x0 + (68)x1 + (106)x2 + (34)x3 + (185)x4 + (125)x5 = -846.361
(68)x0 + (68)x1 + (0)x2 + (22)x3 + (16)x4 + (19)x5 = -212.734
(106)x0 + (0)x1 + (106)x2 + (2)x3 + (54)x4 + (33)x5 = -254.754
(34)x0 + (22)x1 + (2)x2 + (34)x3 + (0)x4 + (0)x5 = -111.295
(185)x0 + (16)x1 + (54)x2 + (0)x3 + (185)x4 + (0)x5 = -302.987
(125)x0 + (19)x1 + (33)x2 + (0)x3 + (0)x4 + (125)x5 = -264.4
Regression equation : y = -2.56211x0 + -1.09147x1 + -0.717314x2 + 0.0371766x3 + 1.22812x4 + 0.802184x5
----- cnt = 1 -----
mu = ( 10.7517, 15.6303, 32.0253, 35.375, 51.4267, 105.369, 23.1055, 33.5897, 68.8228, 10.3593, 15.0599, 30.8566 )
g'(mu) = ( 0.0930087, 0.0639782, 0.0312253, 0.0282685, 0.0194452, 0.00949043, 0.0432798, 0.029771, 0.0145301, 0.0965315, 0.0664014, 0.032408 )
w = ( 0.0930087, 0.0639782, 0.0312253, 0.0282685, 0.0194452, 0.00949043, 0.0432798, 0.029771, 0.0145301, 0.0965315, 0.0664014, 0.032408 )
Equation System :
(432.372)x0 + (79.5915)x1 + (115.707)x2 + (58.4074)x3 + (192.171)x4 + (125.518)x5 = -971.159
(79.5915)x0 + (79.5915)x1 + (0)x2 + (10.7517)x3 + (35.375)x4 + (23.1055)x5 = -240.006
(115.707)x0 + (0)x1 + (115.707)x2 + (15.6303)x3 + (51.4267)x4 + (33.5897)x5 = -298.474
(58.4074)x0 + (10.7517)x1 + (15.6303)x2 + (58.4074)x3 + (0)x4 + (0)x5 = -194.829
(192.171)x0 + (35.375)x1 + (51.4267)x2 + (0)x3 + (192.171)x4 + (0)x5 = -339.025
(125.518)x0 + (23.1055)x1 + (33.5897)x2 + (0)x3 + (0)x4 + (125.518)x5 = -270.734
Regression equation : y = -2.53886x0 + -1.19039x1 + -0.754493x2 + -0.375803x3 + 1.19571x4 + 0.802959x5
----- cnt = 2 -----
mu = ( 6.59568, 10.1992, 21.689, 31.751, 49.0982, 104.409, 21.4382, 33.1511, 70.4968, 9.60437, 14.8517, 31.5827 )
g'(mu) = ( 0.151614, 0.0980466, 0.0461063, 0.0314951, 0.0203673, 0.00957772, 0.0466456, 0.030165, 0.014185, 0.104119, 0.0673322, 0.0316629 )
w = ( 0.151614, 0.0980466, 0.0461063, 0.0314951, 0.0203673, 0.00957772, 0.0466456, 0.030165, 0.014185, 0.104119, 0.0673322, 0.0316629 )
Equation System :
(404.867)x0 + (69.3893)x1 + (107.3)x2 + (38.4839)x3 + (185.258)x4 + (125.086)x5 = -888.832
(69.3893)x0 + (69.3893)x1 + (0)x2 + (6.59568)x3 + (31.751)x4 + (21.4382)x5 = -207.459
(107.3)x0 + (0)x1 + (107.3)x2 + (10.1992)x3 + (49.0982)x4 + (33.1511)x5 = -273.184
(38.4839)x0 + (6.59568)x1 + (10.1992)x2 + (38.4839)x3 + (0)x4 + (0)x5 = -132.198
(185.258)x0 + (31.751)x1 + (49.0982)x2 + (0)x3 + (185.258)x4 + (0)x5 = -323.928
(125.086)x0 + (21.4382)x1 + (33.1511)x2 + (0)x3 + (0)x4 + (125.086)x5 = -267.755
Regression equation : y = -2.53707x0 + -1.20087x1 + -0.757068x2 + -0.491626x3 + 1.195x4 + 0.802962x5
----- cnt = 3 -----
mu = ( 5.82349, 9.07662, 19.3515, 31.4541, 49.0251, 104.522, 21.2528, 33.125, 70.6231, 9.52124, 14.84, 31.6392 )
g'(mu) = ( 0.171718, 0.110173, 0.0516756, 0.0317923, 0.0203977, 0.00956734, 0.0470527, 0.0301886, 0.0141597, 0.105028, 0.0673853, 0.0316064 )
w = ( 0.171718, 0.110173, 0.0516756, 0.0317923, 0.0203977, 0.00956734, 0.0470527, 0.0301886, 0.0141597, 0.105028, 0.0673853, 0.0316064 )
Equation System :
(400.254)x0 + (68.0516)x1 + (106.067)x2 + (34.2516)x3 + (185.002)x4 + (125.001)x5 = -873.139
(68.0516)x0 + (68.0516)x1 + (0)x2 + (5.82349)x3 + (31.4541)x4 + (21.2528)x5 = -202.634
(106.067)x0 + (0)x1 + (106.067)x2 + (9.07662)x3 + (49.0251)x4 + (33.125)x5 = -268.744
(34.2516)x0 + (5.82349)x1 + (9.07662)x2 + (34.2516)x3 + (0)x4 + (0)x5 = -117.854
(185.002)x0 + (31.4541)x1 + (49.0251)x2 + (0)x3 + (185.002)x4 + (0)x5 = -323.173
(125.001)x0 + (21.2528)x1 + (33.125)x2 + (0)x3 + (0)x4 + (125.001)x5 = -267.366
Regression equation : y = -2.53704x0 + -1.20103x1 + -0.757096x2 + -0.498964x3 + 1.195x4 + 0.802962x5
----- cnt = 4 -----
mu = ( 5.78016, 9.01024, 19.2105, 31.45, 49.025, 104.525, 21.25, 33.125, 70.625, 9.52, 14.84, 31.64 )
g'(mu) = ( 0.173006, 0.110985, 0.0520548, 0.0317965, 0.0203978, 0.00956709, 0.0470588, 0.0301887, 0.0141593, 0.105042, 0.0673854, 0.0316056 )
w = ( 0.173006, 0.110985, 0.0520548, 0.0317965, 0.0203978, 0.00956709, 0.0470588, 0.0301887, 0.0141593, 0.105042, 0.0673854, 0.0316056 )
Equation System :
(400.001)x0 + (68.0002)x1 + (106)x2 + (34.0009)x3 + (185)x4 + (125)x5 = -872.262
(68.0002)x0 + (68.0002)x1 + (0)x2 + (5.78016)x3 + (31.45)x4 + (21.25)x5 = -202.428
(106)x0 + (0)x1 + (106)x2 + (9.01024)x3 + (49.025)x4 + (33.125)x5 = -268.492
(34.0009)x0 + (5.78016)x1 + (9.01024)x2 + (34.0009)x3 + (0)x4 + (0)x5 = -116.992
(185)x0 + (31.45)x1 + (49.025)x2 + (0)x3 + (185)x4 + (0)x5 = -323.166
(125)x0 + (21.25)x1 + (33.125)x2 + (0)x3 + (0)x4 + (125)x5 = -267.361
Regression equation : y = -2.53704x0 + -1.20103x1 + -0.757096x2 + -0.498991x3 + 1.195x4 + 0.802962x5
Estimated regression equation : y = -2.53704x0 + -1.20103x1 + -0.757096x2 + -0.498991x3 + 1.195x4 + 0.802962x5
variance of a = ( 0.0197819, 0.0191306, 0.0138587, 0.0472681, 0.0232625, 0.0258571 )
加法モデルでは交互作用効果が除外されるので、デザイン行列の列数は 1 + ( 3 - 1 ) + ( 4 - 1 ) = 6 列になります。回帰式を使って ( j, k ) = ( 3, 4 ) すなわち基準カテゴリ ( 部位 = 四肢 ; 病型 = 不明 ) の期待値を求めると
なので
という結果が得られます。他の組み合わせについても期待値を求めると以下のようになります。
| 病型 | 部位 | |||
|---|---|---|---|---|
| 頭頸部 | 体幹部 | 四肢 | 計 | |
| ハッチンソン黒色斑 | 5.78 | 9.01 | 19.21 | 34 |
| 表在拡大型黒色腫 | 31.45 | 49.02 | 104.53 | 185 |
| 結節型黒色腫 | 21.25 | 33.12 | 70.62 | 125 |
| 不明 | 9.52 | 14.84 | 31.64 | 56 |
| 計 | 68 | 106 | 226 | 400 |
部位 = 頭頸部 ; 病型 = ハッチンソン黒色斑を例にとると、回帰式は
です。これを繰り返せば上表が得られます。
この期待値は、各行・列の和の積を総和で割った結果と一致します。例えば ( j, k ) = ( 1, 1 ) ( 部位 = 頭頸部 ; 病型 = ハッチンソン黒色斑 ) の場合
で上表の値と等しくなります。加法モデルの回帰方程式は
となりますが、右辺の SA,j, SB,k, Sz は ( ap = bq = 0 とみなして )
| SA,j | = | Σk{1→q}( μj,kzj,k ) |
| = | Σk{1→q}( μj,klog( μj,k / N ) + ( yj,k - μj,k ) ) | |
| = | Σk{1→q}( μj,k( a0 + aj + bk ) + ( yj,k - μj,k ) ) | |
| = | μA,ja0 + μA,jaj + Σk{1→q-1}( μj,kbk ) + Σk{1→q}( yj,k - μj,k ) | |
| SB,k | = | μB,ka0 + Σj{1→p-1}( μj,kaj ) + μB,kbk + Σj{1→p}( yj,k - μj,k ) |
| Sz | = | Σk{1→q}( Σj{1→p}( μj,kzj,k ) ) |
| = | Σk{1→q}( Σj{1→p}( μj,klog( μj,k / N ) + ( yj,k - μj,k ) ) ) | |
| = | Σk{1→q}( Σj{1→p}( μj,k( a0 + aj + bk ) + ( yj,k - μj,k ) ) ) | |
| = | μa0 + Σj{1→p-1}( μA,jaj ) + Σk{1→q-1}( μB,kbk ) + Σk{1→q}( Σj{1→p}( yj,k - μj,k ) ) |
と計算することができるので、回帰方程式と比較すると
より
が成り立ちます。
として
であることを利用すると、μj,k = YA,jYB,k / N としたとき
という結果が得られ、先ほど得られた関係式を満たします。
飽和モデルの最大対数尤度を l(μ) とすると、それは各組み合わせに対するポアソン分布において μj,k = yj,k として、その積の対数を求めればよいので
| l(μ) | = | log( Πk{1→q}( Πj{1→p}( yj,kyj,ke-yj,k / yj,k! ) ) ) |
| = | Σk{1→q}( Σj{1→p}( yj,klog yj,k - yj,k - log yj,k! ) ) |
から求めることができます。実際に計算を行うと、l(μ) = -29.56 という結果が得られます。また加法モデルでは μj,k = YA,jYB,k / N なので、最大対数尤度を l(a,b) で表すと
から得られ、l(a,b) = -55.45 となります。従って、両者の差 ΔD は
です。飽和モデルの係数は 12 個あるので、l(μ) は自由度 12 の χ2分布に従い、一方、加法モデルの係数は 6 個なので自由度 6 の χ2分布に従います。従って、ΔD は自由度 12 - 6 = 6 のχ2分布に従い、ΔD = 51.78 のときの上側確率は 2.06E-9 と非常に小さく、加法モデルによる当てはめはよくない、すなわち各組み合わせが互いに独立であるという仮定が棄却されることになります。
加法モデルによる期待値と実測値を並べた表を以下に示します。() 内は実測値に対する差異を表しています。
| 病型 | 部位 | ||||||
|---|---|---|---|---|---|---|---|
| 頭頸部 | 体幹部 | 四肢 | 計 | ||||
| 実測値 | 期待値 | 実測値 | 期待値 | 実測値 | 期待値 | ||
| ハッチンソン黒色斑 | 22 | 5.78 (-16.22) | 2 | 9.01 (+7.01) | 10 | 19.21 (+9.21) | 34 |
| 表在拡大型黒色腫 | 16 | 31.45 (+15.45) | 54 | 49.02 (-4.98) | 115 | 104.53 (-10.47) | 185 |
| 結節型黒色腫 | 19 | 21.25 (+2.25) | 33 | 33.12 (+0.12) | 73 | 70.62 (-2.38) | 125 |
| 不明 | 11 | 9.52 (-1.48) | 17 | 14.84 (-2.16) | 28 | 31.64 (+3.64) | 56 |
| 計 | 68 | 106 | 226 | 400 | |||
実測値との差異が大きいのは、病型が「ハッチンソン黒色斑」と「表在拡大型黒色腫」の個所で、「ハッチンソン黒色斑」では頭頸部の部分で期待値に比べ頻発しており、「表在拡大型黒色腫」は相対的に頭頸部の頻度が小さくなっています。従って少なくともこの二つの病型については、部位との相関関係がある可能性があります。
事象ごとの発生回数が多項分布に従うとして検定を行う手法として「(ピアソンの)χ2-検定」を以前に紹介しました。下表のような、二種類の事象 A, B ごとの発生回数に対し、ピアソン・カイ二乗統計量 χ2 = Σk{1→q}( Σj{1-p}( ( yj,k - YA,jYA,k / N )2 / ( YA,jYB,k / N ) ) ) が自由度 ( p - 1 )( q - 1 ) の χ2-分布に従うことを利用して、二つの事象 A, B の独立性を検定する手法です。
| A1 | A2 | ... | Aj | ... | Ap | 計 | |
|---|---|---|---|---|---|---|---|
| B1 | y11 | y21 | ... | yj1 | ... | yp1 | YB,1 |
| B2 | y12 | y22 | ... | yj2 | ... | yp1 | YB,2 |
| : | : | : | ... | : | ... | : | : |
| Bk | y1k | y2k | ... | yjk | ... | ypk | YB,k |
| : | : | : | ... | : | ... | : | : |
| Bq | y1q | y2q | ... | yjq | ... | ypq | YB,q |
| 計 | YA,1 | YA,2 | ... | YA,j | ... | YA,p | N |
加法モデルにおいて、実測値 yj,k に対する期待値は YA,jYB,k / N となるのでした。ピアソン・カイ二乗統計量は、実測値 oi と期待値 ei について
で求められるので、加法モデルでのピアソン・カイ二乗統計量は χ2-検定でのそれと一致します。つまり、上記の例において独立性の検定を行った場合、χ2-検定とほぼ同じ結果が得られることになります。但し、対数線形モデルではピアソン・カイ二乗統計量だけではなく対数尤度統計量も検定に利用することができるところが異なります。ちなみに、ピアソン・カイ二乗統計量は表 3-3 の ()内にある実測値と期待値の差と、期待値そのものを使えば計算できて、その値は χ2 = 65.81 となります。
対数線形モデルの場合、更に複雑な検定を行うこともできます。文献にある別のサンプル・データを以下に示します。
| 部位 | アスピリン | 総計 | ||
|---|---|---|---|---|
| 使用なし | 使用あり | |||
| 胃潰瘍 | なし | 62 | 6 | 68 |
| あり | 39 | 25 | 64 | |
| 十二指腸潰瘍 | なし | 53 | 8 | 61 |
| あり | 49 | 8 | 57 | |
このデータは、胃潰瘍・十二指腸潰瘍の発症とアスピリン使用有無の関係を調査した時のデータです。ここでは、胃潰瘍・十二指腸潰瘍の発症有無ごとに 4 つのグループがあり、それぞれのサンプル数が固定となります。従って、発症の有無を表す添字 j、胃潰瘍・十二指腸潰瘍のいずれかを表す添字を k、アスピリンの使用有無を表す添字を l とし、それぞれの発生回数を yj,k,l としたとき、4 つのグループのサンプル数 nj,k は
で表され、yj,k,l は積多項分布
Πk{1→2}( Πj{1→2}( nj,k!Πl{1→2}( θj,k,lyj,k,l / yj,k,l! ) ) )
但し、Σl{1→2}( θj,k,l ) = 1
となります。回帰式を
とし、κ は定数項、xα は発症の有無を表す二値変数、xβ は胃潰瘍 ( = 0 ) と十二指腸潰瘍 ( = 1 ) を表すカテゴリ変数、xγ は発症の有無と胃潰瘍・十二指腸潰瘍の相互作用 (十二指腸潰瘍の発症ありのみ 1 )、xλ はアスピリン使用の有無、xη1 と xη2 はそれぞれ発症の有無及び胃潰瘍・十二指腸潰瘍とアスピリン使用有無の交互作用を表します。デザイン行列は以下のようになります。
| X | = | | | 1, | 0, | 0, | 0, | 0, | 0, | 0 | | |
| | | 1, | 1, | 0, | 0, | 0, | 0, | 0 | | | ||
| | | 1, | 0, | 1, | 0, | 0, | 0, | 0 | | | ||
| | | 1, | 1, | 1, | 1, | 0, | 0, | 0 | | | ||
| | | 1, | 0, | 0, | 0, | 1, | 0, | 0 | | | ||
| | | 1, | 1, | 0, | 0, | 1, | 1, | 0 | | | ||
| | | 1, | 0, | 1, | 0, | 1, | 0, | 1 | | | ||
| | | 1, | 1, | 1, | 1, | 1, | 1, | 1 | | | ||
また、従属変数ベクトル y = ( 62, 39, 53, 49, 6, 25, 8, 8 ) です。これらのデータを使ってスコア法によって処理すると以下の回帰式と回帰係数の分散値が得られます。
Estimated regression equation : y = -0.149896x0 + -0.260289x1 + 0.0726564x2 + 0.112942x3 + -1.82193x4 + 1.14288x5 + -0.700046x6 variance of a = ( 0.0165437, 0.0375758, 0.0325526, 0.0683647, 0.0948408, 0.123955, 0.119735 )
回帰式から得られる予測値と実測値の差は以下のようになります。
| 部位 | アスピリン | 総計 | ||
|---|---|---|---|---|
| 使用なし | 使用あり | |||
| 胃潰瘍 | なし | 58.53(-3.47) | 9.47(3.47) | 68 |
| あり | 42.47(3.47) | 21.53(-3.47) | 64 | |
| 十二指腸潰瘍 | なし | 56.47(3.47) | 4.53(-3.47) | 61 |
| あり | 45.53(-3.47) | 11.47(3.47) | 57 | |
このモデル式から xη2 ( 胃潰瘍・十二指腸潰瘍とアスピリン使用有無の交互作用 )、xη1 ( 発症の有無とアスピリン使用有無の交互作用 )、xλ ( アスピリン使用の有無 ) の順で一つずつ変数を除去してスコア法にて回帰係数を求めると、以下のような結果になります。
■ 胃潰瘍・十二指腸潰瘍とアスピリン使用有無の交互作用を除去 (モデル 2) Estimated regression equation : y = -0.11488x0 + -0.203573x1 + 9.31899e-16x2 + 3.55945e-11x3 + -2.10587x4 + 1.12505x5 variance of a = ( 0.0156496, 0.0343737, 0.0310993, 0.0642679, 0.0801242, 0.12179 ) ■ 発症の有無とアスピリン使用有無の交互作用を除去 (モデル 3) Estimated regression equation : y = -0.208255x0 + 1.4785e-10x1 + -5.77581e-11x2 + -1.50665e-10x3 + -1.46306x4 variance of a = ( 0.0156318, 0.0303302, 0.0310988, 0.064267, 0.0262006 ) ■ アスピリン使用の有無を除去 (モデル 4) Estimated regression equation : y = -0.693147x0 + -3.48683e-12x1 + -3.41539e-12x2 + 3.44528e-12x3 variance of a = ( 0.0147058, 0.0303308, 0.0310993, 0.0642681 )
回帰式から得られる予測値と実測値の差は以下の通りです。
| 部位 | アスピリン | 総計 | ||
|---|---|---|---|---|
| 使用なし | 使用あり | |||
| モデル 2 | ||||
| 胃潰瘍 | なし | 60.62(-1.38) | 7.38(1.38) | 68 |
| あり | 46.55(7.55) | 17.45(-7.55) | 64 | |
| 十二指腸潰瘍 | なし | 54.38(1.38) | 6.62(-1.38) | 61 |
| あり | 41.45(-7.55) | 15.55(7.55) | 57 | |
| モデル 3 | ||||
| 胃潰瘍 | なし | 55.22(-6.78) | 12.78(6.78) | 68 |
| あり | 51.97(12.97) | 12.03(-12.97) | 64 | |
| 十二指腸潰瘍 | なし | 49.53(-3.47) | 11.47(3.47) | 61 |
| あり | 46.28(-2.72) | 10.72(2.72) | 57 | |
| モデル 4 | ||||
| 胃潰瘍 | なし | 34.00(-28.00) | 34.00(28.00) | 68 |
| あり | 32.00(-7.00) | 32.00(7.00) | 64 | |
| 十二指腸潰瘍 | なし | 30.50(-22.50) | 30.50(22.50) | 61 |
| あり | 28.50(-20.50) | 28.50(20.50) | 57 | |
予測値が得られれば、対数尤度
| l | = | Σl{1→2}( Σk{1→2}( Σj{1→2}( log( μj,k,lyj,k,l e-μj,k,l / yj,k,l! ) ) ) ) |
| = | Σl{1→2}( Σk{1→2}( Σj{1→2}( yj,k,llog μj,k,l - μj,k,l - log yj,k,l! ) ) ) |
に対して求めた予測値 μj,k,l を代入して各モデルごとの差を計算すれば対数尤度統計量を得ることができます。各モデル式での回帰係数の数と対数尤度は以下の通りです。なお、飽和モデルでは μj,k,l = yj,k,l なので、実測値をそのまま当てはめれば求めることができます。
| モデル式 | 回帰係数の数 | 対数尤度 |
|---|---|---|
| 飽和モデル | 8 | -19.81 |
| モデル 1 | 7 | -22.95 |
| モデル 2 | 6 | -25.08 |
| モデル 3 | 5 | -30.70 |
| モデル 4 | 4 | -83.16 |
発症の有無とアスピリン使用有無の交互作用を調べるにはモデル 2 とモデル 3 の対数尤度統計量を計算すればよいので、その値を Dη1 としたとき
となります。回帰係数の数の差は 1 なので Dη1 は自由度 1 のカイ二乗分布に従うことになり、11.25 に対する上側確率 (p値) は 0.001 より小さな値なので、発症がアスピリンの使用に影響を受けていると判断することができます。同様に、胃潰瘍・十二指腸潰瘍とアスピリン使用有無の交互作用を調べるにはモデル 2 とモデル 3 の対数尤度統計量を計算すればよく、その値を Dη2 とすれば
です。この値も自由度 1 のカイ二乗分布に従い、p 値が 0.039 となることからアスピリンの使用に対して胃潰瘍と十二指腸潰瘍の間でわずかながら差異があると判断できます。しかし、モデル 1 と飽和モデルの間の統計尤度統計量を D0 としたとき、
であり、飽和モデルに対してパラメータがわずか一つしか少なくないにもかかわらず比較的大きな値となっています。これは、このモデル式の当てはめがあまりよくないことを意味しています。
今回は、計数データに対して有効な一般化線形モデルとして「ポアソン回帰」と「対数線形モデル」と紹介し、特に分散分析と比較したときの相違点について細かく見てきました。こうして調べてみると、重回帰分析からの一連の推定・検定が一般化線形モデルという枠組みの中で一つにまとまることがわかってきて、なかなか興味深いです。
以下の行列 V に対する逆行列を M として、M を求める方法を検討してみます。
| V = XTX | = | | | N, | n1, | n2, | ... | np-1 | | |
| | | n1, | n1, | 0, | ... | 0 | | | ||
| | | n2, | 0, | n2, | ... | 0 | | | ||
| | | : | : | : | ... | : | | | ||
| | | np-2, | 0, | 0, | ... | 0 | | | ||
| | | np-1, | 0, | 0, | ... | np-1 | | | ||
対角成分が 1 でそれ以外は 0 になるような行列になる必要があることから、二行目以降の行ベクトル vrT ( 2 ≤ r ≤ p ) と M の列ベクトル mc ( 1 ≤ c ≤ p ) の積は
である必要があります。但し δrc は「クロネッカーのデルタ (Kronecker Delta)」で、r = c のときのみ 1 でそれ以外は 0 になります。M の r 行 c 列の成分を mrc として積を計算すると、
なので、r ≠ c ならば mrc = -m1c、r = c ならば mrc = ( 1 - nr-1m1c ) / nr-1 を満たす必要があります。
次に v1T と m1 の積 v1Tm1 を計算すると
となりますが、N = Σr{1→p}( nr ) であり、r ≠ 1 ならば mr1 = -m11 なので右辺は npm11 であり、これが 1 に等しいことから
となることがわかります。ところで V は対称行列なので、その逆行列 M も対称行列です (*n1-1)。従って、
となって 1 行目の成分が決まり、さらに
より非対角成分全てが決まります。最後に、
より対角成分が求められ、逆行列 M は
| M | = | | | 1 / np, | -1 / np, | -1 / np, | ... | -1 / np | | |
| | | -1 / np, | ( n1 + np ) / n1np, | 1 / np, | ... | 1 / np | | | ||
| | | -1 / np, | 1 / np, | ( n2 + np ) / n2np, | ... | 1 / np | | | ||
| | | : | : | : | ... | : | | | ||
| | | -1 / np, | 1 / np, | 1 / np, | ... | 1 / np | | | ||
| | | -1 / np, | 1 / np, | 1 / np, | ... | ( np-1 + np ) / np-1np | | | ||
となります。
*n1-1) 「固有値問題 (2) カルーネン・レーベ展開」の「4) 主成分分析」にて後半部分で証明しています
二元配置分散分析の場合、XTX は以下のようになるのでした。
| XTX | = n | | | pq, | q1p-1T, | p1q-1T | | | 1p-1T, | 1p-1T, | ... | 1p-1T | | |
| | | q1p-1, | qEp-1, | NT | | | Ep-1, | Ep-1, | ... | Ep-1 | | | ||
| | | p1q-1, | N, | pEq-1 | | | F1T, | F2T, | ... | Fq-1T | | | ||
| | | 1p-1, | Ep-1, | F1 | | | Ep-1, | 0p-1, | ... | 0p-1 | | | ||
| | | 1p-1, | Ep-1, | F2 | | | 0p-1, | Ep-1, | ... | 0p-1 | | | ||
| | | : | : | : | | | : | : | ... | : | | | ||
| | | 1p-1, | Ep-1, | Fq-1 | | | 0p-1, | 0p-1, | ... | Ep-1 | | | ||
但し、1n は全要素が 1 の n 次元ベクトル、En は大きさ n の単位行列、0n は大きさ n の正方零行列、Fk は k 列目のみが 1 で残りはゼロの p - 1 行 q - 1 列行列、N は全要素が 1 の q - 1 行 p - 1 列行列をそれぞれ表します。行列方向に q + 2 個ずつのブロックを持ったこの行列を 3 対 q - 1 個ずつのブロックに分け (上記の仕切り線を参照)、
| XTX | = n | | | P, | QT | | |
| | | Q, | E(p-1)(q-1) | | | ||
とします。ここで、P は p + q - 1 の大きさの正方行列、Q は ( p - 1 )( q - 1 ) 行 p + q - 1 列の行列です。k ≠ 0 である任意の実数 k に対して、M が逆行列を持つならば明らかに ( kM )-1 = (1/k)M-1 なので、各ブロックの行列数が等しいように、XTX の逆行列を以下のように定義します。
| ( XTX )-1 | = (1/n) | | | A, | BT | | |
| | | B, | C | | | ||
このとき、
| PA + QTB = Ep+q-1 | --- (1) |
| QBT + C = E(p-1)(q-1) | --- (2) |
| QA + B = 0(p-1)(q-1),p+q-1 | --- (3) |
| PBT + QTC = 0p+q-1,(p-1)(q-1) | --- (4) |
が成り立ちます。但し、0r,c は r 行 c 列の零行列です。(3) より B = -QA を (1) に代入すると
であり、QTQ は
| QTQ = |
| ||||||||||||||||||||||||||||||||||||||||
| = |
| ||||||||||||||||||||||||||||||||||||||||
| = |
| ||||||||||||||||||||||||||||||||||||||||
なので、
| P - QTQ | = | | | p + q - 1, | 1p-1T, | 1q-1T | | |
| | | 1p-1, | Ep-1, | 0p-1,q-1 | | | ||
| | | 1q-1, | 0q-1,p-1, | Eq-1 | | | ||
となります。これはちょうど、補足 1 の行列にて ni = 1 ( 1 ≤ i ≤ p + q - 1 ) とした場合に相当し、その逆行列は
| = | | | 1, | -1, | -1, | ... | -1 | | |
| | | -1, | 2, | 1, | ... | 1 | | | |
| | | -1, | 1, | 2, | ... | 1 | | | |
| | | : | : | : | ... | : | | | |
| | | -1, | 1, | 1, | ... | 2 | | |
| = | | | 1, | -1p-1T, | -1q-1T | | |
| | | -1p-1, | Np-1 + Ep-1, | NT | | | |
| | | -1q-1, | N, | Nq-1 + Eq-1 | | |
となって ( Nn は大きさが n で全要素が 1 の正方行列とします )、これが A と等しくなります。これを (3) に代入すれば
| B = -QA = |
| ||||||||||||||||||||||||||||||||||||
| = |
| ||||||||||||||||||||||||||||||||||||
| = |
|
となり、(2) に代入すれば
| C = | E(p-1)(q-1) - QBT | |||||||||||||||||||||||||||||||||||||||
| = |
| |||||||||||||||||||||||||||||||||||||||
| = |
| |||||||||||||||||||||||||||||||||||||||
| = |
|
となるので、
| ( XTX )-1 | = (1/n) | | | 1, | -1p-1T, | -1q-1T, | 1p-1T, | 1p-1T, | ... | 1p-1T | | |
| | | -1p-1, | Np-1 + Ep-1, | NT, | -( Np-1 + Ep-1 ), | -( Np-1 + Ep-1 ), | ... | -( Np-1 + Ep-1 ) | | | ||
| | | -1q-1, | N, | Nq-1 + Eq-1, | -( N + F1T ), | -( N + F2T ), | ... | -( N + Fq-1T ) | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + F1 ) | 2( Np-1 + Ep-1 ), | Np-1 + Ep-1, | ... | Np-1 + Ep-1 | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + F2 ) | Np-1 + Ep-1, | 2( Np-1 + Ep-1 ), | ... | Np-1 + Ep-1 | | | ||
| | | : | : | : | : | : | ... | : | | | ||
| | | 1p-1, | -( Np-1 + Ep-1 ), | -( NT + Fq-1 ) | Np-1 + Ep-1, | Np-1 + Ep-1, | ... | 2( Np-1 + Ep-1 ) | | | ||
| < | ( p - 1 )( q - 1 ) 列 | > | |||||||||||||||||||||||||||||
| <1 列> | < | p-1 列 | > | < | q-1 列 | > | < | p-1 列 | > | < | p-1 列 | > | < | p-1 列 | > | ||||||||||||||||
| = (1/n) | | | 1, | -1, | -1, | ... | -1, | -1, | -1, | ... | -1, | 1, | 1, | ... | 1, | 1, | 1, | ... | 1, | ... | 1, | 1, | ... | 1 | | | 1 行 | ||||||
| | | -1, | 2, | 1, | ... | 1, | 1, | 1, | ... | 1, | -2, | -1, | ... | -1, | -2, | -1, | ... | -1, | ... | -2, | -1, | ... | -1 | | | p-1 行 | |||||||
| | | -1, | 1, | 2, | ... | 1, | 1, | 1, | ... | 1, | -1, | -2, | ... | -1, | -1, | -2, | ... | -1, | ... | -1, | -2, | ... | -1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | -1, | 1, | 1, | ... | 2, | 1, | 1, | ... | 1, | -1, | -1, | ... | -2, | -1, | -1, | ... | -2, | ... | -1, | -1, | ... | -2 | | | ||||||||
| | | -1, | 1, | 1, | ... | 1, | 2, | 1, | ... | 1, | -2, | -2, | ... | -2, | -1, | -1, | ... | -1, | ... | -1, | -1, | ... | -1 | | | q-1 行 | |||||||
| | | -1, | 1, | 1, | ... | 1, | 1, | 2, | ... | 1, | -1, | -1, | ... | -1, | -2, | -2, | ... | -2, | ... | -1, | -1, | ... | -1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | -1, | 1, | 1, | ... | 1, | 1, | 1, | ... | 2, | -1, | -1, | ... | -1, | -1, | -1, | ... | -1, | ... | -2, | -2, | ... | -2 | | | ||||||||
| | | 1, | -2, | -1, | ... | -1, | -2, | -1, | ... | -1, | 4, | 2, | ... | 2, | 2, | 1, | ... | 1, | ... | 2, | 1, | ... | 1 | | | p-1 行 | |||||||
| | | 1, | -1, | -2, | ... | -1, | -2, | -1, | ... | -1, | 2, | 4, | ... | 2, | 1, | 2, | ... | 1, | ... | 1, | 2, | ... | 1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -1, | -1, | ... | -2, | -2, | -1, | ... | -1, | 2, | 2, | ... | 4, | 1, | 1, | ... | 2, | ... | 1, | 1, | ... | 2 | | | ||||||||
| | | 1, | -2, | -1, | ... | -1, | -1, | -2, | ... | -1, | 2, | 1, | ... | 1, | 4, | 2, | ... | 2, | ... | 2, | 1, | ... | 1 | | | p-1 行 | |||||||
| | | 1, | -1, | -2, | ... | -1, | -1, | -2, | ... | -1, | 1, | 2, | ... | 1, | 2, | 4, | ... | 2, | ... | 1, | 2, | ... | 1 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -1, | -1, | ... | -2, | -1, | -2, | ... | -1, | 1, | 1, | ... | 2, | 2, | 2, | ... | 4, | ... | 1, | 1, | ... | 2 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -2, | -1, | ... | -1, | -1, | -1, | ... | -2, | 2, | 1, | ... | 1, | 2, | 1, | ... | 1, | ... | 4, | 2, | ... | 2 | | | p-1 行 | |||||||
| | | 1, | -1, | -2, | ... | -1, | -1, | -1, | ... | -2, | 1, | 2, | ... | 1, | 1, | 2, | ... | 1, | ... | 2, | 4, | ... | 2 | | | ||||||||
| | | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | : | : | ... | : | ... | : | : | ... | : | | | ||||||||
| | | 1, | -1, | -1, | ... | -2, | -1, | -1, | ... | -2, | 1, | 1, | ... | 2, | 1, | 1, | ... | 2, | ... | 2, | 2, | ... | 4 | | | ||||||||
という結果になります。
二元配置分散分析のデザイン行列から交互作用効果を除いた場合、以下のような行列になるのでした。
| XTX | = n | | | pq, | q1p-1T, | p1q-1T | | |
| | | q1p-1, | qEp-1, | NT | | | ||
| | | p1q-1, | N, | pEq-1 | | | ||
この逆行列を以下のような成分で表します。各ブロックの行列数は、XTX における同じ行・列のものと等しいとします。
| ( XTX )-1 | = (1/n) | | | a, | bp-1T, | cq-1T | | |
| | | bp-1, | Sp-1, | TT | | | ||
| | | cq-1, | T, | Uq-1 | | | ||
a はスカラーであり、bp-1 は次元数 p - 1、cq-1 は次元数 q - 1 のベクトルです。Sp-1 は大きさが p - 1、Uq-1 は大きさが q - 1 の正方行列であり、T は q - 1 行 p - 1 列の行列です。この二つの行列の積が単位行列になることから、各ブロックの積和を求める式が 9 つ得られ、以下のような連立方程式が得られます。
| pqa + q1p-1Tbp-1 + p1q-1Tcq-1 = 1 | --- (1) |
| pqbp-1T + q1p-1TSp-1 + p1q-1TT = 0p-1T | --- (2) |
| pqcq-1T + q1p-1TTT + p1q-1TUq-1 = 0q-1T | --- (3) |
| qa1p-1 + qbp-1 + NTcq-1 = 0p-1 | --- (4) |
| q1p-1bp-1T + qSp-1 + NTT = Ep-1 | --- (5) |
| q1p-1cq-1T + qTT + NTUq-1 = 0p-1,q-1 | --- (6) |
| pa1q-1 + Nbp-1 + pcq-1 = 0q-1 | --- (7) |
| p1q-1bp-1T + NSp-1 + pT = 0q-1,p-1 | --- (8) |
| p1q-1cq-1T + NTT + pUq-1 = Eq-1 | --- (9) |
bp-1, cq-1 の j 番目の成分をそれぞれ bj, cj とすると、(1) より
(4) より r 列目の要素は
なので、(1') - p x (4') より
が全ての r について成り立ちます。特に r ≠ s に対して上式が成り立つなら
を辺々引けば容易に br = bs が成り立つことがわかります。従って、
より bp-1 = -1p-1 / q となります。(1), (7) に対して同様の操作を行えば cq-1 = -1q-1 / p という結果が得られ、a = ( p + q - 1 ) / p であることもわかります。この結果を (2) に代入すれば、
より第 c 列は
となり、(5) より
なので、その r 行 c 列の成分は
となります。但し、sr,c は S の、tr,c は T の r 行 c 列の成分、δrc は「クロネッカーのデルタ (Kronecker Delta)」で、r = c のときのみ 1 でそれ以外は 0 になります。(2') - p x (5') より
が全ての r について成り立ちます。特に、r ≠ s に対して
を辺々引けば
となるので、r ≠ c かつ r ≠ c ならば sr,c = ss,c であり、r = c ならば
となって、対角成分は非対角成分より 1 / q だけ大きいことを意味します。(A) に対し、r ≠ c のとき、前半の和の中には一つだけ対角成分があるので
q[ ( p - 1 )sr,c + 1 / q ] - pqsr,c = 0 より
sr,c = 1 / q
であり、対角成分は 2 / q です。よって、Sp-1 = ( 1 / q )( Np-1 + Ep-1 ) という結果が得られ、(3) と (6) に同様の操作を行うことで Uq-1 = ( 1 / p )( Nq-1 + Eq-1 ) となります。bp-1 と Sp-1 を (8) に代入すると
| -( p / q )1q-11p-1T + ( 1 / q )N( Np-1 + Ep-1 ) + pT | |
| = | -( p / q )N + [ ( p - 1 ) / q ]N + ( 1 / q )N + pT |
| = | pT = 0q-1,p-1 |
より T = 0q-1,p-1 となり、逆行列 ( XTX )-1 は
| ( XTX )-1 | = (1/n) | | | ( p + q - 1 ) / pq, | -1p-1T / q, | -1q-1T / p | | |
| | | -1p-1 / q, | ( 1 / q )( Np-1 + Ep-1 ), | 0p-1,q-1 | | | ||
| | | -1q-1 / p, | 0q-1,p-1, | ( 1 / p )( Nq-1 + Eq-1 ) | | | ||
となります。
二つの確率変数 x, y がそれぞれ互いに独立に確率分布 Px(x), Py(y) に従うとき、確率変数 x, y の和 u = x + y は畳み込み積分
| Px(u) * Py(u) | = | ∫{-∞→∞} px( u - v )py(v) dv | (連続分布) |
| = | Σv{-∞→∞}( px( u - v )py(v) ) | (離散分布) |
となるのでした。よって、二つの確率変数 x, y がそれぞれ互いに独立にポアソン分布
Pλ1(x) = e-λ1λ1x / x!
Pλ2(y) = e-λ2λ2y / y!
に従うとき、u = x + y の確率密度関数は
| Pλ1(u) * Pλ2(u) | = | Σv{0→u} pλ1( u - v )pλ2(v) |
| = | Σv{0→u}( [ e-λ1λ1u-v / ( u - v )! ]・[ e-λ2λ2v / v! ] ) | |
| = | e-(λ1+λ2)Σv{0→u}( λ1u-vλ2v / ( u - v )!v! ) | |
| = | e-(λ1+λ2)Σv{0→u}( [ u! / ( u - v )!v! ]λ1u-vλ2v / u! ) | |
| = | [ e-(λ1+λ2) / u! ]Σv{0→u} uCvλ1u-vλ2v | |
| = | e-(λ1+λ2)( λ1 + λ2 )u / u! |
となって、これはポアソン分布 Pλ1+λ2(u) そのものです。この結果から、ポアソン分布は「再生性(Reproductive Property)」を持つことがわかり、上記操作を繰り返せば明らかなように、複数の確率変数 xi がポアソン分布 Pλi(xi) に従うとき、その和 x = Σi( xi ) の確率密度関数は
Pλ(x) = e-λλx / x!
但し、λ = Σi( λi )
となることを示すことができます。
ポアソン分布を利用した場合「逸脱度残差」の平方根の中身は次のようになります。
ここで yi は実測値、mi はモデル式から得られた当てはめ値をそれぞれ表します。この値が正値でなければ逸脱度残差は実数になりませんが、これが成り立つことは以下のように証明できます。
上式を mi の関数 f( mi ) とし ( yi は定数とみなします )、導関数 f'( mi ) を計算すると、
よって、mi = yi のとき f( mi ) は極値をとります。二階導関数 f''( mi ) は
なので yi > 0 ならば常に正値となり、f( mi ) は極小値です。f( mi ) = 0 より yi > 0 のとき f( mi ) ≥ 0 が成り立ちます。ポアソン分布では yi > 0 なので、逸脱度残差は必ず実数となることになります。
◆◇◆更新履歴◆◇◆
「(3)対数線形モデル」の利用例を一つ追加しました。
「逸脱度残差」の定義式に誤りがあり修正しました。それに伴い、補足 5 を追加しています。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |