 |
JPEG2000 が持つ特徴として、これまでに二つ紹介してきました。一つはウェーブレット変換で、もう一つは算術符号化です。JPEG2000 ではこの二つの処理の間に、三つめの特徴である EBCOT ( Embedded Block Coding with Optimal Truncation ) が使われています。EBCOT は、算術符号化処理 MQ-Coder とも密接に関係しているので、この章では、EBCOT による符号化とその算術圧縮処理方法 MQ-Coder を中心に紹介をしたいと思います。
EBCOT は「エンベデッド符号化 ( Embedded Coding )」の一種です。"Embedded" とは「埋め込まれた」という意味を持っていますが、エンベデッド符号化というのは、一つの符号化の結果の中に複数の符号化処理の結果の情報が「埋め込まれている」ような符号化処理のことを指しています。
例えば、3 ビットの情報を線形量子化することを考えた場合、下位 1 ビット、または 2 ビットを切り捨てた結果は以下のようになります。
| 原符号 | 下位 1 ビット切り捨て | 下位 2 ビット切り捨て |
|---|---|---|
| 000 | 00 | 0 |
| 001 | ||
| 010 | 01 | |
| 011 | ||
| 100 | 10 | 1 |
| 101 | ||
| 110 | 11 | |
| 111 |
符号化した情報として 3 ビット分を持っていれば、必要に応じて下位のビットを任意に切り捨てて復号化を行うことができます。つまり、任意のビットを切り捨てた符号が、別の符号情報として「埋め込まれている」ことになるわけです。
エンベデッド符号化を使う事により、任意の品質で符号化を行うことができるようになります。符号化レート ( 符号化するデータ量 ) があらかじめ決まっている場合、その量に達した段階で符号化処理を停止することも可能ですし、最後まで符号化を完了しておいてから適当な長さに切り捨てるようなこともできます。このような事は JPEG 符号化では不可能で、決められた符号化レートになるようにパラメータを調整して試行錯誤を繰りかえす必要があります。
EBCOTでは、量子化精度と空間解像度の両方に対して品質を調節することが可能になっています。前者は「ビットプレーン」と「符号化パス」の二つで調節し、後者は「コードブロック」単位で調節を行うことになります。
ウェーブレット変換した結果は画像と同様に二次元平面の形になりますが、EBCOT を行う際にはこれをさらに「コードブロック ( Code-block )」と呼ばれる複数のブロックに分割します。コードブロックの大きさは、高さと幅が 4 〜 1024 の範囲となる 2 のべき乗であり、しかも両者の積が 4096 以下でなければならないという約束があります。
符号化する順番も少々ややこしく、コードブロック内部を 4 行 x 1 列の短冊状のエリア ( 以下 sprite と略記 ) に細分化して、左上の sprite の最も上側のピクセルから下側に向かって処理した後、右側の sprite へ移動して繰りかえし処理を行い、右端まで達したらすぐ下側に並ぶ sprite の左端から同じように符号化を行って行きます。コードブロックの高さが 4 の倍数でない場合は、最も下側の sprite のビット数は 4 よりも少なくなります。
|
一つのピクセルは、ある大きさを持った変換係数を持っています。これを二進数としてみた場合、コードブロックはある高さのビットが並んだ三次元の直方体と考えることができます。最上位ビットを最も上側として、これを一ビットずつ水平方向に切り取った平面を「ビットプレーン ( Bit-plane ) 」と呼びます。最上位ビットはそのデータの正負を表し (「極性ビット」といいます )、その次のビットから下側で係数の絶対値を表すことになります。一つのコードブロックに対しては、最上位ビットを除き、最初に 1 となったビットが見つかったビットプレーンから順に符号化を行います。
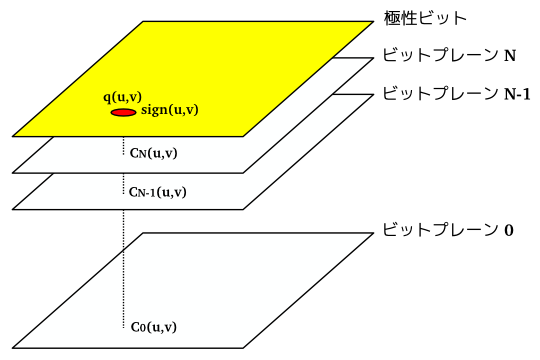 |
コードブロックとビットプレーン用にクラスを用意しておきます。以下に、サンプル・プログラムを示します。
/* 座標定義用構造体 */ template< class T > struct Coord { T x; // x 座標 T y; // y 座標 /* コンストラクタ */ // デフォルト・コンストラクタ // ( x, y ) = ( 0, 0 ) で初期化される Coord() : x( 0 ), y ( 0 ) {} // x, y 座標を指定して構築 Coord( T x_, T y_ ) : x( x_ ), y ( y_ ) {} // 異なる型の座標 c から構築 template< class U > Coord( const Coord< U >& c ) : x( c.x ), y( c.y ) {} }; /* ビットプレーン構造体 */ struct BitPlane { unsigned int coeff; // 係数(絶対値) bool isPos; // 係数は正か unsigned char signFlag; // 有意性 unsigned char pass; // 現在のパス // コンストラクタ BitPlane() : coeff( 0 ), isPos( true ), signFlag( 0 ), pass( EBCOT_CU_PASS ) {} }; /* コードブロック */ class CodeBlock { std::vector< BitPlane > bitPlane_; // ビットプレーン Coord< size_t > size_; // ビットプレーンのサイズ size_t spriteCount_; // ビットプレーンの高さ(スプライト数) public: // デフォルト・コンストラクタ CodeBlock() : bitPlane_(), size_( 0, 0 ), spriteCount_( 0 ) {} // ビットプレーンの幅を返す size_t width() const { return( size_.x ); } // ビットプレーンの高さを返す size_t height() const { return( size_.y ); } // ビットプレーンの縦方向のスプライト数を返す size_t spriteCount() const { return( spriteCount_ ); } };
ビットプレーン構造体 BitPlane は、係数の絶対値 coeff とその符号 isPos の他に、有意性 signFlag とパス pass という二つのメンバ変数があります。これらの詳細は後ほど説明します ( pass の初期値が EBCOT_CU_PASS となっていますが、これはある定数値を表しています。内容については次節にて紹介します )。コードブロックを表す CodeBlock クラスは BitPlane からなる配列 bitPlane_ を持ち、これを二次元配列のように扱います。その他にビットプレーンのサイズ size_ と sprite 数 ( 高さ ) を表す spriteCount_ がメンバ変数として用意されています。ここで、spriteCount_ 数の 4 倍とビットプレーンの高さは必ずとも等しくなく、最大で 3 ピクセル分少なくなる可能性があるとします。つまり、size_ は実際のピクセルの数を表し、sprite にしたときの余剰分はカウントされていないことになります。
CodeBlock クラス にはさらにメンバ関数が追加されていきます。これらは後の節の内容に関係するため後述します。
任意の符号化レートで処理を行う場合、ビットプレーン単位での切り捨てでは精度が粗いため、EBCOT ではビットプレーンをさらに以下に示すような三つの「符号化パス ( Coding Pass )」に分類して処理を行います。どの符号化パスを使って符号化を行うかは、コードブロック内の各係数の状態によって決まります。
まず、各係数は「有意である ( Significant )」か「有意でない ( Insignificant )」かの二つの状態に分けられます。符号化の開始時は全ての係数は「有意でない」状態と見なされ、上位から順にビットプレーンを処理する際に、ビットが立った状態を検出した段階でその係数は「有意である」状態に変化します。符号化パスは、対象の係数自身の状態だけではなく、その近傍にある係数の状態からも影響を受けます。この近傍係数までを含めた状態は「コンテキスト・ベクトル ( Context Vector )」と呼ばれ、水平方向の近傍 Hi ( i = 0, 1 )、垂直方向の近傍 Vi ( i = 0, 1 )、そして対角方向の近傍 Di ( i = 0 〜 3 ) の計 8 つの要素で構成されています ( 近傍の係数がコードブロックの外側にある場合、その近傍係数は常に「有意でない」と見なされます )。
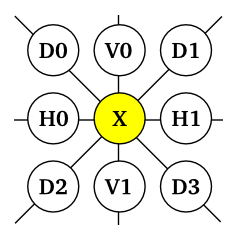 |
隣接する係数の状態の組合せだけでも 28 = 256 通りとなるためコンテキスト・ベクトルの取り得る値はかなり多くなりますが、JPEG2000 では対称性などを利用してそれを 18 種類にまで集約し、それぞれに「コンテキスト・ラベル ( Context Label )」という番号を割り振ります。後で紹介する「MQ-Coder」は、符号化するデータ ( これを「Decision」といいます ) といっしょにこのコンテキスト・ラベルを入力して処理を行い、その値は使用されるコンテキスト・ラベルと現係数の状態によって決まることになるわけです。
前述の通り、符号化処理は、ビットが立った状態を含む最上位のビットプレーンからスタートします。ビットプレーン内の各係数は、その状態によって利用される符号化パスが決まり、まだ対象の係数自身が有意でなく、近傍に有意状態の係数がある場合は「Significance Propagation Pass」が、すでに前のビットプレーンで有意状態に変化した係数は「Magnitude Refinement Pass」が、いずれにも該当しない係数は「Cleanup Pass」がそれぞれ使用されます。
なお、最初のビットプレーンは全ての係数が「有意でない」状態であるため、「Significance Propagation Pass」と「Magnitude Refinement Pass」は使わずに「Cleanup Pass」のみを行います。
Significance Propagation Pass では、現係数の状態に関わらず近傍係数の状態からコンテキスト・ラベルを決定します。近傍係数の状態と、それに対するコンテキスト・ラベルの値を以下に示します。
| LL/LH subband | HL subband | HH subband | Context Label | |||||
|---|---|---|---|---|---|---|---|---|
| ΣHi | ΣVi | ΣDi | ΣHi | ΣVi | ΣDi | Σ(Hi+Vi) | ΣDi | |
| 2 | x | x | x | 2 | x | x | ≥3 | 8 |
| 1 | ≥1 | x | ≥1 | 1 | x | ≥1 | 2 | 7 |
| 1 | 0 | ≥1 | 0 | 1 | ≥1 | 0 | 2 | 6 |
| 1 | 0 | 0 | 0 | 1 | 0 | ≥2 | 1 | 5 |
| 0 | 2 | x | 2 | 0 | x | 1 | 1 | 4 |
| 0 | 1 | x | 1 | 0 | x | 0 | 1 | 3 |
| 0 | 0 | ≥2 | 0 | 0 | ≥2 | ≥2 | 0 | 2 |
| 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
ΣHi, ΣVi, ΣDi はそれぞれ水平・垂直・対角方向の近傍係数の中で有意なものの個数を表します。コンテキスト・ラベルは、コードブロックがどのサブバンドに属しているかにも依存しており、例えば LL / LH サブバンドと HL サブバンドでは ΣHi と ΣVi の条件が入れ換えられています。これは、ウェーブレット変換が垂直・水平方向のどちらに対して行われたかを考慮した結果です。
次に現係数の Decision と取得したコンテキスト・ラベルを算出符号器へ入力して符号化を行います ( コンテキスト・ラベルが 0 の場合は後述の Cleanup Pass で符号化を行うため、ここでの処理はスキップします)。符号化処理を行った後、Decision が 1 であれば係数を「有意である」状態に遷移してから、極性ビットの符号化処理に移ります。
極性ビットは 1 ならば負数、0 ならば正数を表します。極性ビットの符号化でもコンテキスト・ラベルを決定する必要がありますが、この時も近傍状態を使って処理を行います。まず、水平方向の近傍係数 H0, H1 と垂直方向の近傍係数 V0, V1 に対して、有意であるかどうか、また有意であるならば符号は正負のどちらであるかをチェックします。次にその結果から、以下に示す表を使って「水平指標 ( Horizontal Contribution )」と「垂直指標 ( Vertical Contribution )」を決定します。指標の決め方には一定の規則があり、二つの近傍係数を正値なら 1、負値なら -1、有意でないなら 0 として、その和を計算した結果が正なら指標は 1、負ならば -1、ゼロならば 0 と決めることができます。
| V1(H1) | |||||
|---|---|---|---|---|---|
| 有意である | 有意でない | ||||
| 正値 | 負値 | ||||
| V0(H0) | 有意である | 正値 | 1 | 0 | 1 |
| 負値 | 0 | -1 | -1 | ||
| 有意でない | 1 | -1 | 0 | ||
水平・垂直指標が決まったら、その組合せによってコンテキスト・ラベルを決定します。また同時に XORbit を決定して極性ビットと排他的論理和を計算し、その結果を Decision としてコンテキスト・ラベルといっしょに算術符号器へ入力します。以下に、指標とコンテキスト・ラベル、XORbit の組合せを示します。
| 水平指標 | 垂直指標 | コンテキスト・ラベル | XORbit |
|---|---|---|---|
| 1 | 1 | 13 | 0 |
| 0 | 12 | ||
| -1 | 11 | ||
| 0 | 1 | 10 | |
| 0 | 9 | ||
| -1 | 10 | ||
| -1 | 1 | 11 | 1 |
| 0 | 12 | ||
| -1 | 13 |
以下に、EBCOT 符号化に必要なパラメータ類を示します。
/***************************************************************************************** 定数宣言 *****************************************************************************************/ const unsigned int EBCOT_SPRITE_SIZE = 4; // sprite の縦方向のサイズ /* コンテキスト・ラベル */ enum JPEG2000_CONTEXT_LABEL { CL_SP_CODING_0 = 0, CL_SP_CODING_1 = 1, CL_SP_CODING_2 = 2, CL_SP_CODING_3 = 3, CL_SP_CODING_4 = 4, CL_SP_CODING_5 = 5, CL_SP_CODING_6 = 6, CL_SP_CODING_7 = 7, CL_SP_CODING_8 = 8, CL_SIGN_CODING_00 = 9, CL_SIGN_CODING_01 = 10, CL_SIGN_CODING_PM = 11, CL_SIGN_CODING_10 = 12, CL_SIGN_CODING_11 = 13, CL_MR_CODING_NEIGH0 = 14, CL_MR_CODING_NEIGH1 = 15, CL_MR_CODING_MULTI = 16, CL_RUNLENGTH_CODING = 17, CL_UNIFORM = 18, CL_SIZE = 19, }; /* サブバンドに付加する定数値 コンテキストラベル 0-8 を決めるための定義に利用する */ enum EBCOT_SUBBAND { EBCOT_SUBBAND_LL = 0, // スケーリング係数 EBCOT_SUBBAND_LH = 0, // 垂直方向のウェーブレット係数 EBCOT_SUBBAND_HL = 1, // 水平方向のウェーブレット係数 EBCOT_SUBBAND_HH = 2, // 対角方向のウェーブレット係数 EBCOT_SUBBAND_SIZE = 3, // 定数値の数 }; /* 符号化パスに対する定数値 */ enum EBCOT_PASS { EBCOT_CU_PASS = 0, // Cleanup Pass EBCOT_SP_PASS = 1, // Significance Propagation Pass EBCOT_MR_PASS = 2, // Magnitude Refinement Pass };
列挙子 JPEG2000_CONTEXT_LABEL はコンテキスト・ラベルの番号を表しています。まだ Significance Propagation Pass のコンテキスト・ラベル ( 0 〜 13 ) しか説明していませんが、その他の符号化パスに対するコンテキスト・ラベルもまとめて定義されています。その次にある EBCOT_SUBBAND は、0 から 8 までのコンテキスト・ラベルを決めるときのサブバンドの識別子を表しています ( 表 3-1 参照 )。また、EBCOT_PASS は各ビットがどの符号化パスであるかを識別するために使用し、BitPlane 構造体のメンバ変数 pass にはこの値が登録されます。
次に、Significance Propagation Pass を処理するためのサンプル・プログラムを示します。
/***************************************************************************************** 関数の型定義 *****************************************************************************************/ typedef ContextLabel (*significance_encode_type)( CodeBlock*, Coord< size_t >, unsigned int, unsigned int, Encoder&, bool ); typedef ContextLabel (*significance_decode_type)( CodeBlock*, Coord< size_t >, unsigned int, unsigned int, Decoder&, bool ); typedef ContextLabel (*sign_encode_type)( CodeBlock*, Coord< size_t >, Encoder& ); typedef ContextLabel (*sign_decode_type)( CodeBlock*, Coord< size_t >, Decoder& ); /***************************************************************************************** Significant Coding Context Labelの定義 *****************************************************************************************/ const size_t EBCOT_SIGN_CL_SIZE = 9; // Significance Propagetion のコンテキストラベル数 struct SignificantContextLabelType { unsigned char h_min; // 有意な水平成分の数最小値 min(ΣHi) unsigned char h_max; // 有意な水平成分の数最大値 max(ΣHi) unsigned char v_min; // 有意な垂直成分の数最小値 min(ΣVi) unsigned char v_max; // 有意な垂直成分の数最大値 max(ΣVi) unsigned char d_min; // 有意な対角成分の数最小値 min(ΣDi) unsigned char d_max; // 有意な対角成分の数最大値 max(ΣDi) }; SignificantContextLabelType SignCL[EBCOT_SUBBAND_SIZE][EBCOT_SIGN_CL_SIZE] = { { // min(ΣHi),max(ΣHi),min(ΣVi),max(ΣVi),min(ΣDi),max(ΣDi) { 0, 0, 0, 0, 0, 0, }, // LL,LH subband { 0, 0, 0, 0, 1, 1, }, { 0, 0, 0, 0, 2, 4, }, { 0, 0, 1, 1, 0, 4, }, { 0, 0, 2, 2, 0, 4, }, { 1, 1, 0, 0, 0, 0, }, { 1, 1, 0, 0, 1, 4, }, { 1, 1, 1, 2, 0, 4, }, { 2, 2, 0, 2, 0, 4, }, }, { // min(ΣHi),max(ΣHi),min(ΣVi),max(ΣVi),min(ΣDi),max(ΣDi) { 0, 0, 0, 0, 0, 0, }, // HL subband { 0, 0, 0, 0, 1, 1, }, { 0, 0, 0, 0, 2, 4, }, { 1, 1, 0, 0, 0, 4, }, { 2, 2, 0, 0, 0, 4, }, { 0, 0, 1, 1, 0, 0, }, { 0, 0, 1, 1, 1, 4, }, { 1, 2, 1, 1, 0, 4, }, { 0, 2, 2, 2, 0, 4, }, }, { // min(ΣHi),max(ΣHi),min(ΣVi),max(ΣVi),min(ΣDi),max(ΣDi) { 0, 0, 0, 0, 0, 0, }, // HH subband { 1, 1, 1, 1, 0, 0, }, { 2, 4, 2, 4, 0, 0, }, { 0, 0, 0, 0, 1, 1, }, { 1, 1, 1, 1, 1, 1, }, { 2, 4, 2, 4, 1, 1, }, { 0, 0, 0, 0, 2, 2, }, { 1, 4, 1, 4, 2, 2, }, { 0, 4, 0, 4, 3, 4, }, }, }; /***************************************************************************************** CodeBlock のメンバ関数 *****************************************************************************************/ /* 座標 c の係数・または近傍の係数のビットプレーンへの参照を返す 近傍状態を確認する時に範囲外を参照する可能性があるため、実際のサイズより上下左右に 1 ピクセル分の余白がある。 そのため、左上の原点は ( 0, 0 ) ではなく ( 1, 1 ) となっていることに注意。 */ BitPlane& CodeBlock::operator[]( Coord< size_t > c ) { return( bitPlane_.at( pos( c.x + 1, c.y + 1 ) ) ); } // 現在位置 BitPlane& CodeBlock::operator()( size_t x, size_t y ) { return( bitPlane_.at( pos( x + 1, y + 1 ) ) ); } // 現在位置 const BitPlane& CodeBlock::operator[]( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x + 1, c.y + 1 ) ) ); } // 現在位置 const BitPlane& CodeBlock::operator()( size_t x, size_t y ) const { return( bitPlane_.at( pos( x + 1, y + 1 ) ) ); } // 現在位置 const BitPlane& CodeBlock::d0( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x, c.y ) ) ); } // 左上 const BitPlane& CodeBlock::d1( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x + 2, c.y ) ) ); } // 右上 const BitPlane& CodeBlock::d2( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x, c.y + 2 ) ) ); } // 左下 const BitPlane& CodeBlock::d3( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x + 2, c.y + 2 ) ) ); } // 右下 const BitPlane& CodeBlock::h0( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x, c.y + 1 ) ) ); } // 左 const BitPlane& CodeBlock::h1( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x + 2, c.y + 1 ) ) ); } // 右 const BitPlane& CodeBlock::v0( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x + 1, c.y ) ) ); } // 上 const BitPlane& CodeBlock::v1( Coord< size_t > c ) const { return( bitPlane_.at( pos( c.x + 1, c.y + 2 ) ) ); } // 下 /***************************************************************************************** EBCOT 処理用関数 *****************************************************************************************/ // 係数 coeff の下位から bit 番目のビット状態を返す inline bool GetBit( unsigned int coeff, unsigned int bit ) { return( ( ( coeff >> bit ) & 1 ) != 0 ); } // 係数 coeff の下位から bit 番目のビットを立てる inline void SetBit( unsigned int* coeff, unsigned int bit ) { *coeff |= ( 1 << bit ); } /* 現係数 codeBlock の位置 c の近傍状態を h(水平成分), v(垂直成分), d(対角成分) に返す codeBlock : 現係数 c : 現係数の位置 */ void GetNeighborState( const CodeBlock& codeBlock, Coord< size_t > c, unsigned char* h, unsigned char* v, unsigned char* d ) { *h = *v = *d = 0; if ( ( codeBlock.h0( c ) ).signFlag > 0 ) ++( *h ); if ( ( codeBlock.h1( c ) ).signFlag > 0 ) ++( *h ); if ( ( codeBlock.v0( c ) ).signFlag > 0 ) ++( *v ); if ( ( codeBlock.v1( c ) ).signFlag > 0 ) ++( *v ); if ( ( codeBlock.d0( c ) ).signFlag > 0 ) ++( *d ); if ( ( codeBlock.d1( c ) ).signFlag > 0 ) ++( *d ); if ( ( codeBlock.d2( c ) ).signFlag > 0 ) ++( *d ); if ( ( codeBlock.d3( c ) ).signFlag > 0 ) ++( *d ); } /* Significance Propagetion Pass と Cleanup Pass に対するコンテキストラベルを返す codeBlock : 現係数 c : 現係数の位置 subband : サブバンド 戻り値 : コンテクストラベル */ ContextLabel GetSignificance_CL( const CodeBlock& codeBlock, Coord< size_t > c, unsigned int subband ) { unsigned char h, v, d; // 水平・垂直・対角成分の有意ビット数 ContextLabel cl; // コンテキストラベル GetNeighborState( codeBlock, c, &h, &v, &d ); // HH subbandの場合は h + v で比較 if ( subband == EBCOT_SUBBAND_HH ) { h += v; v = h; } // サブバンド別の、近傍係数に対するコンテキストラベル表からコンテキストラベルを決定 SignificantContextLabelType* signCL = SignCL[subband]; for ( cl = EBCOT_SIGN_CL_SIZE - 1 ; cl > 0 ; --cl ) { if ( ( signCL[cl] ).h_min <= h && ( signCL[cl] ).h_max >= h && ( signCL[cl] ).v_min <= v && ( signCL[cl] ).v_max >= v && ( signCL[cl] ).d_min <= d && ( signCL[cl] ).d_max >= d ) break; } return( cl ); } /* Significance Coding 近傍状態からコンテクストラベルを決定し、符号化/復号化を行う。 codeBlock : コードブロックへのポインタ c : 現係数の位置 subband : サブバンド(LL/LH/HL/HH) bit : BitPlaneのビット位置 encoder/decoder : 符号化/復号化処理用関数オブジェクト isCleanUp : Clean Up パスから呼び出されたものか 戻り値 : コンテクストラベル */ ContextLabel SignificanceEncode( CodeBlock* codeBlock, Coord< size_t > c, unsigned int subband, unsigned int bit, Encoder& encoder, bool isCleanUp ) { BitPlane& current_bp = (*codeBlock)[c]; // 現係数 if ( current_bp.signFlag > 0 ) return( 0 ); // 現係数がすでに有意ならスキップ(ゼロを返す) ContextLabel cl = GetSignificance_CL( *codeBlock, c, subband ); // コンテキストラベル if ( ( cl == 0 ) && ( ! isCleanUp ) ) return( cl ); // CleanUp の場合、符号化は cl = 0 でも行う bool b = GetBit( (*codeBlock)[c].coeff, bit ); if ( b ) current_bp.signFlag = 1; encoder( b, cl ); return( cl ); } ContextLabel SignificanceDecode( CodeBlock* codeBlock, Coord< size_t > c, unsigned int subband, unsigned int bit, Decoder& decoder, bool isCleanUp ) { BitPlane& current_bp = (*codeBlock)[c]; // 現係数 if ( current_bp.signFlag > 0 ) return( 0 ); // 現係数がすでに有意ならスキップ(ゼロを返す) ContextLabel cl = GetSignificance_CL( *codeBlock, c, subband ); // コンテキストラベル if ( ( cl == 0 ) && ( ! isCleanUp ) ) return( cl ); // CleanUp の場合、符号化は cl = 0 でも行う if ( decoder( cl ) ) { current_bp.signFlag = 1; SetBit( &( (*codeBlock)[c].coeff ), bit ); } return( cl ); } /* 極性ビットの符号化のための指標を決定する hv0 : 垂直/水平近傍 1 hv1 : 垂直/水平近傍 2 戻り値 : 指標 */ int GetPolarIndex( const BitPlane& hv0, const BitPlane& hv1 ) { // どちらも有意 if ( hv0.signFlag > 0 && hv1.signFlag > 0 ) { if ( hv0.isPos && hv1.isPos ) return( 1 ); else if ( ( ! hv0.isPos ) && ( ! hv1.isPos ) ) return( -1 ); else return( 0 ); // hv0 が有意 } else if ( hv0.signFlag > 0 ) { return( ( hv0.isPos ) ? 1 : -1 ); // hv1 が有意 } else if ( hv1.signFlag > 0 ) { return( ( hv1.isPos ) ? 1 : -1 ); // 両方とも有意でない } else { return( 0 ); } } /* 極性ビットの排他的論理和(XOR)を返す sign : 極性ビット h_c : 水平指標(Horizontal Contribution) 戻り値 : 正/負(=false/true) と XORbit との排他的論理和 */ bool GetXorbitOfSign( bool sign, int h_c ) { // 水平指標が 0 以上の場合 XORbit は false、そうでなければ true を取る return( ( h_c >= 0 ) ? sign ^ false : sign ^ true ); } /* 極性符号化に対するコンテキストラベルを返す codeBlock : コードブロックへの参照 c : 現係数の位置 sign : 係数の極性へのポインタ( NULL なら無視 ) */ ContextLabel GetSign_CL( const CodeBlock& codeBlock, Coord< size_t > c, bool* sign ) { const BitPlane& current_bp = codeBlock[c]; // 現係数 ContextLabel cl = 0; // コンテキストラベル int h_c = GetPolarIndex( codeBlock.h0( c ), codeBlock.h1( c ) ); // 水平指標(Horizontal Contribution) int v_c = GetPolarIndex( codeBlock.v0( c ), codeBlock.v1( c ) ); // 垂直指標(Vertical Contribution) // 現係数の極性ビットの排他的論理和(XOR)を取得する if ( sign != 0 ) *sign = GetXorbitOfSign( ! current_bp.isPos, h_c ); switch( h_c ) { case 1: cl = ( v_c > 0 ) ? CL_SIGN_CODING_11 : ( ( v_c < 0 ) ? CL_SIGN_CODING_PM : CL_SIGN_CODING_10 ); break; case 0: cl = ( v_c != 0 ) ? CL_SIGN_CODING_01 : CL_SIGN_CODING_00; break; case -1: cl = ( v_c > 0 ) ? CL_SIGN_CODING_PM : ( ( v_c < 0 ) ? CL_SIGN_CODING_11 : CL_SIGN_CODING_10 ); break; } return( cl ); } /* Sign Coding 極性ビットの符号化/復号化 codeBlock : コードブロックへのポインタ c : 現係数の位置 encoder/decoder : 符号化/復号化処理用関数オブジェクト 戻り値 : コンテクストラベル */ ContextLabel SignEncode( CodeBlock* codeBlock, Coord< size_t > c, Encoder& encoder ) { bool sign; // 係数の極性 ContextLabel cl = GetSign_CL( *codeBlock, c, &sign ); // コンテキストラベル encoder( sign, cl ); return( cl ); } ContextLabel SignDecode( CodeBlock* codeBlock, Coord< size_t > c, Decoder& decoder ) { ContextLabel cl = GetSign_CL( *codeBlock, c, 0 ); // コンテキストラベル bool d = decoder( cl ); // Decision // 正/負(=0/1) と XORbit との排他的論理和 if ( GetXorbitOfSign( d, GetPolarIndex( codeBlock->h0( c ), codeBlock->h1( c ) ) ) ) { (*codeBlock)[c].isPos = false; } return( cl ); } /* Significance Propagation Pass codeBlock : コードブロックへのポインタ subband : サブバンド bit : BitPlane のビット位置 significanceOp : Significance Coding function signOp : Sign Coding function coderOp : 符号化/復号化処理用関数オブジェクト */ template< class SignificanceOp, class SignOp, class CoderOp > void SigProPass( CodeBlock* codeBlock, unsigned int subband, unsigned int bit, SignificanceOp significanceOp, SignOp signOp, CoderOp& coderOp ) { for ( size_t sy = 0 ; sy < codeBlock->spriteCount() ; ++sy ) { for ( Coord< size_t > c( 0, 0 ) ; c.x < codeBlock->width() ; ++( c.x ) ) { for ( c.y = sy * EBCOT_SPRITE_SIZE ; c.y < ( sy + 1 ) * EBCOT_SPRITE_SIZE ; ++( c.y ) ) { if ( significanceOp( codeBlock, c, subband, bit, coderOp, false ) > 0 ) { (*codeBlock)[c].pass = EBCOT_SP_PASS; if ( (*codeBlock)[c].signFlag > 0 ) signOp( codeBlock, c, coderOp ); } } } } }
固定長の二次元配列 SignCL はコンテキスト・ラベル 0 〜 8 を決めるためのパラメータを保持しています。一つの配列には全部で 9 つのパラメータがあり、それぞれが各コンテキスト・ラベルに割り当てられます。また、三つの配列は各サブバンドに対応しています。表 3-1 の内容をそのままコーディングしていますが、範囲指定が必要なため水平・垂直・対角成分の最小・最大値を指定するのに 6 つのパラメータが必要となります。
先に示したコードブロック用クラス CodeBlock には、要素にアクセスするためのメンバ関数を追加しています。指定した座標にアクセスする関数として operator[] ( Coord を使ったアクセス ) と operator() ( x, y それぞれを指定するアクセス ) を用意し、その他に近傍の状態を得るための関数 ( d0 〜 d3, h0, h1, v0, v1 ) も作成しています。注意点としてソース内のコメントにも記載していますが、 近傍状態を確認する時に範囲外にアクセスする場合があるため構築時に実際のサイズより上下左右に 1 ピクセル分の余白を設けています ( 構築方法は後述します )。そのため、左上の原点位置は ( 0, 0 ) ではなく ( 1, 1 ) となっており、現在位置に対しては指定座標に対して x, y それぞれに 1 を加算してアクセスする必要があります。
EBCOT 処理用関数の内容は先ほど説明した通りです。GetNeighborState は水平・垂直・対角成分の近傍状態を得るための関数で、GetSignificance_CL はコンテキスト・ラベルを返す関数、SignificanceEncode と SignificanceDecode がそれぞれ Significance Propagation Pass 用の符号・復号化関数です。その後に続く GetPolarIndex, GetXorbitOfSign, GetSign_CL で極性ビットに対するコンテキスト・ラベルを決定し、SignEncode と SignDecode で極性ビットを符号・復号化します。最後の SigProPass が全体をまとめてコードブロック全体に対して Significance Propagation Pass を実行します。ここで、符号化と復号化では SigProPass の処理の流れが全く同じなので、SignificanceEncode と SignificanceDecode は SignificanceOp 型、SignEncode と SignDecode は SignOp 型、また後述する MQ-Coder の符号・復号化関数は CoderOp 型としてテンプレート引数にしてまとめて実装しています。これらの関数の型定義はサンプル・プログラムの先頭で行なっていて、後でこれらの関数を呼び出す時に適切な関数を引数に指定することで実体が作られるようにしてあります。あるデータの変換とその逆変換で、メインの処理が全く同じで呼び出す関数だけが異なるという事はよくあります。このような時にテンプレートを利用すると、同じソースを記述する必要がなくなります。
CodeBlock 構造体のメンバ変数 signFlag は初期値がゼロとなっています。この値は SignificanceEncode / SignificanceDecode で現係数のビットが立っていたら 1 になります。そのため、係数が有意かどうかは signFlag がゼロより大きいかどうかで判別することができます。なお、signFlag は次に説明する Magnitude Refinement Pass でさらに値が変化します。
signFlag と pass は独立して変化します。signFlag がゼロで pass が Significance Propagation Pass に移行している場合 ( 現係数は有意ではないが、近傍係数は有意なとき ) や、逆に signFlag が有意で pass は Cleanup Pass である場合 ( Cleanup Pass で現係数が有意と判定されたとき ) などがあります。
その他の注意事項として、SignificanceEncode と SignificanceDecode に isCleanUp という引数があります。これらの関数は後述する Cleanup Pass でも利用するので、どちらから呼び出されたものかを判別するために使っています。Significance Propagation Pass の場合、コンテキスト・ラベルがゼロならば符号化を行わない ( 次の符号化パスにスキップする ) のに対し、Cleanup Pass では必ず処理を行います。
すでに有意であると判定された係数は、Magnitude Refinement Pass を使って符号化されます ( 但し、同一ビットプレーンで、直前に実行される Significance Propagation Pass にて有意と判定された場合は除きます。つまり前に処理されたビットプレーンで有意となった係数に対して使用されるということになります )。
この符号化パスでは、まず対象の係数が Magnitude Refinement Pass を初めて使うのかをチェックし、すでに以前のビットプレーンで使用されていれば、コンテキスト・ラベルとして 16 を割り当てます。また、もし初めて使用されるのであれば全近傍係数の和を算出し、その値が 0 であればコンテキスト・ラベルとして 14 を、そうでなければ 15 を割り当てます。この割り当てられたコンテキスト・ラベルと係数のビットを算出符号器へ入力して符号化を行います。
| ΣHi+ΣVi+ΣDi | 最初のMagnitude Refinement Passか | コンテキスト・ラベル |
|---|---|---|
| - | 最初でない | 16 |
| ≥1 | 最初である | 15 |
| 0 | 14 |
Magnitude Refinement Pass を処理するためのサンプル・プログラムを以下に示します。
/***************************************************************************************** 関数の型定義 *****************************************************************************************/ typedef ContextLabel (*mag_ref_encode_type)( CodeBlock*, Coord< size_t >, unsigned int, Encoder& ); typedef ContextLabel (*mag_ref_decode_type)( CodeBlock*, Coord< size_t >, unsigned int, Decoder& ); /* Magnitude Refinement Passに対するコンテキストラベルを返す codeBlock : コードブロックへのポインタ c : 現係数の位置 戻り値 : コンテキストラベル */ ContextLabel GetMR_CL( CodeBlock* codeBlock, Coord< size_t > c ) { BitPlane& current_bp = (*codeBlock)[c]; // 現係数 ContextLabel cl = 0; // コンテキストラベル switch( current_bp.signFlag ) { case 0: // まだ有意でなければスキップ ( ゼロを返す ) break; case 1: // 直前の Significance Propagation Passで有意に変化 ( 何もせずゼロを返す ) ++( current_bp.signFlag ); // signFlag を次にセット break; case 2: // 最初の Maginitude Refinement Pass ++( current_bp.signFlag ); // signFlag を次にセット unsigned char h, v, d; // 水平・垂直・対角成分の有意ビット数 GetNeighborState( *codeBlock, c, &h, &v, &d ); cl = ( h + v + d >= 1 ) ? CL_MR_CODING_NEIGH1 : CL_MR_CODING_NEIGH0; break; case 3: // 二回目以降の Maginitude Refinement Pass cl = CL_MR_CODING_MULTI; break; } return( cl ); } /* Maginitude Refinement Coding すでに有意判定された係数ビットの符号化/復号化 codeBlock : コードブロックへのポインタ c : 現係数の位置 bit : BitPlaneのビット位置 encoder/decoder : 符号化/復号化処理用関数オブジェクト 戻り値 : コンテクストラベル */ ContextLabel MR_Encode( CodeBlock* codeBlock, Coord< size_t > c, unsigned int bit, Encoder& encoder ) { ContextLabel cl = GetMR_CL( codeBlock, c ); if ( cl > 0 ) encoder( GetBit( (*codeBlock)[c].coeff, bit ), cl ); return( cl ); } ContextLabel MR_Decode( CodeBlock* codeBlock, Coord< size_t > c, unsigned int bit, Decoder& decoder ) { ContextLabel cl = GetMR_CL( codeBlock, c ); if ( cl > 0 ) { if ( decoder( cl ) ) SetBit( &( (*codeBlock)[c].coeff ), bit ); } return( cl ); } /* Magnitude Refinement Pass codeBlock : コードブロックへのポインタ bit : BitPlane のビット位置 magRefOp : Magnitude Refinement Coding function coderOp : 符号化/復号化処理用関数オブジェクト */ template< class MagRefOp, class CoderOp > void MagRefPass( CodeBlock* codeBlock, unsigned int bit, MagRefOp magRefOp, CoderOp& coderOp ) { for ( size_t sy = 0 ; sy < codeBlock->spriteCount() ; ++sy ) { for ( Coord< size_t > c( 0, 0 ) ; c.x < codeBlock->width() ; ++( c.x ) ) { for ( c.y = sy * EBCOT_SPRITE_SIZE ; c.y < ( sy + 1 ) * EBCOT_SPRITE_SIZE ; ++( c.y ) ) { if ( magRefOp( codeBlock, c, bit, coderOp ) > 0 ) (*codeBlock)[c].pass = EBCOT_MR_PASS; } } } }
Magnitude Refinement Pass の処理は他の符号化パスに比べると単純です。GetMR_CL がコンテキスト・ラベルを返すための関数、MR_Encode と MR_Decode が符号・復号化関数で、これらを取りまとめたのが MagRefPass です。ここでも Significance Propagation Pass での場合と同様に、符号化と復号化を一つにまとめるためテンプレートを利用しています。
GetMR_CL では signFlag を使って係数の状態を判別しています。まず、ゼロなら何もせずに処理を終了します。1 だった場合、直前の Significance Propagation Pass で有意に変化したと見なしてさらに signFlag をインクリメントして処理を終了します ( このときは Magnitude Refinement Pass は行われないことに注意して下さい )。これで値は 2 になります。もし値が 2 であれば、それは最初の Magnitude Refinement Pass であると判断し、もう一度 signFlag をインクリメントしてから専用の処理を行います。値が 3 なら二回目以降の Magnitude Refinement Pass なので、専用のコンテキスト・ラベルを返します。
なお、Cleanup Pass で有意に変化した場合、次の Magnitude Refinement Pass では値 2 として処理しなければならないため、後述する Cleanup Pass で帳尻合わせのための処理を行なっています。
現係数がまだ有意にはなっておらず、また全近傍係数も有意ではない ( Significance Propagation Pass でのコンテキスト・ラベルが 0 である ) 場合、Cleanup Pass を使って符号化処理を行います。この時、現ビットプレーン上では現係数が有意となっている可能性があることに注意してください。前に処理されたビットプレーンでまだ有意でなっていないというのが Cleanup Pass で処理するための条件になります。
Cleanup Passでは、最初に sprite 単位で「ランレングス符号化 ( Run-length Coding )」を行うかどうかをチェックします。前にも述べましたが、sprite はコードブロック内部を 4 行 x 1 列の短冊状のエリアに分割したときの一単位となります。まず、sprite 内の 4 つの係数が Cleanup Pass に属し、且つそれらの全近傍係数が有意でないかを判定し、もしこの条件を満たせばランレングス符号化を行って、sprite 内の全係数をまとめて処理します。もし条件を満たしていない場合は、係数を一つずつ Significance Propagation Pass と同じ方法で符号化していきます ( このときは、コンテキスト・ラベルが 0 の場合でも符号化を行います )。
ランレングス符号化では、sprite 内にある 4 つの現係数のビットが立っているかをチェックして、一つでもビットが立っている係数があれば Decision に 1 を、全ての現係数が 0 であれば Decision に 0 を割り当て、ランレングス符号化用のコンテキスト・ラベルである 17 とともに算術符号器へ入力して符号化します。
さらに Decision が 1 だった場合は、どの位置にあるビットが最初の有意係数であるかを下表に示すような 2 ビットの符号で表し、上位・下位ビットの順で符号化します。この時に使用されるされるコンテキスト・ラベルは「Uniform Context」と呼ばれる特殊なものを使います。この符号は確率分布が一様であるため、後で述べる算術符号化での確率推定表も常に推定確率が一定となるインデックスを利用します。
この後、有意係数が見つかった箇所から後の係数について、Significance Propagation Pass を使って符号化を行います。
| 最初に有意係数が見つかった場所 | 符号 |
|---|---|
| 一番上側 | 00 |
| 上から二番目 | 01 |
| 上から三番目 | 10 |
| 上から四番目 | 11 |
Cleanup Pass を処理するためのサンプル・プログラムを以下に示します。
/***************************************************************************************** 関数の型定義 *****************************************************************************************/ typedef unsigned char (*runlength_encode_type)( CodeBlock*, Coord< size_t >, unsigned int, unsigned int, Encoder& ); typedef unsigned char (*runlength_decode_type)( CodeBlock*, Coord< size_t >, unsigned int, unsigned int, Decoder& ); /* 現係数 codeBlock の位置 c の近傍状態が全て有意でなければ true を返す */ bool NotSignNeighborState( const CodeBlock& codeBlock, Coord< size_t > c ) { if ( ( codeBlock.h0( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.h1( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.v0( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.v1( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.d0( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.d1( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.d2( c ) ).signFlag > 0 ) return( false ); if ( ( codeBlock.d3( c ) ).signFlag > 0 ) return( false ); return( true ); } /* Runlength Codingが必要かを判別する 現 SPRITE 内に一つでも Cleanup Pass でない係数があったら不要と判断 codeBlock : コードブロックへの参照 c : 現SPRITEの位置 戻り値 : 必要なら true を返す */ bool NeedRunlengthCoding( const CodeBlock& codeBlock, Coord< size_t > c ) { for ( unsigned int i = 0 ; i < EBCOT_SPRITE_SIZE ; i++ ) { if ( codeBlock( c.x, c.y + i ).pass != EBCOT_CU_PASS ) return( false ); if ( ! NotSignNeighborState( codeBlock, c ) ) return( false ); } return( true ); } /* Run Length Coding ランレングス符号化/復号化 codeBlock : コードブロックへのポインタ c : 現係数の X 座標と現係数のある SPRITE の先頭 Y 座標 subband : サブバンド bit : ビット位置 encoder/decoder : 符号化/復号化処理用関数オブジェクト 戻り値 : ランレングスコンテクストのシンボル( 4 つのビットが全てゼロなら 0 ) */ void RunlengthEncode( CodeBlock* codeBlock, Coord< size_t > c, unsigned int subband, unsigned int bit, Encoder& encoder ) { // SPRITE内に有意係数を持った係数があるか bool runLenSymbol = false; // SPRITEにおいて最初に有意係数が見つかった位置を示すシンボル 上から順に 00, 01, 10, 11 unsigned char uniformSymbol = 0; // SPRITE内の有意係数を探す for ( ; uniformSymbol < EBCOT_SPRITE_SIZE ; ++uniformSymbol ) { if ( GetBit( (*codeBlock)( c.x, c.y + uniformSymbol ).coeff, bit ) ) { // 有意係数が次のビットプレーンで Maginitude Refinement Coding を実行できるように signFlag を 2 にする ( (*codeBlock)( c.x, c.y + uniformSymbol ) ).signFlag = 2; runLenSymbol = true; break; } } // runLenSymbolの符号化 encoder( runLenSymbol, CL_RUNLENGTH_CODING ); if ( ! runLenSymbol ) return; // uniformSymbolの符号化 encoder( ( ( uniformSymbol >> 1 ) & 1 ) != 0, CL_UNIFORM ); encoder( ( uniformSymbol & 1 ) != 0, CL_UNIFORM ); SignEncode( codeBlock, Coord< size_t >( c.x, c.y + uniformSymbol ), encoder ); // 残りの係数をSignificance Coding while ( ++uniformSymbol < EBCOT_SPRITE_SIZE ) { SignificanceEncode( codeBlock, Coord< size_t >( c.x, c.y + uniformSymbol ), subband, bit, encoder, true ); if ( (*codeBlock)( c.x, c.y + uniformSymbol ).signFlag > 0 ) { // 有意の場合、次のビットプレーンで Maginitude Refinement Coding が実行できるように signFlag を 2 にする ( (*codeBlock)( c.x, c.y + uniformSymbol ) ).signFlag = 2; SignEncode( codeBlock, Coord< size_t >( c.x, c.y + uniformSymbol ), encoder ); } } } void RunlengthDecode( CodeBlock* codeBlock, Coord< size_t > c, unsigned int subband, unsigned int bit, Decoder& decoder ) { // SPRITE内に有意係数を持った係数があるか if ( ! decoder( CL_RUNLENGTH_CODING ) ) return; // SPRITEにおいて最初に有意係数が見つかった位置を示すシンボル 上から順に 00, 01, 10, 11 unsigned char uniformSymbol = ( decoder( CL_UNIFORM ) ) ? 2 : 0; if ( decoder( CL_UNIFORM ) ) ++uniformSymbol; SetBit( &( (*codeBlock)( c.x, c.y + uniformSymbol ).coeff ), bit ); SignDecode( codeBlock, Coord< size_t >( c.x, c.y + uniformSymbol ), decoder ); // 有意係数が次のビットプレーンで Maginitude Refinement Coding を実行できるように signFlag を 2 にする (*codeBlock)( c.x, c.y + uniformSymbol ).signFlag = 2; // 残りの係数をSignificance Coding while ( ++uniformSymbol < EBCOT_SPRITE_SIZE ) { SignificanceDecode( codeBlock, Coord< size_t >( c.x, c.y + uniformSymbol ), subband, bit, decoder, true ); if ( (*codeBlock)( c.x, c.y + uniformSymbol ).signFlag > 0 ) { // 有意の場合、次のビットプレーンで Maginitude Refinement Coding が実行できるように signFlag を 2 にする (*codeBlock)( c.x, c.y + uniformSymbol ).signFlag = 2; SignDecode( codeBlock, Coord< size_t >( c.x, c.y + uniformSymbol ), decoder ); } } } /* Cleanup Pass codeBlock : コードブロックへのポインタ subband : サブバンド bit : BitPlane のビット位置 runlengthOp : Runlength Coding function significanceOp : Significance Coding function signOp : Sign Coding function coderOp : 符号化/復号化処理用関数オブジェクト */ template< class RunlengthOp, class SignificanceOp, class SignOp, class CoderOp > void CleanupPass( CodeBlock* codeBlock, unsigned int subband, unsigned int bit, RunlengthOp runlengthOp, SignificanceOp significanceOp, SignOp signOp, CoderOp& coderOp ) { for ( size_t sy = 0 ; sy < codeBlock->spriteCount() ; ++sy ) { for ( Coord< size_t > c( 0, sy * EBCOT_SPRITE_SIZE ) ; c.x < codeBlock->width() ; c.y = sy * EBCOT_SPRITE_SIZE, ++( c.x ) ) { if ( NeedRunlengthCoding( *codeBlock, c ) ) { runlengthOp( codeBlock, c, subband, bit, coderOp ); } else { for ( ; c.y < ( sy + 1 ) * EBCOT_SPRITE_SIZE ; ++( c.y ) ) { BitPlane& current_bp = (*codeBlock)[c]; // 現係数 if ( current_bp.pass != EBCOT_CU_PASS ) continue; significanceOp( codeBlock, c, subband, bit, coderOp, true ); if ( current_bp.signFlag > 0 ) { // 有意の場合、次のビットプレーンで Maginitude Refinement Coding が実行できるように signFlag を 2 にする (*codeBlock)[c].signFlag = 2; signOp( codeBlock, c, coderOp ); current_bp.pass = EBCOT_MR_PASS; } } } } } }
メイン・ルーチンは最後の CleanupPass で、最初に関数 NeedRunlengthCoding を使ってランレングス符号化・復号化が必要かどうかをチェックします。NeedRunlengthCoding は対象の sprite が全て Cleanup Pass で、それらの近傍係数が全て有意でない場合だけ true を返す関数です。ランレングス符号化・復号化が必要と判断されたら、RunlengthEncode / RunlengthDecode を呼び出して処理を行います。この中の処理は先に述べた通りであり、残りビットを Significance Propagation Pass で処理するところも前に示した関数を流用しているだけですが、Cleanup Pass ではコンテキスト・ラベルがゼロの時も符号・復号化を行うため、SignificanceEncode / SignificanceDecode の最後の引数を true としていることに注意して下さい。
最後に、係数を CodeBlock インスタンスへ取り込み EBCOT 符号化を行う処理と、逆に復号化から係数行列へ結果を書き込む処理のサンプル・プログラムを示します。
const unsigned int EBCOT_BITSIZE_BIT = CHAR_BIT; // 最上位ビット位置の符号化ビット数 const unsigned int EBCOT_BITSIZE_MAX = ( 1 << EBCOT_BITSIZE_BIT ) - 1; // 最上位ビット位置の最大値 const unsigned int EBCOT_BLOCKSIZE_BIT = 12; // コードブロックサイズの符号化ビット数 const unsigned int EBCOT_BLOCKSIZE_MAX = ( 1 << EBCOT_BLOCKSIZE_BIT ) - 1; // コードブロックサイズの最大値 /* 有意な係数を持つビット位置を返す codeBlock : コードブロックへの参照 戻り値 : 有意係数を持った最上位のビット位置 (ビット位置は最下位を1とする) 0 の場合は全てが 0 であることを意味する。 */ unsigned int GetSignificantBitPlane( const CodeBlock& codeBlock ) { for ( unsigned int bit = UINT_BIT_SIZE ; bit > 0 ; --bit ) for ( Coord< size_t > c( 0, 0 ) ; c.y < codeBlock.spriteCount() * EBCOT_SPRITE_SIZE ; ++( c.y ) ) for ( c.x = 0 ; c.x < codeBlock.width() ; ++( c.x ) ) if ( GetBit( codeBlock[c].coeff, bit - 1 ) ) return( bit ); return( 0 ); } /* EBCOT符号/復号化メインルーチン codeBlock : コードブロックへのポインタ subband : サブバンド bit_size : 符号化するビット数 ( 最上位ビット + 1 ) lsb : 符号化する最下位ビット( 0 で前ビットが対象 ) lsbPass : 最下位ビットで実行するパス EBCOT_SP_PASS ... Significance Propagation Pass まで EBCOT_MR_PASS ... Magnitude Refinement Pass まで それ以外(EBCOT_CU_PASS) ... Cleanup Pass まで (全て対象) runlength : Runlength Coding function sigPro : Significance Coding function sign : Sign Coding function magRef : Magnitude Refinement Coding function coder : 符号化・復号化処理用関数オブジェクト */ template< class Runlength, class SigPro, class Sign, class MagRef, class Coder > void EbcotMain( CodeBlock* codeBlock, unsigned int subband, unsigned int bit_size, unsigned int lsb, unsigned int lsbPass, Runlength runlength, SigPro sigPro, Sign sign, MagRef magRef, Coder& coder ) { // 最上位ビットは CleanupPass のみ CleanupPass( codeBlock, subband, bit_size, runlength, sigPro, sign, coder ); // 中間ビット while ( bit_size > lsb + 1 ) { --bit_size; SigProPass( codeBlock, subband, bit_size, sigPro, sign, coder ); MagRefPass( codeBlock, bit_size, magRef, coder ); CleanupPass( codeBlock, subband, bit_size, runlength, sigPro, sign, coder ); } // 最下位ビットに対しては途中のパスまでの可能性あり SigProPass( codeBlock, subband, lsb, sigPro, sign, coder ); if ( lsbPass == EBCOT_SP_PASS ) return; MagRefPass( codeBlock, lsb, magRef, coder ); if ( lsbPass == EBCOT_MR_PASS ) return; CleanupPass( codeBlock, subband, lsb, runlength, sigPro, sign, coder ); } /********************************************************* インターフェース群 *********************************************************/ /* ビットプレーンの初期化 サイズが 2 pixel 分大きいのは隣接するピクセルがCode Blockの外部にある場合を考慮している。 そのため、Code Blockの左端は(1,1)から始まる。 size : 係数のサイズ ( Y はスプライト数ではなくビット数を表す ) */ void CodeBlock::init( Coord< size_t > size ) { // Y サイズをスプライト数に変更する size_t y = size.y / EBCOT_SPRITE_SIZE; // 余剰分を加算する if ( size.y % EBCOT_SPRITE_SIZE != 0 ) ++y; bitPlane_.assign( ( size.x + 2 ) * ( y * EBCOT_SPRITE_SIZE + 2 ), BitPlane() ); size_ = size; spriteCount_ = y; } void CodeBlock::init() { init( size_ ); } /* Code Blockの初期化と、係数列からのデータ取り込み coeff : 係数列への参照 coefSize : 係数列の大きさ block : 係数列上で符号化/復号化を行う位置 blockSize : コードブロックの大きさ */ template< class T > void CodeBlock::assign( const vector< T >& coeff, Coord< size_t > coefSize, Coord< size_t > block, Coord< size_t > blockSize ) { if ( block.x >= coefSize.x || block.y >= coefSize.y ) throw std::out_of_range( "CodeBlock::assign : Block coord is out of coeff size." ); Coord< size_t > codeBlockSize( blockSize ); // 確保するサイズ // 確保するエリアが係数列の範囲外にはみ出ている場合はサイズを補正 if ( block.x + blockSize.x > coefSize.x ) codeBlockSize.x = coefSize.x - block.x; if ( block.y + blockSize.y > coefSize.y ) codeBlockSize.y = coefSize.y - block.y; init( codeBlockSize ); for ( Coord< size_t > c( 0, 0 ) ; c.y < height() ; ++( c.y ) ) { size_t ty = block.y + c.y; for ( c.x = 0 ; c.x < width() ; ++( c.x ) ) { size_t tx = block.x + c.x; T t = coeff.at( ty * coefSize.x + tx ); (*this)[c].coeff = abs( round( t ) ); (*this)[c].isPos = ( t > 0 ); } } } template void CodeBlock::assign( const vector< double >& coeff, Coord< size_t > coefSize, Coord< size_t > block, Coord< size_t > blockSize ); template void CodeBlock::assign( const vector< int >& coeff, Coord< size_t > coefSize, Coord< size_t > block, Coord< size_t > blockSize ); /* Code Blockの係数列への取得 coeff : 係数列へのポインタ coefSize : 係数列の大きさ block : 係数列上で符号化/復号化を行った位置 */ template< class T > void CodeBlock::get( vector< T >* coeff, Coord< size_t > coefSize, Coord< size_t > block ) { for ( Coord< size_t > c( 0, 0 ) ; c.y < height() ; ++( c.y ) ) { size_t ty = block.y + c.y; if ( ty >= coefSize.y ) throw std::out_of_range( "CodeBlock::get : Block coord is out of coeff size." ); for ( c.x = 0 ; c.x < width() ; ++( c.x ) ) { size_t tx = block.x + c.x; if ( tx >= coefSize.x ) throw std::out_of_range( "CodeBlock::get : Block coord is out of coeff size." ); T t = (*this)[c].coeff; if ( ! (*this)[c].isPos ) t *= -1; coeff->at( ty * coefSize.x + tx ) = t; } } } template void CodeBlock::get( vector< double >* coeff, Coord< size_t > coefSize, Coord< size_t > block ); template void CodeBlock::get( vector< int >* coeff, Coord< size_t > coefSize, Coord< size_t > block ); /* EBCOT符号化メインルーチン subband : サブバンド lsb : 符号化する最下位ビット( 0 で前ビットが対象 ) lsbPass : 最下位ビットで実行するパス EBCOT_SP_PASS ... Significance Propagation Pass まで EBCOT_MR_PASS ... Magnitude Refinement Pass まで それ以外(EBCOT_CU_PASS) ... Cleanup Pass まで (全て対象) encoder : 符号化処理用関数オブジェクト */ void CodeBlock::ebcotEncoder( unsigned int subband, unsigned int lsb, unsigned int lsbPass, Encoder& encoder ) { unsigned int bit_size = GetSignificantBitPlane( *this ); // 最上位ビット位置 + 1 ( 0-255 ; 8bits ) を符号化 for ( int i = EBCOT_BITSIZE_BIT - 1 ; i >= 0 ; --i ) { bool b = ( ( bit_size >> i ) & 1 ) != 0; encoder( b, CL_UNIFORM ); } // サイズ ( 0 - 8191 ; 12bits )を符号化 for ( int i = EBCOT_BLOCKSIZE_BIT - 1 ; i >= 0 ; --i ) { bool b = ( ( width() >> i ) & 1 ) != 0; encoder( b, CL_UNIFORM ); b = ( ( height() >> i ) & 1 ) != 0; encoder( b, CL_UNIFORM ); } if ( bit_size-- <= lsb ) return; EbcotMain( this, subband, bit_size, lsb, lsbPass, RunlengthEncode, SignificanceEncode, SignEncode, MR_Encode, encoder ); } /* EBCOT復号化メインルーチン subband : サブバンド lsb : 符号化する最下位ビット( 0 で前ビットが対象 ) lsbPass : 最下位ビットで実行するパス EBCOT_SP_PASS ... Significance Propagation Pass まで EBCOT_MR_PASS ... Magnitude Refinement Pass まで それ以外(EBCOT_CU_PASS) ... Cleanup Pass まで (全て対象) decoder : 復号化処理用関数オブジェクト */ void CodeBlock::ebcotDecoder( unsigned int subband, unsigned int lsb, unsigned int lsbPass, Decoder& decoder ) { // 最上位ビット位置 + 1 ( 0-255 ; 8bits ) を復号化 unsigned int bit_size = 0; for ( int i = EBCOT_BITSIZE_BIT - 1 ; i >= 0 ; --i ) bit_size = ( bit_size << 1 ) | ( ( decoder( CL_UNIFORM ) ) ? 1 : 0 ); // サイズ ( 0 - 8191 ; 12bits )を復号化 size_.x = size_.y = 0; for ( int i = EBCOT_BLOCKSIZE_BIT - 1 ; i >= 0 ; --i ) { size_.x = ( size_.x << 1 ) | ( ( decoder( CL_UNIFORM ) ) ? 1 : 0 ); size_.y = ( size_.y << 1 ) | ( ( decoder( CL_UNIFORM ) ) ? 1 : 0 ); } init(); if ( bit_size-- <= lsb ) return; EbcotMain( this, subband, bit_size, lsb, lsbPass, RunlengthDecode, SignificanceDecode, SignDecode, MR_Decode, decoder ); }
CodeBlock クラス用のメンバ関数として init, assign, get, ebcotEncoder, ebcotDecoder が新たに追加されています。init はサイズの変更と値の初期化を行うためのもので、assign は指定した係数列から値を取り込む関数、get は逆に係数列へ書き込む関数です。また EBCOT 符号化を CodeBlock インスタンスへ行うには ebcotEncoder を、復号化には ebcotDecoder を呼び出します。
前にも述べた通り、近傍係数を取得するとき範囲外にアクセスする場合があるため、init での領域確保において実際のサイズより水平・垂直成分ともに 2 だけ余分にサイズを増やし、上下左右に一つの余白が生じるようにしています。
assign では係数列から係数を取り込む位置を block で指定する他、係数列とコードブロックのサイズも引数として渡します。コードブロックのサイズには制約がありましたが、このサンプル・プログラムの中では制限を緩和して、幅と高さの両方に対して 8191 ( 212 - 1 ) まで対応できるようにしています。また、コードブロックが係数列の範囲外であれば自動的にサイズを補正するようになっています。なお、コードブロックのサイズは符号データの先頭に付加するので、係数列へ書き込む get ではコードブロックのサイズは指定不要となっています。
ebcotEncoder は、GetSignificantBitPlane を使ってコードブロック内の最上位ビットを決めた後、その位置とコードブロックのサイズを符号化して EbcotMain 関数を呼び出します。逆に ebcotDecoder は、最上位ビット位置とコードブロックのサイズを復号化してから EbcotMain 関数を呼び出します。どちらも最下位ビットを指定するための lsb と、最下位ビットで符号化する対象のパスを制限するための lsbPass を引数として持ち、任意の個所で符号化・復号化をやめることができるようにしてあります。これらの引数はそのまま EbcotMain へ渡されます。
EbcotMain 関数は、Significance Propagation Pass, Magnitude Refinement Pass, Cleanup Pass 各処理を、ビットプレーンごとに呼び出す処理を行うだけの簡単な処理フローになっています。最上位ビットは Cleanup Pass のみを処理し、lsb で指定した最下位ビットの一つ上までは全ての符号化パスを実行します。最下位ビットは、lsbPass で指定したところで処理を止めるようになっていて、例えば EBCOT_SP_PASS が指定されていた場合は Significance Propagation Pass のみが実行されます。
EbcotMain 関数は 5 つのテンプレート引数を持ち、これらは全て各符号化パス用の関数を表しています。実体が指定されるのは CodeBlock のメンバ関数 ebcotEncoder と ebcotDecoder の中で、ここで今までに紹介した各関数が指定されています。但し、encoder と decoder はまだ実装されていない関数オブジェクトで、これらは次節で紹介する MQ-Coder の中で実装されています。
Significance Propagation Pass で符号化されるデータは近傍の状態を加味したものであり、有意となる可能性が最も高いため、画像品質に対する影響は最も大きいことになります。また、Magnitude Refinement Pass はすでに有意となった係数に対してその精度を高める役割があります。Cleanup Pass で処理される残りの係数は、近傍状態が有意でないことからひずみに対する影響が比較的小さくなります。これらの符号化パス単位で切り捨ての度合いを変化させることで、符号化レートを細かく制御することが可能になるわけです。
実際に一つの sprite を EBCOT で処理する流れを例に示します ( 周囲のspriteは全ビットが有意でないと仮定します )。
| 係数値 | 10 | 1 | 3 | -7 | ||
|---|---|---|---|---|---|---|
| 係数の極性 | + | + | + | - | ||
| 係数のビットプレーン展開 | (3) | 1 | 0 | 0 | 0 | |
| (2) | 0 | 0 | 0 | 1 | ||
| (1) | 1 | 0 | 1 | 1 | ||
| (0) | 0 | 1 | 1 | 1 | ||
| 符号化パス | (3) | CU | 1+ | 0 | 0 | 0 |
| (2) | SP | 0 | ||||
| MR | 0 | |||||
| CU | 0 | 1- | ||||
| (1) | SP | 0 | 1+ | |||
| MR | 1 | 1 | ||||
| CU | ||||||
| (0) | SP | 1+ | ||||
| MR | 0 | 1 | 1 | |||
| CU | ||||||
表の上側に、4 つの係数値をビットプレーン毎に展開した結果が示されています。係数値の最大値は 10 ( 二進数で 1010 ) なので、符号化するビットプレーンは 4 枚 ( 最上位 (3) 〜 最下位 (0) ) になります。
表の下側には、符号化パスの流れが示されています。最上位ビットは Cleanup pass のみで、その後は Significance Propagation pass、Magnitude Refinement pass、Cleanup pass の順で符号化されます。なお、有意になった箇所は赤く、すでに有意な状態になっている箇所は青く示してあります。
近傍に有意ビットが生じた場合、他に優先して Significance Propagation pass が利用される様子がわかると思います。また、有意になるのは Significance Propagation pass か Cleanup pass のいずれかで、一度有意になったら、常に Magnitude Refinement pass で符号化されるようになります。
EBCOT で処理されたビットはコンテキスト・ラベルといっしょに算術符号器である MQ-Coder へ入力されます。MQ-Coder は前章で紹介した Q-Coder と処理の内容は同じですが、コンテキスト・ラベルによって確率推定値を切り替えることができます。前章では概略のみ説明していたため、ここではもう少し詳細な内容を説明したいと思います。
下の表は、MQ-Coder で利用されている確率推定値とその状態推移表です。前章にて説明したように、MQ-Coder では出現頻度をきちんと計算する代わりにこの状態推移表を使って確率推定値を決めています。
Qe は LPS の確率推定値を表し、表内では 16 進数と 10 進数形式で表記されています。MQ-Coder では、16 進数の 0x8000 を10進数の 0.75 と等しいとする固定小数点数を利用しているため、下表のような変換結果になります。
NMPS は MPS を、NLPS は LPS を符号化した場合、次に遷移する index を示しています。基本的に、MPS を符号化すれば Qe は低い値に、逆に LPS を符号化すれば Qe は高い値に遷移していきます。また、MPS と LPS の出現頻度にほとんど差がない状態では、LPS を符号化した時に推定確率の大小関係が逆転する場合があるため、それぞれを表す符号を入れ換える必要があります。そのフラグが、SWITCH になります。
index が 0 から 13 までの推定確率は状態遷移の始動部分に対応しており、最後の 46 は Cleanup Pass で利用される Uniform Context であるため、推定確率は約 0.5 で遷移もしないようになっています。
| index | Qe | NMPS | NLPS | SWITCH | index | Qe | NMPS | NLPS | SWITCH | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 16進 | 10進 | 16進 | 10進 | ||||||||
| 0 | 0x5601 | 0.503937 | 1 | 1 | 1 | 24 | 0x1C01 | 0.164088 | 25 | 22 | 0 |
| 1 | 0x3401 | 0.304715 | 2 | 6 | 0 | 25 | 0x1801 | 0.140650 | 26 | 23 | 0 |
| 2 | 0x1801 | 0.140650 | 3 | 9 | 0 | 26 | 0x1601 | 0.128931 | 27 | 24 | 0 |
| 3 | 0X0AC1 | 0.063012 | 4 | 12 | 0 | 27 | 0x1401 | 0.117212 | 28 | 25 | 0 |
| 4 | 0x0521 | 0.030053 | 5 | 29 | 0 | 28 | 0x1201 | 0.105493 | 29 | 26 | 0 |
| 5 | 0x0221 | 0.012474 | 38 | 33 | 0 | 29 | 0x1101 | 0.099634 | 30 | 27 | 0 |
| 6 | 0x5601 | 0.503937 | 7 | 6 | 1 | 30 | 0x0AC1 | 0.063012 | 31 | 28 | 0 |
| 7 | 0x5401 | 0.492218 | 8 | 14 | 0 | 31 | 0x09C1 | 0.057153 | 32 | 29 | 0 |
| 8 | 0x4801 | 0.421904 | 9 | 14 | 0 | 32 | 0x08A1 | 0.050561 | 33 | 30 | 0 |
| 9 | 0x3801 | 0.328153 | 10 | 14 | 0 | 33 | 0x0521 | 0.030053 | 34 | 31 | 0 |
| 10 | 0x3001 | 0.281277 | 11 | 17 | 0 | 34 | 0x0441 | 0.024926 | 35 | 32 | 0 |
| 11 | 0x2401 | 0.210964 | 12 | 18 | 0 | 35 | 0x02A1 | 0.015404 | 36 | 33 | 0 |
| 12 | 0x1C01 | 0.164088 | 13 | 20 | 0 | 36 | 0x0221 | 0.012474 | 37 | 34 | 0 |
| 13 | 0x1601 | 0.128931 | 29 | 21 | 0 | 37 | 0x0141 | 0.007347 | 38 | 35 | 0 |
| 14 | 0x5601 | 0.503937 | 15 | 14 | 1 | 38 | 0x0111 | 0.006249 | 39 | 36 | 0 |
| 15 | 0x5401 | 0.492218 | 16 | 14 | 0 | 39 | 0x0085 | 0.003044 | 40 | 37 | 0 |
| 16 | 0x5101 | 0.474640 | 17 | 15 | 0 | 40 | 0x0049 | 0.001671 | 41 | 38 | 0 |
| 17 | 0x4801 | 0.421904 | 18 | 16 | 0 | 41 | 0x0025 | 0.000847 | 42 | 39 | 0 |
| 18 | 0x3801 | 0.328153 | 19 | 17 | 0 | 42 | 0x0015 | 0.000481 | 43 | 40 | 0 |
| 19 | 0x3401 | 0.304715 | 20 | 18 | 0 | 43 | 0x0009 | 0.000206 | 44 | 41 | 0 |
| 20 | 0x3001 | 0.281277 | 21 | 19 | 0 | 44 | 0x0005 | 0.000114 | 45 | 42 | 0 |
| 21 | 0x2801 | 0.234401 | 22 | 19 | 0 | 45 | 0x0001 | 0.000023 | 45 | 43 | 0 |
| 22 | 0x2401 | 0.210964 | 23 | 20 | 0 | 46 | 0x5601 | 0.503937 | 46 | 46 | 0 |
| 23 | 0x2201 | 0.199245 | 24 | 21 | 0 | ||||||
次の表は、EBCOT で紹介した各コンテキスト・ラベルに対する index の初期値を示しています。MQ-Coder では確率推定値 Qe をコンテキスト・ラベルごとに設定することができるため、その初期値も内容によって異なります。
MQ-Coder では LPS と MPS を符号化します。0 と 1 を符号化するわけではないことに注意してください。つまり、0 が LPS、1 が MPS として符号化される場合と、1 が LPS、0 が MPS として符号化される場合の二通りがあるということになります。「MPS となる符号」は、処理開始時に 0 と 1 のどちらを MPS として扱うかを示しています。ウェーブレット変換した結果の中で、高周波成分は輪郭部分以外の値が小さくなるため、ビットが 0 になる割合は通常高くなります。そのため、MPSの初期値は 0 と定義されています。
| コンテキスト・ラベル | index初期値 | MPSとなる符号 |
|---|---|---|
| Uniform Context | 46 | 0 |
| Run-length Coding | 3 | 0 |
| 0 | 4 | 0 |
| その他 | 0 | 0 |
確率区間幅 A の初期値は 0x8000 ( = 0.75 ) です。A は処理によって減少していくため、常に 0.75 ≤ A < 1.5 ( 0x8000 ≤ A < 0x10000 ) の範囲になるように、値が 0x8000 より小さくなったら 2 倍 ( つまり 1 ビット左へシフトすることになります ) することで正規化を行います。このとき、符号 C も同様に 2 倍して正規化処理され、一定回数正規化を行ったら上位ビットを出力します。符号 C の構成を以下に示します。
| MSB | LSB | ||
|---|---|---|---|
| 0000 cbbb | bbbb bsss | xxxx xxxx | xxxx xxxx |
上表の中で、"c" は Carry Bit、"b" は出力対象のビット、"s" はキャリー・オーバーに対処するための Spacer Bit、"x" は処理対象となる符号ビットをそれぞれ示しています。符号の計算処理には下位 16 ビットだけが使われます。正規化処理時に繰り上げられたビットは出力対象のビットとして蓄積され、満杯になった時点で符号列として出力されます。
前章で述べたように、確率区間幅 A と符号 C の算出式は実装が単純になるように近似式を利用しているため、LPS と MPS それぞれの区間幅の大きさが逆転することがあり、この場合は LPS と MPS の状態交換を行う必要があります。状態交換とは、LPS 副区間が MPS 副区間の下側にあるという通常の関係が逆転したとき、その位置関係に合わせて符号化・復号化を行うというもので、確率区間幅 A と符号 C の算出式が LPS と MPS のそれぞれで入れ換わる形になります。
状態交換が必要となるのは、MPS 副区間を表す A - Qe が、LPS 副区間を表す Qe より小さくなったときなので、以下の条件式を満たすことになります。
A - Qe < Qe より
Qe > A / 2 --- (4.1)
一方、正規化が必要となるのは、更新後の確率区間幅 ( = Qe ) が必ず 0.75 より小さくなる LPS 符号化のときと、MPS 符号化にて更新後の確率区間幅 ( = A - Qe ) が 0.75 より小さくなるときになります。よって、その条件式は以下のようになります。
A - Qe < 0.75 より
Qe > A - 0.75 --- (4.2)
0.75 ( 2 進数 0.11 ) ≤ A < 1.5 ( 2 進数 1.1 )、0 < Qe < 0.5 ( 2 進数 0.1 ) なので、(4.1) を満たす A と Qe は全て (4.2) 式を満たすことになり、状態交換を行う必要があるのは正規化を行うときのみということになります。
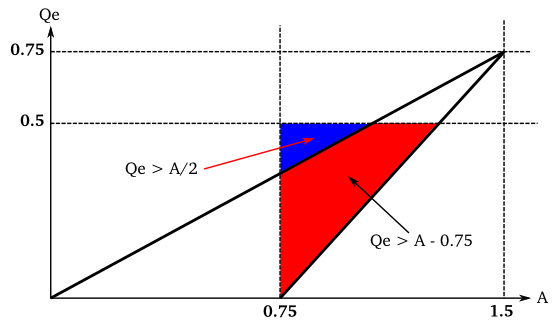 |
正規化の要否、及び状態交換による確率区間幅 A と符号 C の算出式を以下にまとめます。
| LPS | MPS | ||||
|---|---|---|---|---|---|
| A - Qe < Qe | A - Qe ≥ Qe | A - Qe ≥ 0.75 | A - Qe < 0.75 | ||
| A - Qe < Qe | A - Qe ≥ Qe | ||||
| 正規化 | 要 | 不要 | 要 | ||
| 符号 C | C + Qe | C | C + Qe | C | C + Qe |
| 確率区間幅 A | A - Qe | Qe | A - Qe | Qe | A - Qe |
以下に、MQ-Coder 符号化処理のサンプル・プログラムを示します。
/* 初期値用定数 */ enum MQ_INIT_PARAM { // context label毎の Qe の index 初期値 MQ_UNIFORM_INIT = 46, // Uniform Context MQ_RUNLENGTH_INIT = 3, // Run-length Coding MQ_SP_CODING0_INIT = 4, // context label = 0 MQ_CONTEXT_INIT = 0, // その他 // MPS となる Decision の初期値 MQ_MPS_INIT = false, // 確率区間(Range)の初期値 MQ_RANGE_DECIMAL = 15, // Range の二進桁数 - 1 MQ_RANGE_INIT = 1 << MQ_RANGE_DECIMAL, // Range 初期値 }; /* 符号用パラメータ定数 */ enum MQ_CODE_PARAM { /* 符号化用ビット数 0000 cbbb bbbb bsss xxxx xxxx xxxx xxxx */ MQ_CODE_SIGN_BIT_COUNT = 16, // fractional bits x MQ_CODE_SPACER_BIT_COUNT = 3, // spacer bits s MQ_CODE_OUTPUT_BIT_COUNT = CHAR_BIT, // output bits b MQ_CODE_CARRY_BIT_COUNT = 1, // carry bit c /* 復号化用ビット数 Chigh xxxx xxxx xxxx xxxx Clow bbbb bbbb 0000 0000 */ MQ_CODE_CHIGH_BIT_COUNT = 16, // Chigh register MQ_CODE_CLOW_BIT_COUNT = 16, // Clow register // Clow setのためのマスクパターン MQ_CODE_CLOW_MASK = ( 1 << MQ_CODE_CLOW_BIT_COUNT ) - 1, // 符号化用レジスタの符号長 MQ_CODE_SIZE = MQ_CODE_SIGN_BIT_COUNT + MQ_CODE_SPACER_BIT_COUNT + MQ_CODE_OUTPUT_BIT_COUNT + MQ_CODE_CARRY_BIT_COUNT, // carry bit set のためのマスクパターン MQ_CODE_CARRY_SET = 1 << ( MQ_CODE_SIZE - MQ_CODE_CARRY_BIT_COUNT ), // carry bit reset のためのマスクパターン MQ_CODE_CARRY_RESET_MASK = MQ_CODE_CARRY_SET - 1, }; /* Qeと状態遷移用構造体 */ struct Qe_Type { unsigned int Qe; // Qe値 unsigned int nmps; // MPS処理時の次のindex unsigned int nlps; // LPS処理時の次のindex unsigned int sw; // 状態交換フラグ }; /* Context Label毎の推定確率とMPS */ struct CL_Index_Type { unsigned int index; // 状態遷移表のindex bool mps; // MPSとなるDecision // コンストラクタ CL_Index_Type() : index( MQ_CONTEXT_INIT ), mps( MQ_MPS_INIT ) {} }; /* MQ-Coder用のパラメータ */ struct MQ_Coder_Type { unsigned int range; // 確率区間 unsigned int code; // 符号 unsigned int bit_count; // output bitsに登録されたビット数 // コンストラクタ MQ_Coder_Type() : range( MQ_RANGE_INIT ), code( 0 ), bit_count( MQ_CODE_SPACER_BIT_COUNT + MQ_CODE_OUTPUT_BIT_COUNT + MQ_CODE_CARRY_BIT_COUNT ) {} }; /* MQ-Coder 符号化関数オブジェクト */ class MQEncoder { MQ_Coder_Type mqCoder_; // MQ-Coder用のパラメータ std::vector< unsigned char >& out_; // 符号出力先 std::vector< CL_Index_Type > clIndex_; // Context Label毎の推定確率とMPS // 1 バイト出力 void byteOutSub( unsigned int bitStuff ); void byteOut(); void renorme(); // 正規化処理 void codeLPS( const Qe_Type& qe, CL_Index_Type* cl_index ); // LPS 符号化 void codeMPS( const Qe_Type& qe, CL_Index_Type* cl_index ); // MPS 符号化 public: // コンストラクタ MQEncoder( std::vector< unsigned char >& out ); // デストラクタ(符号化の終端処理) ~MQEncoder() { flush(); } // 符号化の終端処理 void flush(); // 符号化処理 void operator()( bool d, ContextLabel cl ); }; /* 状態遷移表 Qe値 MPS処理時の次のindex LPS処理時の次のindex 状態交換フラグ */ Qe_Type Qe[] = { { 0x5601, 1, 1, 1, }, { 0x3401, 2, 6, 0, }, { 0x1801, 3, 9, 0, }, { 0x0AC1, 4, 12, 0, }, { 0x0521, 5, 29, 0, }, { 0x0221, 38, 33, 0, }, { 0x5601, 7, 6, 1, }, { 0x5401, 8, 14, 0, }, { 0x4801, 9, 14, 0, }, { 0x3801, 10, 14, 0, }, { 0x3001, 11, 17, 0, }, { 0x2401, 12, 18, 0, }, { 0x1C01, 13, 20, 0, }, { 0x1601, 29, 21, 0, }, { 0x5601, 15, 14, 1, }, { 0x5401, 16, 14, 0, }, { 0x5101, 17, 15, 0, }, { 0x4801, 18, 16, 0, }, { 0x3801, 19, 17, 0, }, { 0x3401, 20, 18, 0, }, { 0x3001, 21, 19, 0, }, { 0x2801, 22, 19, 0, }, { 0x2401, 23, 20, 0, }, { 0x2201, 24, 21, 0, }, { 0x1C01, 25, 22, 0, }, { 0x1801, 26, 23, 0, }, { 0x1601, 27, 24, 0, }, { 0x1401, 28, 25, 0, }, { 0x1201, 29, 26, 0, }, { 0x1101, 30, 27, 0, }, { 0x0AC1, 31, 28, 0, }, { 0x09C1, 32, 29, 0, }, { 0x08A1, 33, 30, 0, }, { 0x0521, 34, 31, 0, }, { 0x0441, 35, 32, 0, }, { 0x02A1, 36, 33, 0, }, { 0x0221, 37, 34, 0, }, { 0x0141, 38, 35, 0, }, { 0x0111, 39, 36, 0, }, { 0x0085, 40, 37, 0, }, { 0x0049, 41, 38, 0, }, { 0x0025, 42, 39, 0, }, { 0x0015, 43, 40, 0, }, { 0x0009, 44, 41, 0, }, { 0x0005, 45, 42, 0, }, { 0x0001, 45, 43, 0, }, { 0x5601, 46, 46, 0, }, }; /********************************************************* 符号化処理 内部ルーチン群 *********************************************************/ /* context label 毎の Qe の index を初期化する */ void InitCLIndex( vector< CL_Index_Type >* cp ) { (*cp)[CL_SP_CODING_0].index = MQ_SP_CODING0_INIT; // 全近傍がゼロ (*cp)[CL_RUNLENGTH_CODING].index = MQ_RUNLENGTH_INIT; // Runlength (*cp)[CL_UNIFORM].index = MQ_UNIFORM_INIT; // Uniform context } /* 1 バイト出力する(サブ・ルーチン) bitStuff : Bit Stuffingを行うビット数 ( 0...行わない / 1...行う ) */ void MQEncoder::byteOutSub( unsigned int bitStuff ) { /* cbbb bbbb bsss xxxx xxxx xxxx xxxx -> cbbb bbbb | bsss xxxx xxxx xxxx xxxx ( bitStuff = 1 ) -> bbbb bbbb | 0sss xxxx xxxx xxxx xxxx ( bitStuff = 0 ) */ out_.push_back( mqCoder_.code >> ( MQ_CODE_SIGN_BIT_COUNT + MQ_CODE_SPACER_BIT_COUNT + bitStuff ) ); mqCoder_.code &= ( 1 << ( MQ_CODE_SIGN_BIT_COUNT + MQ_CODE_SPACER_BIT_COUNT + bitStuff ) ) - 1; // Bit Stuffingを行った場合は次の出力までのカウントを一つ減らす mqCoder_.bit_count = MQ_CODE_OUTPUT_BIT_COUNT - bitStuff; } /* 1 バイト出力する */ void MQEncoder::byteOut() { if ( out_.size() == 0 ) { byteOutSub( 0 ); return; } if ( out_.back() == 0xFF ) { byteOutSub( 1 ); return; } // Carry bit がセットされている場合 if ( mqCoder_.code >= 1 << ( MQ_CODE_SIZE - MQ_CODE_CARRY_BIT_COUNT ) ) { ++( out_.back() ); // 前の出力バイトに 1 を加える if ( out_.back() == 0xFF ) { // Carry Bit をリセットしてから Bit Stuffing mqCoder_.code &= MQ_CODE_CARRY_RESET_MASK; byteOutSub( 1 ); return; } } byteOutSub( 0 ); } /* 符号化処理用の正規化処理 */ void MQEncoder::renorme() { do { mqCoder_.range <<= 1; mqCoder_.code <<= 1; --( mqCoder_.bit_count ); if ( mqCoder_.bit_count == 0 ) byteOut(); } while( ( mqCoder_.range & MQ_RANGE_INIT ) == 0 ); } /* LPSの符号化 qe : 現在のContext Labelに対する状態遷移装置への参照 ( Qe[index[CL]] ) clIndex : 現在の Context Label に対する index と MPS */ void MQEncoder::codeLPS( const Qe_Type& qe, CL_Index_Type* clIndex ) { mqCoder_.range -= qe.Qe; // Qe = LPS確率区間 ; Range - Qe = MPS確率区間 if ( mqCoder_.range < qe.Qe ) { /* +-----LPS-----+--MPS--+ +-------+ */ mqCoder_.code += qe.Qe; } else { /* +--LPS--+-----MPS-----+ +-------+ */ mqCoder_.range = qe.Qe; } if ( qe.sw == 1 ) clIndex->mps = ! clIndex->mps; clIndex->index = qe.nlps; renorme(); } /* MPSの符号化 qe : 現在のContext Labelに対する状態遷移装置へのポインタ ( Qe[index[CL]] ) clIndex : 現在の Context Label に対する index と MPS */ void MQEncoder::codeMPS( const Qe_Type& qe, CL_Index_Type* clIndex ) { mqCoder_.range -= qe.Qe; // Qe = LPS確率区間 ; Range - Qe = MPS確率区間 // MPS < 0.75 if ( ( mqCoder_.range & MQ_RANGE_INIT ) == 0 ) { if ( mqCoder_.range < qe.Qe ) { /* +-----LPS-----+--MPS--+ +-------------+ */ mqCoder_.range = qe.Qe; } else { /* +--LPS--+-----MPS-----+ +-------------+ */ mqCoder_.code += qe.Qe; } clIndex->index = qe.nmps; renorme(); return; } /* MPS >= 0.75 +--LPS--+-----MPS-----+ +-------------+ */ mqCoder_.code += qe.Qe; } /********************************************************* 符号化処理 インターフェース群 *********************************************************/ /* MEQncoder コンストラクタ out : 符号の出力先への参照 */ MQEncoder::MQEncoder( std::vector< unsigned char >& out ) : mqCoder_(), out_( out ), clIndex_( CL_SIZE ) { InitCLIndex( &clIndex_ ); } /* 符号化の終端処理 */ void MQEncoder::flush() { unsigned int temp = mqCoder_.code + mqCoder_.range; // code + range = 確率区間の上限 mqCoder_.code |= ( 1 << MQ_CODE_SIGN_BIT_COUNT ) - 1; // 符号ビット部分にできるだけ多く1をセットする // 確率区間の上限より大きい場合は、符号ビットの先頭ビットをOFFにする if ( mqCoder_.code >= temp ) mqCoder_.code -= MQ_RANGE_INIT; // 残りのOUTPUT BITを符号列に出力する for ( unsigned int i = 0 ; i < 3 ; i++ ) { mqCoder_.code <<= mqCoder_.bit_count; byteOut(); } // 最後にゼロを出力(Bit Stuffing の伝播を防ぐため) out_.push_back( 0 ); } /* MQ Coder符号化処理 d : Decision cl : Context Label */ void MQEncoder::operator()( bool d, ContextLabel cl ) { CL_Index_Type* cp = &( clIndex_[cl] ); // 対象の Context Label の index と MPS if ( d == cp->mps ) { return( codeMPS( Qe[cp->index], cp ) ); } else { return( codeLPS( Qe[cp->index], cp ) ); } }
符号化を行うための関数オブジェクトとして MQEncoder クラスを用意しています。これを EBCOT 符号化時に ebcotEncoder にて呼び出すことで、MQ-Coder による符号化ができる仕組みになっています。このような形にしたのは、後で符号化の処理方法を切り替えることができるようにするためです ( 実際、EBCOT 処理の確認用に、渡された Decision をそのまま出力する処理を作成してデバッグに利用しました )。
LPS、MPS それぞれの符号化はメンバ関数 codeLPS と codeMPS で行われています。この中で MPS 副区間 ( A - Qe ) と LPS 副区間 ( Qe ) の大小関係から状態交換の要否をチェックしています。また、MPS 符号化では確率区間幅が 0.75 より小さい場合、正規化処理 ( renorme ) を行っています。LPS 符号化では確率区間幅が必ず 0.75 より小さくなるため、常に正規化処理を行います。
正規化処理 ( renorme ) では、確率区間幅と符号を 2 倍 ( 左に一つだけビットシフト ) して、出力ビットが満杯になった時点で符号列へ出力 ( byteOut ) する処理を、確率区間幅が 0.75 以上になるまで繰り返しています。なお、0.75 は 16 進数では 0x8000 で表現されるため、最上位ビットが立っているかどうかで判別することができます。
符号列の出力 ( byteOut ) では、必要に応じて Bit Stuffing を行っています。まず、前に出力された符号列の要素が 0xFF であれば、キャリー・オーバーによるビット・シフトの伝播が発生する可能性があるので Bit Stuffing が必要であると判断されます。次に符号の Carry Bit が立っているかをチェックして、もし立っていたら、前に出力された符号列の要素に 1 を加えてから Carry Bit をリセットします。ここで再度、前に出力された符号列の要素が 0xFF であるかをチェックして、もしそうであればやはり Bit Stuffing が必要であると判断します。
実際の符号列の出力は byteOutSub で行われます。Bit Stuffing を行う場合、Carry Bit と、出力対象のビットのうち上位 7 ビットを出力し、残り 1 ビットの出力対象ビットは次の出力時まで持ち越します。そのため、次の符号列出力までのカウントは一つ減らすことになります。
符号化する対象を全て処理したら、後始末のため残りのビット列を出力する必要があります。この処理はメンバ関数 flush が行い、デストラクタの中でも呼び出されるようになっています。ここでは残った符号を符号列に出力すればよいのですが、このとき符号ビット部分をできるだけ立てて、出力ビットと符号ビットの計 3 バイト分を出力しています。これは出力ビットだけを単純に必要分だけビットシフトして処理した場合、誤差の関係により復号化で誤ったビットを出力することを防ぐためで、それまでに符号化された値にピッタリになるように全ビットを立てています ( 10 進数で 3.xxx... という数値を 3.999... としてちょうど 4 としていると考えればわかりやすいと思います )。実際、単純なビットシフトだけにすると、最下位のビットプレーンに対していくつかの復号処理でエラーが発生します。符号が確率区間内に確実に収まるよう、このような処理をしているわけです。しかし単純に全ビットを立ててしまった場合、逆に確率区間を越えてしまう場合があり、そうなるとやはり復号化でエラーが発生してしまうため、確率区間の上限 ( 符号と確率区間幅の和 ) と比較して、大きければ符号ビットの最上位を 0 にします。確率区間幅は 0.75 以上であることが保障されているため、これで確実に確率区間幅内に符号を収めることができます。なお、最後にゼロを余分に出力しているのは、次のコードブロックを続けて処理する場合に Bit Stuffing が発生するのを防ぐためです。
復号化処理の場合、符号 C の構成が変わります。以下にその構成を示します。
| MSB | LSB | ||
|---|---|---|---|
| Chigh | Clow | ||
| xxxx xxxx | xxxx xxxx | bbbb bbbb | 0000 0000 |
算術圧縮処理の復号化で行われる、符号 C の確率区間 A 内における位置の確認には、上位 16 ビットの Chigh だけが使われます。正規化処理によって、符号列の次のデータから一ビットずつデータを送るために、そのデータは下位 16 ビット部分 ( Clow ) の上位 8 ビットの位置に登録しておき、全てを使いきったらまた符号列の次のデータを読み込む処理を繰り返します。
状態交換の発生は復号化でも発生します。よって、Chigh が LPS と MPS のどちら側にあるかを判別した後さらに、符号化の場合と同じような両者の副区間の大小比較を行う必要があります。また、MPS 復号化の場合は、MPS 副区間と 0.75 を比較して正規化が必要であるかを判別するのも符号化のときと同様です。
以下はMQ-Coder復号化処理のサンプル・プログラムです。
/* MQ-Coder 復号化関数オブジェクト */ class MQDecoder { MQ_Coder_Type mqCoder_; // MQ-Coder用のパラメータ std::vector< unsigned char >::const_iterator in_; // 符号入力先 std::vector< unsigned char >::const_iterator end_; // 符号列の末尾の次 std::vector< CL_Index_Type > clIndex_; // Context Label毎の推定確率とMPS unsigned int preVal_; // 前回に入力した値(Bit Stuffing確認用) // 1 バイト入力 void byteInSub( unsigned int bit_stuff ); void byteIn(); void renormd(); // 正規化処理 bool mpsExchange( const Qe_Type& qe, CL_Index_Type* cl_index ); // 復号器のMPSパス状態交換 bool lpsExchange( const Qe_Type& qe, CL_Index_Type* cl_index ); // 復号器のLPSパス状態交換 public: // コンストラクタ MQDecoder( std::vector< unsigned char >::const_iterator in, std::vector< unsigned char >::const_iterator end ); // 復号化処理 bool operator()( ContextLabel cl ); }; /********************************************************* 復号化処理 内部ルーチン群 *********************************************************/ /* 1 バイト入力する(サブ・ルーチン) bitStuff : Bit Stuffingを行うビット数(0...行わない/1...行う) */ void MQDecoder::byteInSub( unsigned int bitStuff ) { /* 0000 0000 0000 0000 0000 0000 0000 0000 -> 0000 0000 0000 000b bbbb bbb0 0000 0000 ( bitStuff = 1 ) -> 0000 0000 0000 0000 bbbb bbbb 0000 0000 ( bitStuff = 0 ) */ preVal_ = *in_++; // 前の値は Bit Stuffing 用に保持 ( 同時に char->int 型変換 ) mqCoder_.code += preVal_ << ( MQ_CODE_CLOW_BIT_COUNT - MQ_CODE_OUTPUT_BIT_COUNT + bitStuff ); // Bit Stuffingを行った場合は次の入力までのカウントを一つ減らす mqCoder_.bit_count = MQ_CODE_OUTPUT_BIT_COUNT - bitStuff; } /* 1 バイト入力する */ void MQDecoder::byteIn() { // 終端まで達した場合はそれ以上読み込まない if ( in_ == end_ ) return; if ( preVal_ == 0xFF ) { byteInSub( 1 ); // Bit Stuffing を行う } else { byteInSub( 0 ); // Bit Stuffing を行わない } } /* 復号化処理用の正規化処理 */ void MQDecoder::renormd() { do { if ( mqCoder_.bit_count == 0 ) byteIn(); mqCoder_.range <<= 1; mqCoder_.code <<= 1; mqCoder_.bit_count--; } while ( mqCoder_.range < MQ_RANGE_INIT ); } /* 復号器のMPSパス状態交換 qe : 現在のContext Labelに対する状態遷移装置への参照 ( Qe[index[CL]] ) clIndex : 現在のContext Labelに対するindexとMPS 戻り値 : Decision */ bool MQDecoder::mpsExchange( const Qe_Type& qe, CL_Index_Type* clIndex ) { bool d; // Decision /* +-----LPS-----+--MPS--+ -> D = LPS */ if ( mqCoder_.range < qe.Qe ) { d = ! clIndex->mps; if ( qe.sw == 1 ) clIndex->mps = ! clIndex->mps; clIndex->index = qe.nlps; } /* +--LPS--+-----MPS-----+ -> D = MPS */ else { d = clIndex->mps; clIndex->index = qe.nmps; } return( d ); } /* 復号器のLPSパス状態交換 qe : 現在のContext Labelに対する状態遷移装置への参照 ( Qe[index[CL]] ) clIndex : 現在のContext Labelに対するindexとMPS 戻り値 : Decision */ bool MQDecoder::lpsExchange( const Qe_Type& qe, CL_Index_Type* clIndex ) { bool d; // Decision /* +-----LPS-----+--MPS--+ -> D = MPS */ if ( mqCoder_.range < qe.Qe ) { mqCoder_.range = qe.Qe; d = clIndex->mps; clIndex->index = qe.nmps; } /* +--LPS--+-----MPS-----+ -> D = LPS */ else { mqCoder_.range = qe.Qe; d = ! clIndex->mps; if ( qe.sw == 1 ) clIndex->mps = ! clIndex->mps; clIndex->index = qe.nlps; } return( d ); } /********************************************************* 復号化処理 インターフェース群 *********************************************************/ /* 復号化処理用の初期化 [ in, end ) : 復号化する符号の先頭から末尾までの範囲 */ MQDecoder::MQDecoder( vector< unsigned char >::const_iterator in, vector< unsigned char >::const_iterator end ) : mqCoder_(), in_( in ), end_( end ), clIndex_( CL_SIZE ), preVal_( 0 ) { if ( in_ == end_ ) throw std::out_of_range( "MQDecoder constructor : No more data for decode." ); InitCLIndex( &clIndex_ ); unsigned int code = *in_++; // char->int 型変換 mqCoder_.code = code << MQ_CODE_CLOW_BIT_COUNT; byteIn(); mqCoder_.code <<= ( MQ_RANGE_DECIMAL - MQ_CODE_OUTPUT_BIT_COUNT ); mqCoder_.bit_count -= MQ_RANGE_DECIMAL - MQ_CODE_OUTPUT_BIT_COUNT; mqCoder_.range = MQ_RANGE_INIT; } /* MQ Coder復号化処理 cl : Context Label 戻り値 : Decision */ bool MQDecoder::operator()( ContextLabel cl ) { bool d; // Decision CL_Index_Type* cp = &( clIndex_[cl] ); // 対象の Context Label の index と MPS const Qe_Type& qe = Qe[cp->index]; // 対象の Context Label の推定確率と状態遷移 unsigned int h_code = mqCoder_.code >> 16; // Chigh = 符号の上位16ビット mqCoder_.range -= qe.Qe; // Qe = LPS確率区間 ; Range - Qe = MPS確率区間 /* Chigh +-+ +--LPS--+-----MPS-----+ ↓ +-------+ +-+ Chigh */ if ( h_code < qe.Qe ) { d = lpsExchange( qe, cp ); renormd(); } /* Chigh +----------+ +--LPS--+-----MPS-----+ ↓ +-------------+ +--+ Chigh */ else { // ChighからLPS確率区間を引く mqCoder_.code -= qe.Qe << MQ_CODE_CLOW_BIT_COUNT; // A < 0.75ならMPS_EXCHANGEへ if ( ( mqCoder_.range & MQ_RANGE_INIT ) == 0 ) { d = mpsExchange( qe, cp ); renormd(); } else { d = cp->mps; } } return( d ); }
復号化用の関数オブジェクトとして MQDecoder を用意します。メンバ関数の構成は MQEncoder とほとんど変わりませんが、復号化の場合はコンテキスト・ラベルを受け取り Decision を戻り値として返す形になっています。
状態交換が発生することで処理の流れが少々分かりにくいかも知れませんが、基本的な処理の内容は「Range Coder」と変わりません。値が LPS と MPS の二つしかないことや、確率推定値を有限オートマトンで表現することで、却って Range Coder よりもシンプルになっています。よくわからないという方は、前章の Range Coder にて示した数直線による処理の流れを併せて見ていただくと理解しやすいのではないかと思います。
EBCOT と MQ-Coder を使って、実際にウェーブレット変換結果を符号化してみます。符号化・復号化に利用したテスト・プログラムは以下のような構成になっています。
// 符号・復号化は MQ-Coder typedef MQEncoder Encoder; typedef MQDecoder Decoder; Coord< int > destSize; // 画像サイズ(変換する回数に応じて余白を付加したサイズ) vector< vector< WaveletCoef< T > > >wc( 3 ); // ウェーブレット変換結果 unsigned int level; // ウェーブレット変換回数 vector< int > lsb( 3 ); // 符号化する最下位ビット(YUV各成分) vector< int > pass( 3 ); // 最下位ビットに対する最終符号化パス(YUV各成分) Coord< size_t > blockSize; // コードブロックの大きさ // YUVへ変換 : // Wavelet 変換 : // EBCOT/MQ-Coder 符号化 vector< vector< unsigned char > > code( 3 ); // EBCOT 符号(YUV各成分) vector< vector< size_t > > start( 3 ); // EBCOT 符号の開始位置(YUV各成分) // YUV 各成分に対して実行 for ( size_t i = 0 ; i < code.size() ; ++i ) { Coord< size_t > sz( destSize ); // 係数のサイズ CodeBlock codeBlock; // コードブロック Encoder* encoder = new Encoder( code[i] ); // --- (1) start[i].push_back( 0 ); // 最初はゼロからスタート for ( size_t j = 0 ; j < level ; ++j ) { sz.x >>= 1; sz.y >>= 1; // 係数はレベルごとに半分に // ウェーブレット係数(LH/HL/HH) for ( size_t y = 0 ; y < sz.y ; y += blockSize.y ) { for ( size_t x = 0 ; x < sz.x ; x += blockSize.x ) { //Encoder* encoder = new Encoder( code[i] ); // --- (2) codeBlock.assign( wc[i][j].wv, sz, Coord< size_t >( x, y ), blockSize ); codeBlock.ebcotEncoder( EBCOT_SUBBAND_LH, lsb[i], pass[i], *encoder ); codeBlock.assign( wc[i][j].wh, sz, Coord< size_t >( x, y ), blockSize ); codeBlock.ebcotEncoder( EBCOT_SUBBAND_HL, lsb[i], pass[i], *encoder ); codeBlock.assign( wc[i][j].wd, sz, Coord< size_t >( x, y ), blockSize ); codeBlock.ebcotEncoder( EBCOT_SUBBAND_HH, lsb[i], pass[i], *encoder ); //delete encoder; // --- (2) start[i].push_back( code[i].size() ); // 終端 = 次の開始位置 } } } // スケーリング係数(LL) for ( size_t y = 0 ; y < sz.y ; y += blockSize.y ) { for ( size_t x = 0 ; x < sz.x ; x += blockSize.x ) { //Encoder* encoder = new Encoder( code[i] ); // --- (2) codeBlock.assign( wc[i][level - 1].s, sz, Coord< size_t >( x, y ), blockSize ); codeBlock.ebcotEncoder( EBCOT_SUBBAND_LL, lsb[i], pass[i], *encoder ); //delete encoder; // --- (2) start[i].push_back( code[i].size() ); // 終端 = 次の開始位置 } } delete encoder; // --- (1) } // EBCOT/MQ-Coder 復号化 // YUV 各成分に対して実行 for ( size_t i = 0 ; i < code.size() ; ++i ) { size_t index = 0; // EBCOT 符号の開始位置を示す添字 Coord< size_t > sz( destSize ); // 係数のサイズ CodeBlock codeBlock; // コードブロック Decoder decoder( code[i].begin(), code[i].end() ); // --- (1) for ( size_t j = 0 ; j < level ; ++j ) { sz.x >>= 1; sz.y >>= 1; for ( size_t y = 0 ; y < sz.y ; y += blockSize.y ) { for ( size_t x = 0 ; x < sz.x ; x += blockSize.x ) { //Decoder decoder( code[i].begin() + start[i][index], code[i].begin() + start[i][index + 1] ); // ---(2) codeBlock.ebcotDecoder( EBCOT_SUBBAND_LH, lsb[i], pass[i], decoder ); codeBlock.get( &( wc[i][j].wv ), sz, Coord< size_t >( x, y ) ); codeBlock.ebcotDecoder( EBCOT_SUBBAND_HL, lsb[i], pass[i], decoder ); codeBlock.get( &( wc[i][j].wh ), sz, Coord< size_t >( x, y ) ); codeBlock.ebcotDecoder( EBCOT_SUBBAND_HH, lsb[i], pass[i], decoder ); codeBlock.get( &( wc[i][j].wd ), sz, Coord< size_t >( x, y ) ); ++index; } } } for ( size_t y = 0 ; y < sz.y ; y += blockSize.y ) { for ( size_t x = 0 ; x < sz.x ; x += blockSize.x ) { //Decoder decoder( code[i].begin() + start[i][index], code[i].begin() + start[i][index + 1] ); // --- (2) codeBlock.ebcotDecoder( EBCOT_SUBBAND_LL, lsb[i], pass[i], decoder ); codeBlock.get( &( wc[i][level - 1].s ), sz, Coord< size_t >( x, y ) ); ++index; } } } // Wavelet 逆変換 : // 画像へ変換 :
テスト・プログラムの中で Encoder と Decoder に (1), (2) とコメントが記載され、(2) についてはコメント・アウトされています。(1) の方法は、YUV 各成分ごとに符号・復号化処理を連続して行った場合で、確率推移は各成分単位で更新されることになるのに対し、(2) の方法はコードブロックごとに細分化して処理を行うため、コードブロック単位で確率推移は初期化されることになります。これらは画質には影響しませんが、符号サイズが変化します。
画質に影響するパラメータは、lsb と pass の二つです。lsb をゼロ、pass を EBCOT_CU_PASS とすれば、全てのビットが符号化されるのに対し、lsb を大きくすれば下位のビットプレーンが、pass を EBCOT_SP_PASS や EBCOT_MR_PASS にすれば、最下位ビットに対して指定した符号化パスより後が処理対象外となります。その分、符号サイズは小さくなりますが、画質は悪くなります。
下表は、「風景」画像を使った符号化処理において、ウェーブレット変換のタイプによる圧縮率の差を示したものです。どの結果も、全ビット・符号化パスを符号化対象とし、ウェーブレット変換は一回のみ、コードブロックの大きさは画像サイズと同じ ( 1024 x 768 ) としています。また、符号化は上記サンプル・プログラムの中の (2) のタイミングで実施しています。
| 画像 | Haar | Daubechies2 | Daubechies3 | Daubechies4 | J2k 5/3 | J2k 9/7 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | |
| 画像1 | 919901 | 38.99 | 1561360 | 66.18 | 1268712 | 53.77 | 906650 | 38.43 | 1052531 | 44.61 | 859222 | 36.42 |
| 画像2 | 931780 | 39.49 | 1575613 | 66.78 | 1314038 | 55.70 | 957449 | 40.58 | 1061124 | 44.98 | 906961 | 38.44 |
| 画像3 | 801563 | 33.97 | 1505355 | 63.81 | 1195208 | 50.66 | 811336 | 34.39 | 925870 | 39.24 | 749568 | 31.77 |
| 画像4 | 1194630 | 50.63 | 1784807 | 75.65 | 1530815 | 64.88 | 1140308 | 48.33 | 1306231 | 55.37 | 1104318 | 46.81 |
| 画像5 | 957901 | 40.60 | 1583838 | 67.13 | 1294845 | 54.88 | 933145 | 39.55 | 1025723 | 43.48 | 879884 | 37.29 |
| 画像6 | 1090531 | 46.22 | 1672892 | 70.91 | 1404188 | 59.52 | 1022378 | 43.33 | 1200928 | 50.90 | 982001 | 41.62 |
| 画像7 | 765921 | 32.46 | 1469543 | 62.29 | 1159535 | 49.15 | 773601 | 32.79 | 888829 | 37.67 | 713621 | 30.25 |
| 画像8 | 871826 | 36.95 | 1529055 | 64.81 | 1229723 | 52.12 | 838579 | 35.54 | 987329 | 41.85 | 796638 | 33.77 |
| 画像9 | 1066002 | 45.18 | 1704066 | 72.23 | 1433435 | 60.76 | 1038095 | 44.00 | 1215099 | 51.50 | 993449 | 42.11 |
| 画像10 | 411121 | 17.43 | 1061602 | 45.00 | 759135 | 32.18 | 423568 | 17.95 | 474037 | 20.09 | 373037 | 15.81 |
| 平均 | 901118 | 38.19 | 1544813 | 65.48 | 1258963 | 53.36 | 884511 | 37.49 | 1013770 | 42.97 | 835870 | 35.43 |
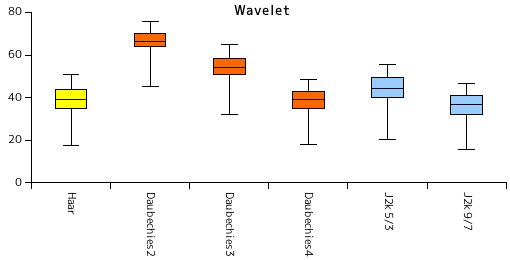 |
図表 5-1. の中で、Haar は Haar のウェーブレット変換、Daubechies2 から Daubechies4 までは N = 2, 3, 4 の数列に対するドビッシーのウェーブレット変換、J2k 5/3 と J2k 9/7 は JPEG2000 で採用されている変換方法で、前者が 5/3 可逆フィルタ、後者が 9/7 非可逆フィルタになります。最も圧縮率の高いのは 9/7 非可逆フィルタでしたが、Haar と Daubechies4 もほとんど大差はなく、処理が単純な分、Haar はかなり有効な手法だと思います。
なお、前章で使用した Range Coder では画像をそのまま符号化したのでほとんど圧縮できませんでした。EBCOT と MQ-Coder を利用することで圧縮率は大きく改善されることがこの結果から確認できます。
ウェーブレット変換の中では 9/7 非可逆フィルタ変換が最も圧縮率が高かったため、以下はこの変換方法に固定して他の条件は同一とします。今度はコードブロックのサイズを変化させた時の圧縮率の変化を下表に示します。
| 画像 | (16,16) | (32,32) | (64,64) | (128,128) | (256,256) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | |
| 画像1 | 960584 | 40.71 | 891354 | 37.78 | 869865 | 36.87 | 862813 | 36.57 | 860356 | 36.47 |
| 画像2 | 998451 | 42.32 | 932766 | 39.54 | 911705 | 38.64 | 905736 | 38.39 | 904478 | 38.34 |
| 画像3 | 855886 | 36.28 | 785930 | 33.31 | 761760 | 32.29 | 753693 | 31.95 | 750785 | 31.82 |
| 画像4 | 1192656 | 50.55 | 1131582 | 47.96 | 1112331 | 47.15 | 1107382 | 46.94 | 1106553 | 46.90 |
| 画像5 | 981157 | 41.59 | 914697 | 38.77 | 891886 | 37.80 | 883946 | 37.47 | 881925 | 37.38 |
| 画像6 | 1083327 | 45.92 | 1014330 | 42.99 | 991261 | 42.02 | 984219 | 41.72 | 982487 | 41.64 |
| 画像7 | 810564 | 34.36 | 746539 | 31.64 | 725551 | 30.75 | 718528 | 30.46 | 715934 | 30.35 |
| 画像8 | 898263 | 38.07 | 829421 | 35.16 | 807168 | 34.21 | 800390 | 33.92 | 798440 | 33.84 |
| 画像9 | 1081695 | 45.85 | 1018540 | 43.17 | 998279 | 42.31 | 993474 | 42.11 | 992611 | 42.07 |
| 画像10 | 477535 | 20.24 | 411220 | 17.43 | 388158 | 16.45 | 378598 | 16.05 | 375538 | 15.92 |
| 平均 | 934012 | 39.59 | 867638 | 36.78 | 845796 | 35.85 | 838878 | 35.56 | 836911 | 35.47 |
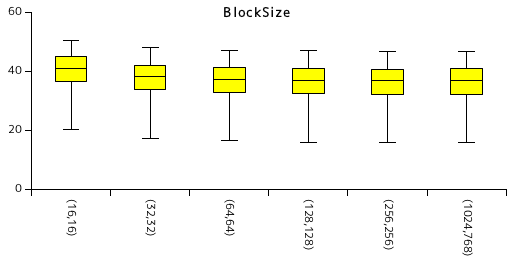 |
ブロックサイズを変化させても圧縮率にはほとんど影響はしません。コードブロックが細分化されると推定確率は毎回初期化されるので、画像全体の傾向が同じならコードブロックは大きい方が、逆に局所的に異なる傾向を持てば小さい方が有利になると考えていましたが、予想に反して差異はほとんどありませんでした。「風景」画像だけではなく「アニメ調」画像に対しても同じテストを行いましたが、やはり差異はそれほどありませんでした。
| 画像 | 1 | 2 | 3 | 4 | ||||
|---|---|---|---|---|---|---|---|---|
| Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | |
| 画像1 | 569681 | 24.15 | 374915 | 15.89 | 231603 | 9.817 | 128570 | 5.450 |
| 画像2 | 633688 | 26.86 | 440212 | 18.66 | 292212 | 12.39 | 176875 | 7.497 |
| 画像3 | 460052 | 19.50 | 279989 | 11.87 | 155877 | 6.607 | 74140 | 3.142 |
| 画像4 | 781490 | 33.12 | 549642 | 23.30 | 363221 | 15.40 | 216720 | 9.186 |
| 画像5 | 605608 | 25.67 | 391458 | 16.59 | 229385 | 9.723 | 127211 | 5.392 |
| 画像6 | 643052 | 27.26 | 439410 | 18.62 | 278112 | 11.79 | 154477 | 6.548 |
| 画像7 | 420145 | 17.81 | 245341 | 10.40 | 133889 | 5.675 | 65096 | 2.759 |
| 画像8 | 482898 | 20.47 | 317987 | 13.48 | 195843 | 8.301 | 101390 | 4.297 |
| 画像9 | 675948 | 28.65 | 471009 | 19.96 | 310975 | 13.18 | 190611 | 8.079 |
| 画像10 | 162898 | 6.905 | 88764 | 3.762 | 48095 | 2.039 | 24119 | 1.022 |
| 平均 | 543546 | 23.04 | 359873 | 15.25 | 223921 | 9.491 | 125921 | 5.337 |
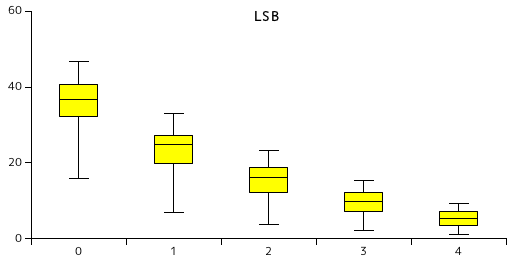 |
下位のビットを量子化すると当然圧縮率はよくなっていきますが、その分、画質は劣化していきます。画質の推移については後ほど示します。
| 画像 | SP_PASS | MR_PASS | ||
|---|---|---|---|---|
| Code size | Ratio(%) | Code size | Ratio(%) | |
| 画像1 | 669417 | 28.37 | 803474 | 34.06 |
| 画像2 | 731519 | 31.01 | 866059 | 36.71 |
| 画像3 | 581874 | 24.66 | 696155 | 29.51 |
| 画像4 | 906763 | 38.43 | 1062548 | 45.04 |
| 画像5 | 712140 | 30.18 | 851090 | 36.07 |
| 画像6 | 745072 | 31.58 | 887931 | 37.64 |
| 画像7 | 545848 | 23.14 | 653769 | 27.71 |
| 画像8 | 569804 | 24.15 | 688873 | 29.20 |
| 画像9 | 779722 | 33.05 | 922289 | 39.09 |
| 画像10 | 208503 | 8.838 | 273357 | 11.59 |
| 平均 | 645066 | 27.34 | 770554 | 32.66 |
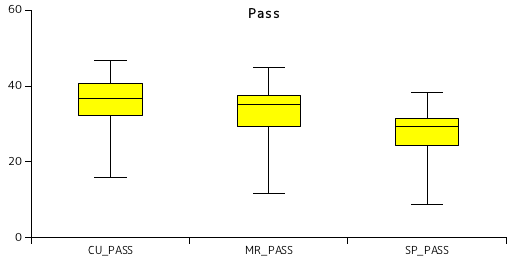 |
図表 5-4. は、最下位ビット ( 0 番目のビット ) に対して Cleanup Pass まで全てを符号化した場合 ( CU_PASS ) に対して Magnitude Refinement Pass で処理をやめた場合 ( MR_PASS ) と Significance Propagation Pass で処理をやめた場合 ( SP_PASS ) を比較した結果です。CU_PASS, MR_PASS, SP_PASS の順に圧縮率は当然上がっていくわけですが、画質にどの程度影響するかについては、これも後述します。
| 画像 | 2 | 3 | 4 | |||
|---|---|---|---|---|---|---|
| Code size | Ratio(%) | Code size | Ratio(%) | Code size | Ratio(%) | |
| 画像1 | 817734 | 34.66 | 808112 | 34.25 | 805124 | 34.13 |
| 画像2 | 856576 | 36.31 | 844127 | 35.78 | 841057 | 35.65 |
| 画像3 | 674312 | 28.58 | 657909 | 27.89 | 654534 | 27.74 |
| 画像4 | 1058972 | 44.89 | 1052000 | 44.59 | 1051470 | 44.57 |
| 画像5 | 833269 | 35.32 | 822222 | 34.85 | 819485 | 34.73 |
| 画像6 | 916241 | 38.84 | 905730 | 38.39 | 904308 | 38.33 |
| 画像7 | 638506 | 27.06 | 619563 | 26.26 | 614961 | 26.07 |
| 画像8 | 718645 | 30.46 | 702934 | 29.79 | 700502 | 29.69 |
| 画像9 | 942464 | 39.95 | 933268 | 39.56 | 931552 | 39.48 |
| 画像10 | 300205 | 12.72 | 277797 | 11.77 | 271476 | 11.51 |
| 平均 | 775692 | 32.88 | 762366 | 32.31 | 759447 | 32.19 |
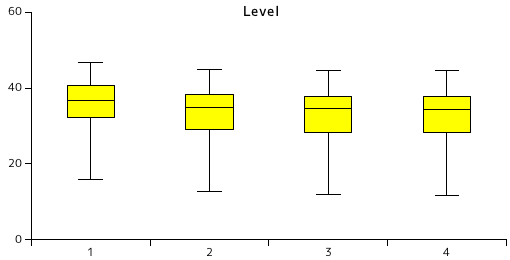 |
ウェーブレット変換回数を増やしても圧縮率にはほとんど変化はありません。
圧縮率に影響するのは符号化する最下位ビットの位置と符号化パスの他にウェーブレット変換方法がありました。そこで、圧縮率の高かった Haar と 9/7 非可逆フィルタの二つについて、lsb = 4 ( 0 〜 3 ビットを符号化しない )、ウェーブレット変換回数を 1 と 3 の二通りとし、他は同一条件 ( LSB に対する符号化パスは全て、コードブロックは画像サイズと同じ ) で処理した時の画像を以下に示します。
| Haar Level=1 | Haar Level=3 |
|---|---|
 |
 |
| 9/7 非可逆フィルタ Level=1 | 9/7 非可逆フィルタ Level=3 |
 |
 |
上図を見る限り画質は Haar の方がよいという結果になりました。変換回数を上げると量子化による画像のエッジがぼやけた感じになります。また、目や帽子の羽の部分など、細かいところはよく再現されている反面、周りの風景などの劣化がかなり激しいという特徴があります。
劣化が激しすぎるため、Y 成分のみを最下位ビットまで処理するようにした場合と、さらに U, V 成分の 3 ビット目に対しては Magnitude Refinement Pass まで処理を行った場合の 2 パターンで処理してみました。どちらも 9/7 非可逆フィルタ を使い、変換回数は 3 回としています。
| Y 成分のみ全ビット符号化 | U/V 成分を Magnitude Refinement Pass まで実行 |
|---|---|
 |
 |
Y 成分を量子化しなくするだけでかなり改善されました。U, V 成分の画質を少し上げた右の画像は、かなりの部分が再現された状態になっています。
下表は、それぞれの条件下での圧縮率を示したものです。LSB(Y/UV) が YUV 各成分の最下位処理ビット、PASS(Y/UV) が YUV 各成分の最下位処理ビットに対する符号化パス ( CU:Cleanup Pass まで, MR:Magnitude Refinement Pass まで ) をそれぞれ示しています。
| Wavelet | Level | LSB(Y) | LSB(U) | LSB(V) | PASS(Y) | PASS(U) | PASS(V) | Code size | Ratio(%) |
|---|---|---|---|---|---|---|---|---|---|
| Haar | 1 | 4 | 4 | 4 | CU | CU | CU | 49891 | 6.344 |
| 3 | 4 | 4 | 4 | CU | CU | CU | 27796 | 3.534 | |
| J2k 9/7 | 1 | 4 | 4 | 4 | CU | CU | CU | 30214 | 3.842 |
| 3 | 4 | 4 | 4 | CU | CU | CU | 11478 | 1.460 | |
| 3 | 0 | 4 | 4 | CU | CU | CU | 142216 | 18.08 | |
| 3 | 0 | 3 | 3 | CU | MR | MR | 144846 | 18.42 |
以上、JPEG2000 の仕組みについて何章かに分けて紹介してきました。今回、特に EBCOT の仕組みが複雑で、サンプル・プログラムも今回はかなりの分量となりました。しかし、JPEG2000 本来の符号化フォーマットは今回のサンプル・プログラムとは異なり、また一部の仕組み ( Region of Interest ( ROI )、すなわち重要度の高い場所のみ圧縮率を変える手法など ) については説明をしていません。興味のある方は、以下の参考文献を一読されることをお勧めします。
![[Go Back]](../images/back1.png) 前に戻る 前に戻る |
![[Back to HOME]](../images/home1.png) タイトルに戻る タイトルに戻る |